Downloaded 62 times







![Example Queries (for a taste)
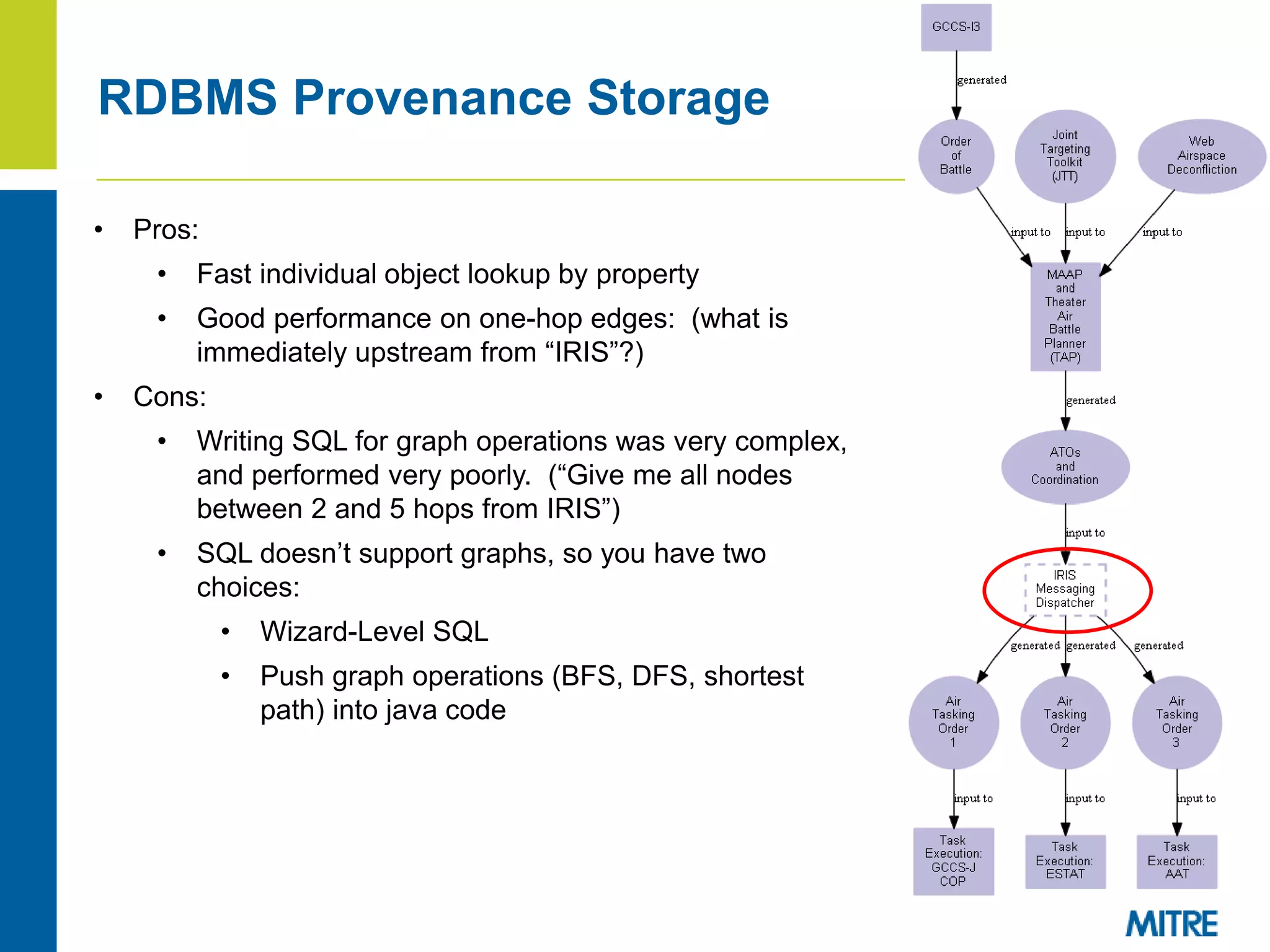
match (n {oid: {oid}})<-[*1..5]-m
where m.type='invocation'
return m;
match (n {oid: {oid}})-[*]->m
where m.name =~ '.*COP.*'
return m;
Get all upstream invocations between 1 and 5 steps away
Does this item flow into any Common Operating Picture? (COP)](https://image.slidesharecdn.com/familytreeofdataprovenanceandneo4j-150328185216-conversion-gate01/75/Family-tree-of-data-provenance-and-neo4j-16-2048.jpg)
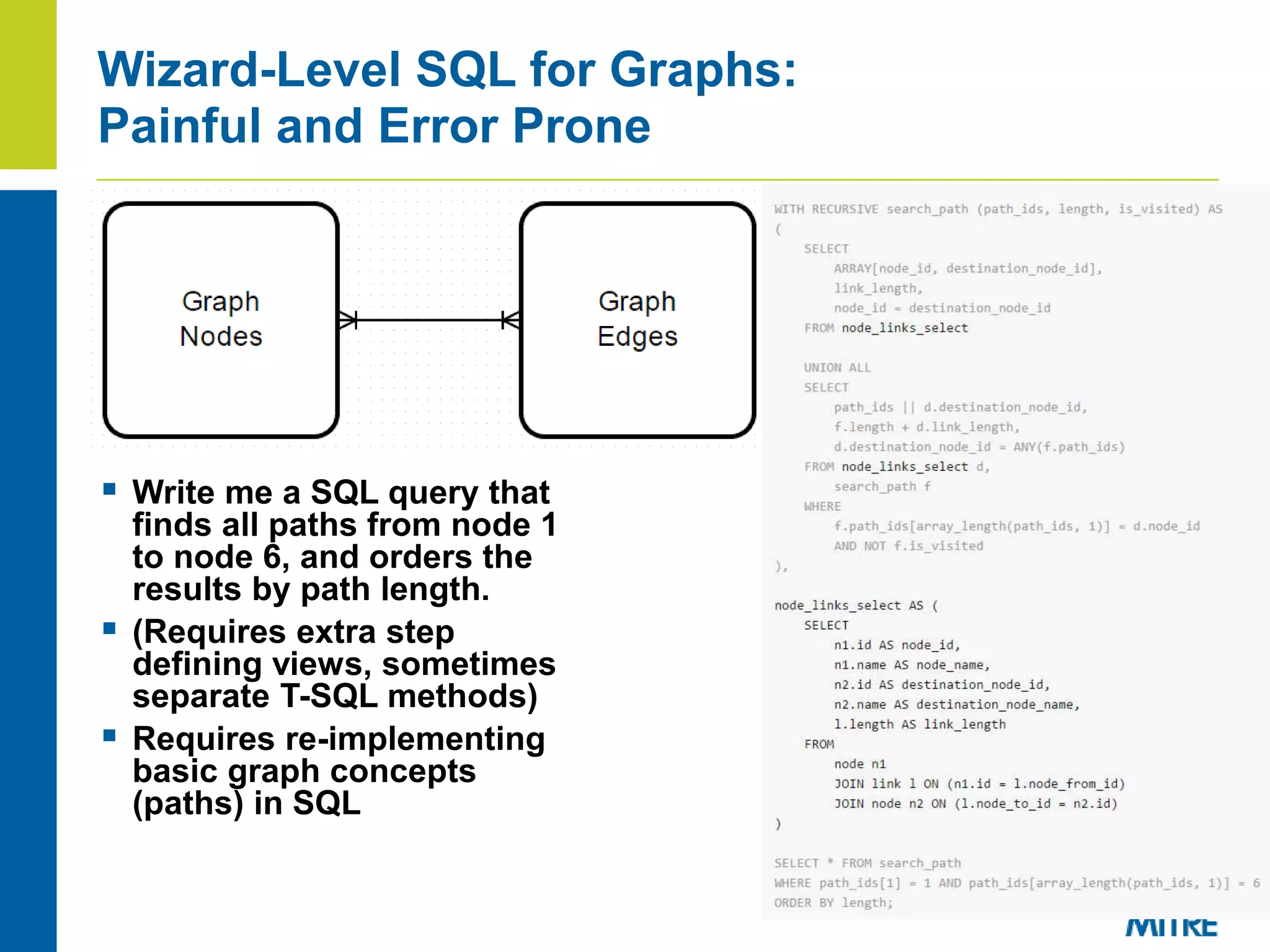
![Example Queries (for a taste)
match m-[r:*]->(n {oid: {oid}})
where m.name='GCCS-I3'
return length(r);
START n=node:node_auto_index(oid={oid})
match (n {oid: {oid}})<-[r:*]-m,
owner-[r1:owns]->m
where m.type='data' and owner.name='TBMCS'
return count(distinct m);
How many hops away is GCCS-I3?
How many different data items from TBMCS contribute to this node?](https://image.slidesharecdn.com/familytreeofdataprovenanceandneo4j-150328185216-conversion-gate01/75/Family-tree-of-data-provenance-and-neo4j-17-2048.jpg)


![How to Think in Graphs:
Get all relationships in a workflow
A B C
workflow
instanceinstance
instance
A B C
Workflow
id=1
Node/Table Orientation
relationship
wf=1
relationship
wf=1
Graph Orientation
START r=relationship(*)
WHERE r.workflow = 'SOME WORKFLOW ID'
RETURN r
MATCH (wf:Workflow {oid: ‘foo’})
->[r:instance]->node,
node-[pr:generated|`input to`]->m
RETURN pr
SLOWER
(and requires special index on “id” property)
FASTER](https://image.slidesharecdn.com/familytreeofdataprovenanceandneo4j-150328185216-conversion-gate01/75/Family-tree-of-data-provenance-and-neo4j-20-2048.jpg)



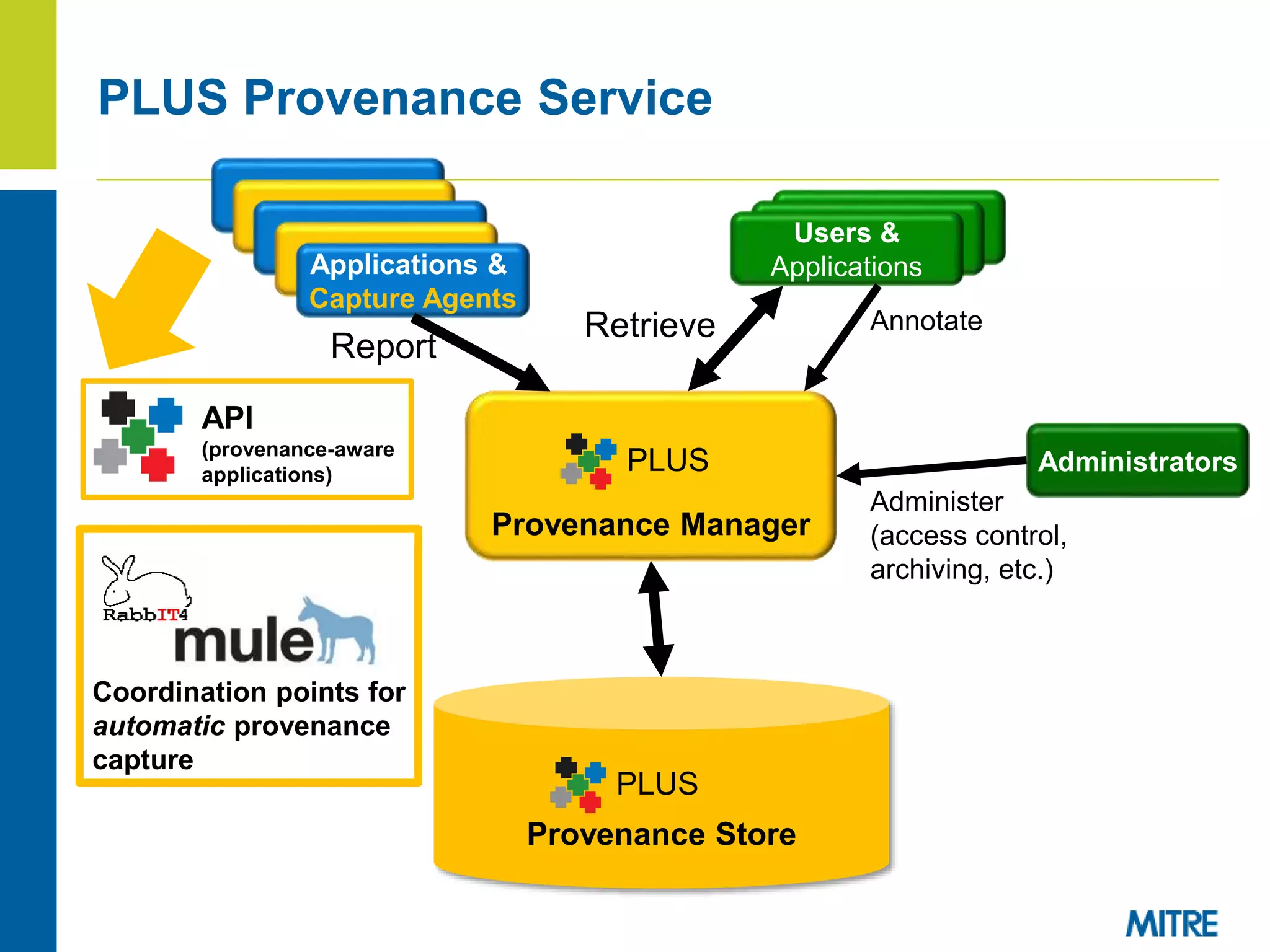


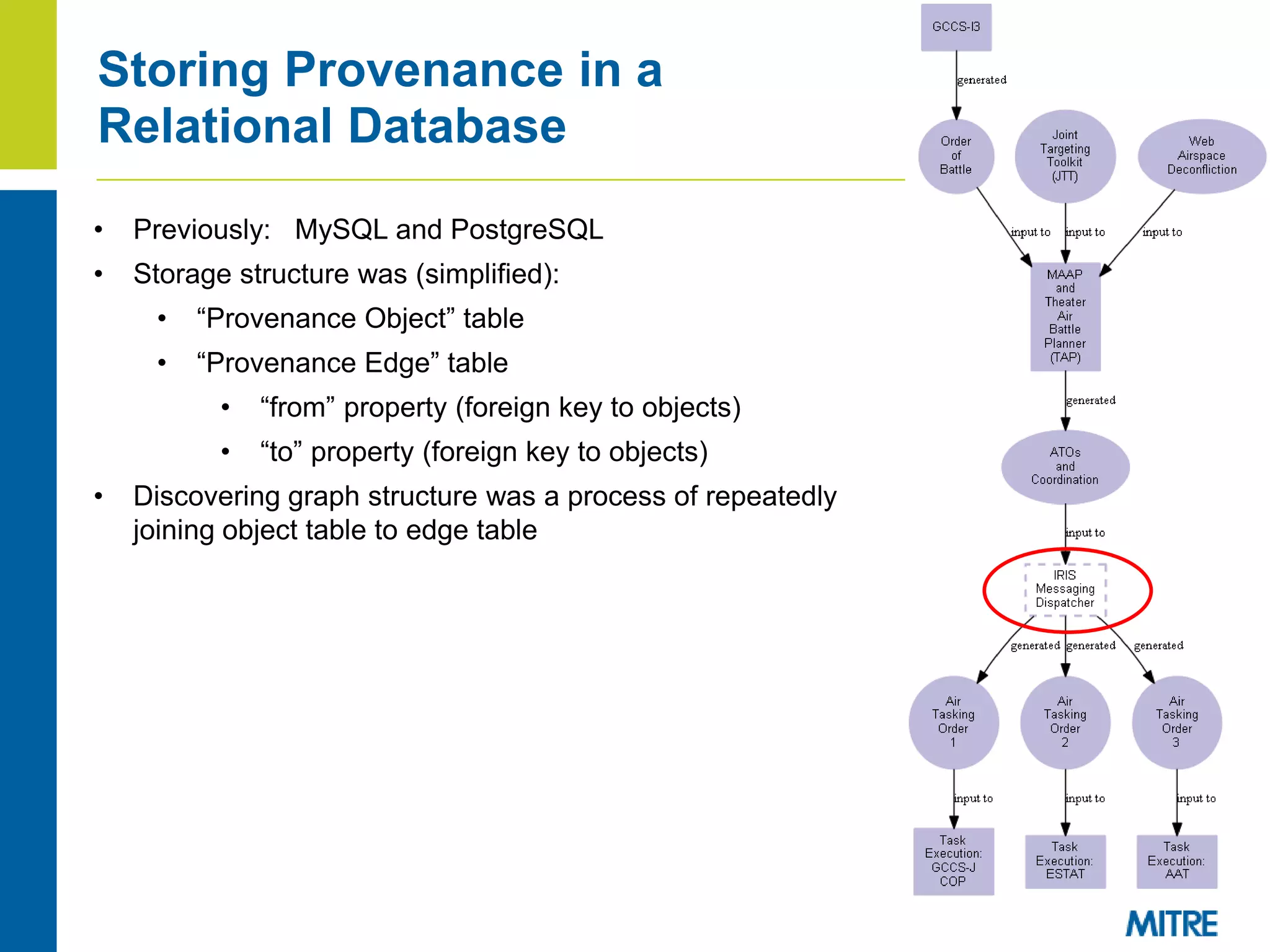
The document discusses using Neo4j, a graph database, to store and query provenance data. Some key points: - Storing provenance in a relational database requires complex SQL and pushes graph operations into code, hurting performance on graph queries. - Neo4j uses the Cypher query language which allows declarative graph queries without imperative code. - Example Cypher queries are provided to demonstrate retrieving paths and relationships in a provenance graph. - While graph databases provide better performance for graph queries, they have limitations for certain bulk scans compared to relational databases. Proper graph design is important.









































































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)













