Download as PDF, PPTX




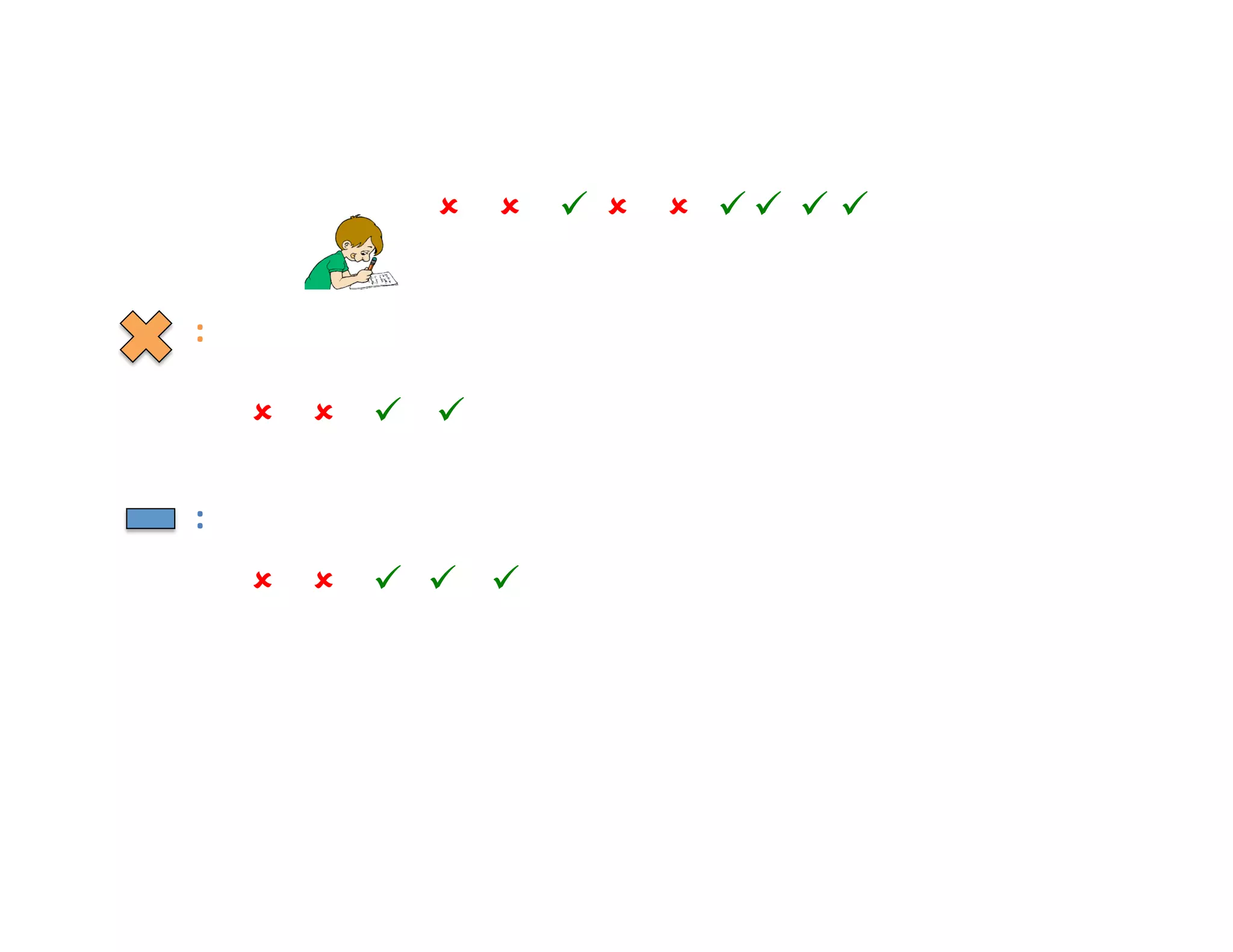
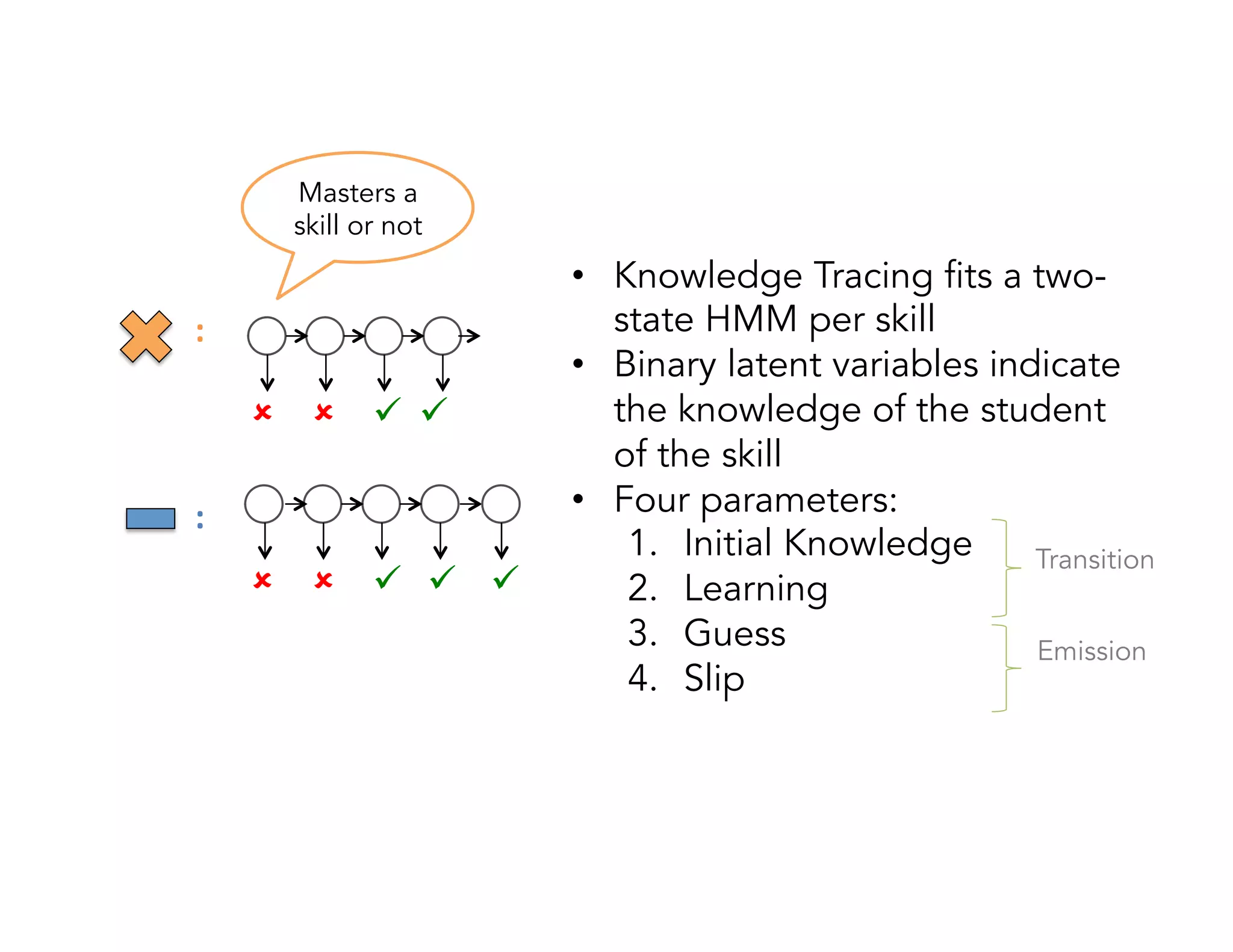













![Something new…
k
y
f
f
• Instead of using inefficient
conditional probability tables,
we use logistic regression
[Berg-Kirkpatrick et al’10 ]
• Exponential complexity ->
linear complexity](https://image.slidesharecdn.com/fastpresentation-150528150241-lva1-app6891/75/EDM2014-paper-General-Features-in-Knowledge-Tracing-to-Model-Multiple-Subskills-Temporal-Item-Response-Theory-and-Expert-Knowledge-20-2048.jpg)

![Something blue?
k
y
f
f
• Not a lot of changes to
implement prediction
• Training requires quite a bit of
changes
– We use a recent modification of
the Expectation-Maximization
algorithm proposed for
Computational Linguistics
problems
[Berg-Kirkpatrick et al’10 ]](https://image.slidesharecdn.com/fastpresentation-150528150241-lva1-app6891/75/EDM2014-paper-General-Features-in-Knowledge-Tracing-to-Model-Multiple-Subskills-Temporal-Item-Response-Theory-and-Expert-Knowledge-22-2048.jpg)


![“Conditional
Probability
Table”
Lookup
Latent
Mastery
Logistic
regression
weights
FAST uses a recent E-M algorithm
[Berg-Kirkpatrick et al’10 ]
E-step](https://image.slidesharecdn.com/fastpresentation-150528150241-lva1-app6891/75/EDM2014-paper-General-Features-in-Knowledge-Tracing-to-Model-Multiple-Subskills-Temporal-Item-Response-Theory-and-Expert-Knowledge-25-2048.jpg)
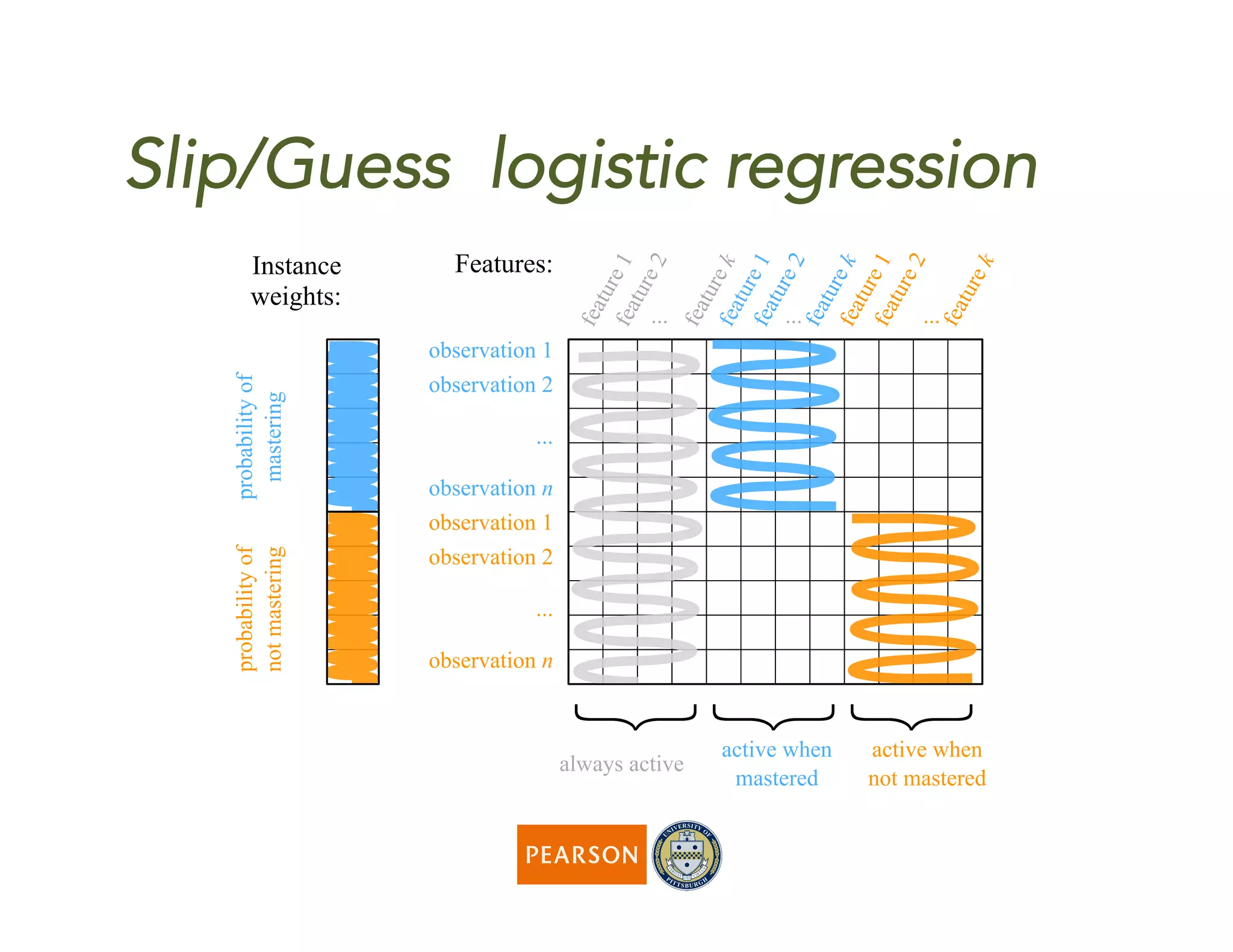
![Slip/guess lookup:
Mastery p(Correct)
False (1)
True (2)
Use the multiple
parameters of logistic
regression to fill the
values of a “no-
features”conditional
probability table!
[Berg-Kirkpatrick et al’10 ]](https://image.slidesharecdn.com/fastpresentation-150528150241-lva1-app6891/75/EDM2014-paper-General-Features-in-Knowledge-Tracing-to-Model-Multiple-Subskills-Temporal-Item-Response-Theory-and-Expert-Knowledge-26-2048.jpg)
![“Conditional
Probability
Table”
Lookup
Latent
Mastery
Logistic
regression
weights
FAST uses a recent E-M algorithm
[Berg-Kirkpatrick et al’10 ]](https://image.slidesharecdn.com/fastpresentation-150528150241-lva1-app6891/75/EDM2014-paper-General-Features-in-Knowledge-Tracing-to-Model-Multiple-Subskills-Temporal-Item-Response-Theory-and-Expert-Knowledge-27-2048.jpg)






![Multiple subskills &
KnowledgeTracing
• Original Knowledge Tracing can not
model multiple subskills
• Most Knowledge Tracing variants assume
equal importance of subskills during
training (and then adjust it during testing)
• State of the art method, LR-DBN [Xu and
Mostow ’11] assigns importance in both
training and testing](https://image.slidesharecdn.com/fastpresentation-150528150241-lva1-app6891/75/EDM2014-paper-General-Features-in-Knowledge-Tracing-to-Model-Multiple-Subskills-Temporal-Item-Response-Theory-and-Expert-Knowledge-36-2048.jpg)



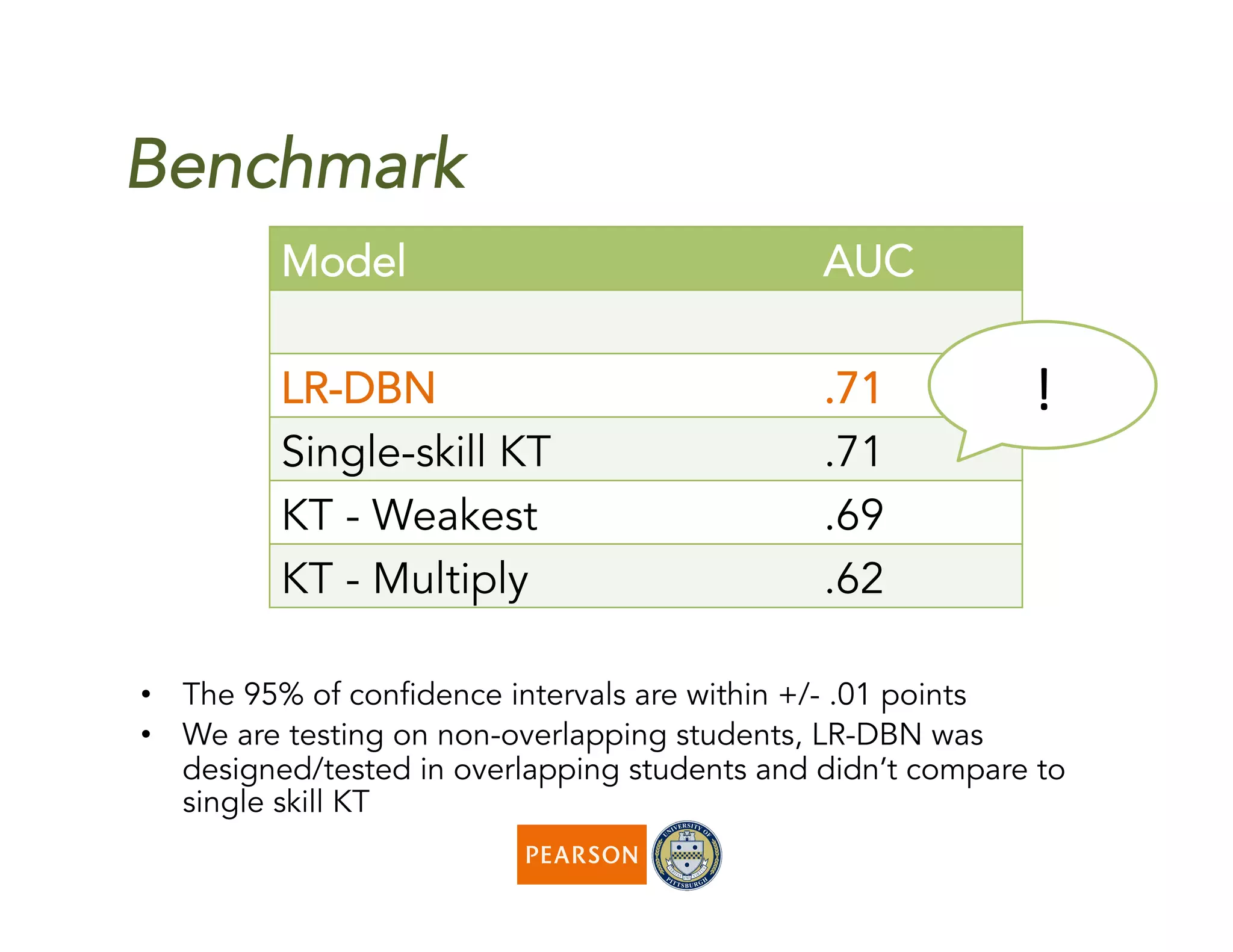
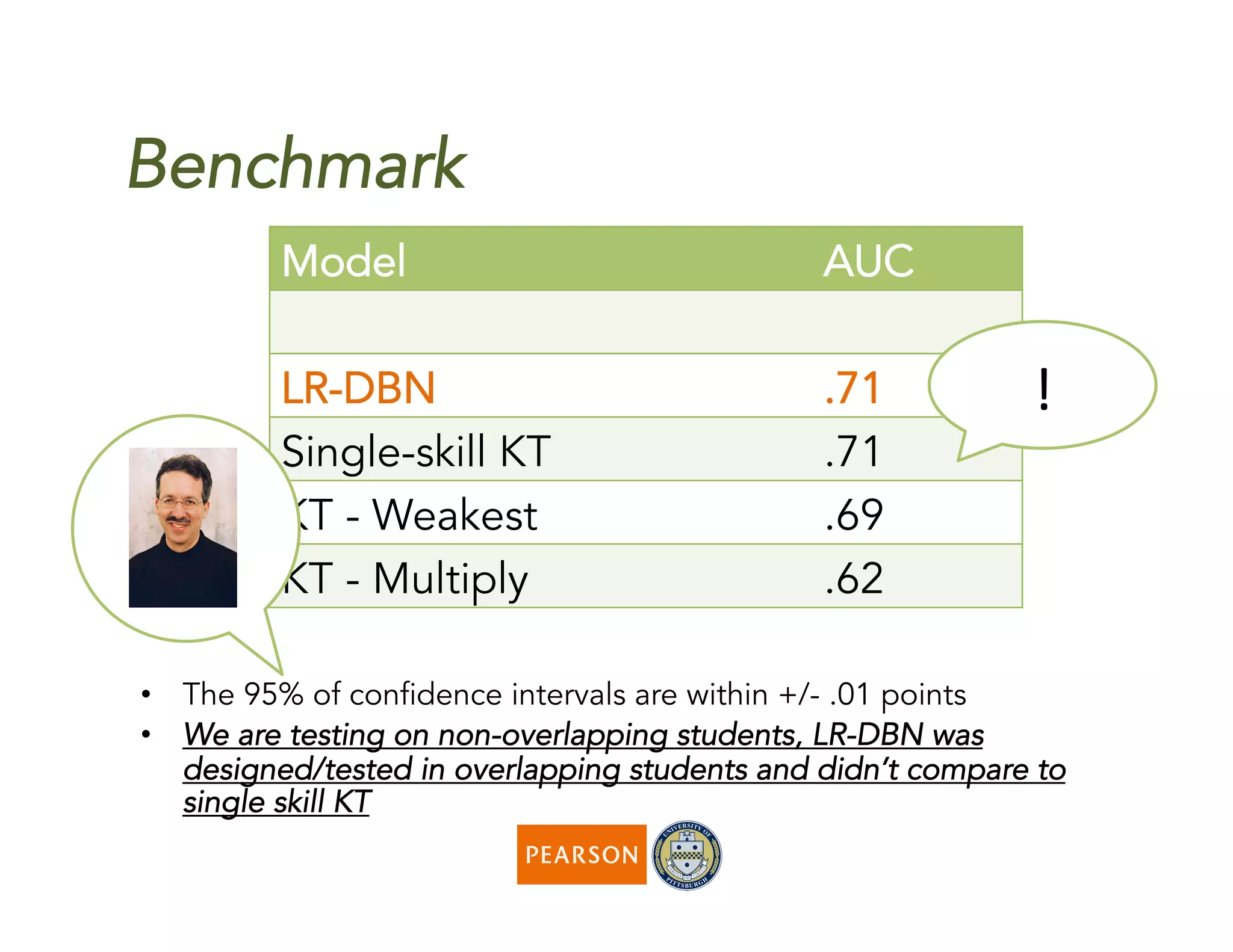
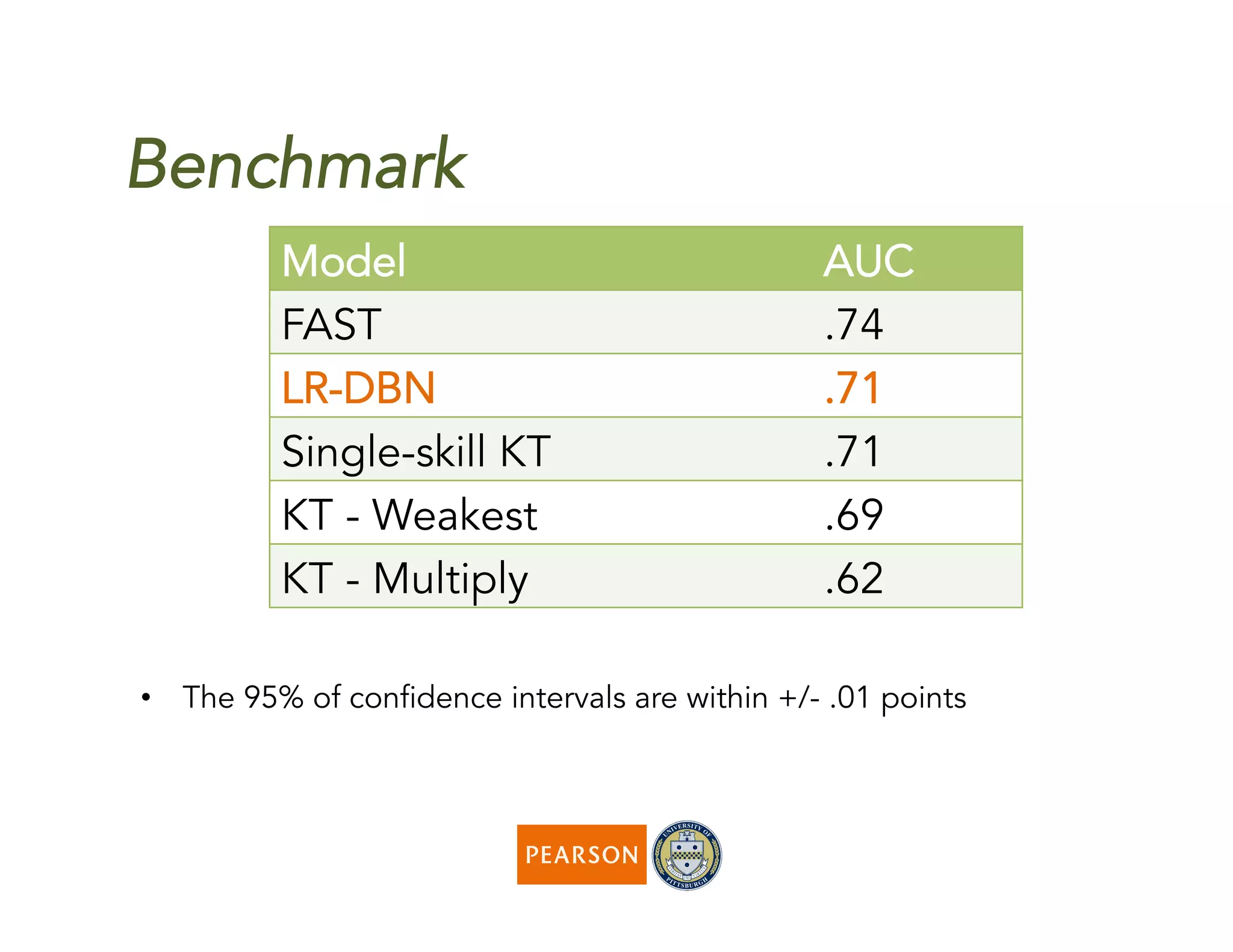




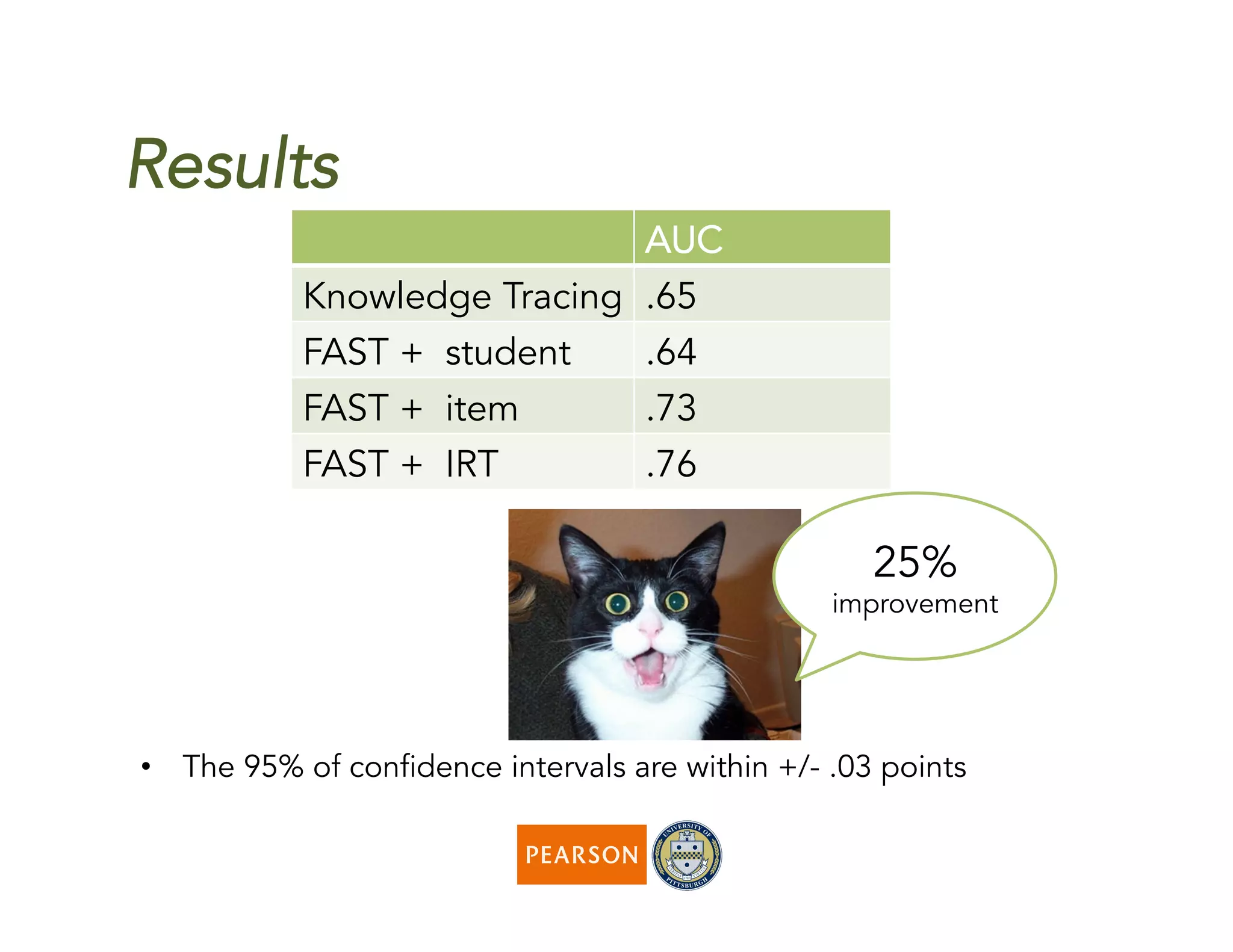


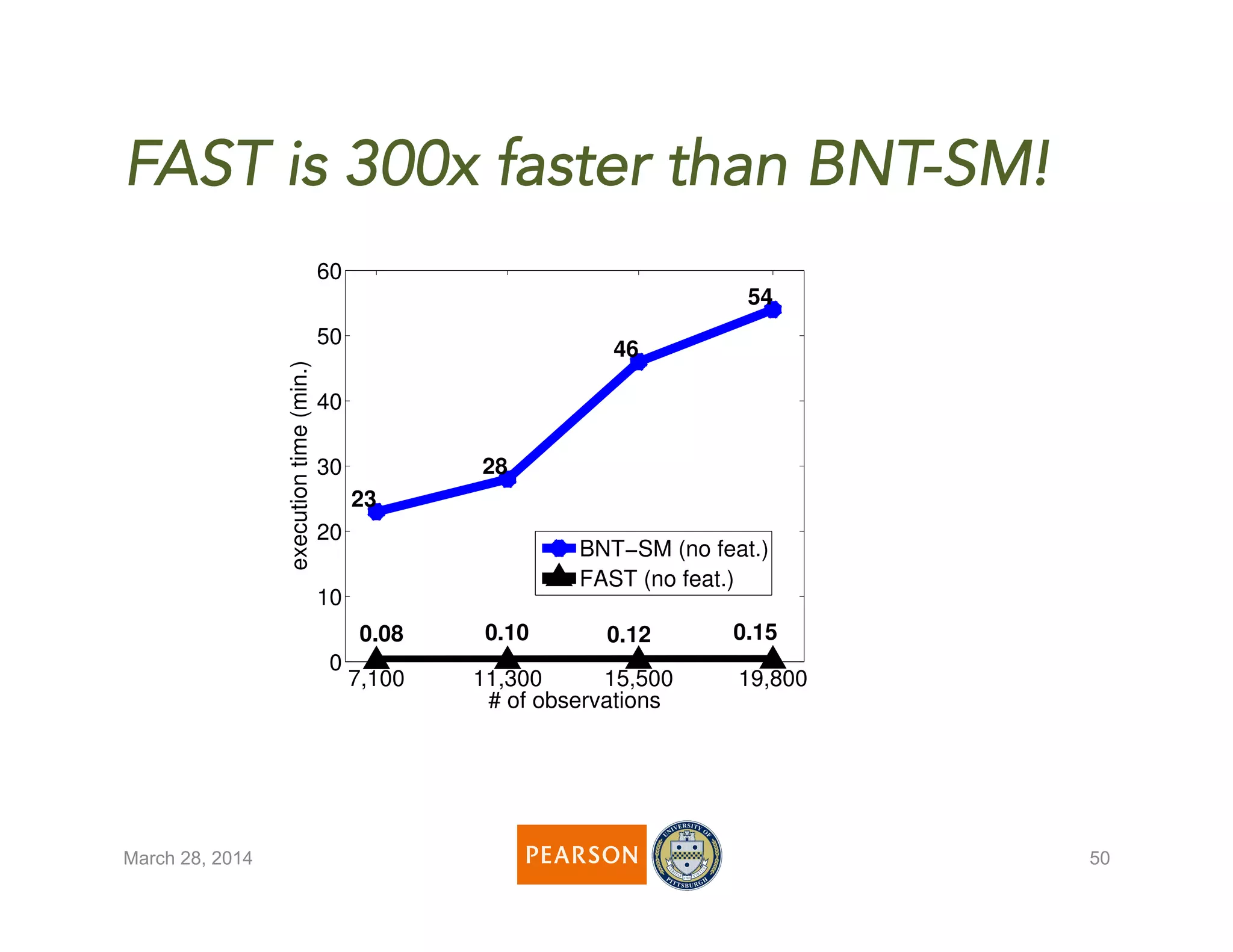


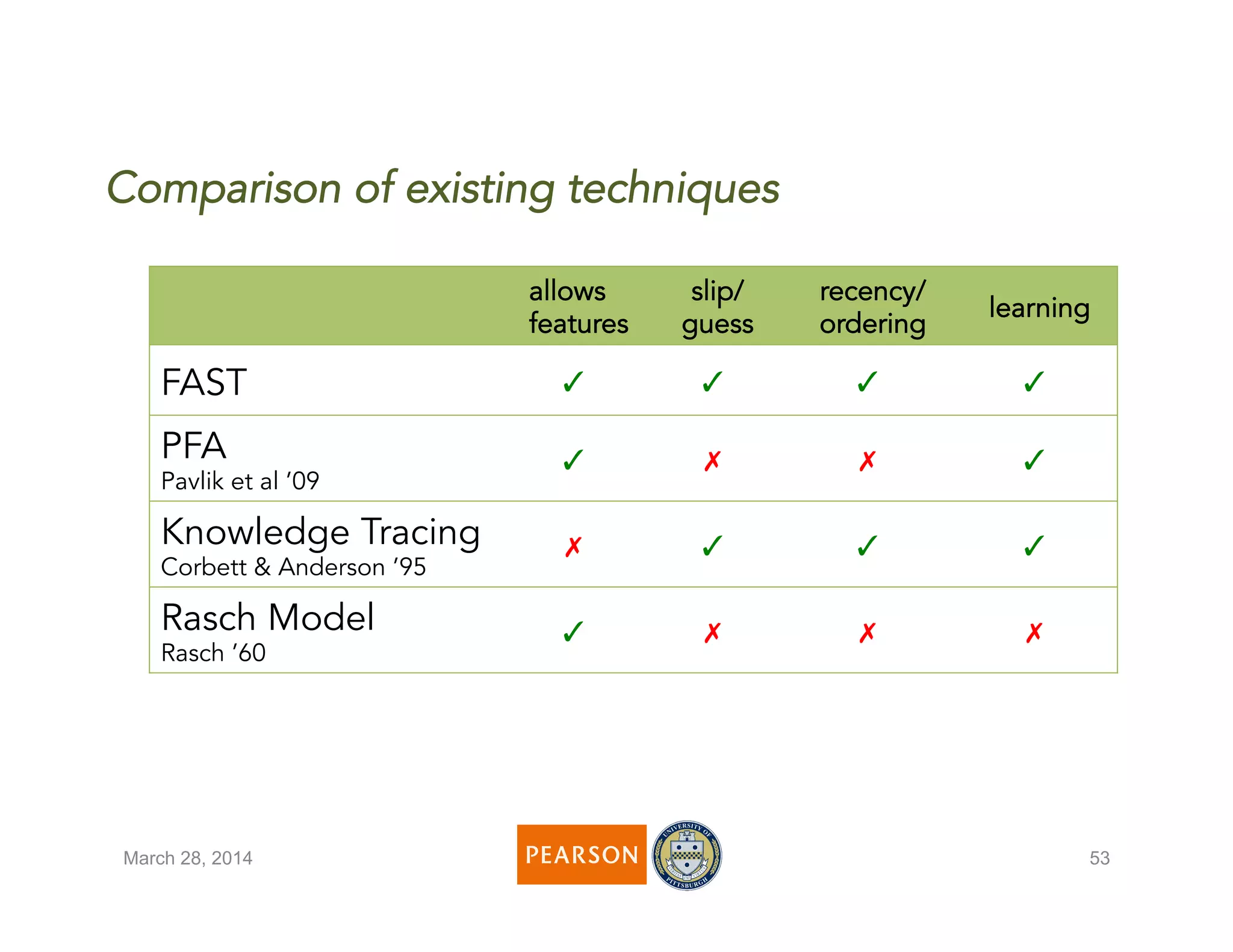




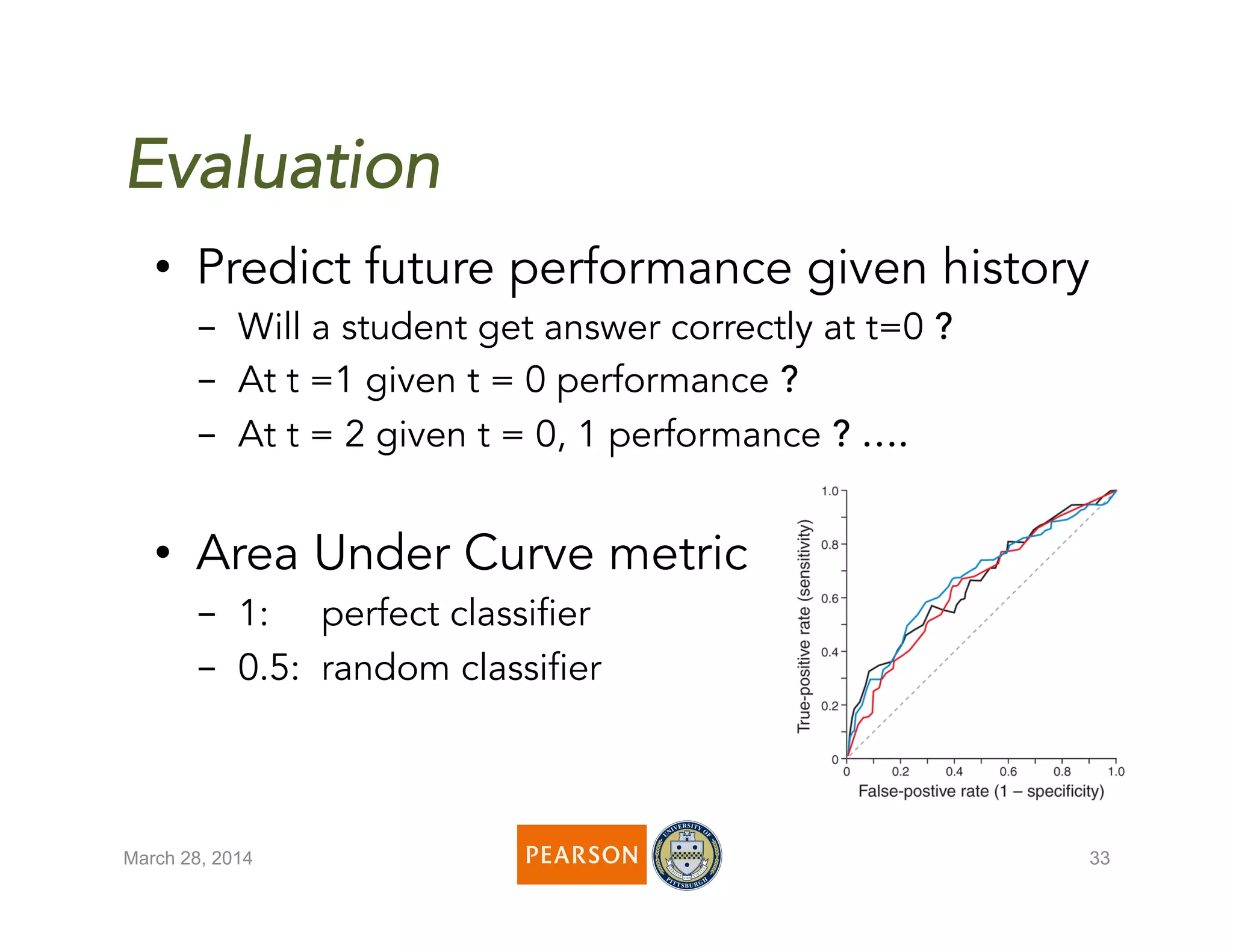
The document discusses a novel algorithm called 'fast' for feature-aware student knowledge tracing, which enhances student mastery assessment by utilizing fine-grained performance data and enabling faster processing times. The algorithm outperforms traditional methods in both accuracy and computational efficiency, achieving 25% better AUC and up to 300 times faster execution. It addresses limitations of past knowledge tracing models by accommodating multiple subskills and utilizing logistic regression for better scalability.


























































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)






![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)
