

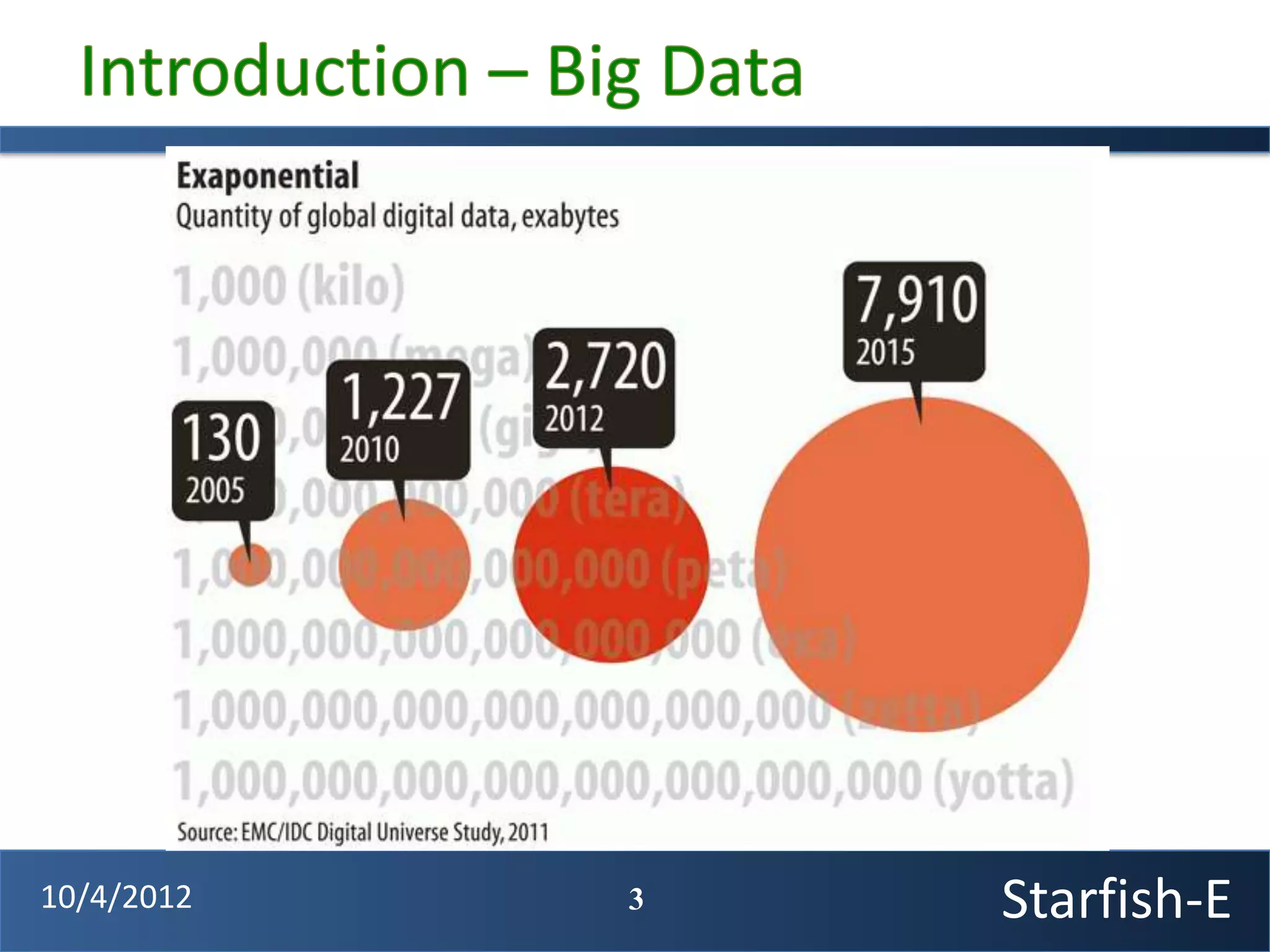
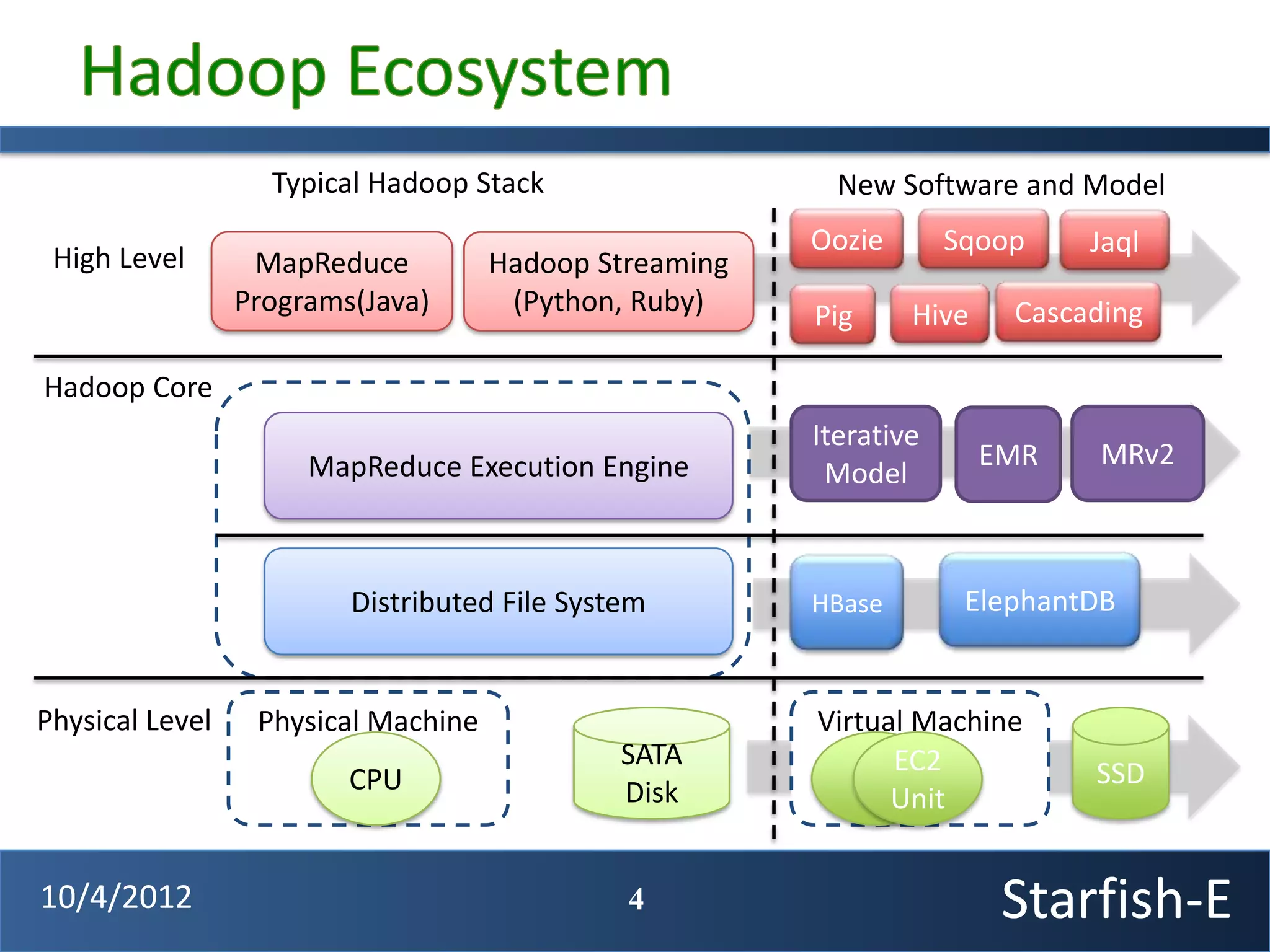
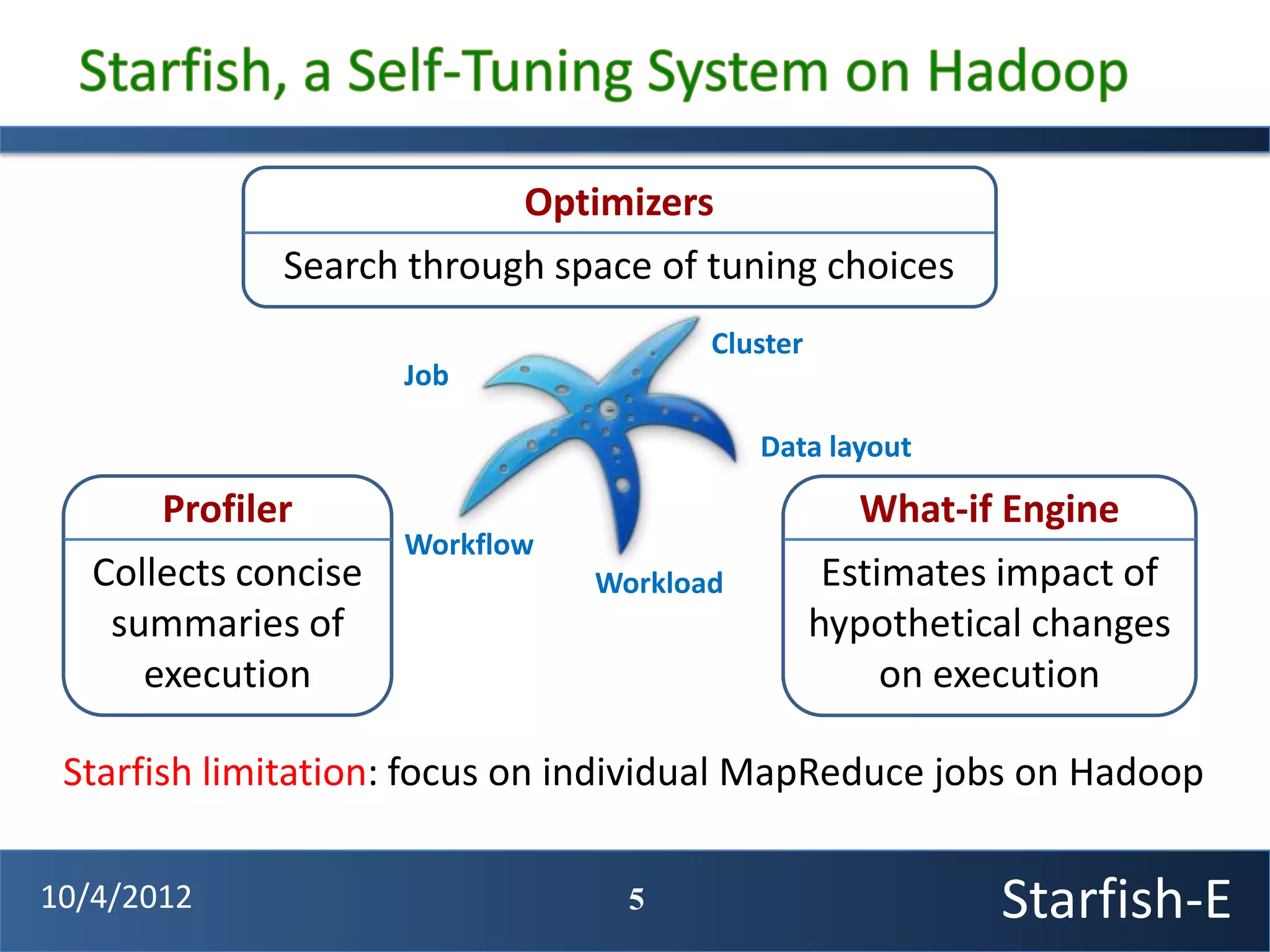


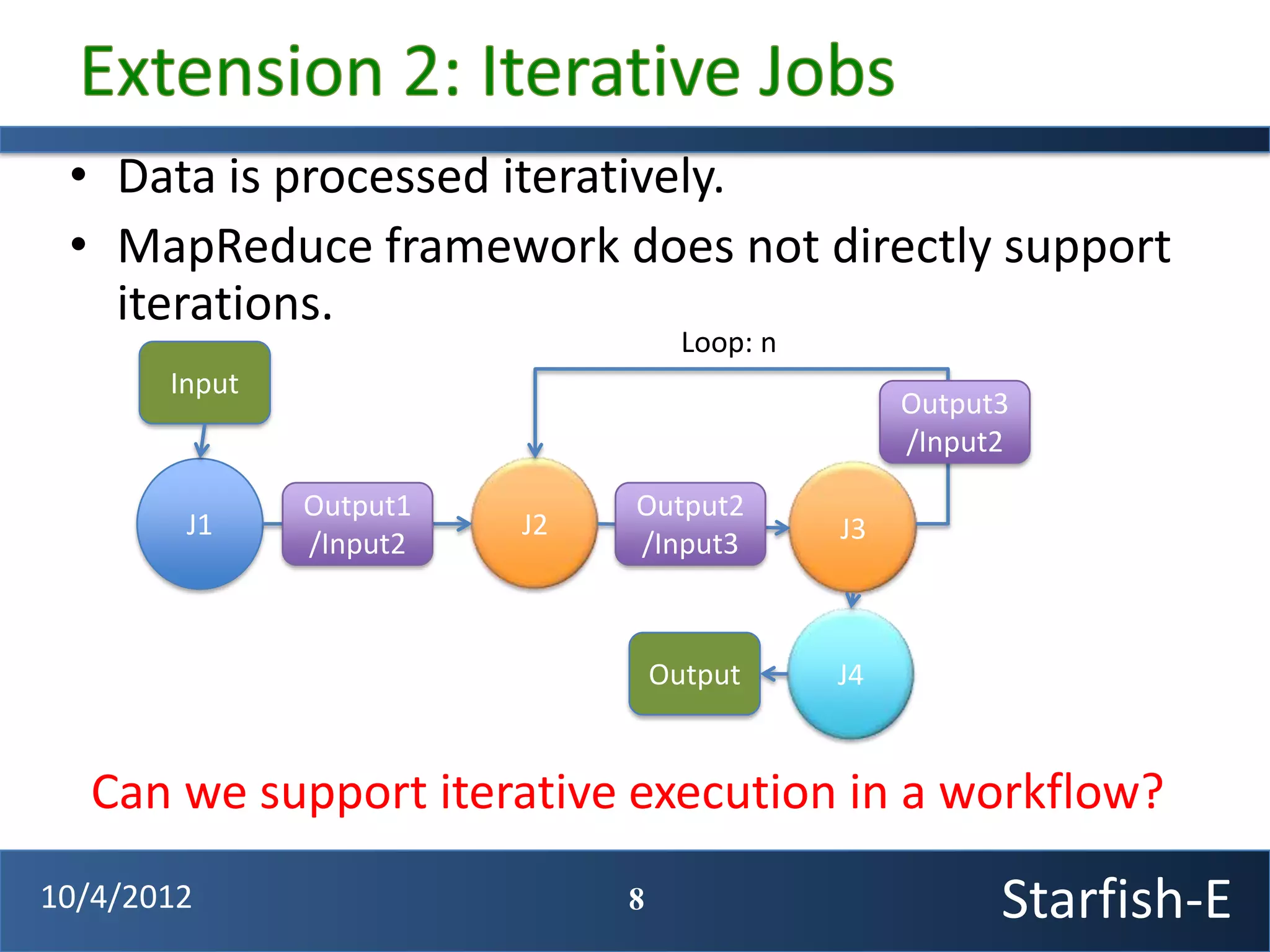



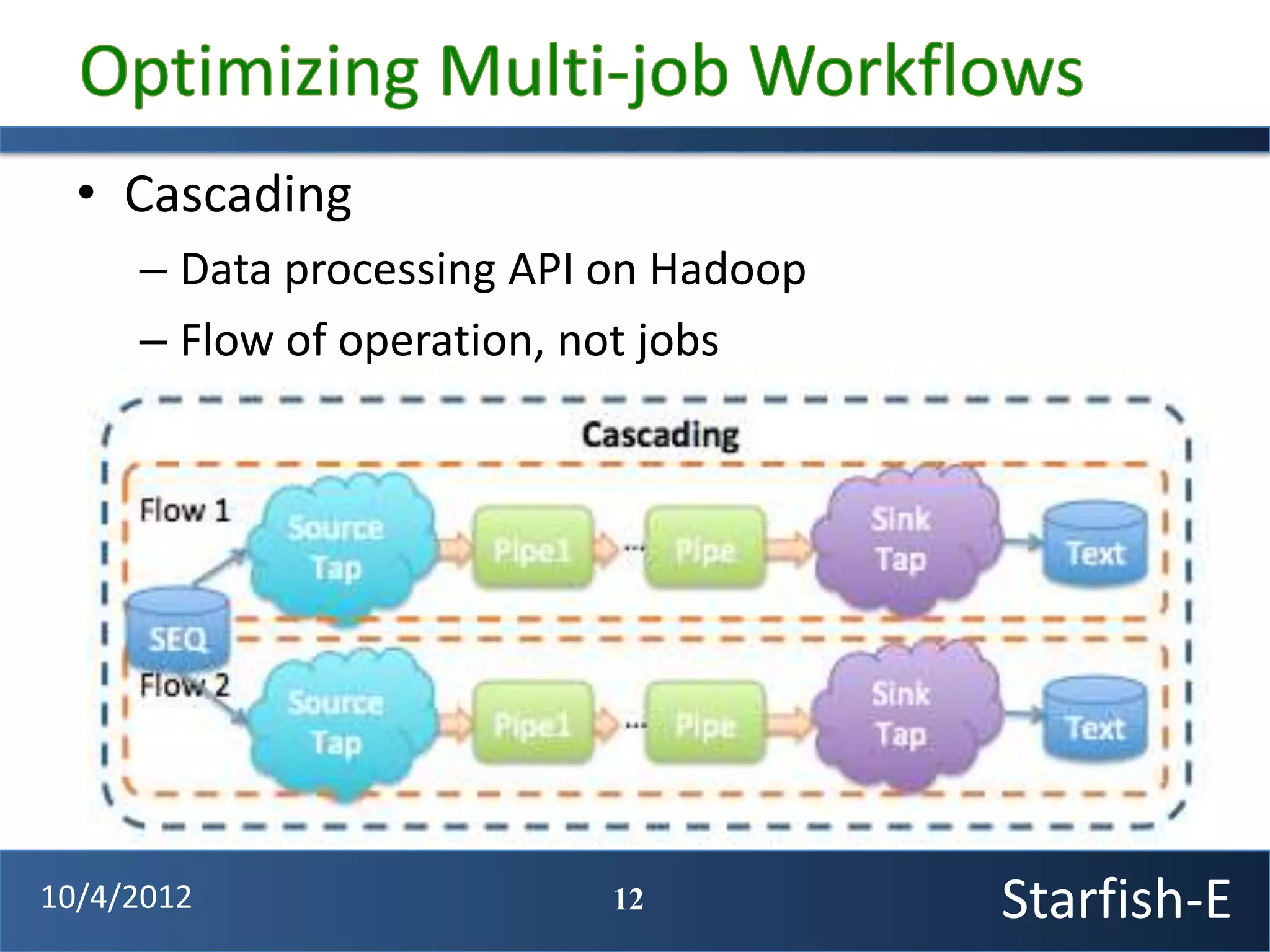

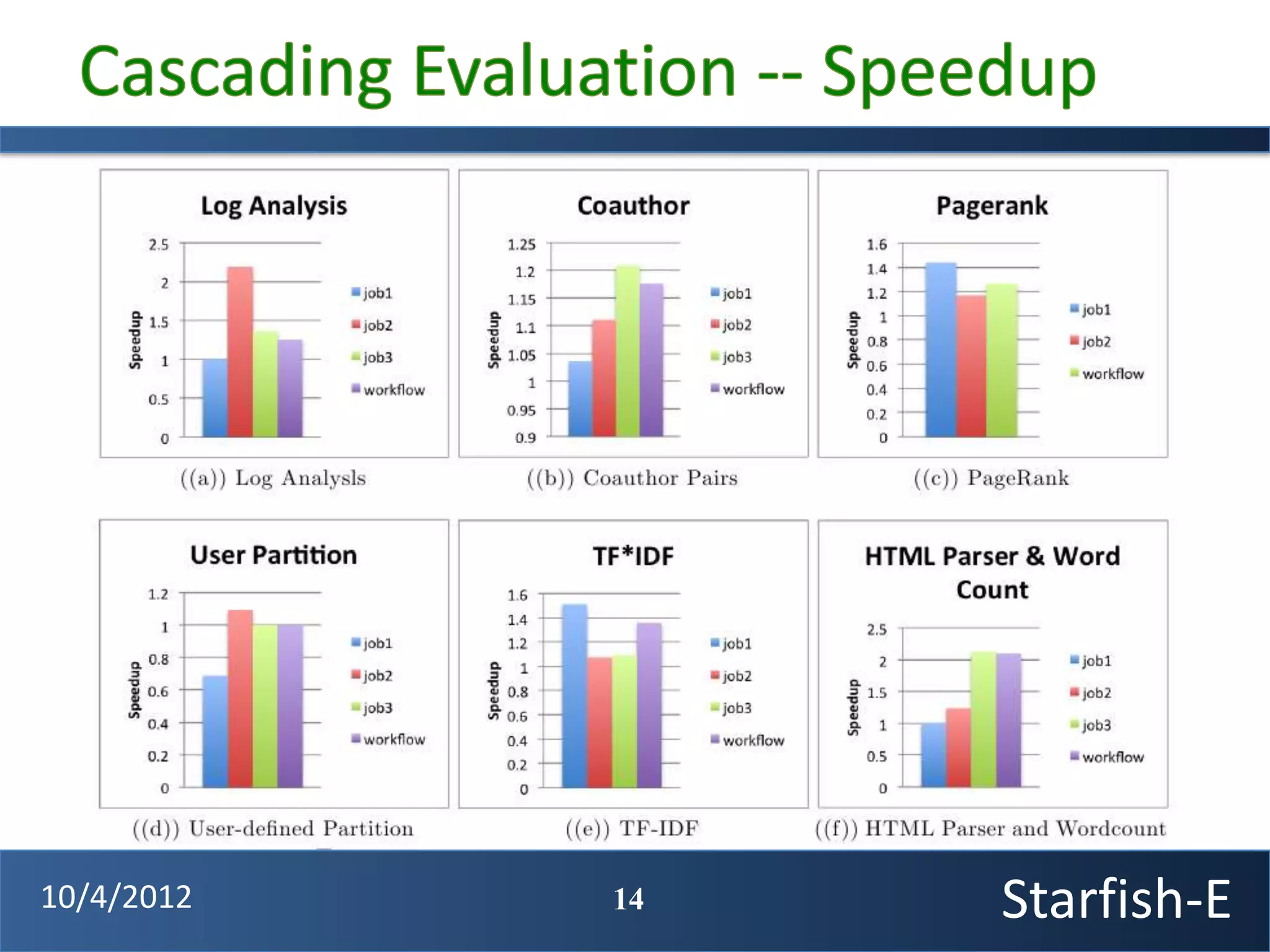
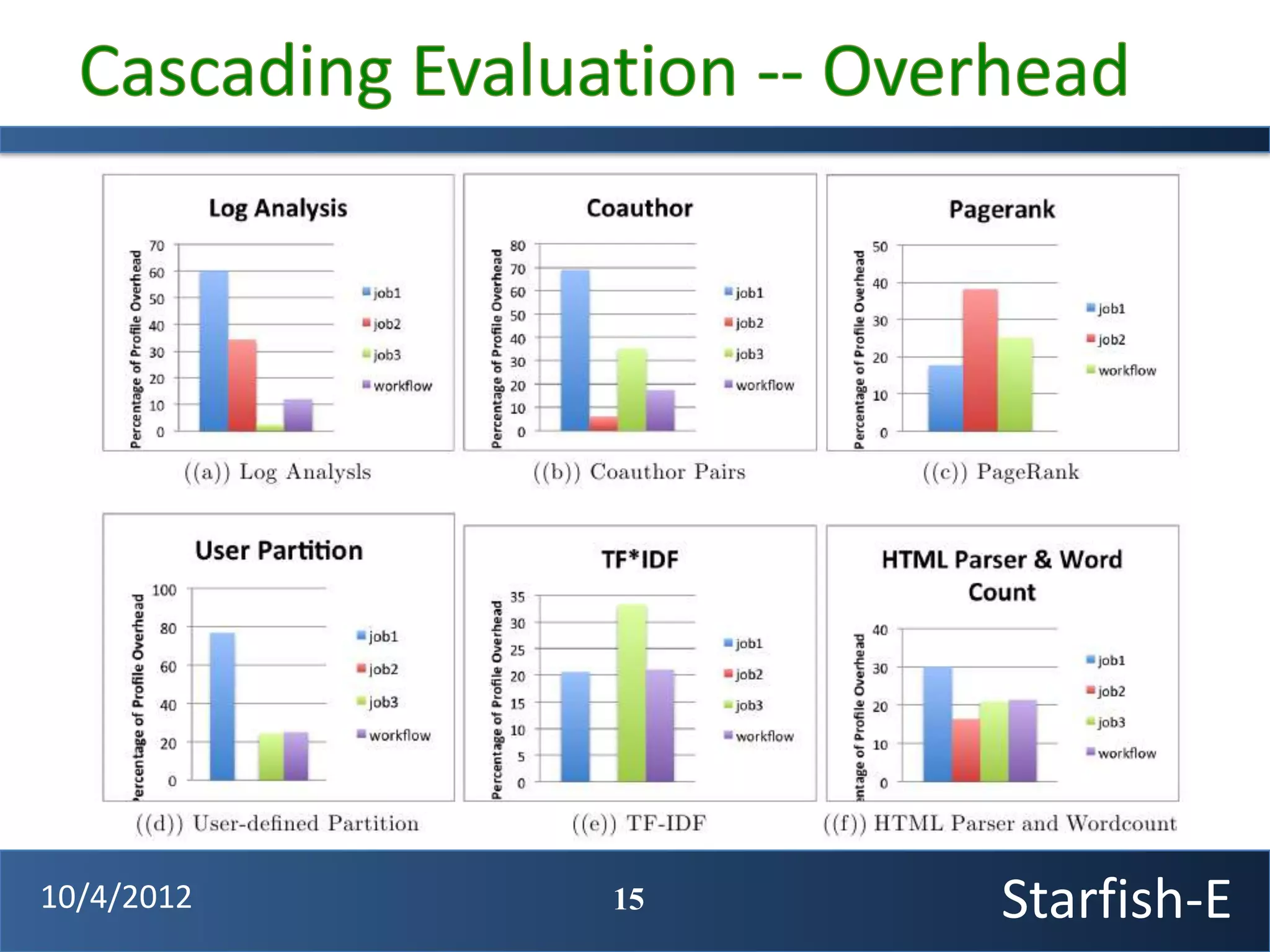

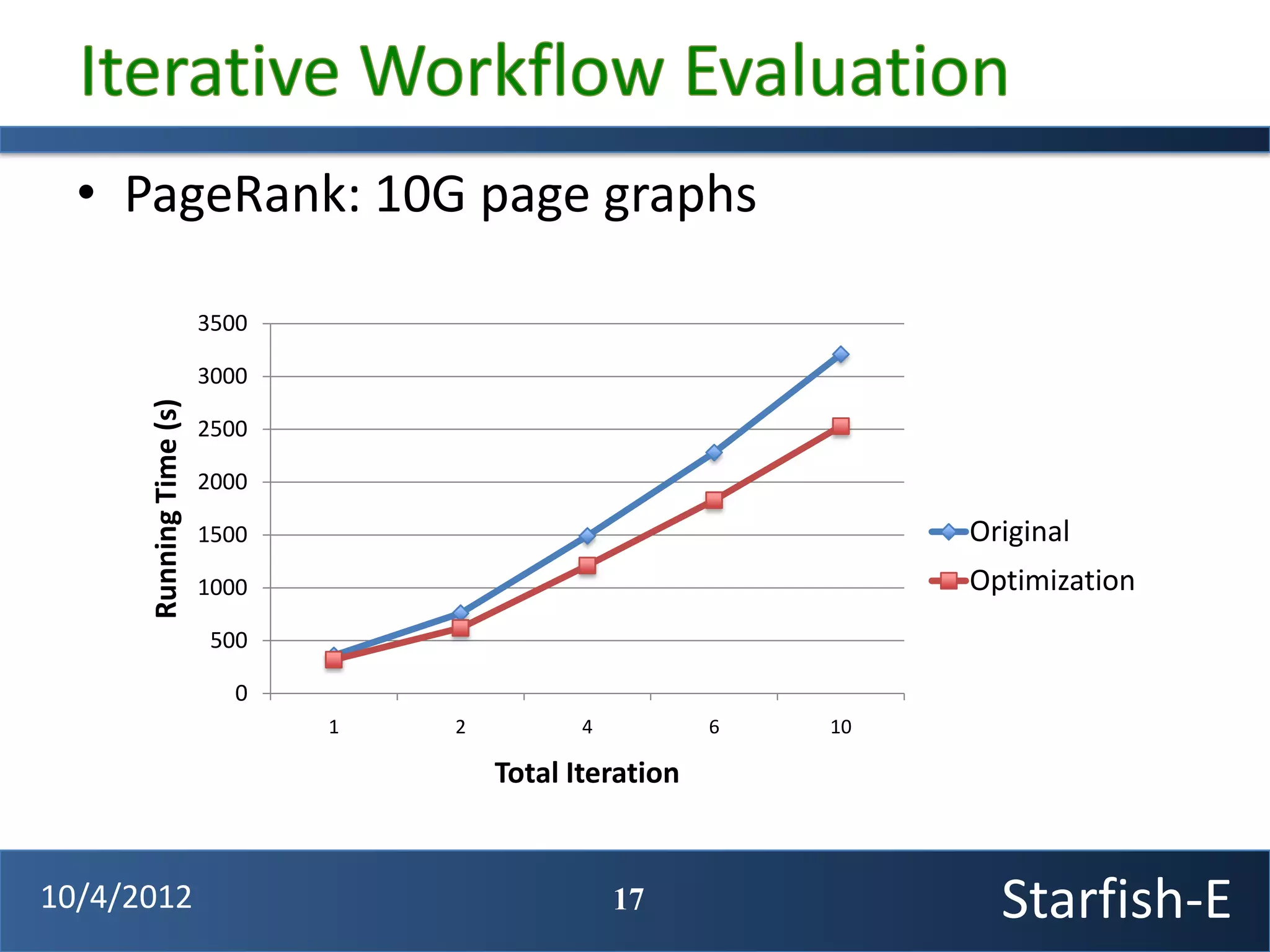
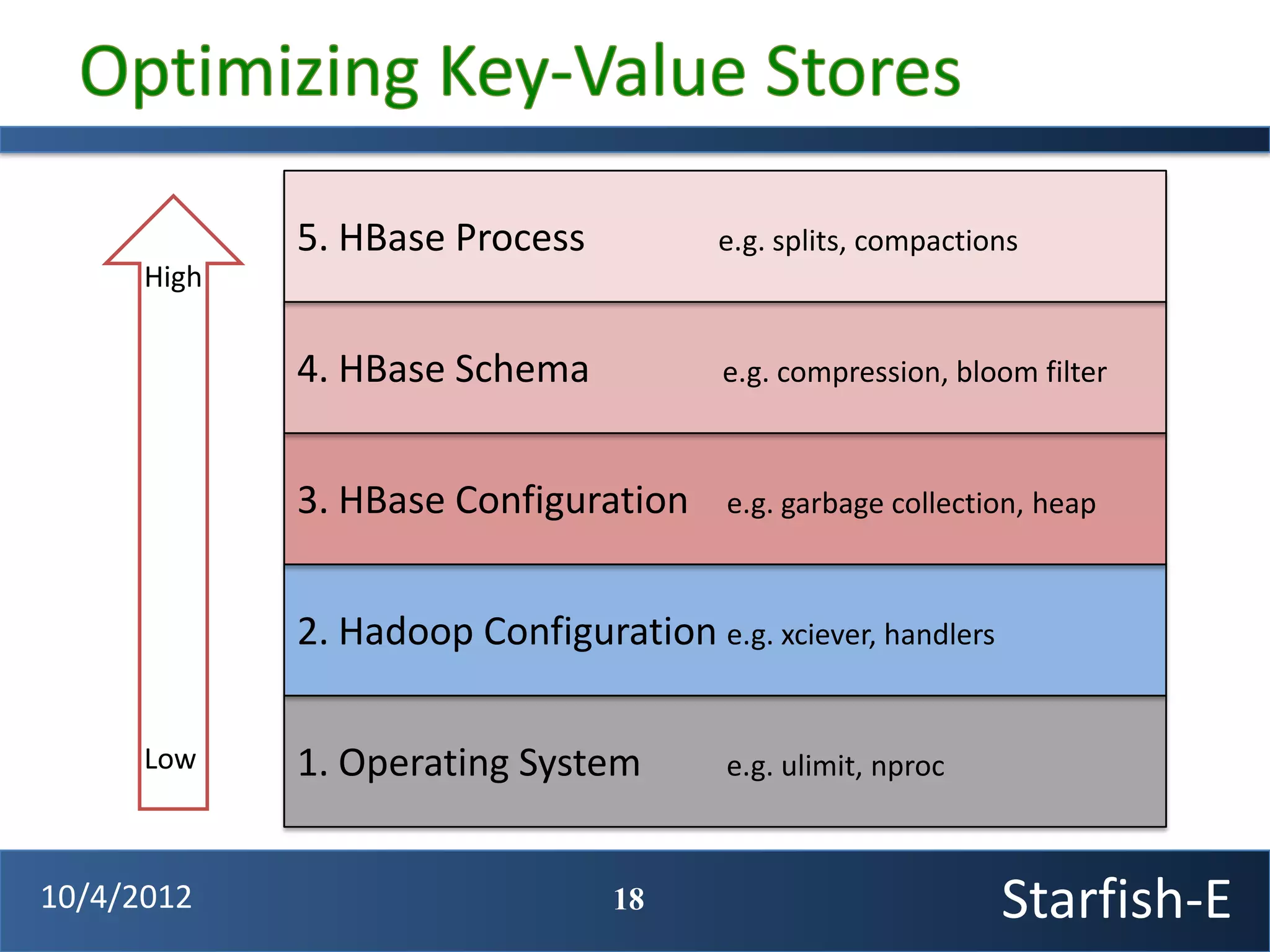


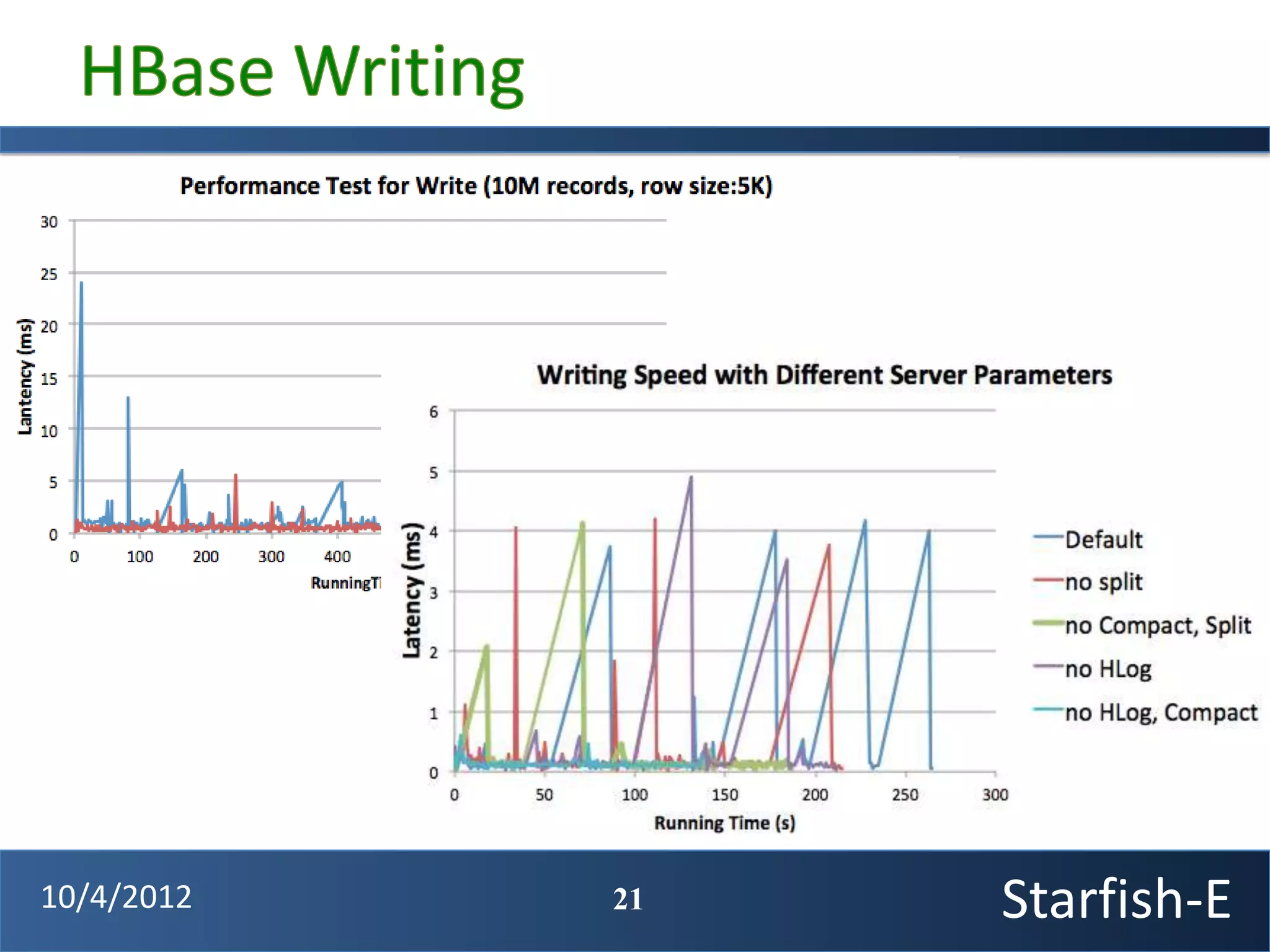
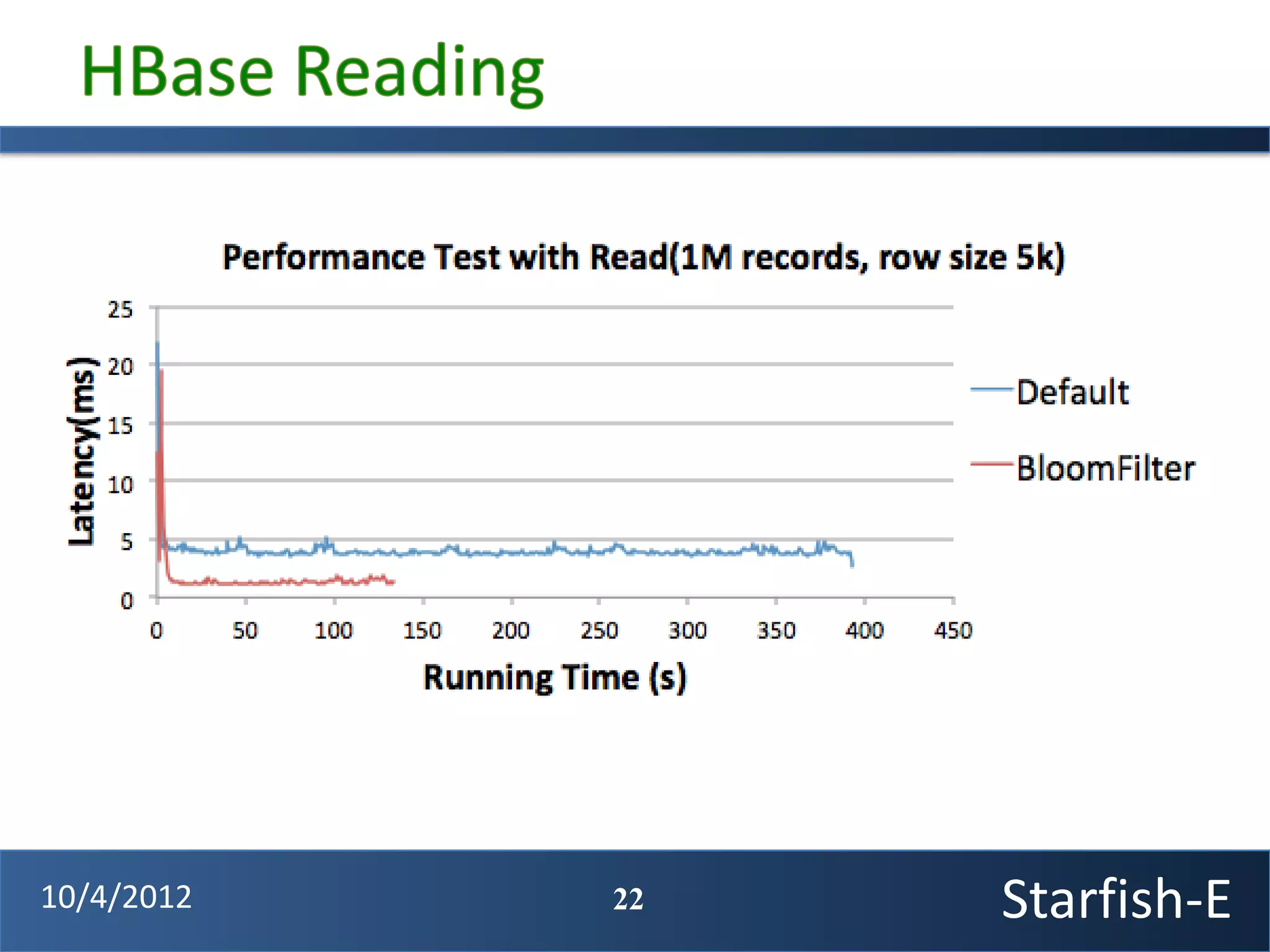


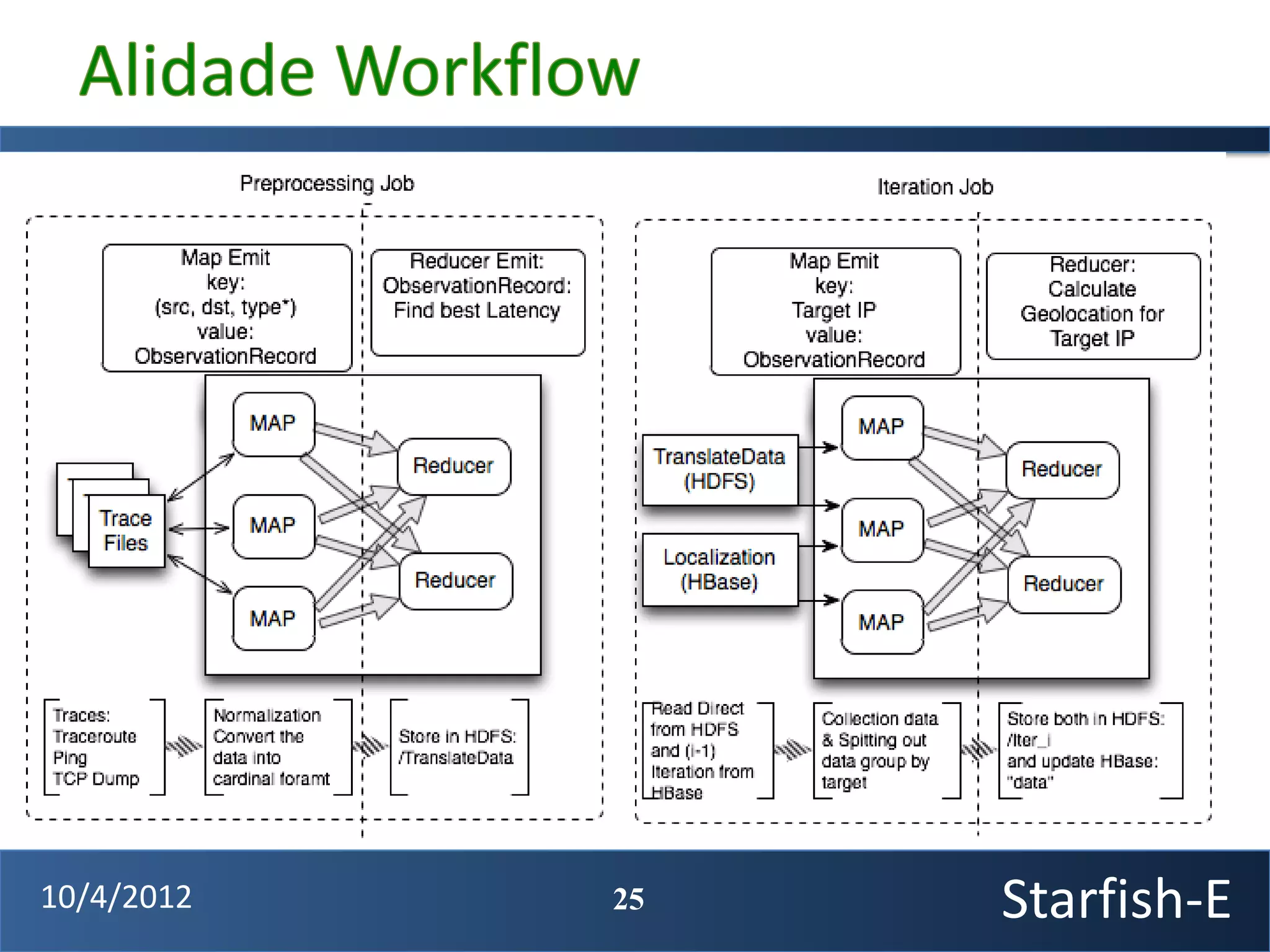


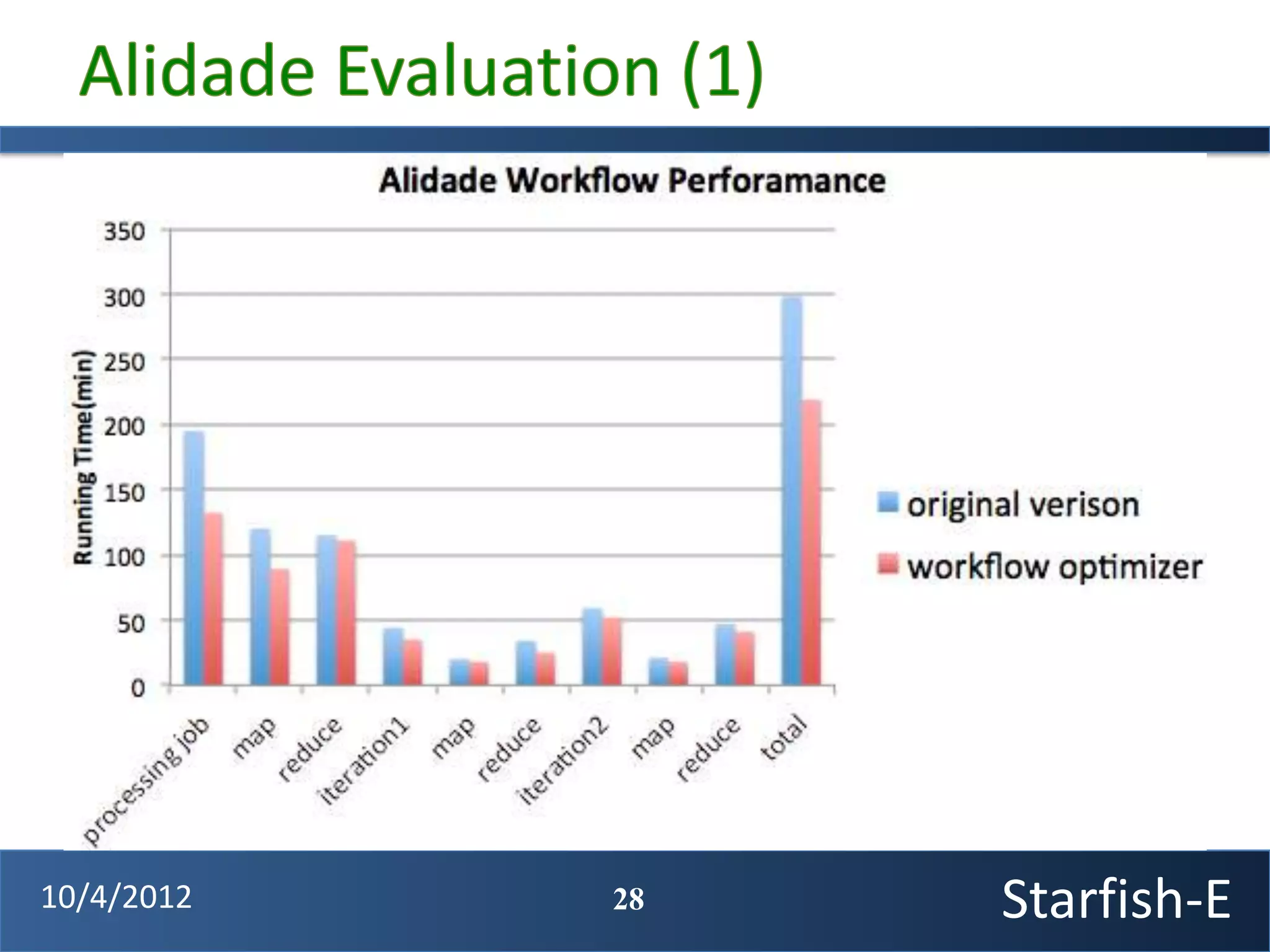
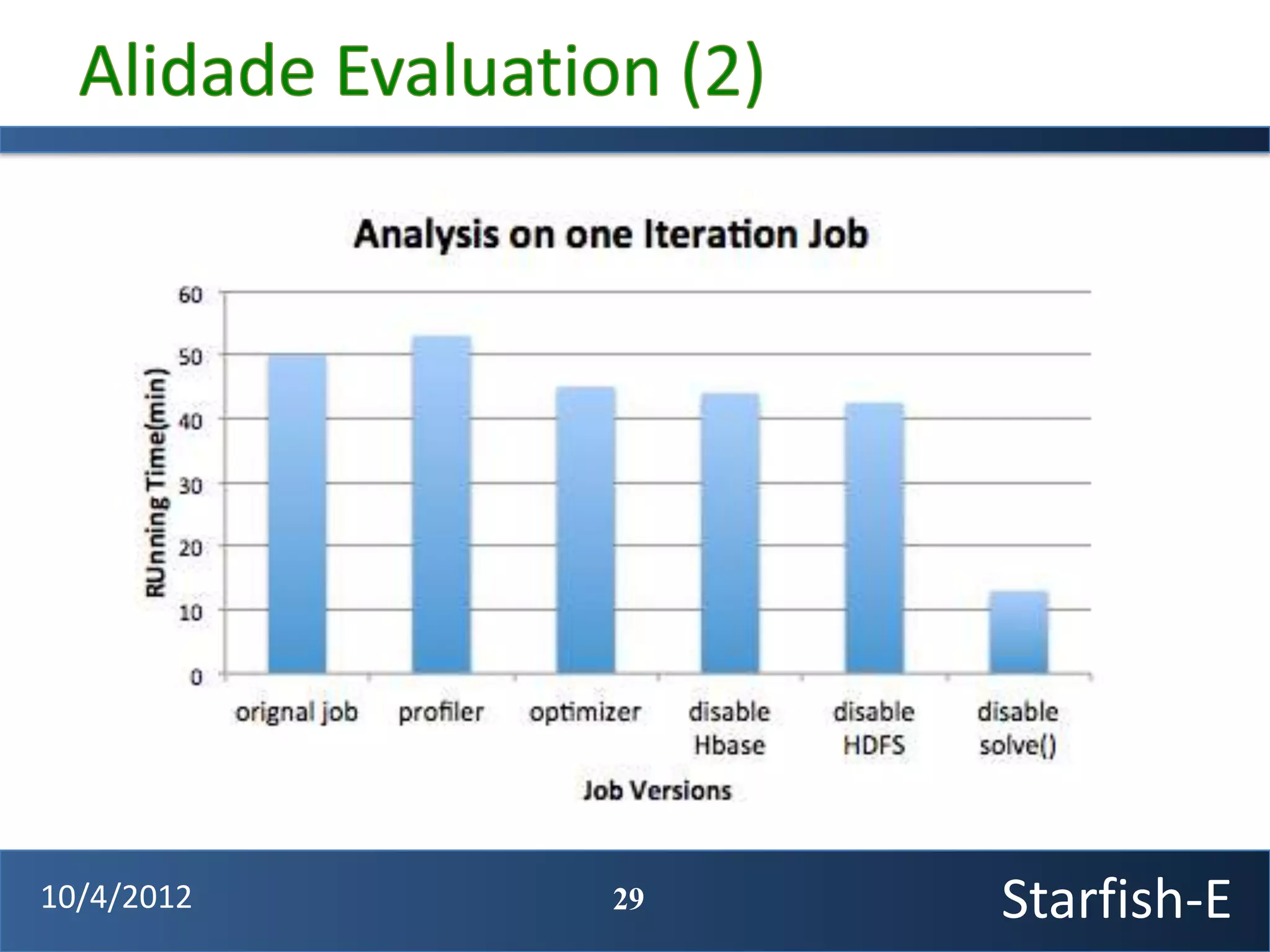
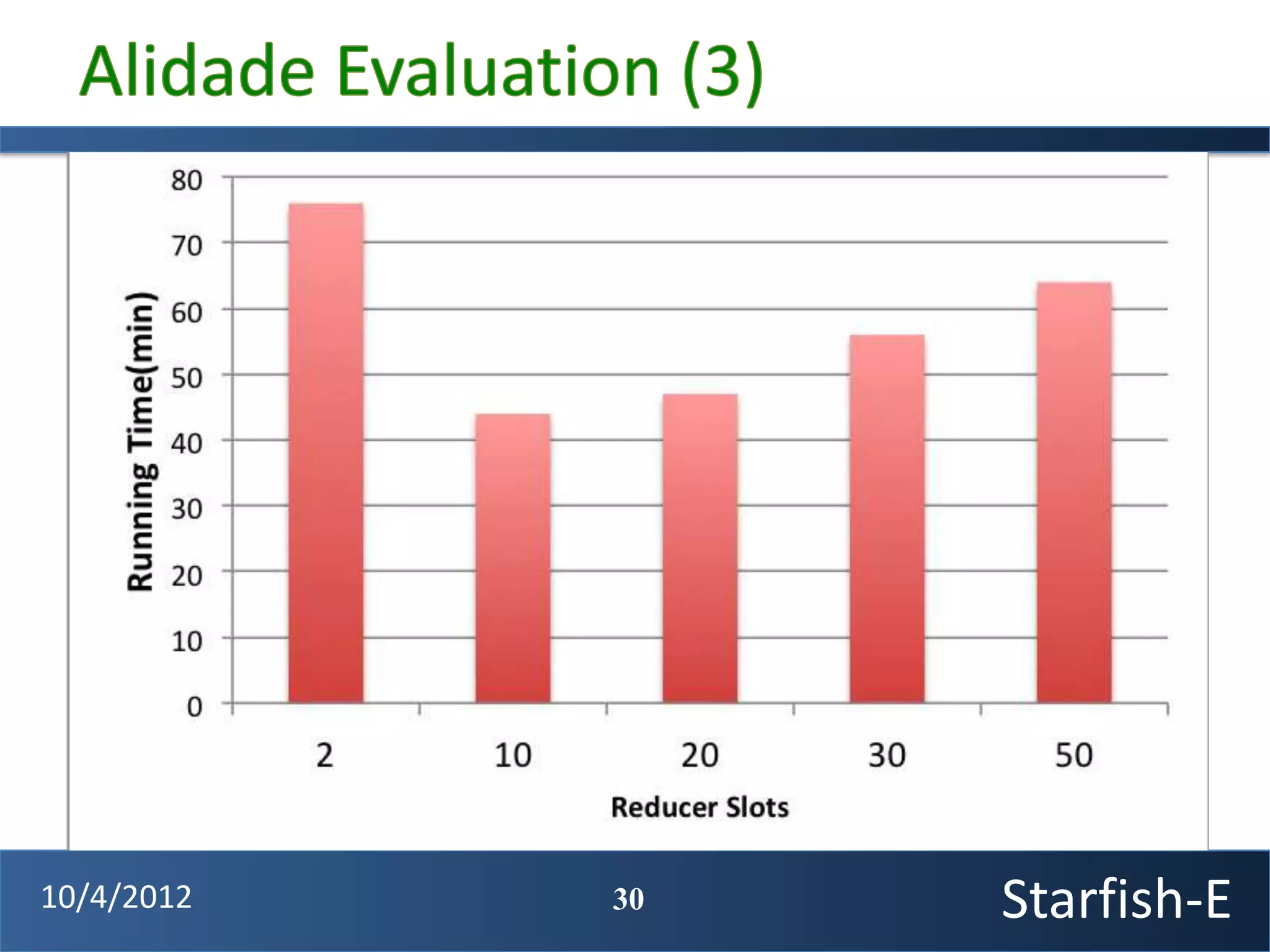
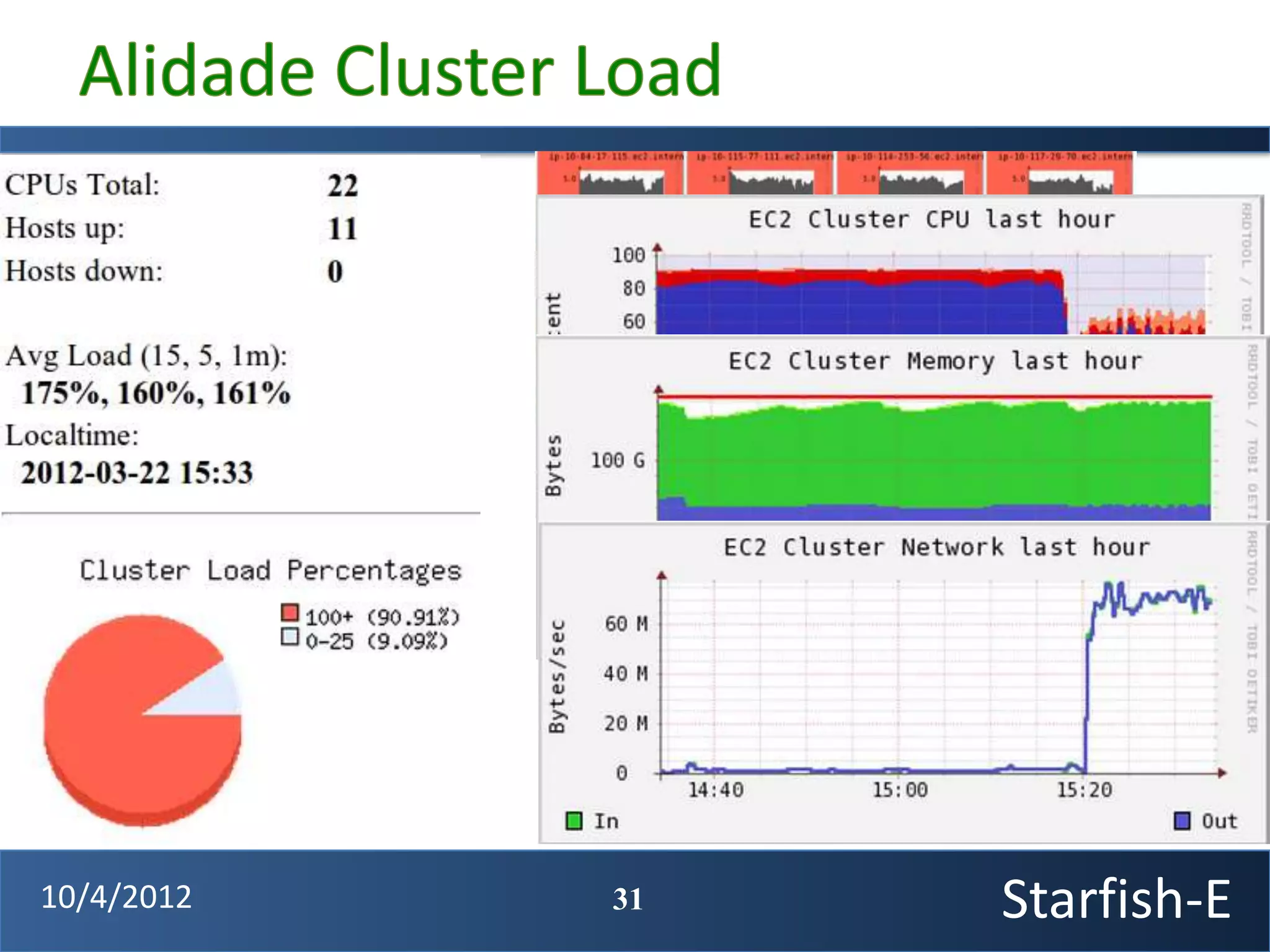
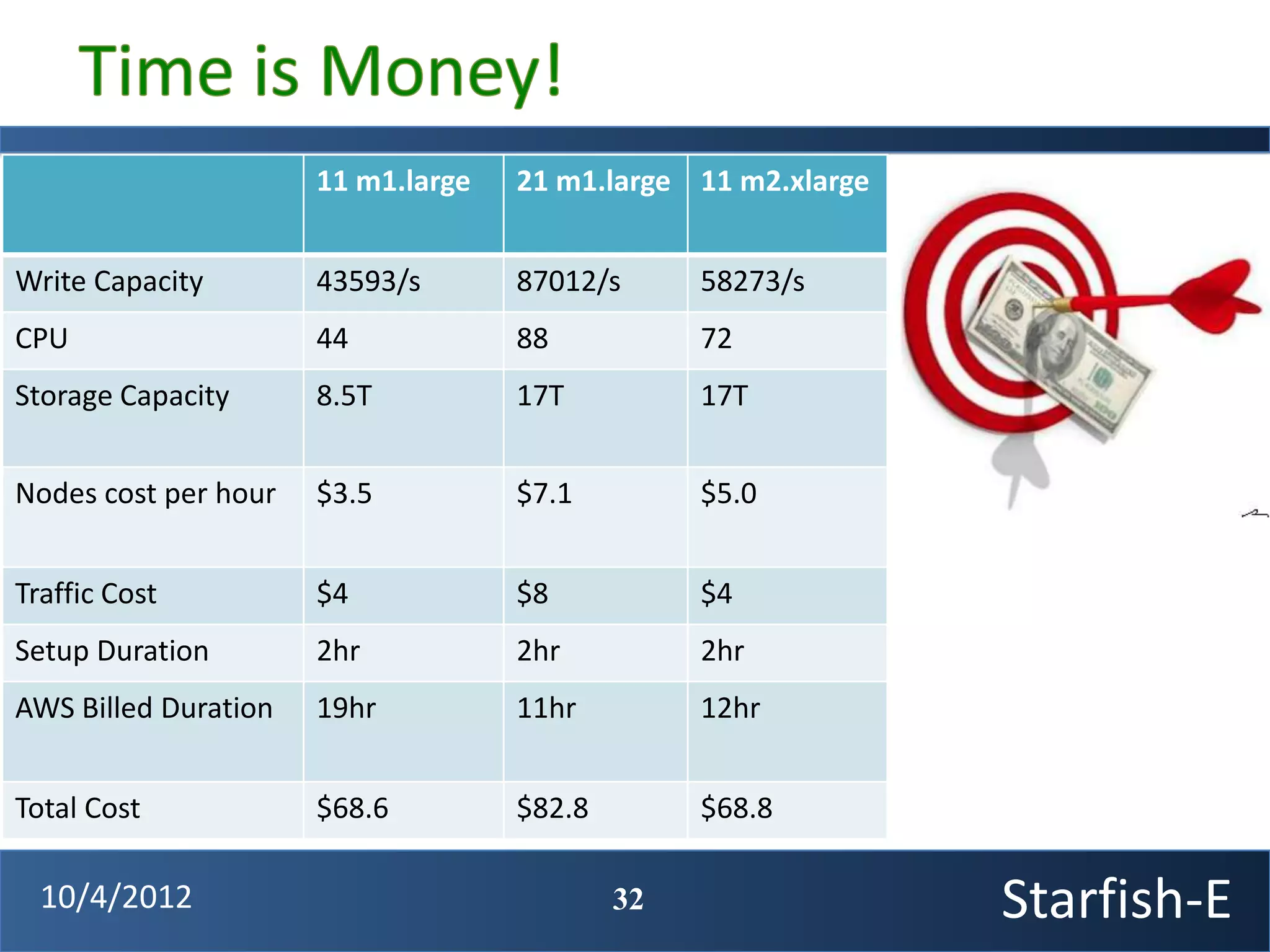






The document discusses extending the Starfish system to optimize multi-job workflows, iterative workflows, and key-value stores like HBase. It describes applying Starfish's profiling and optimization capabilities to the Cascading workflow system and supporting iterative MapReduce jobs. Optimizing the Alidade geolocation application is used as a case study.



































































