Download to read offline






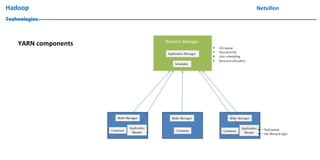

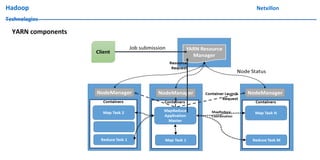
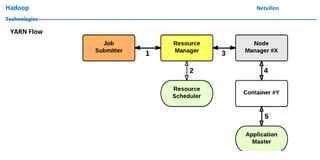
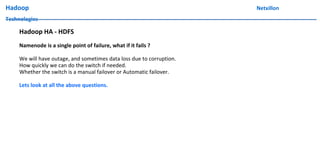
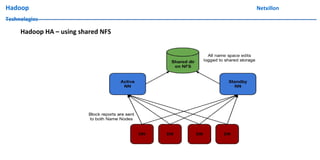

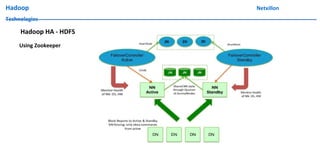
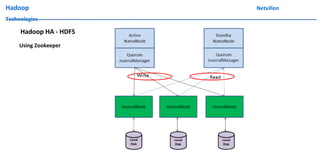
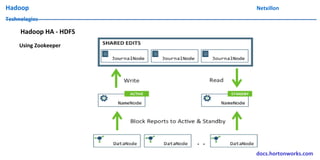
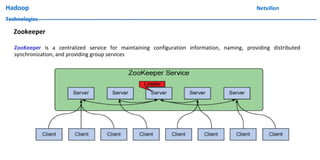

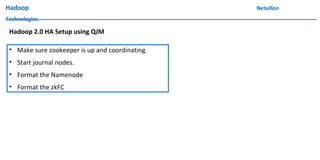


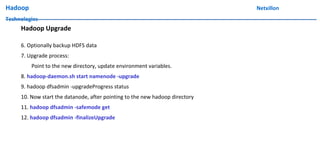






The document discusses data ingestion and storage in Hadoop. It covers topics like ingesting data into Hadoop, using Hadoop as a data warehouse, Pig scripting, using Flume to ingest Twitter and web server logs, Hive as a query layer, HBase as a NoSQL database, and setting up high availability for HBase. It also discusses differences between Hadoop 1.0 and 2.0, how to set up a Hadoop 2.0 cluster including configuration files, and demonstrates upgrading Hadoop.















































