Downloaded 927 times











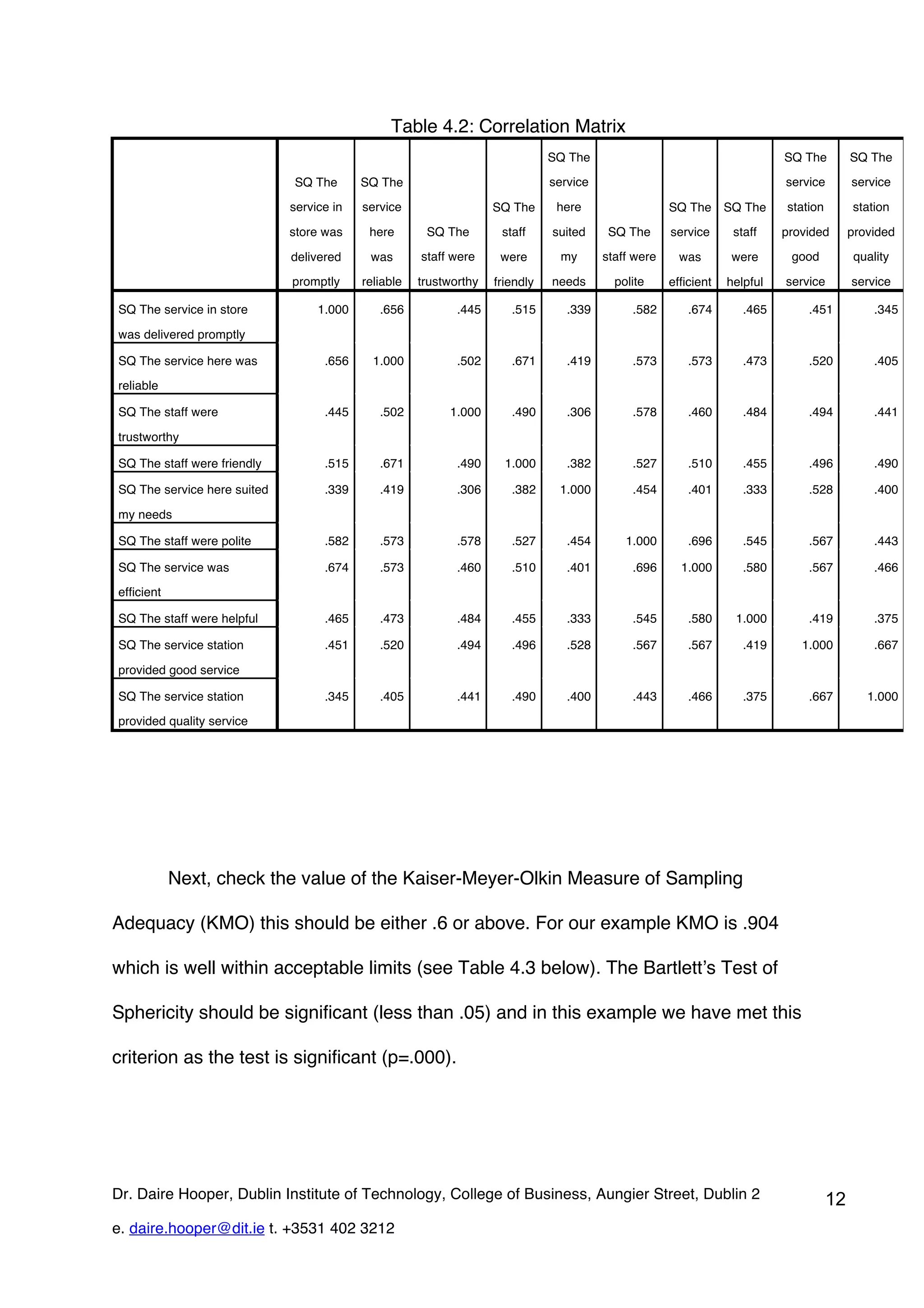


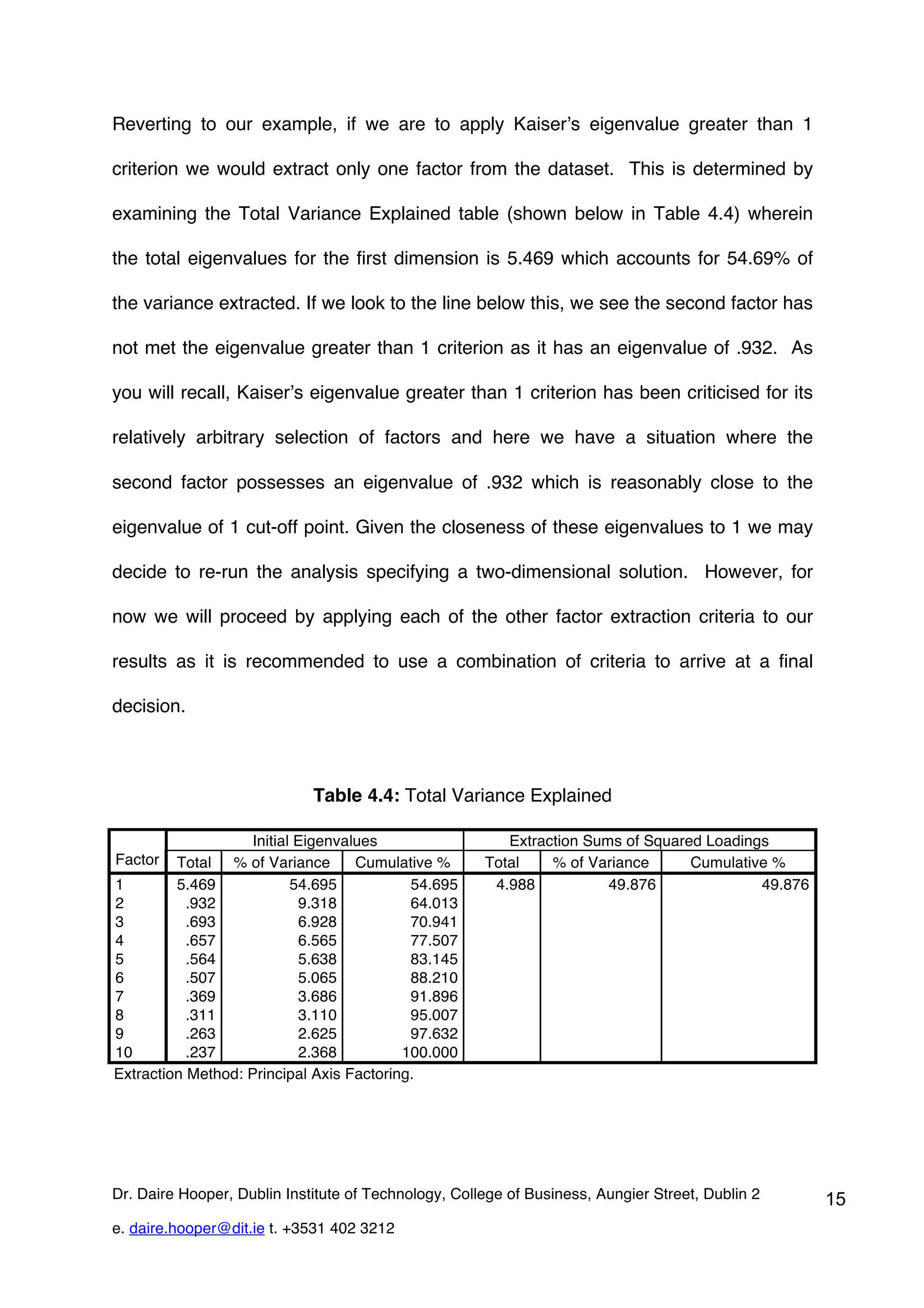
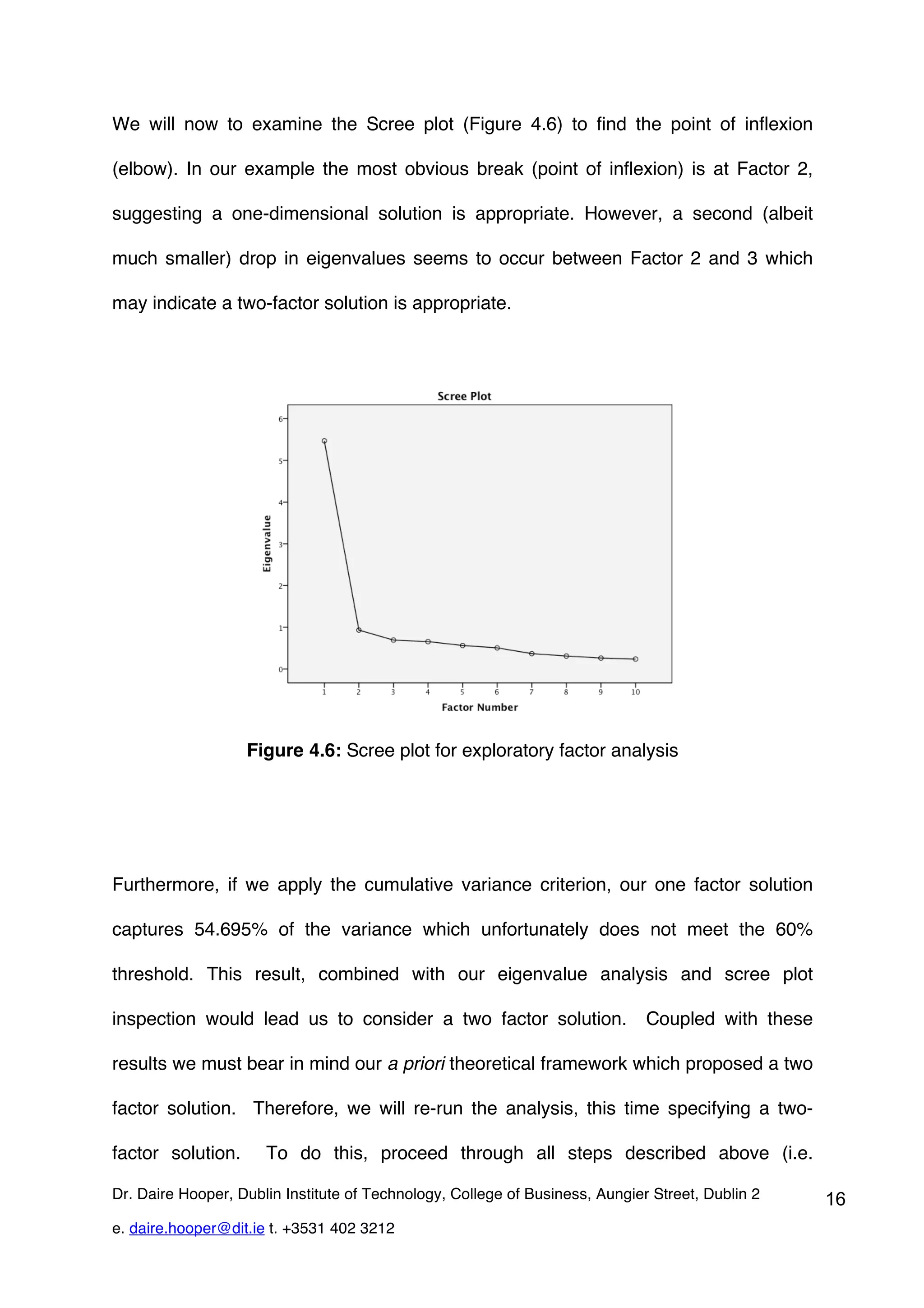

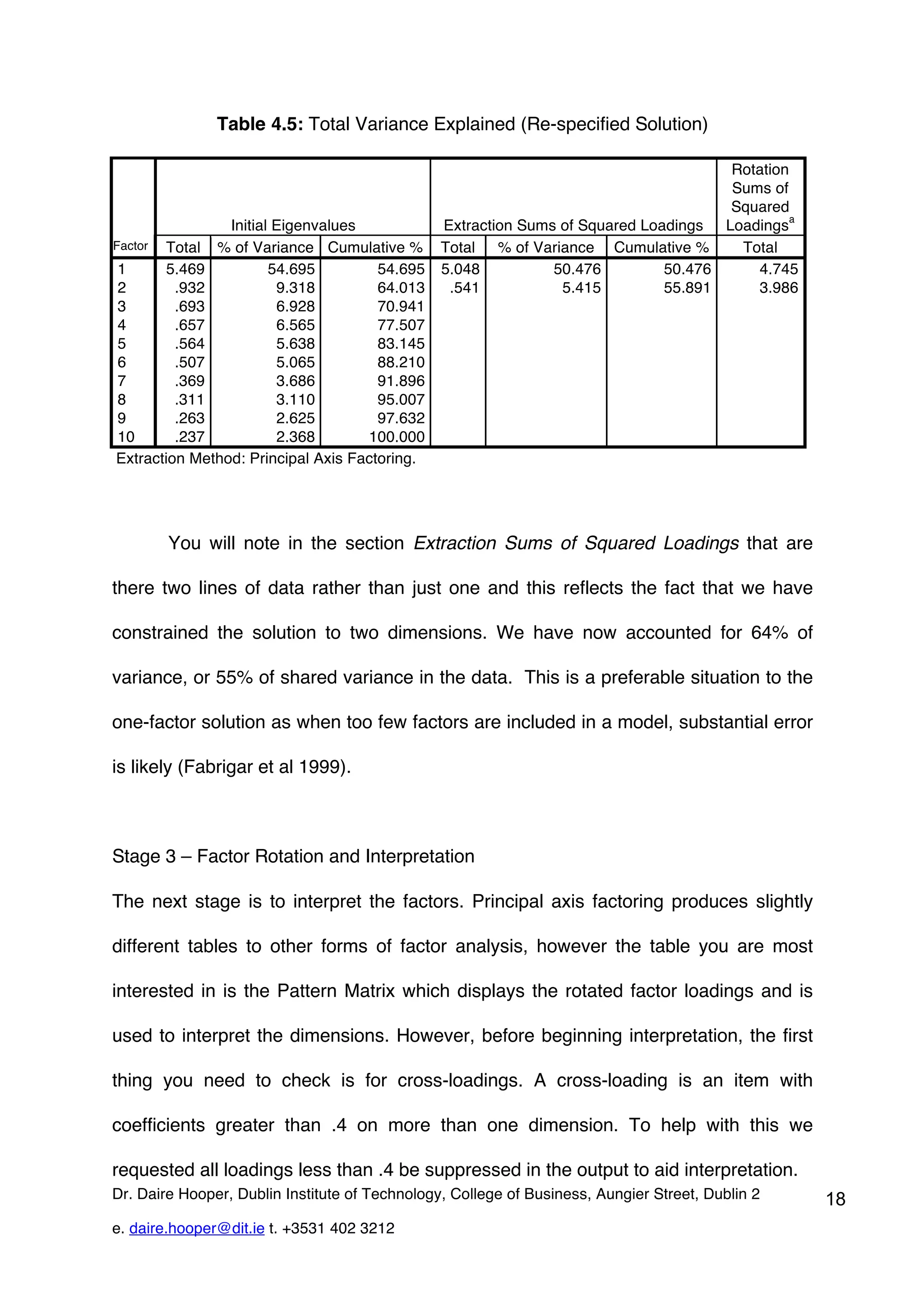













This document provides an overview of exploratory factor analysis (EFA), detailing its purpose in identifying underlying dimensions within a dataset and its applications in research, particularly in scale development. It contrasts EFA with principal components analysis (PCA), emphasizing the importance of shared variance and theoretical constructs in factor analysis. Additionally, the document outlines data requirements and procedures for conducting EFA, using a service quality example to illustrate the analysis process in SPSS.



































































