The document provides an overview of structural equation modeling (SEM), explaining its advantages over ordinary least squares regression, such as maximum likelihood estimation and the ability to analyze complex relationships among variables. It introduces key concepts like exogenous and endogenous variables, mediation, path analysis, and model fit indices, including chi-square, CFI, TLI, RMSEA, and SRMR. Additionally, it discusses issues related to latent variables and provides a practical example of conducting a confirmatory factor analysis using R.





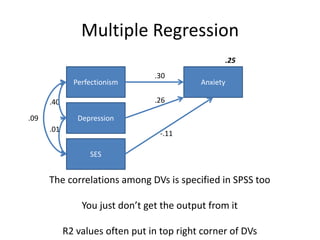

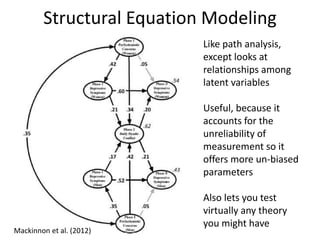

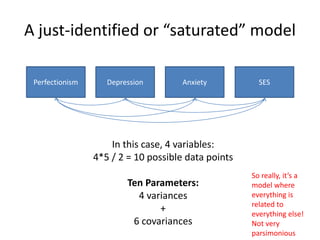
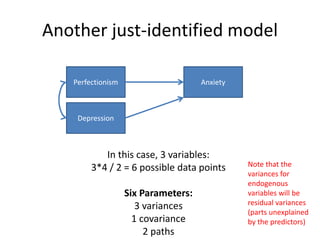

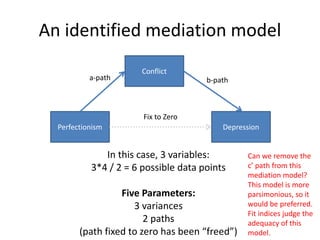



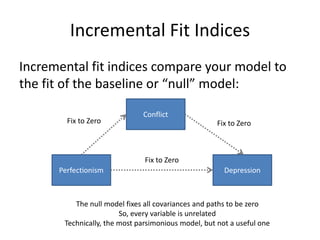


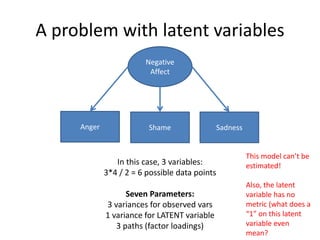
![Parsimonious Indices
Root Mean Square Approximation of Error (RMSEA)
Similar to the others, except that it doesn’t actually
compare to the null model, and (like TLI) offers a
penalty for more complex models:
√(χ2 - df)
√[df(N - 1)]
Can also calculate a 90% CI for RMSEA
http://davidakenny.net/cm/fit.htm](https://image.slidesharecdn.com/introsem-150216093420-conversion-gate01/85/Basics-of-Structural-Equation-Modeling-26-320.jpg)






























































![[DSC Europe 25] Slobodan Dolinic - Smart and Intelligent Green Region.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/0bribinjsp6ghwtvsvor-2-sigre-slobodan-dolinic-260115093812-c9c10e90-thumbnail.jpg?width=640&height=640&fit=bounds)






![[DSC Europe 25] Elena Menshikova - AI-Powered Operational Excellence: Revolut...](https://cdn.slidesharecdn.com/ss_thumbnails/es6nholbqy3zaao2c2yd-2-elena-menshikova-data-ai-in-decision-making-260115093812-4fba8b38-thumbnail.jpg?width=640&height=640&fit=bounds)










