Download as PDF, PPTX












![scikit-learn contributors
• GitHub-centric contribution workflow
• each pull request needs 2 x [+1] reviews
• code + tests + doc + example
• ~95% test coverage / Continuous Integration
• 2-3 major releases per years + bug-fix
• 150+ contributors for release 0.15](https://image.slidesharecdn.com/rec204-150227061713-conversion-gate02/85/Scikit-Learn-Machine-Learning-in-Python-21-320.jpg)

![scikit-learn users
• We support users on & ML
• 1500+ questions tagged with [scikit-learn]
• Many competitors + benchmarks
• Many data-driven startups use sklearn
• 500+ answers on 0.13 release user survey
• 60% academics / 40% from industry](https://image.slidesharecdn.com/rec204-150227061713-conversion-gate02/85/Scikit-Learn-Machine-Learning-in-Python-27-320.jpg)



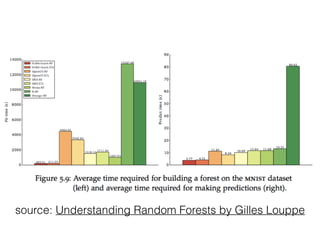
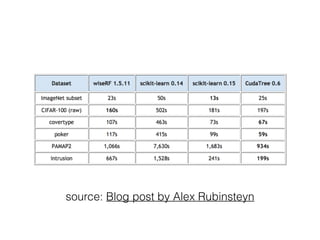




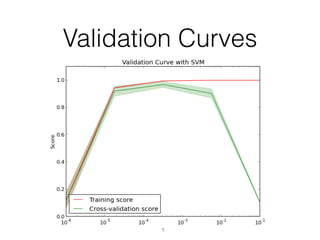
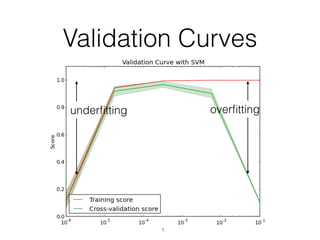
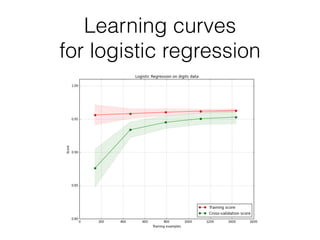
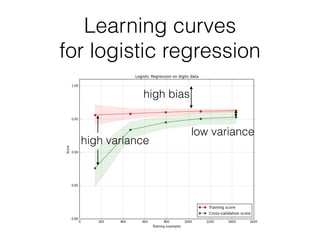
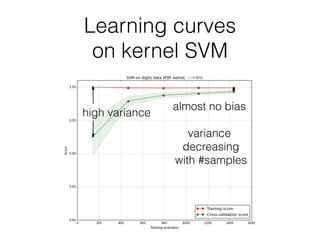




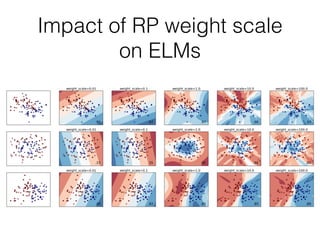






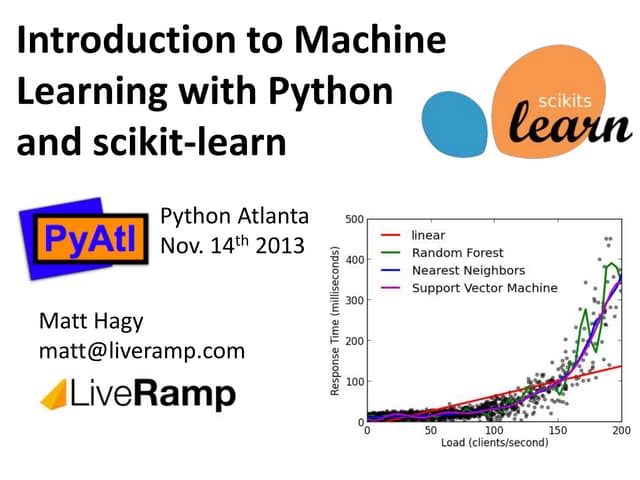
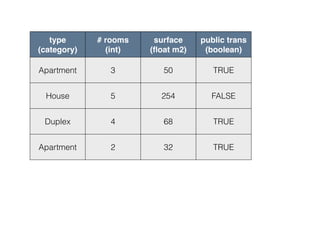
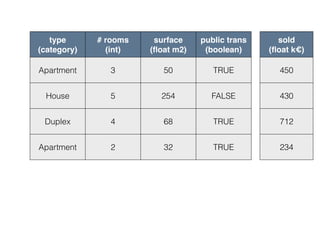
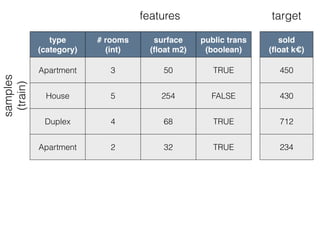
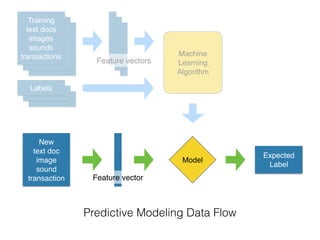
This document provides an overview of machine learning and the scikit-learn library. It discusses predictive modeling using historical data to build executable models for making predictions on new data. It describes how scikit-learn provides machine learning algorithms and tools through a simple API using Python, NumPy and SciPy. It highlights improvements in scikit-learn 0.15, including reduced training times for ensemble methods and optimized memory usage. It demos income classification using scikit-learn with Census data in an IPython notebook.