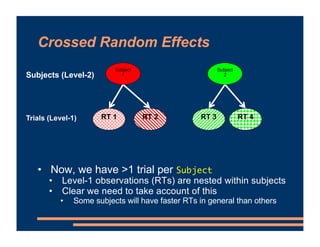
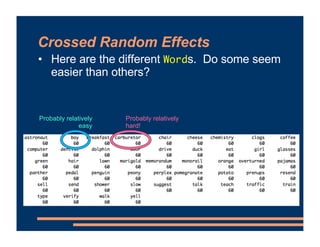
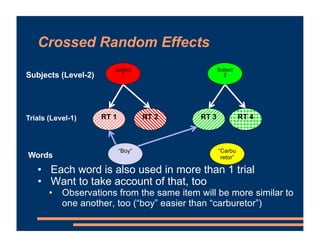
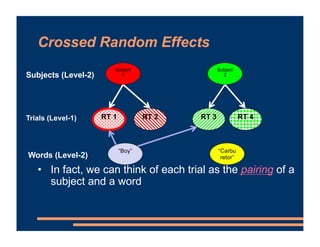
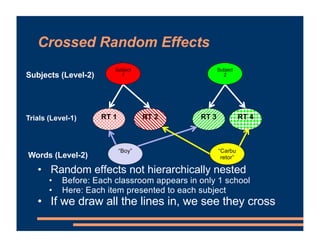
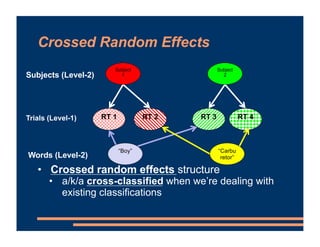
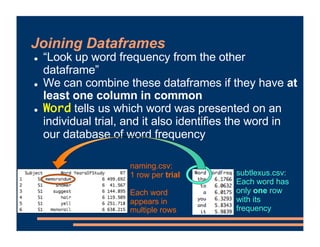
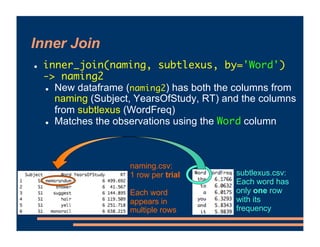
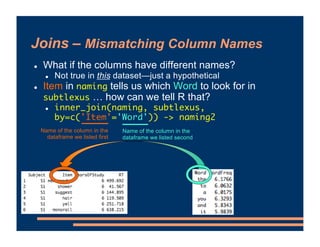
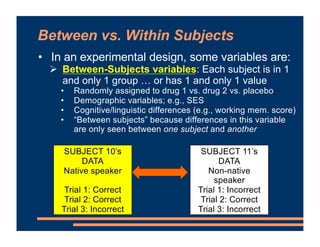
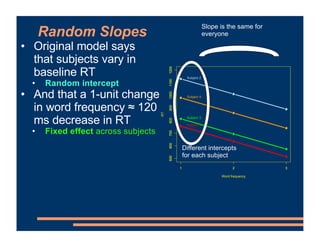
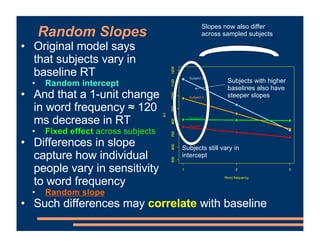
This document discusses crossed random effects analysis using an experimental dataset measuring response times for students learning English naming words. The dataset includes 60 subjects presented with 49 words each, with measurements of years of study and word frequency as variables of interest. It describes fitting a linear mixed effects model with random intercepts for subject and word to account for non-independence of observations. It also discusses joining additional word frequency data from another file and adding word frequency as a fixed effect. Finally, it introduces the concepts of between-subjects and within-subjects variables to determine what random slopes may be relevant.







































































![Experimentalresearch[1]](https://cdn.slidesharecdn.com/ss_thumbnails/experimentalresearch1-090414212522-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)









































