Downloaded 40 times








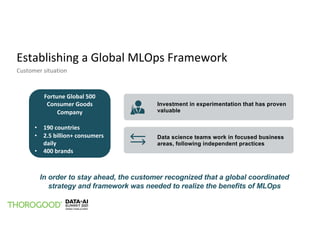
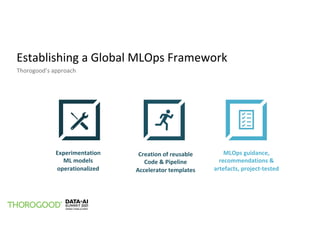
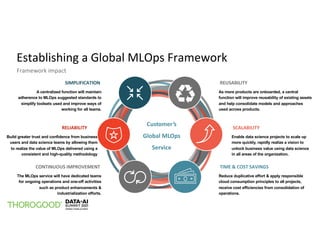

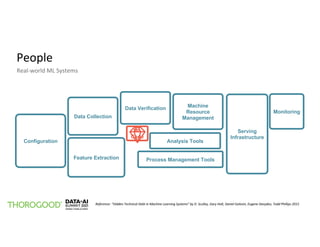


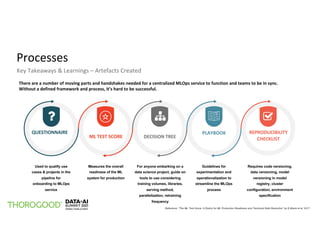
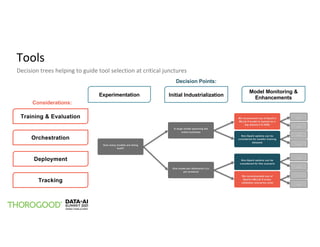




The document outlines the implementation of MLOps by Thorogood Associates and presents a case study on establishing a global MLOps framework for a Fortune Global 500 consumer goods company. It emphasizes the importance of scalability, model reusability, operational efficiency, and ongoing improvements to enhance the value of machine learning and data science across the organization. Key takeaways include the necessity of a well-defined framework, collaboration among data science experts, and the use of integrated tools like Databricks and MLflow to optimize the MLOps process.






































































![Hacking-Uncovered-How-People-Get-Hacked-and-How-to-Stay-Safe[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/hacking-uncovered-how-people-get-hacked-and-how-to-stay-safe1-260130170011-4883a9c7-thumbnail.jpg?width=640&height=640&fit=bounds)










![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)





