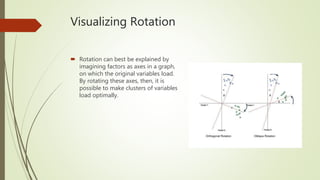
This document provides an overview of exploratory factor analysis (EFA). EFA is used to uncover the underlying structure of a set of variables and identify latent variables that are inferred rather than directly observed. It allows investigation of factor structures and helps understand response patterns. The document discusses EFA assumptions, procedures for extraction and rotation of factors, and methods for determining the appropriate number of factors.