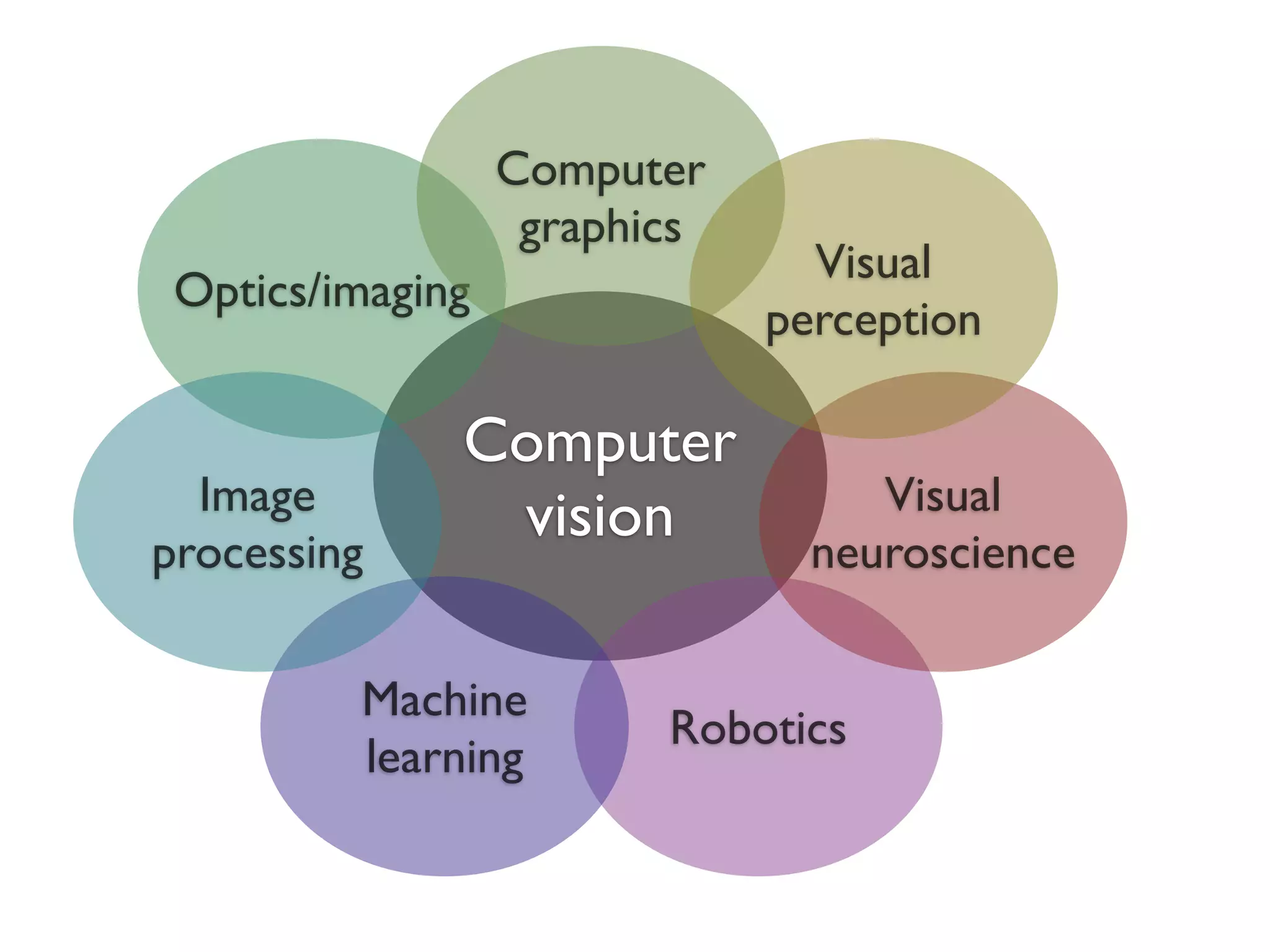
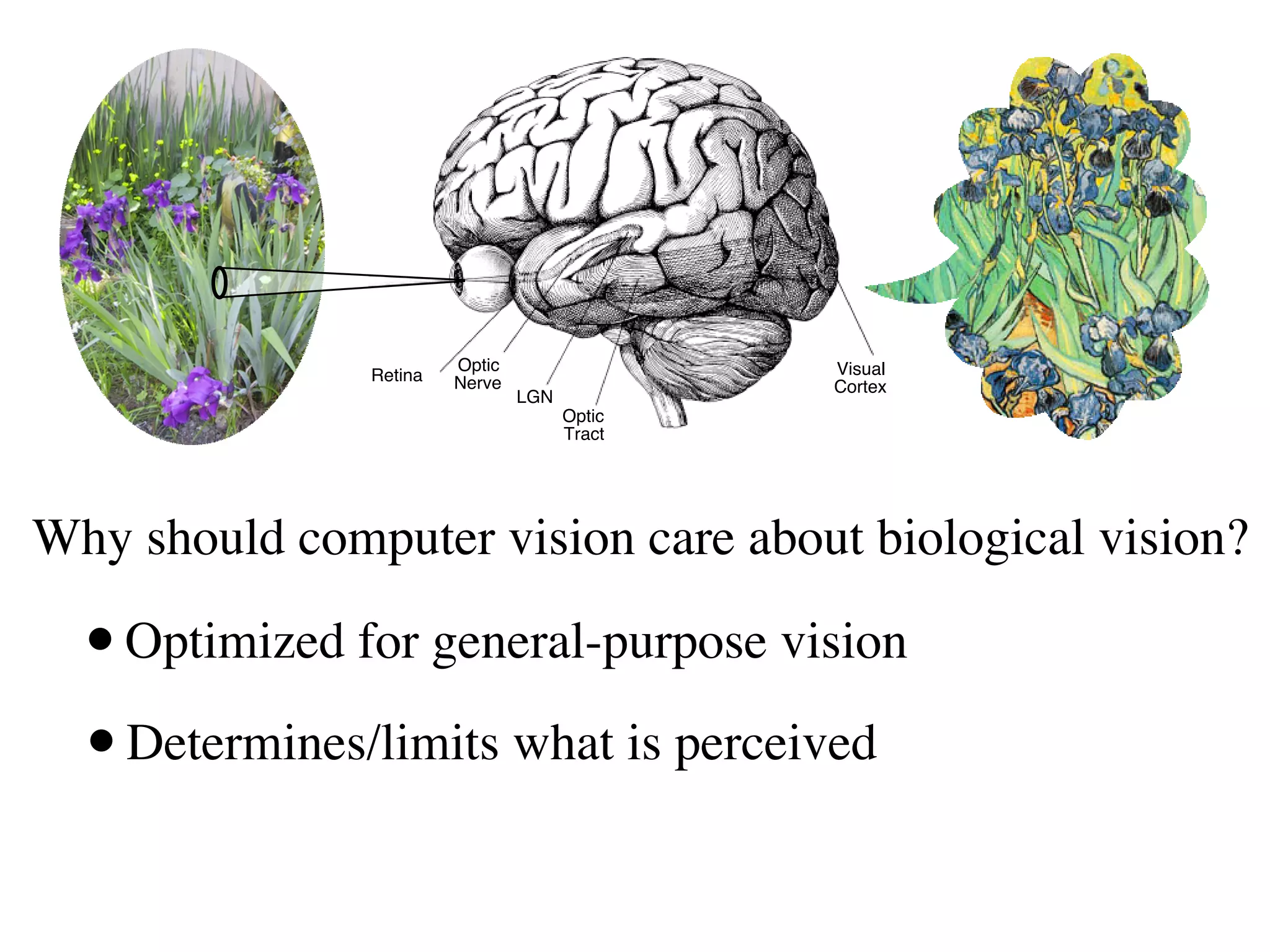
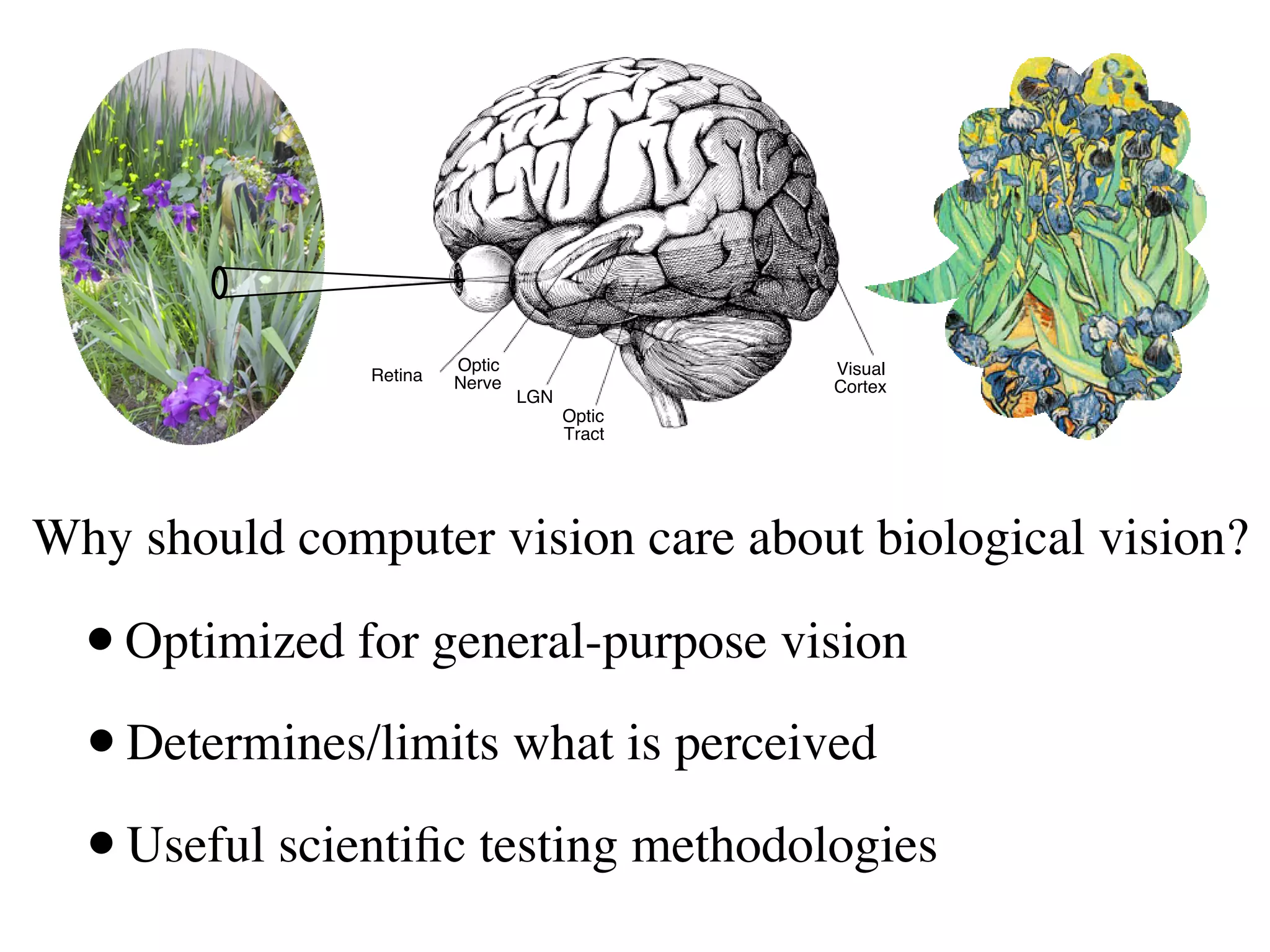
1. The document discusses using principles from biological vision to improve computer vision systems.
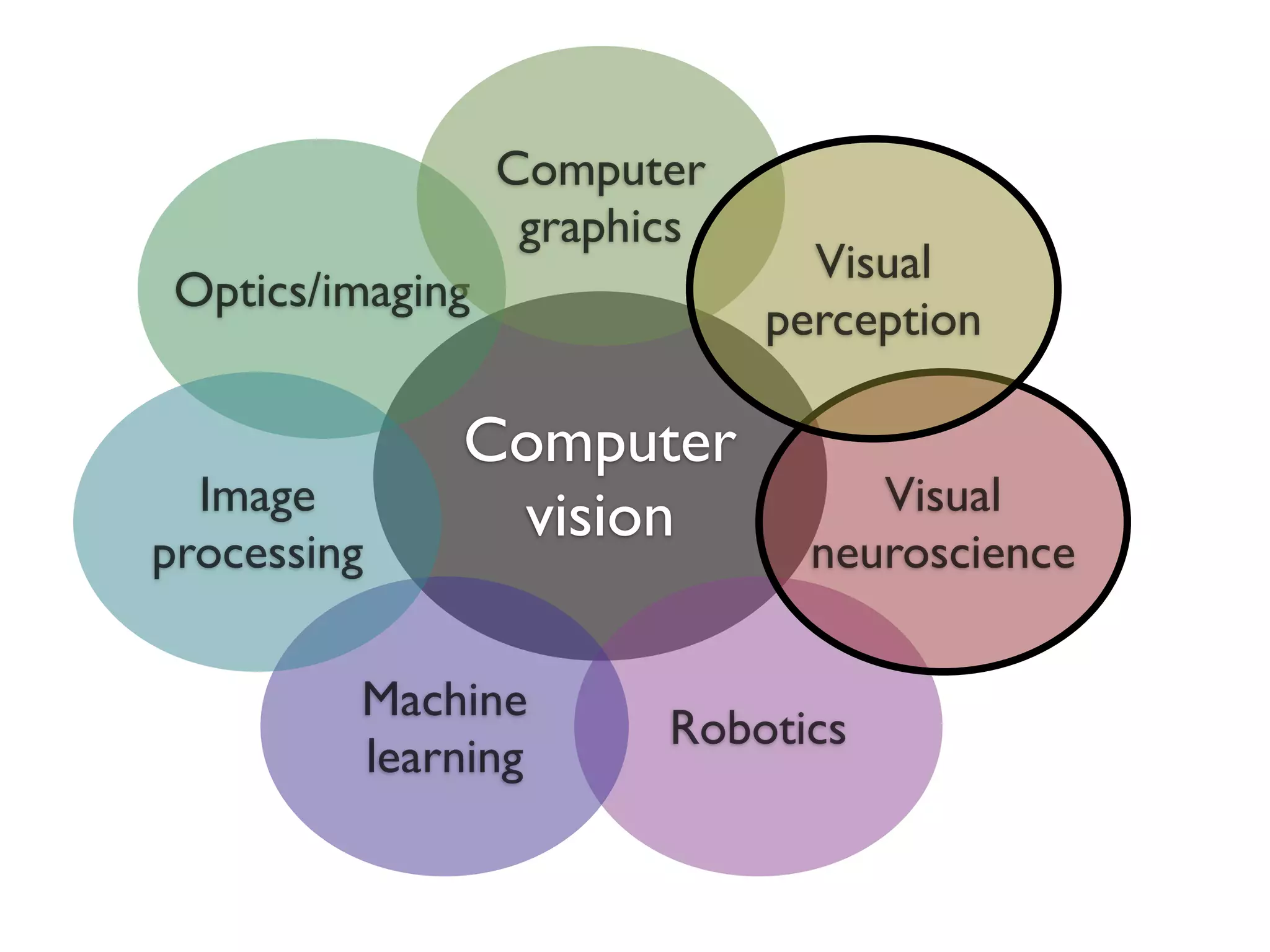
2. It describes how computer vision has incorporated ideas from visual neuroscience, such as using oriented filters inspired by V1 simple cells and implementing normalization models.
3. The document argues that biology uses cascades of canonical operations like linear filtering, nonlinearities, and pooling in an optimized way for general-purpose vision, and following these principles can improve computer vision tasks like object recognition.



![Which features?
[Adelson & Bergen, 1985]](https://image.slidesharecdn.com/fcvbiocvsimoncelli-111230040157-phpapp02/75/Fcv-bio-cv_simoncelli-10-2048.jpg)
![Which features?
Oriented filters: capture stimulus-dependency of neural
responses in primary visual cortex (area V1)
Simple cell
Complex cell +
[Adelson & Bergen, 1985]](https://image.slidesharecdn.com/fcvbiocvsimoncelli-111230040157-phpapp02/75/Fcv-bio-cv_simoncelli-11-2048.jpg)
![Which features?
Oriented filters: capture stimulus-dependency of neural
responses in primary visual cortex (area V1)
Simple cell
Complex cell +
[Adelson & Bergen, 1985]](https://image.slidesharecdn.com/fcvbiocvsimoncelli-111230040157-phpapp02/75/Fcv-bio-cv_simoncelli-12-2048.jpg)
![Which features?
Oriented filters: capture stimulus-dependency of neural
responses in primary visual cortex (area V1)
Simple cell
Complex cell +
[Adelson & Bergen, 1985]](https://image.slidesharecdn.com/fcvbiocvsimoncelli-111230040157-phpapp02/75/Fcv-bio-cv_simoncelli-13-2048.jpg)
![Retinal image
The normalization model of simple cells
Firing
rate
Retinal image
Other cortical cells
RC circuit implementation
Firing
Retinal image rate
Other cortical cells
[Carandini, Heeger, and Movshon, 1996]](https://image.slidesharecdn.com/fcvbiocvsimoncelli-111230040157-phpapp02/75/Fcv-bio-cv_simoncelli-14-2048.jpg)
![Retinal image
The normalization model of simple cells
Firing
rate
Retinal image
Other cortical cells
RC circuit implementation
Firing
Retinal image rate
Other cortical cells
[Carandini, Heeger, and Movshon, 1996]](https://image.slidesharecdn.com/fcvbiocvsimoncelli-111230040157-phpapp02/75/Fcv-bio-cv_simoncelli-15-2048.jpg)
![Dynamic retina/LGN model
[Mante, Bonin & Carandini 2008]](https://image.slidesharecdn.com/fcvbiocvsimoncelli-111230040157-phpapp02/75/Fcv-bio-cv_simoncelli-16-2048.jpg)
![2-stage MT model
Input: image intensities Input: V1 afferents
1
Linear
Receptive ... ...
Field
Half-squaring ...
Rectification ... 2 2
1
+ +
Divisive ... ...
Normalization
Output: V1 neurons tuned for Output: MT neurons tuned for
spatio-temporal orientation local image velocity
[Simoncelli & Heeger, 1998]](https://image.slidesharecdn.com/fcvbiocvsimoncelli-111230040157-phpapp02/75/Fcv-bio-cv_simoncelli-17-2048.jpg)
![2-stage MT model
Input: image intensities Input: V1 afferents
1
Linear
Receptive ... ...
Field
Half-squaring ...
Rectification ... 2 2
1
+ +
Divisive ... ...
Normalization
Output: V1 neurons tuned for Output: MT neurons tuned for
spatio-temporal orientation local image velocity
[Simoncelli & Heeger, 1998]](https://image.slidesharecdn.com/fcvbiocvsimoncelli-111230040157-phpapp02/75/Fcv-bio-cv_simoncelli-18-2048.jpg)

![Improved object recognition?
“In many recent object recognition systems, feature extraction
stages are generally composed of a filter bank, a non-linear
transformation, and some sort of feature pooling layer [...]
We show that using non-linearities that include rectification
and local contrast normalization is the single most important
ingredient for good accuracy on object recognition
benchmarks. We show that two stages of feature extraction
yield better accuracy than one....”
- From the abstract of
“What is the Best Multi-Stage Architecture for Object Recognition?”
Kevin Jarrett, Koray Kavukcuoglu, Marc’Aurelio Ranzato and Yann LeCun
ICCV-2009](https://image.slidesharecdn.com/fcvbiocvsimoncelli-111230040157-phpapp02/75/Fcv-bio-cv_simoncelli-20-2048.jpg)
![Using synthesis to test models I:
Gender classification
• 200 face images (100 male, 100 female)
• Labeled by 27 human subjects
• Four linear classifiers trained on subject data
[Graf & Wichmann, NIPS*03]](https://image.slidesharecdn.com/fcvbiocvsimoncelli-111230040157-phpapp02/75/Fcv-bio-cv_simoncelli-21-2048.jpg)
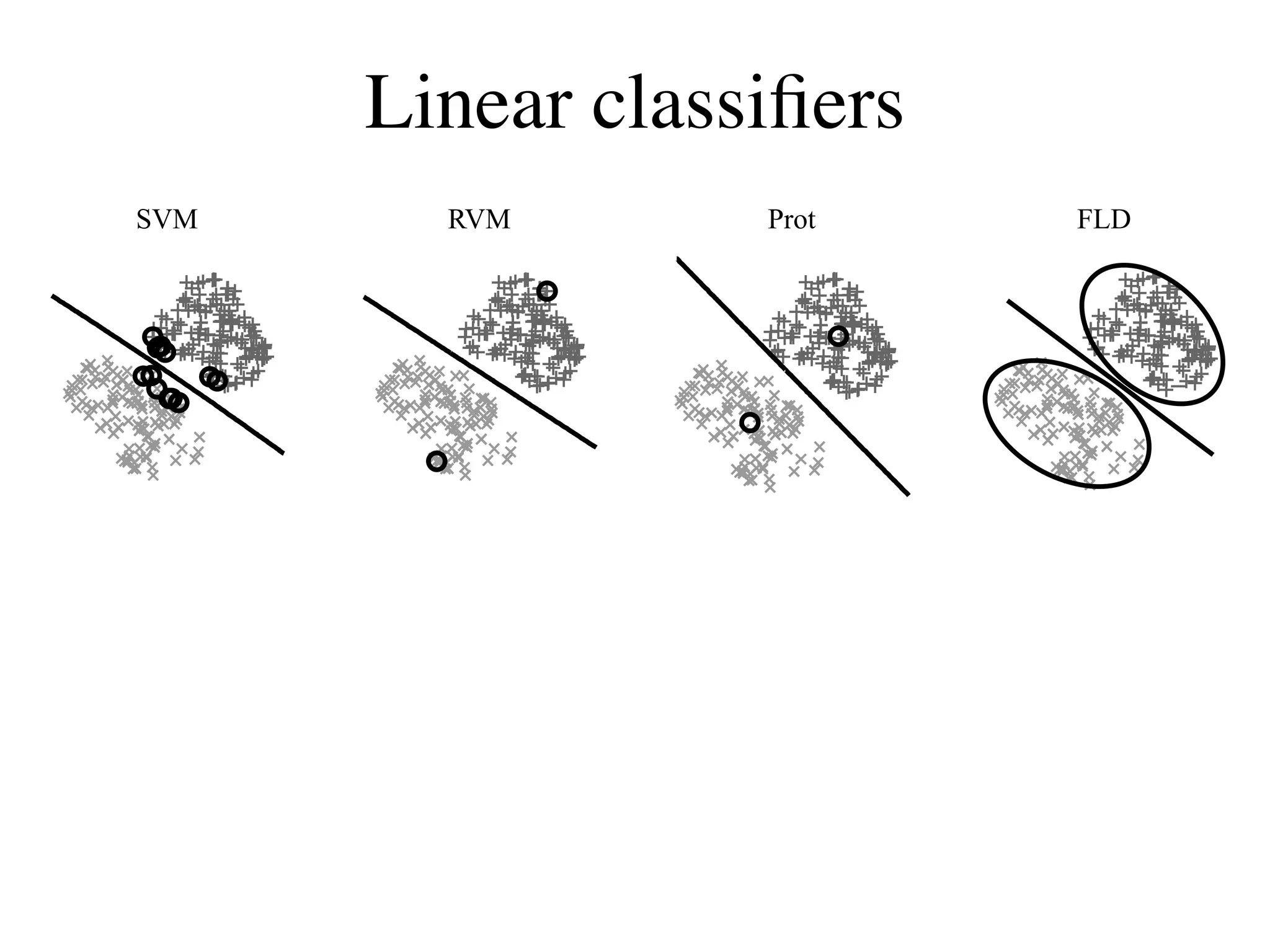
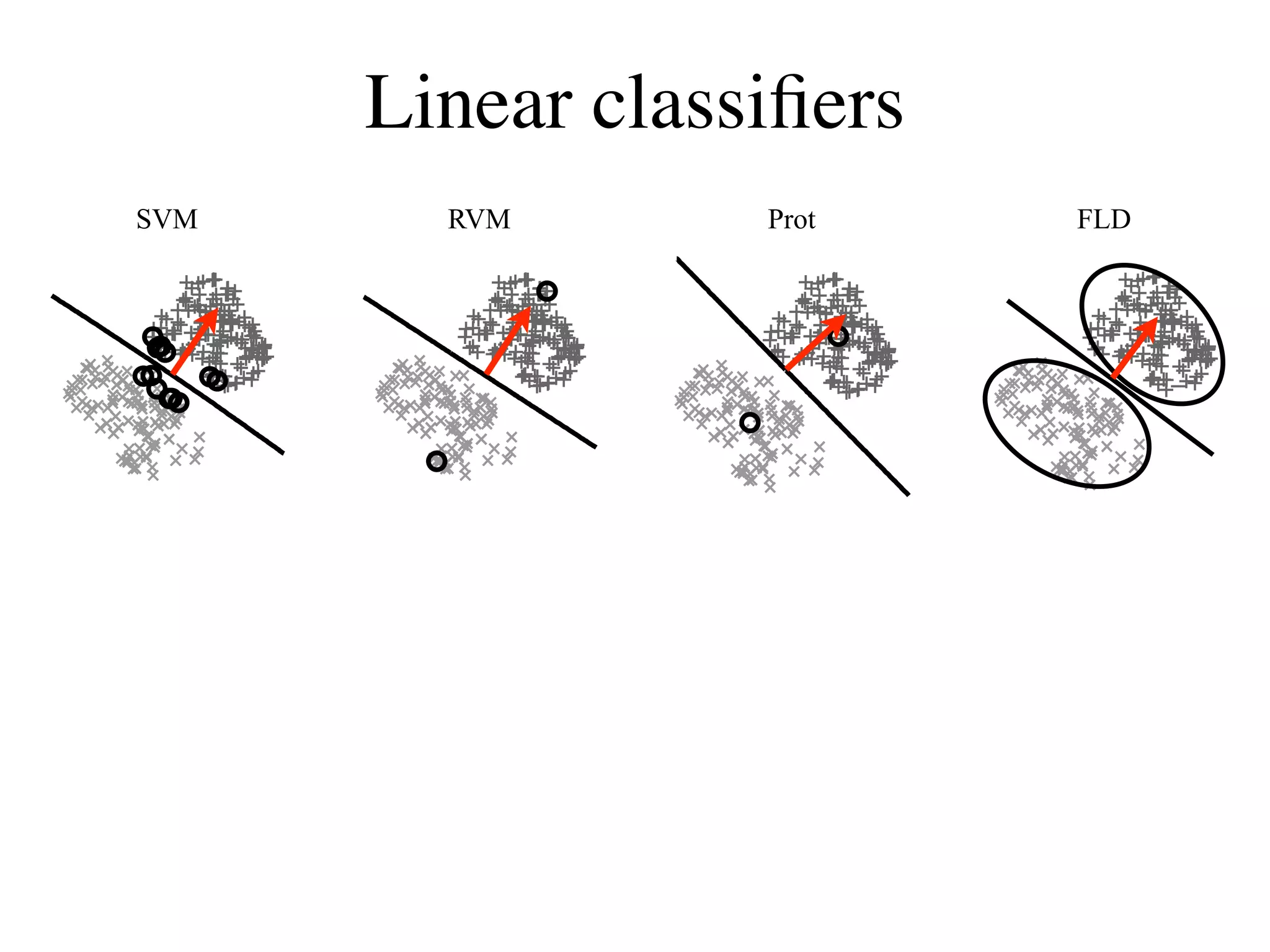
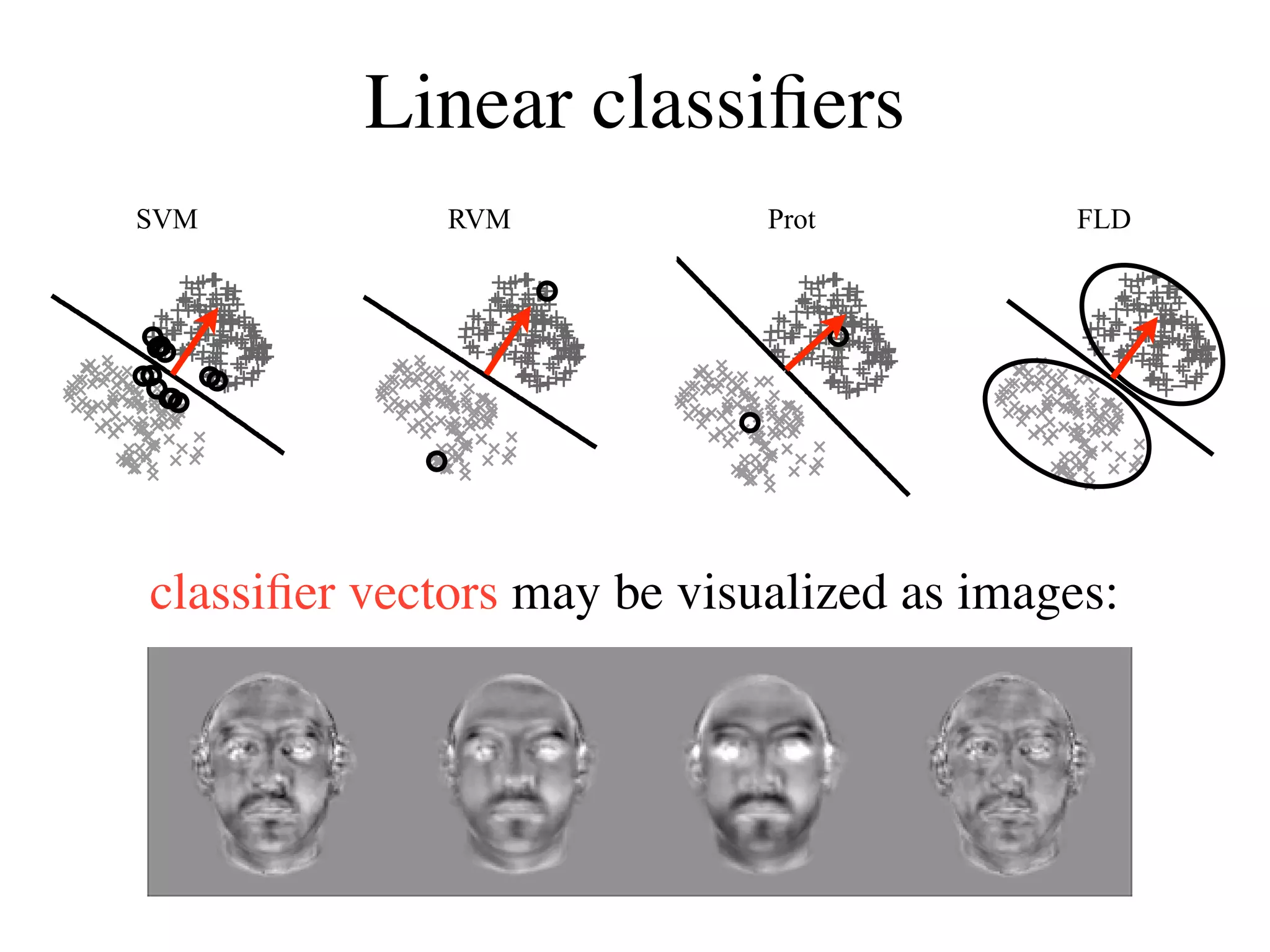
![Validation by “gender-morphing”
Subtract classifier Add classifier
!=−21 !=−14 !=−7 !=0 !=7 !=14 !=21
SVM
RVM
Prot
FLD
[Wichmann, Graf, Simoncelli, Bülthoff, Schölkopf, NIPS*04]](https://image.slidesharecdn.com/fcvbiocvsimoncelli-111230040157-phpapp02/75/Fcv-bio-cv_simoncelli-25-2048.jpg)
![Human subject responses
Perceptual validation
100
SVM
RVM
% Correct
Proto
FLD
50
0.25 0.5 1.0 2.0 4.0 8.0
Amount of classifier image added/subtracted
(arbitrary units)
[Wichmann, Graf, Simoncelli, Bülthoff, Schölkopf, NIPS*04]](https://image.slidesharecdn.com/fcvbiocvsimoncelli-111230040157-phpapp02/75/Fcv-bio-cv_simoncelli-26-2048.jpg)
![rates of an IT population of 200 neurons, despite variation evidence suggests that the ventral stream transfor
in object position and size [19]. It is important to note that (culminating in IT) solves object recognition by unta
Using synthesis to test models II:
using ‘stronger’ (e.g. non-linear) classifiers did not substan-
tially improve recognition performance and the same
object manifolds. For each visual image striking the e
total transformation happens progressively (i.e. st
Ventral stream
representation
[DiCarlo Cox, 2007]](https://image.slidesharecdn.com/fcvbiocvsimoncelli-111230040157-phpapp02/75/Fcv-bio-cv_simoncelli-27-2048.jpg)
![F
a re
fie
V4 fie
Receptive field size (deg)
25 V2 V
20 (1
ec
15 d
10
(b
V1
si
5 T
o
0
b
0 5 10 15 20 25 30 35 40 45 50 et
Eccentricity, receptive center (deg)
Receptive field field center (deg) ec
la
b [Gattass et. al., 1981;
o
Gattass et. al., 1988] th](https://image.slidesharecdn.com/fcvbiocvsimoncelli-111230040157-phpapp02/75/Fcv-bio-cv_simoncelli-28-2048.jpg)
![V1 V4
V2
IT
V1 V2 V4 IT
[Freeman Simoncelli, Nature Neurosci, Sep 2011]](https://image.slidesharecdn.com/fcvbiocvsimoncelli-111230040157-phpapp02/75/Fcv-bio-cv_simoncelli-29-2048.jpg)
![2
1
1
Canonical computation Ventral stream
“complex” cell
Ventral stream
V1 cells
receptive fields
+
[Freeman Simoncelli, Nature Neurosci, Sep 2011]](https://image.slidesharecdn.com/fcvbiocvsimoncelli-111230040157-phpapp02/75/Fcv-bio-cv_simoncelli-30-2048.jpg)
![2
1
1
Canonical computation Ventral stream
“complex” cell
Ventral stream
V1 cells
receptive fields
3.1
1.4
+ 12.5
.
.
.
[Freeman Simoncelli, Nature Neurosci, Sep 2011]](https://image.slidesharecdn.com/fcvbiocvsimoncelli-111230040157-phpapp02/75/Fcv-bio-cv_simoncelli-31-2048.jpg)
![2
1
1
Canonical computation Ventral stream
“complex” cell
Ventral stream
V1 cells
receptive fields
3.1
1.4
+ 12.5
.
.
.
How do we test this?
[Freeman Simoncelli, Nature Neurosci, Sep 2011]](https://image.slidesharecdn.com/fcvbiocvsimoncelli-111230040157-phpapp02/75/Fcv-bio-cv_simoncelli-32-2048.jpg)
![Model
model
Original image responses model
Synthesized image
3.1
1.4
12.5
.
. 250
.
150
25
170
40
Idea: synthesize random samples from the equivalence
class of images with identical model responses
Scientific prediction: such images should look the same
(“Metamers”)
[Freeman Simoncelli, Nature Neurosci, Sep 2011]](https://image.slidesharecdn.com/fcvbiocvsimoncelli-111230040157-phpapp02/75/Fcv-bio-cv_simoncelli-33-2048.jpg)
![Model
Original image responses Synthesized image
3.1
1.4
12.5
.
.
.
Idea: synthesize random samples from the equivalence
class of images with identical model responses
Scientific prediction: such images should look the same
(“Metamers”)
[Freeman Simoncelli, Nature Neurosci, Sep 2011]](https://image.slidesharecdn.com/fcvbiocvsimoncelli-111230040157-phpapp02/75/Fcv-bio-cv_simoncelli-34-2048.jpg)
![Model
Original image responses Synthesized image
3.1
1.4
12.5
.
.
.
Idea: synthesize random samples from the equivalence
class of images with identical model responses
Scientific prediction: such images should look the same
(“Metamers”)
[Freeman Simoncelli, Nature Neurosci, Sep 2011]](https://image.slidesharecdn.com/fcvbiocvsimoncelli-111230040157-phpapp02/75/Fcv-bio-cv_simoncelli-35-2048.jpg)



![Reading
a
b
[Freeman Simoncelli, Nature Neurosci, Sep 2011]](https://image.slidesharecdn.com/fcvbiocvsimoncelli-111230040157-phpapp02/75/Fcv-bio-cv_simoncelli-39-2048.jpg)
![Camouflage
c
[Freeman Simoncelli, Nature Neurosci, Sep 2011]](https://image.slidesharecdn.com/fcvbiocvsimoncelli-111230040157-phpapp02/75/Fcv-bio-cv_simoncelli-40-2048.jpg)

































![Anguruwathota [wb klt-2106]-umts2100 swap site ssv report_v2.0](https://cdn.slidesharecdn.com/ss_thumbnails/anguruwathotawb-klt-2106umts2100swapsitessvreportv2-161202073742-thumbnail.jpg?width=640&height=640&fit=bounds)


























































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)
![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)
















