Download as PDF, PPTX


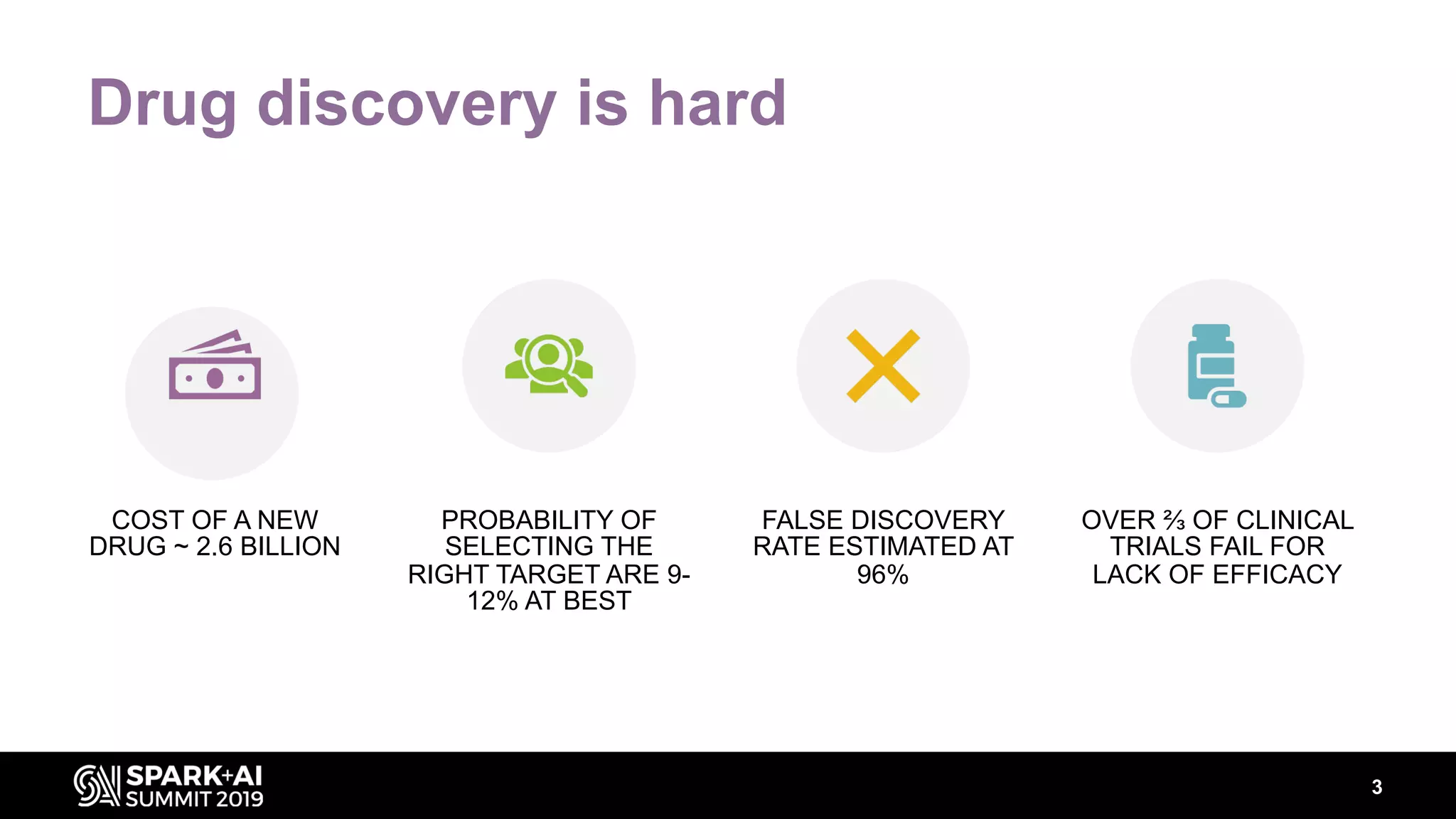
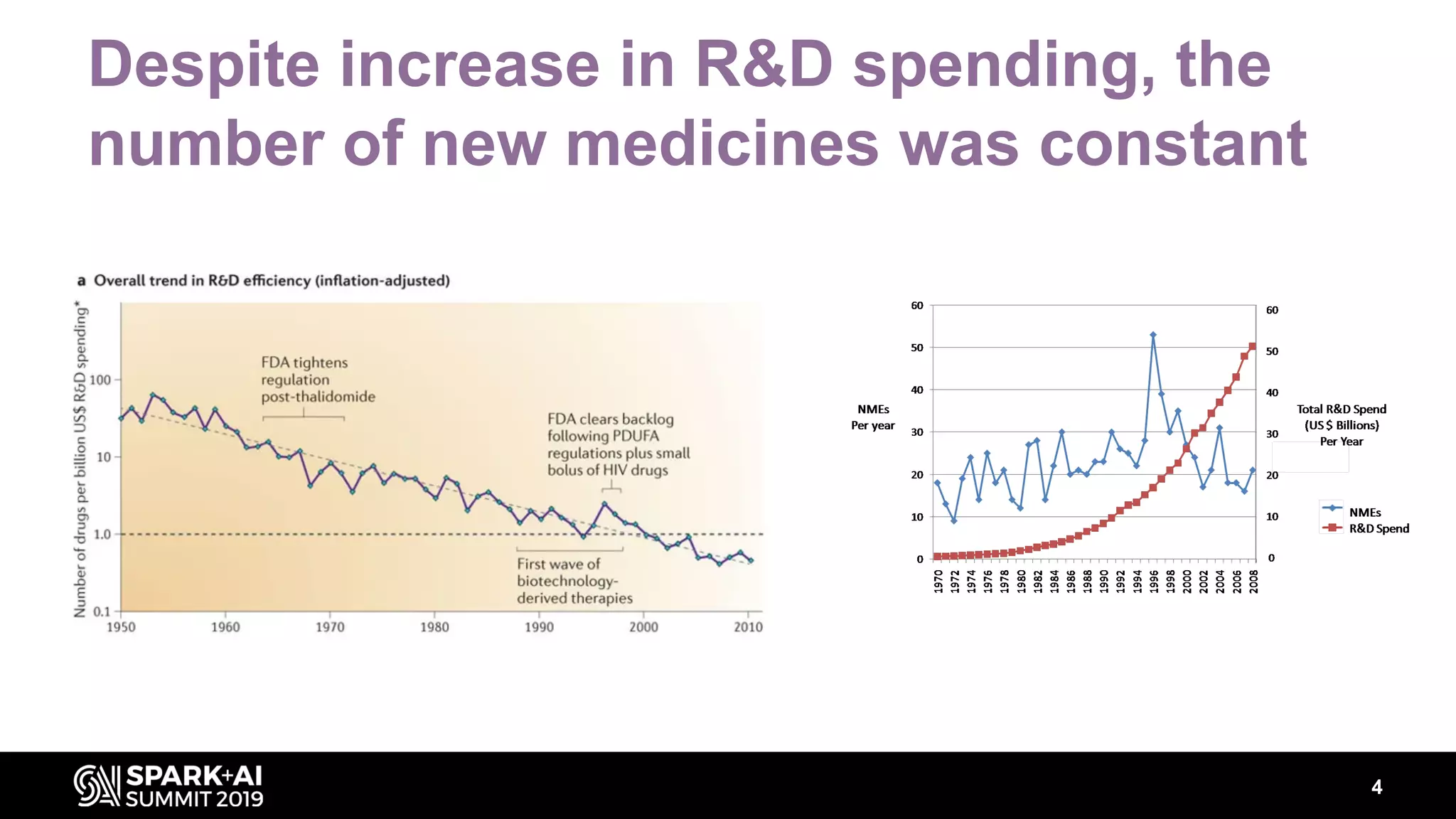
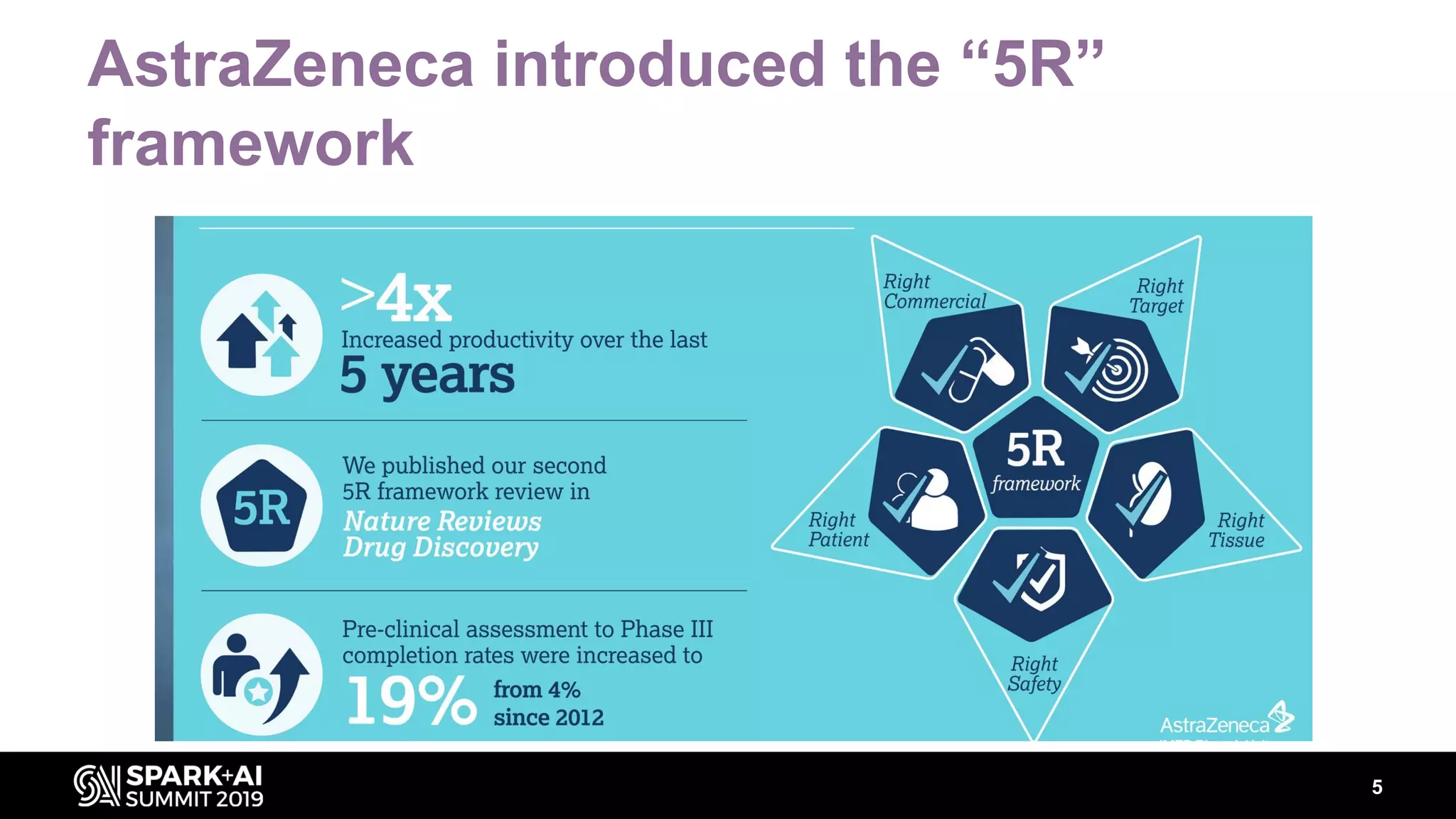
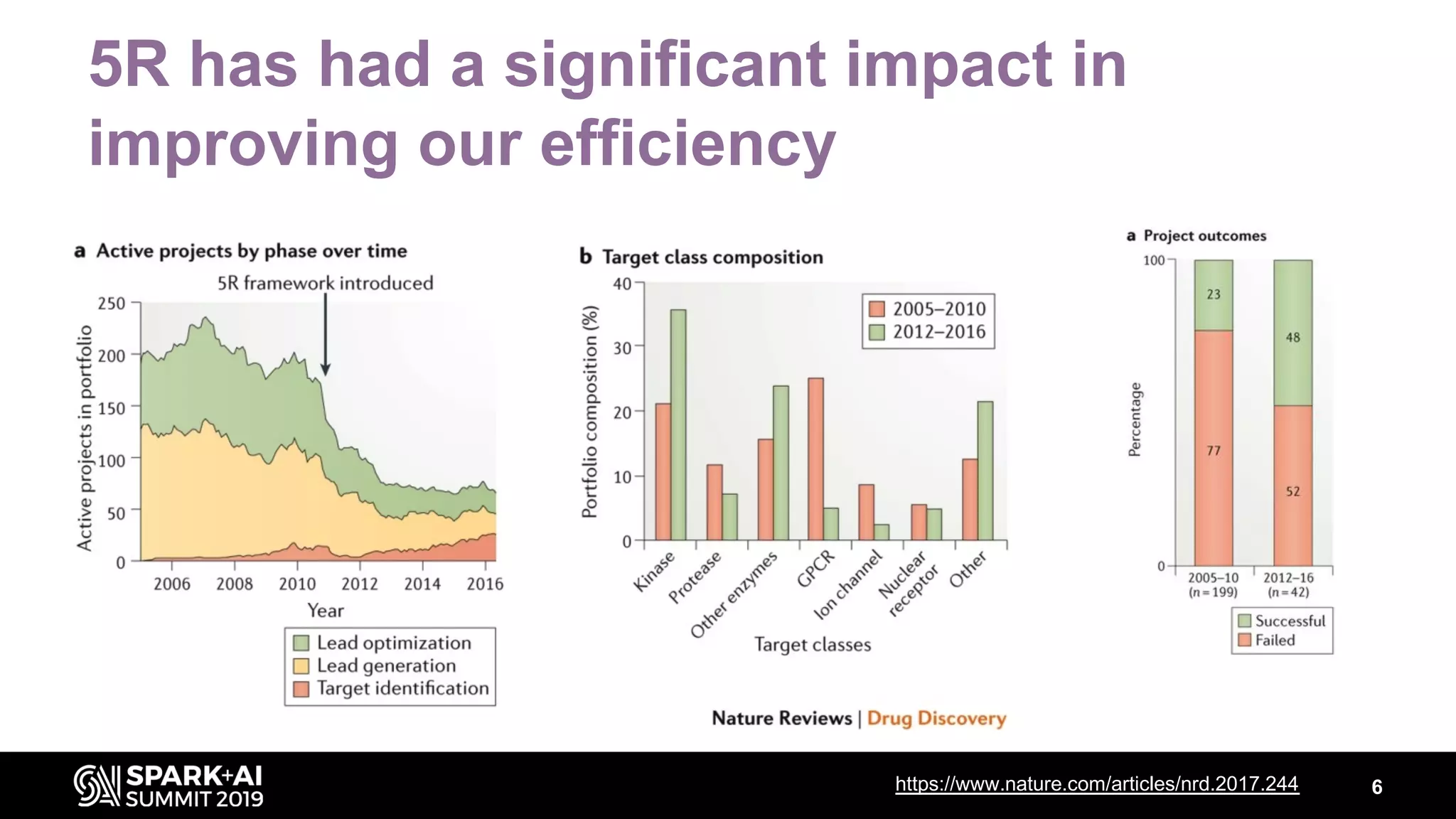
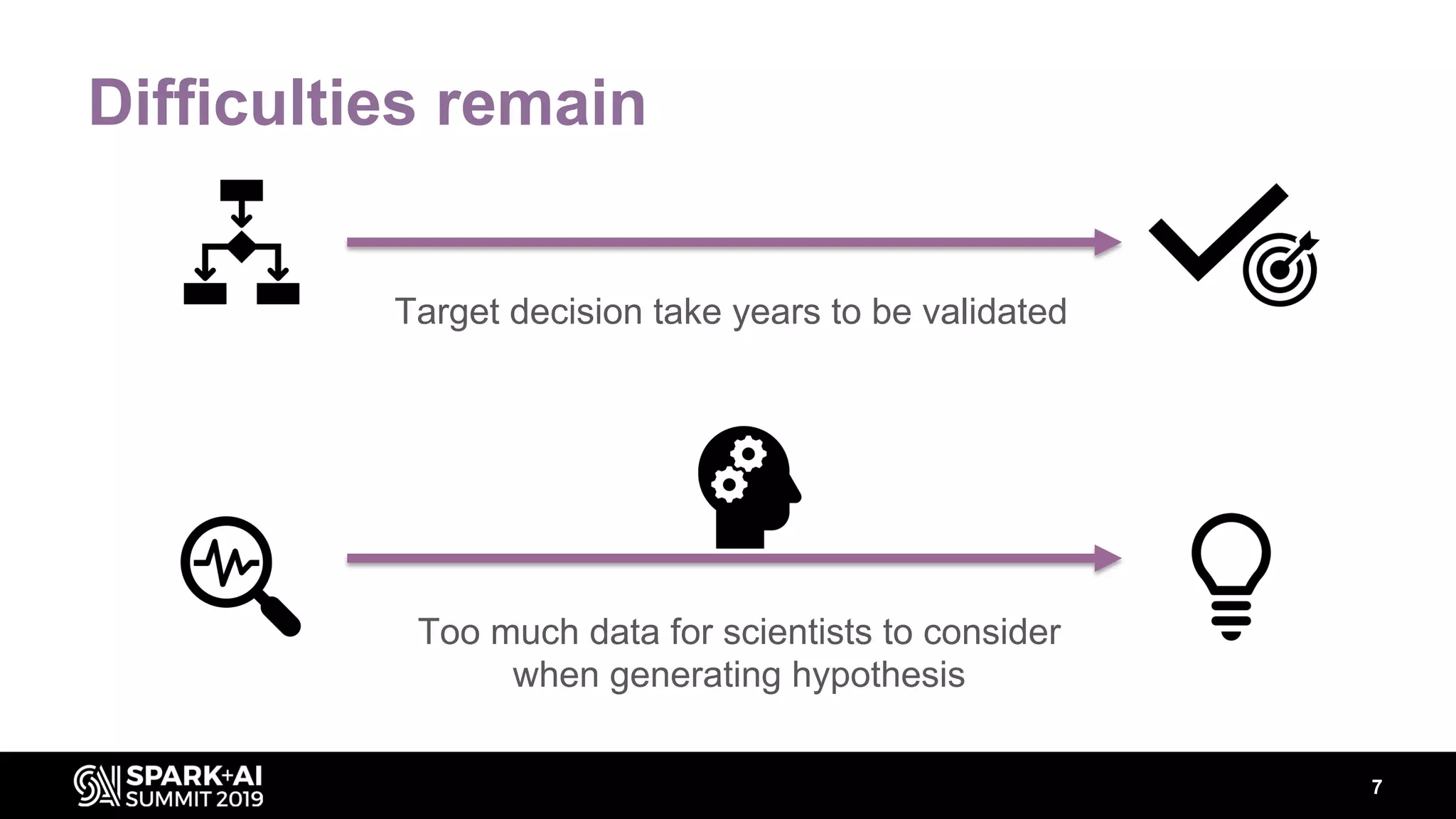


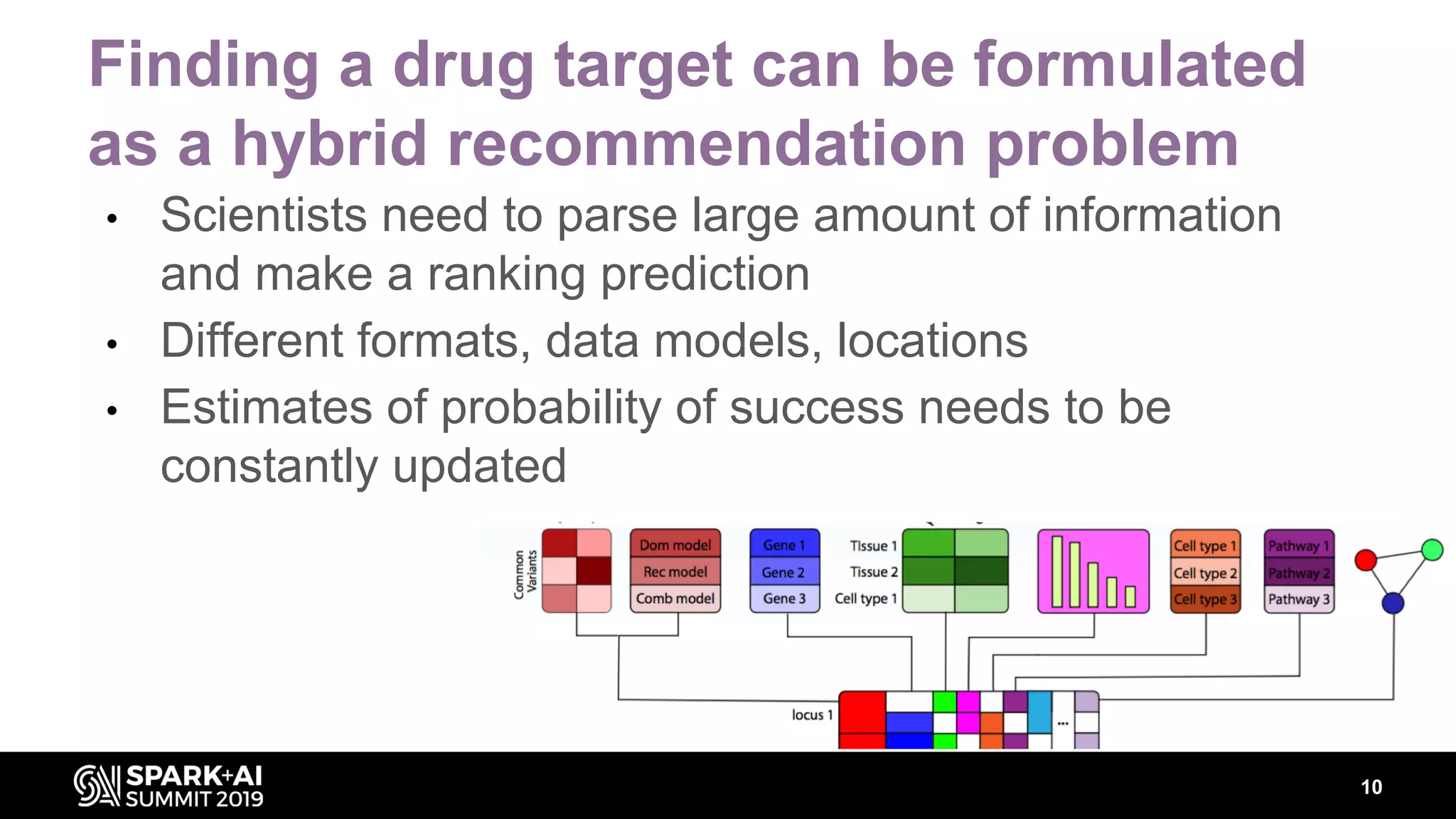
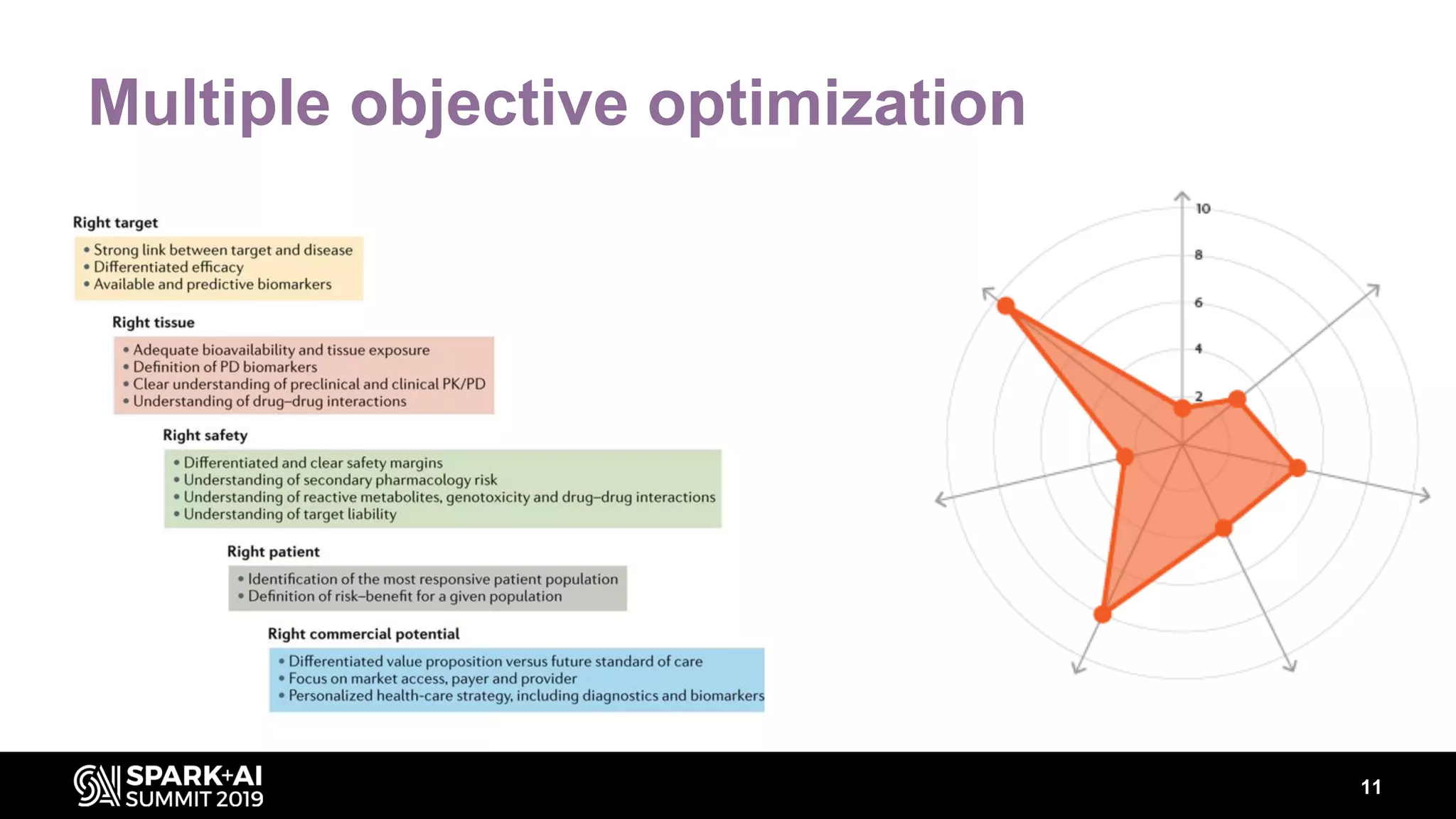

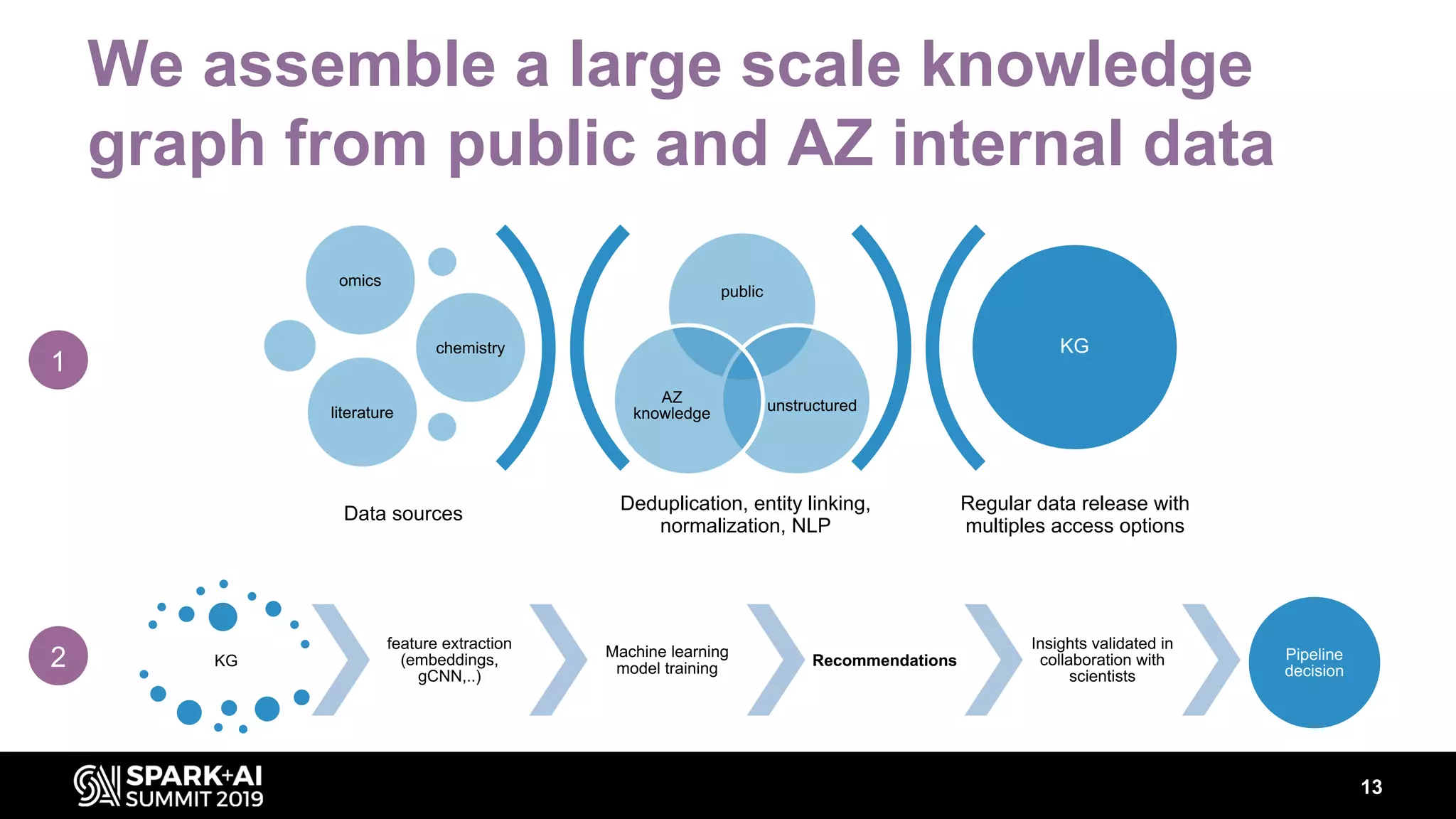
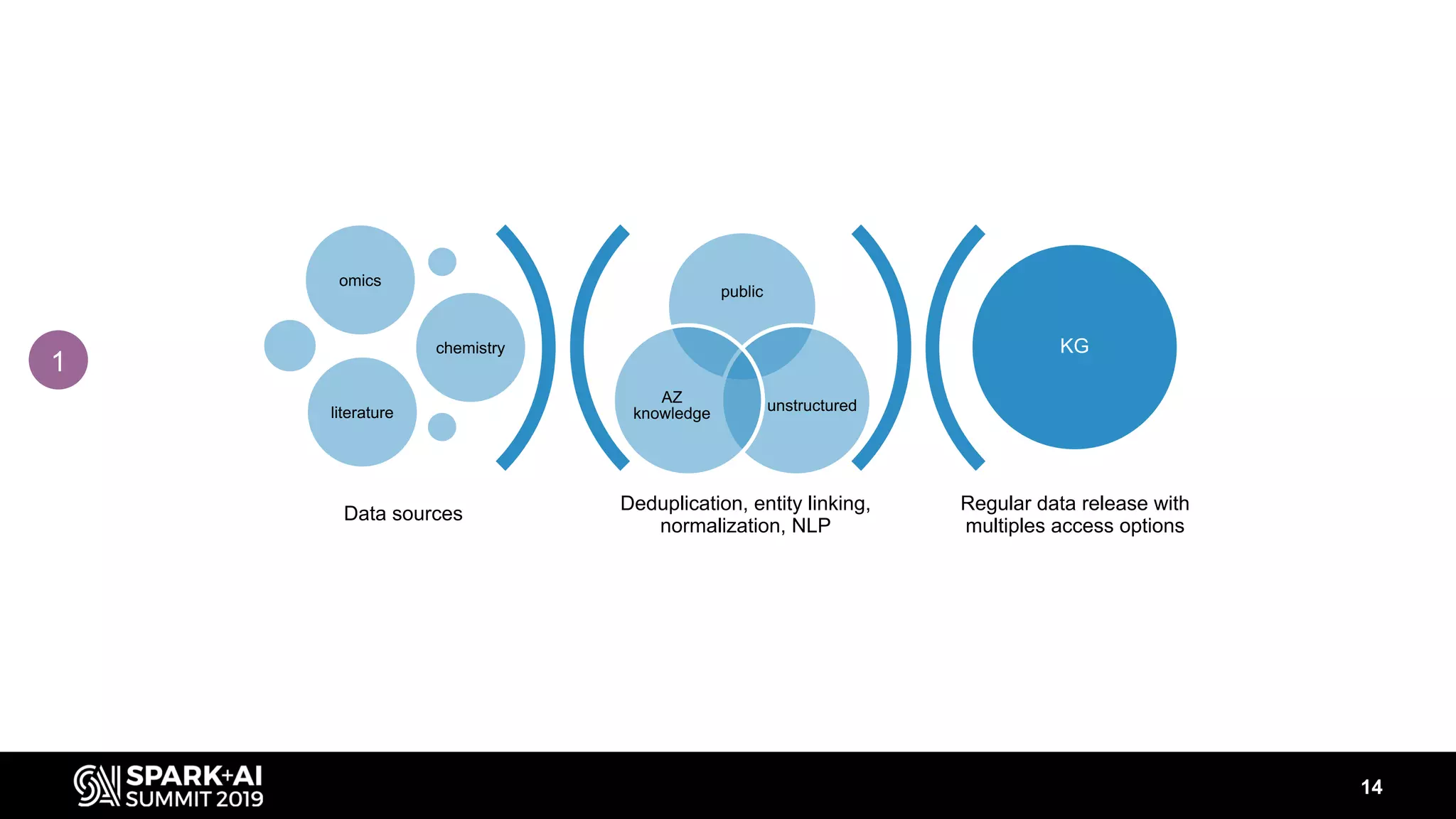
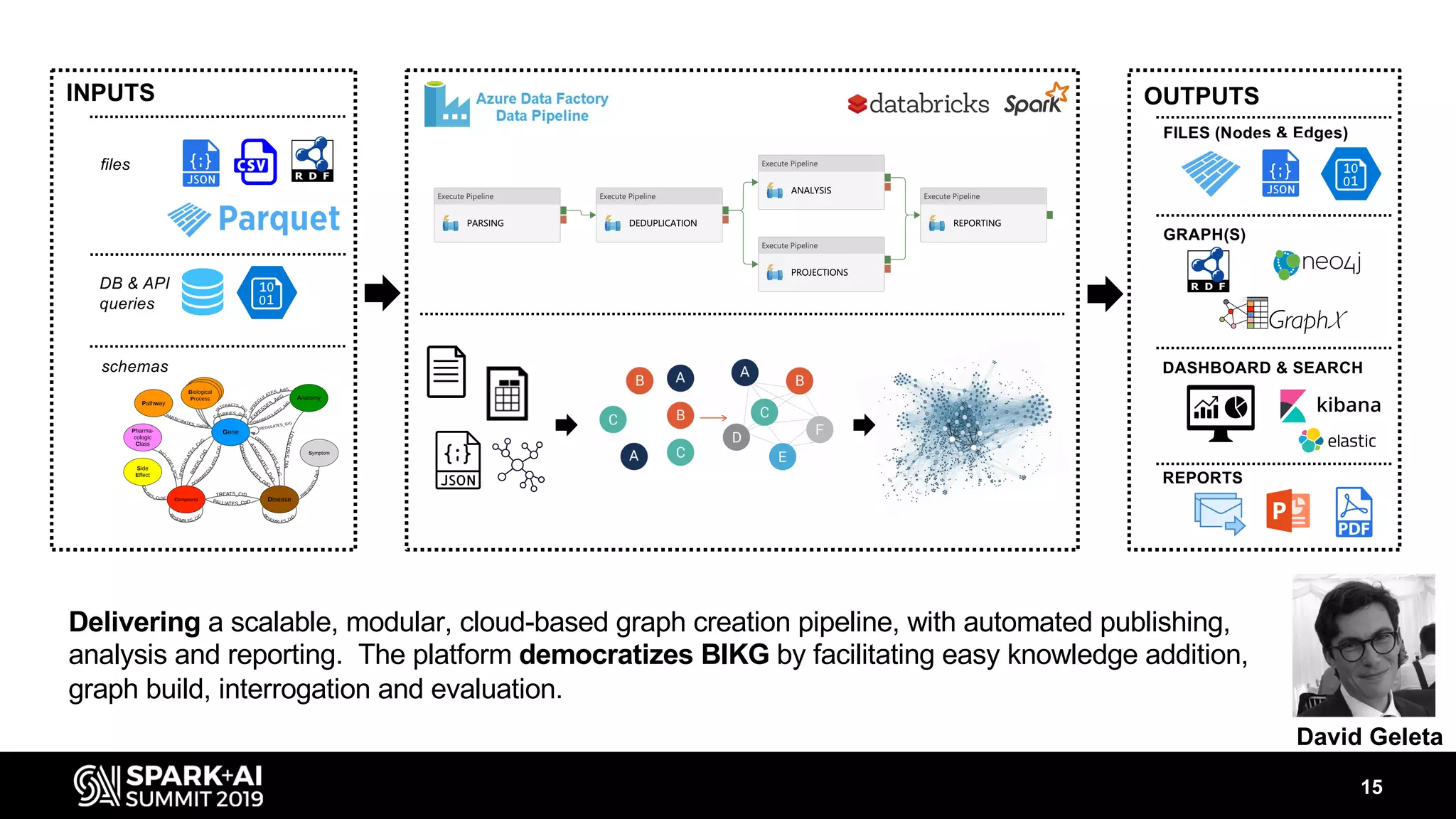







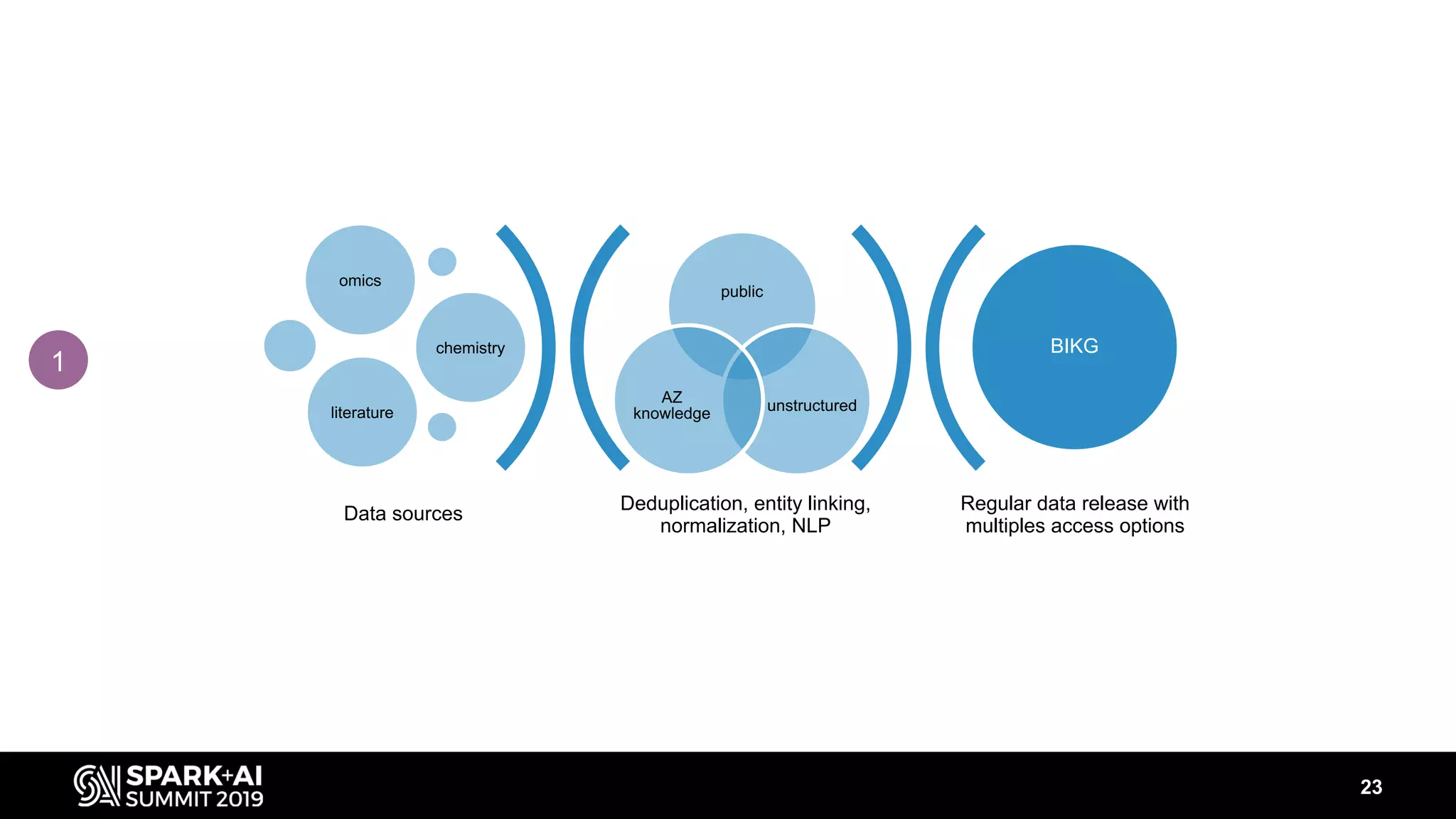

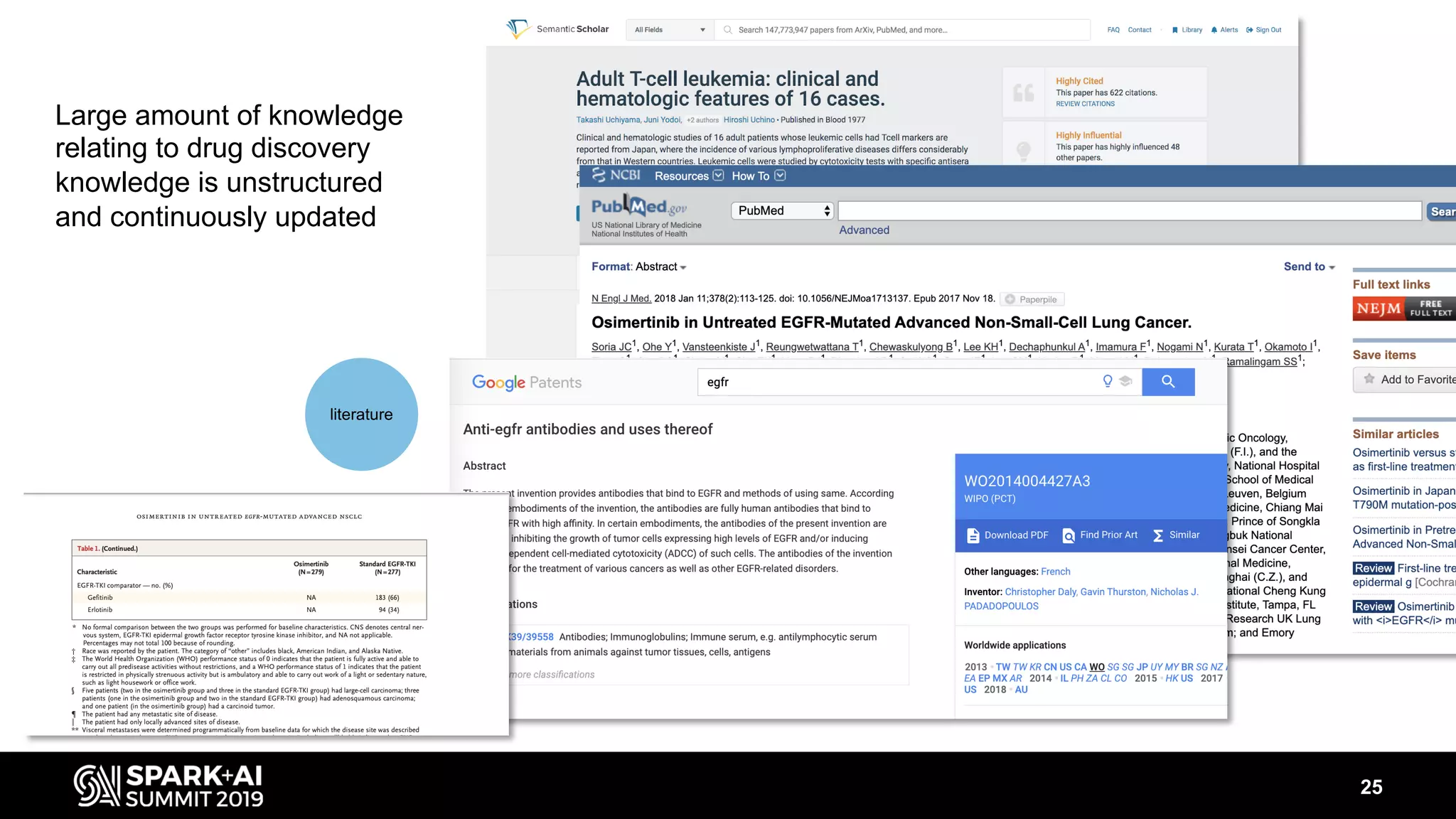
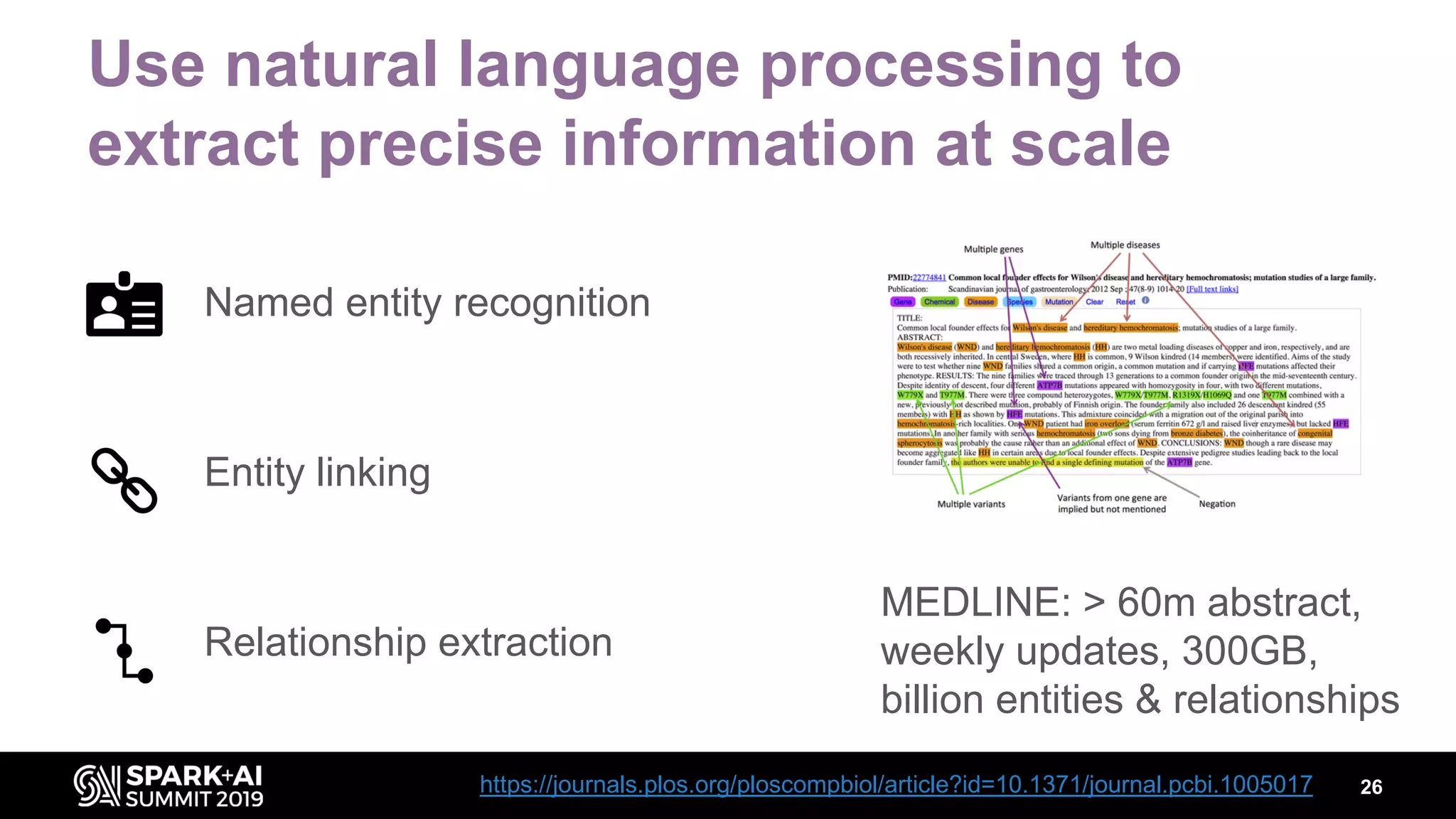
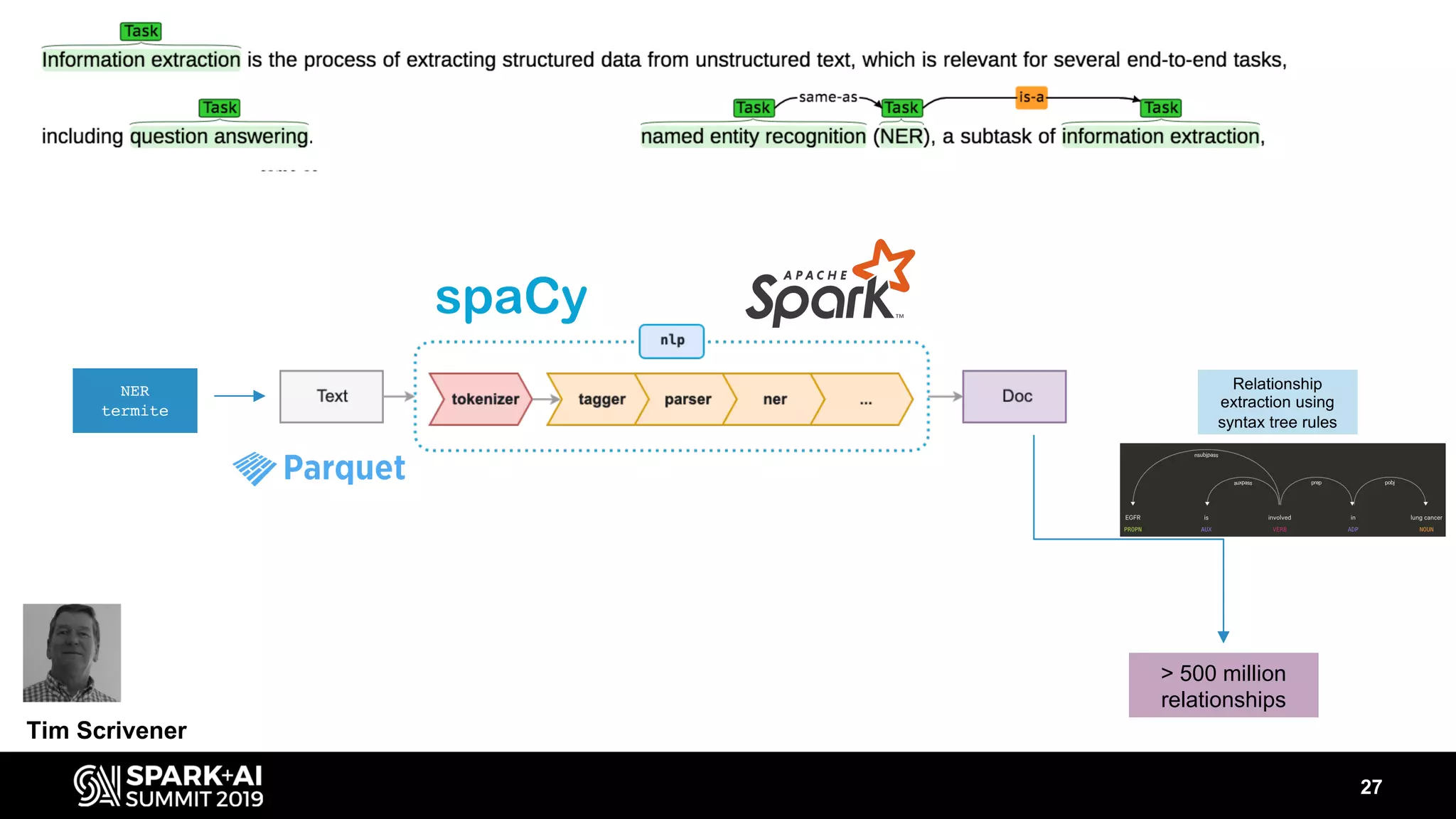

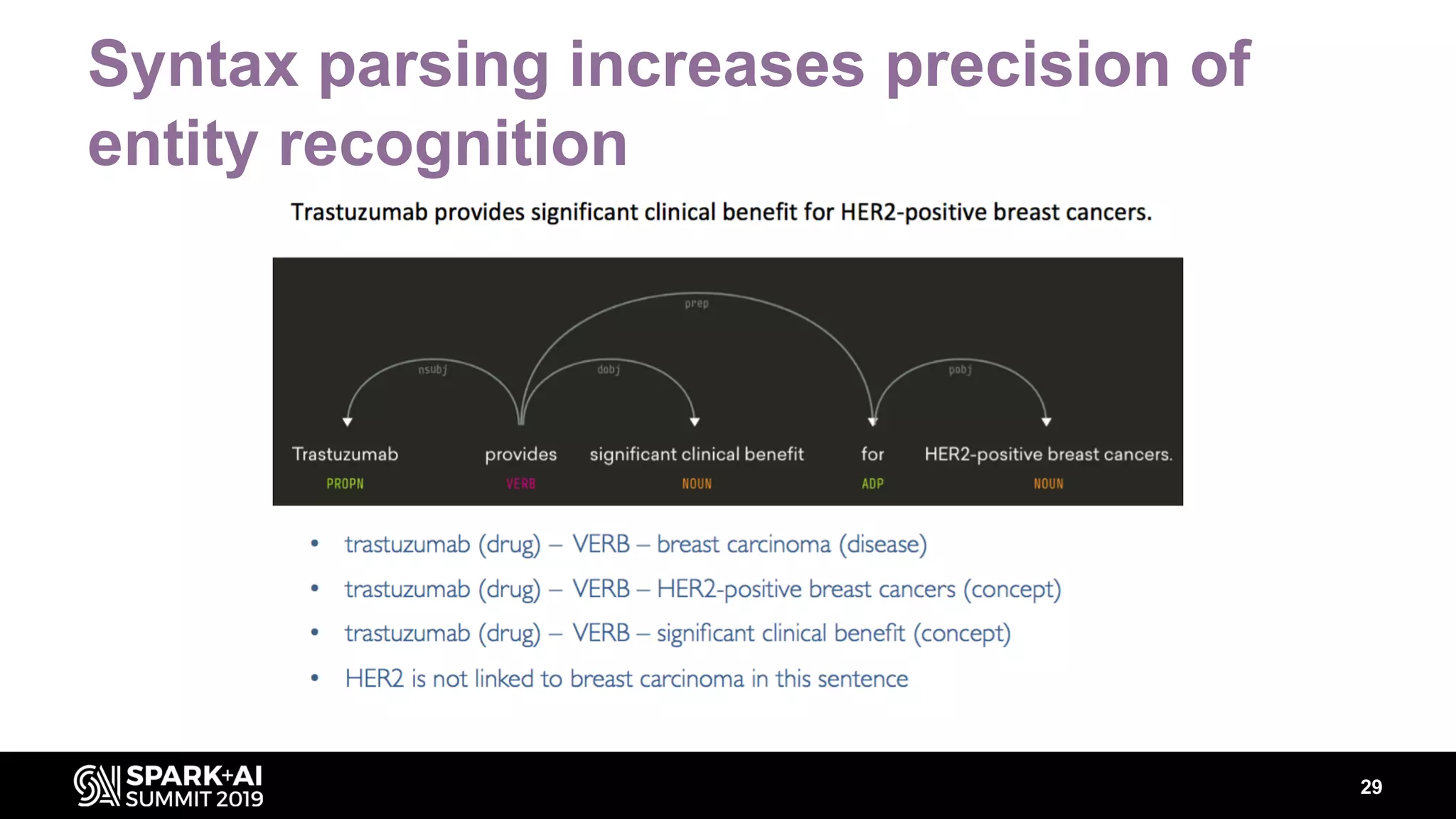
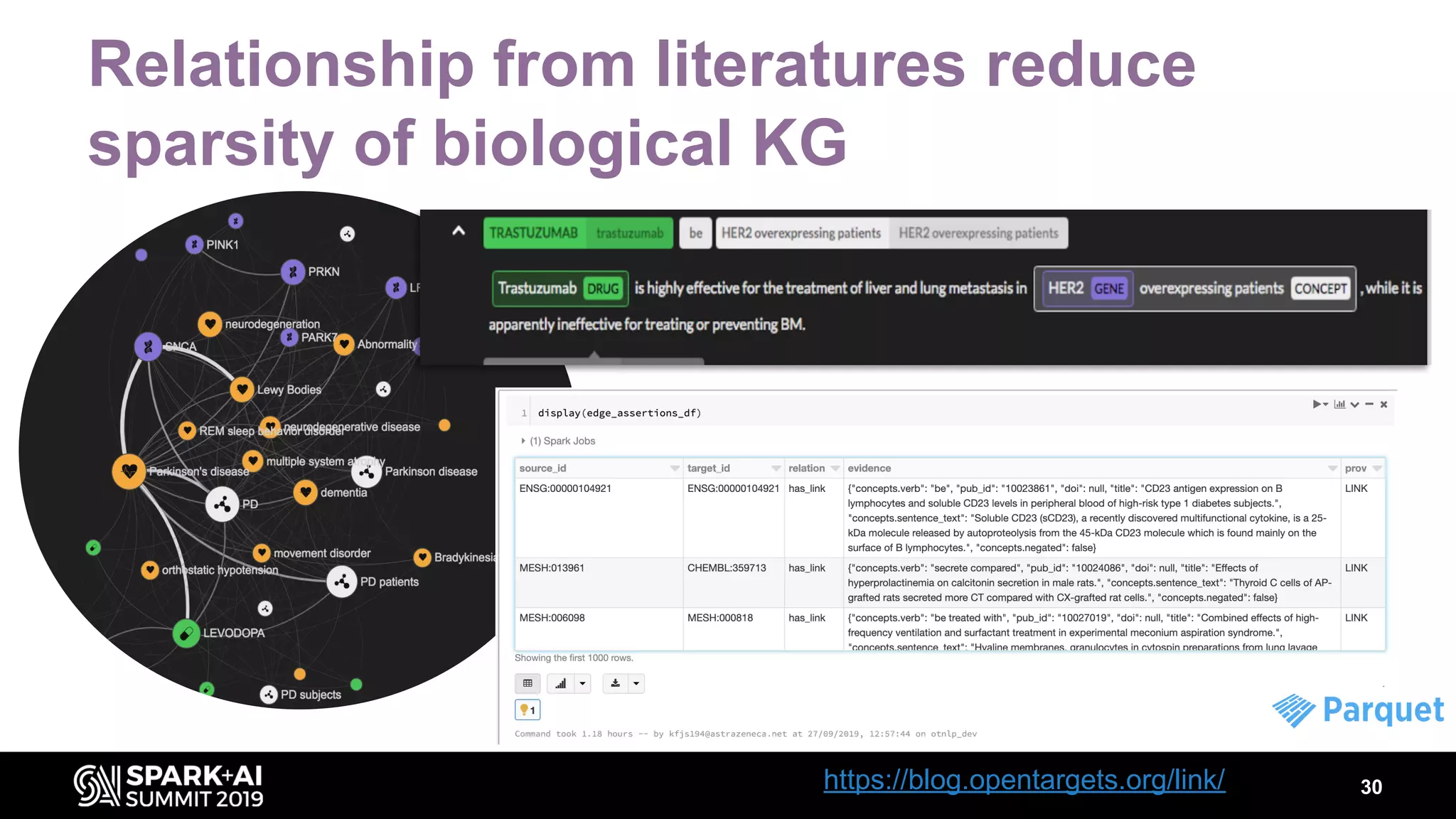
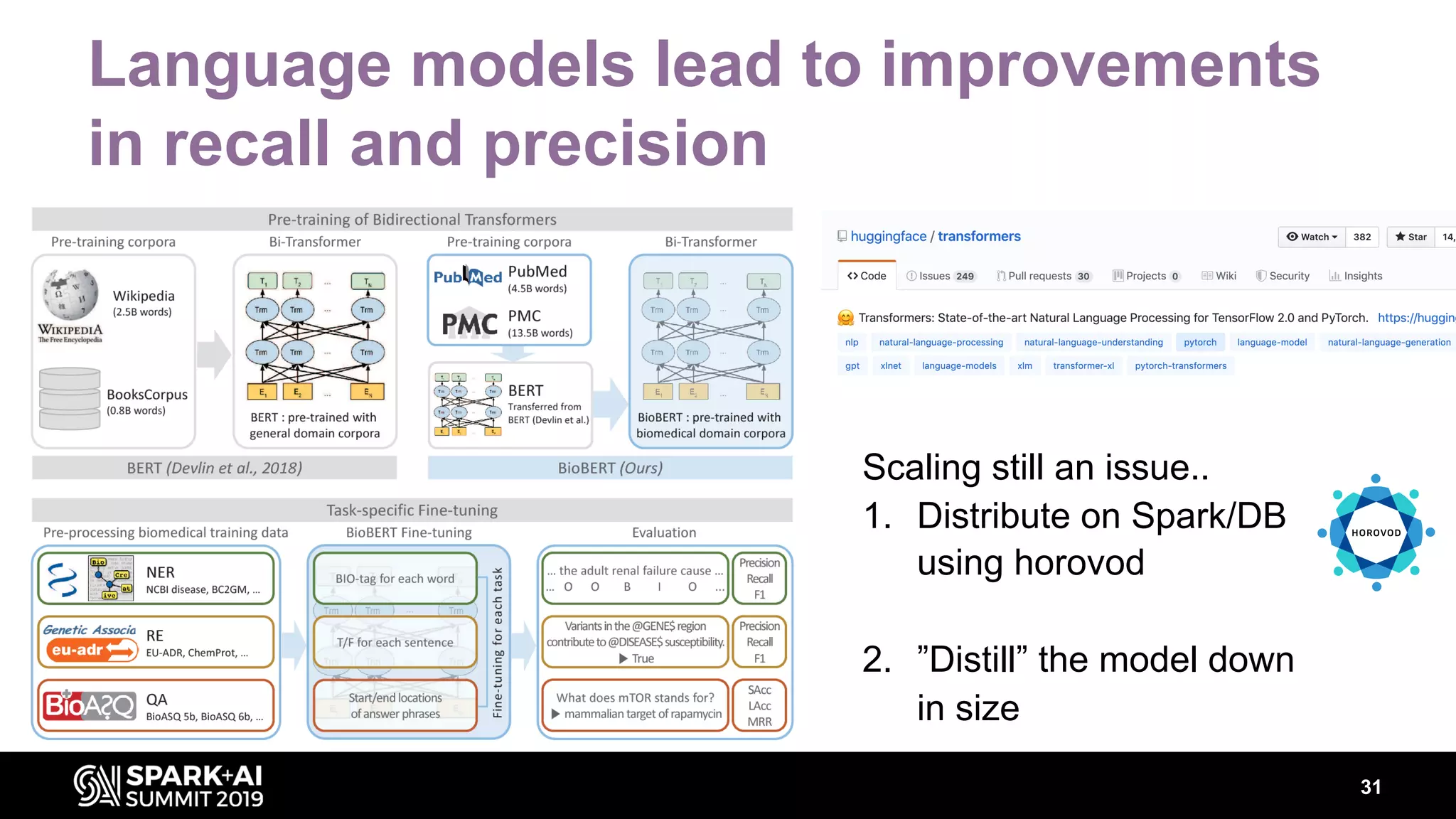
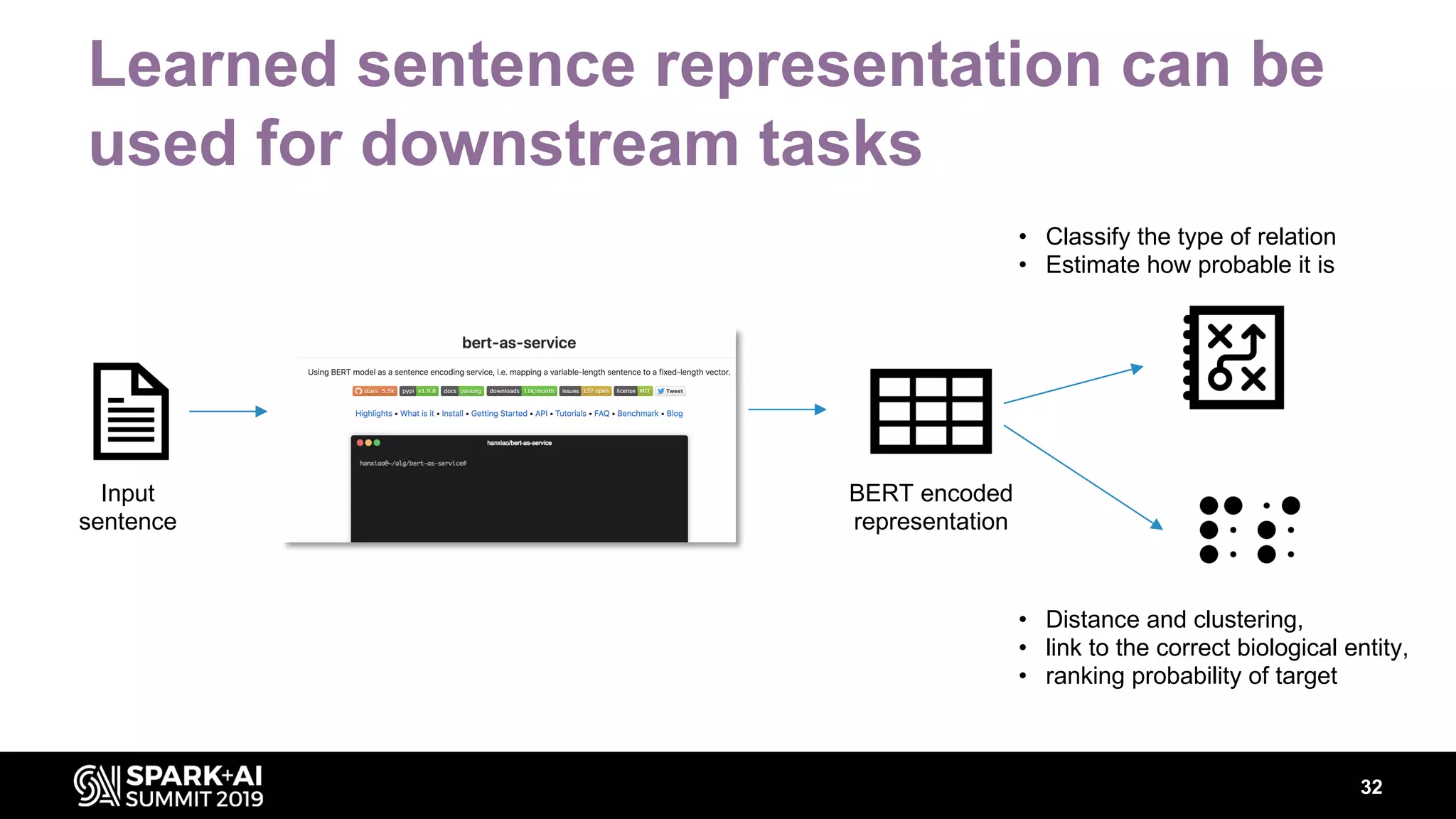
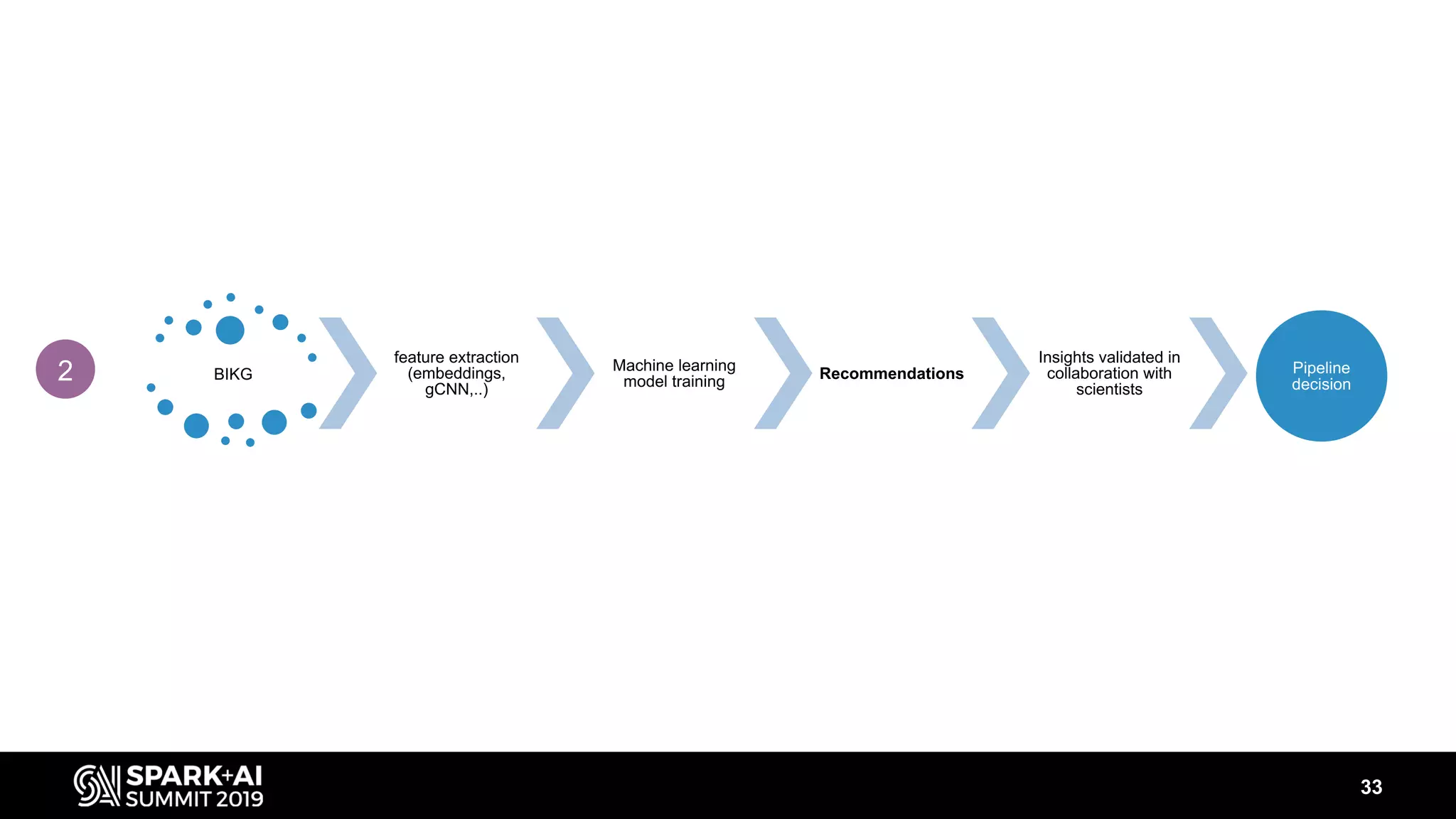
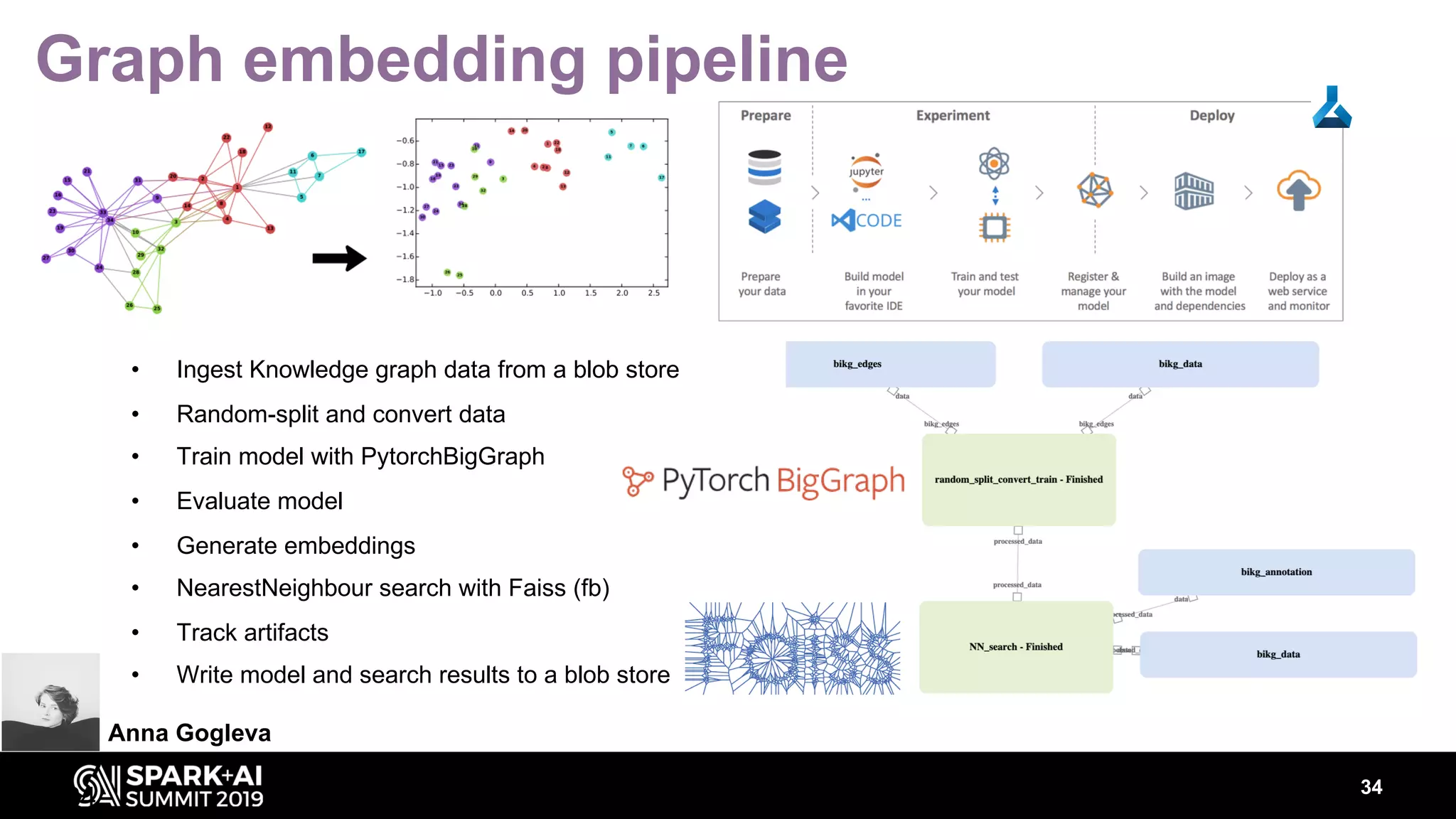





The document discusses AstraZeneca's efforts in utilizing machine learning and natural language processing to enhance drug discovery through the creation of a knowledge graph. It outlines the challenges faced in drug target identification and the proposed '5R' framework to improve decision-making efficiency. Additionally, it details the construction of a scalable cloud-based pipeline for knowledge extraction and the integration of various data sources to aid scientists in generating hypotheses.




































































![[DSC Europe 25] Jakub Stech - AI for Public Good: How Data and AI Can Transfo...](https://cdn.slidesharecdn.com/ss_thumbnails/ayuupcru6ggr9f7vbp0q-1-251215095918-7b7334a3-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Behzad Hosseini - AI Agents in the Wild: Deploying Models tha...](https://cdn.slidesharecdn.com/ss_thumbnails/3qtejajvsjqrzwfept2c-10-251212103250-7f2b1068-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Uros Pesic - The Reality of AI in Marketing.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/rtkodnmtycovsllvzsyn-9-251215095918-b0c6bfe3-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DSC Europe 25] Tatevik Maytesyan - How to actually use AI in marketing: gett...](https://cdn.slidesharecdn.com/ss_thumbnails/tjo626lsqdgfntbgl2mw-4-251216103155-e36cd239-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Dobrica Cosic - From Electrons to Innovation: How Granular Da...](https://cdn.slidesharecdn.com/ss_thumbnails/h4qk69zereaumbceubgr-dobrica-cosic-from-electrons-to-innovation-how-granular-data-and-analytics-are--251218085301-b982fb14-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Djordje Hirs - Revolutionizing Telco Customer Experience with...](https://cdn.slidesharecdn.com/ss_thumbnails/zif75aur3qscnckv6tnc-djordje-hirs-cc-dsc2025-1-251219145617-679178aa-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Ivan Peric - Intelligence Swarm Logic and Techno-Functional M...](https://cdn.slidesharecdn.com/ss_thumbnails/7my7c97fsduiccadgavw-2-251212103249-5a03f7c6-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Miodrag Pesovic & Vladislav Radonjic - Federated Data Archite...](https://cdn.slidesharecdn.com/ss_thumbnails/gsbe3y5it5uhndi4e08e-1-251212103249-f1008e0c-thumbnail.jpg?width=640&height=640&fit=bounds)