Downloaded 207 times




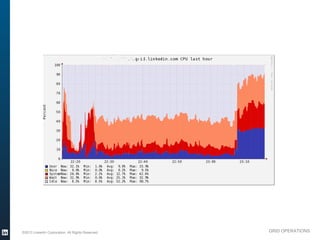



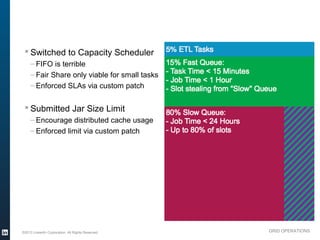
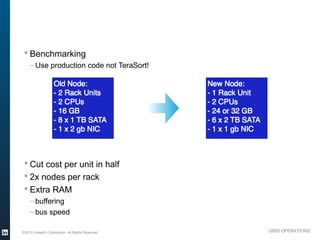
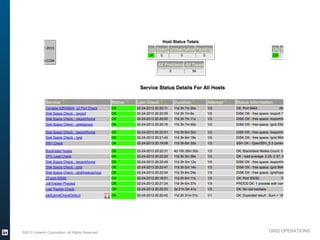

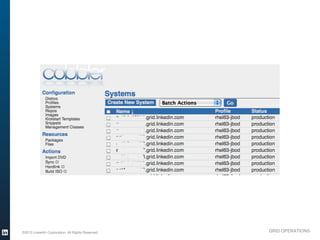

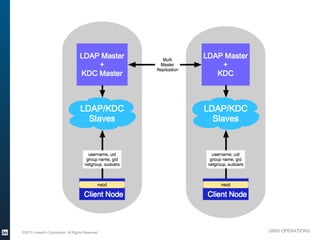

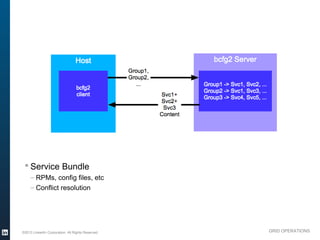


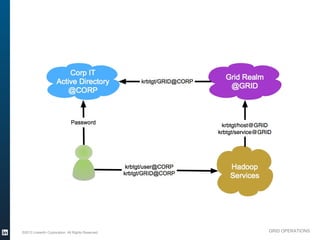

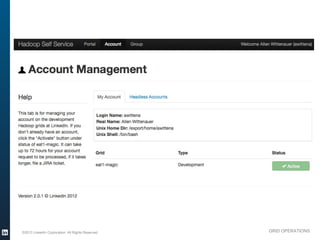
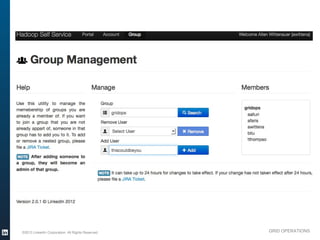

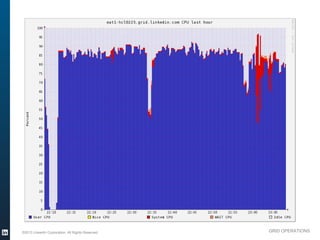






The document outlines the operational evolution of Apache Hadoop at LinkedIn, highlighting significant improvements over time, from an unmonitored 20-node setup to a secure, managed grid comprising 5000 nodes. Key changes included enhanced task management, data optimization, and a shift to capacity scheduling, resulting in a tenfold reduction in map tasks and improved storage efficiency. The document emphasizes the continuous effort to establish a reliable and secure environment while assessing the suitability of Hadoop for various workloads.












































































