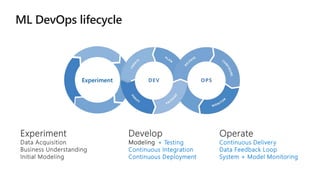
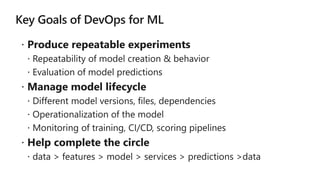
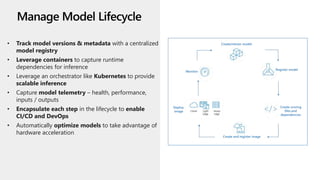
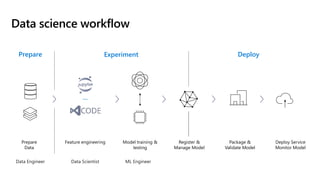
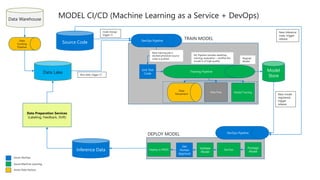
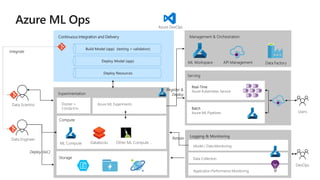
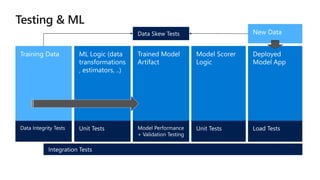
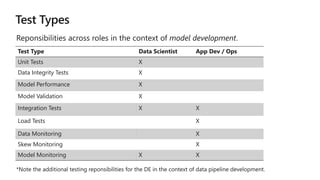
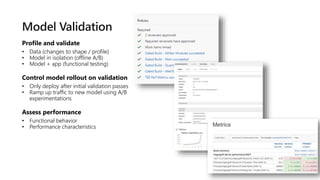
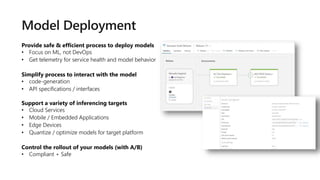
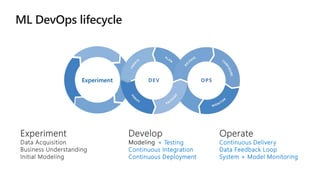
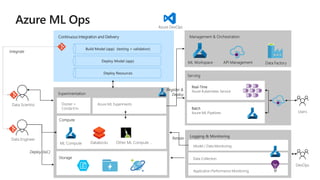
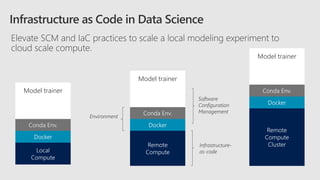
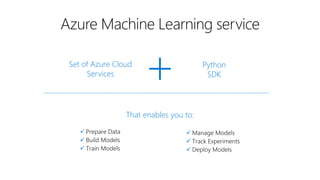
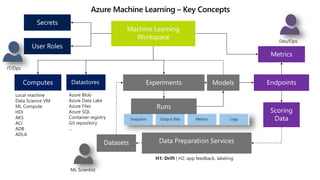
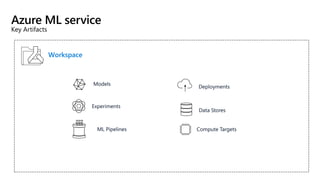
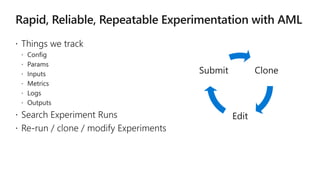
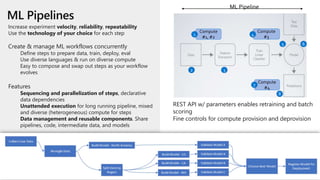
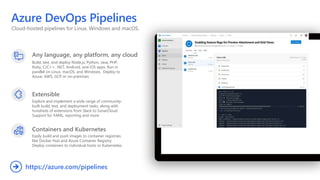
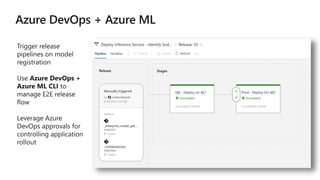
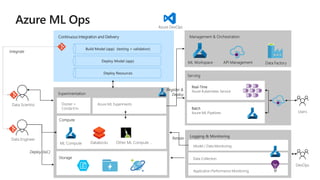
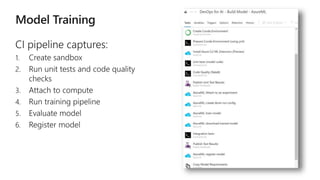
This document discusses applying DevOps practices and principles to machine learning model development and deployment. It outlines how continuous integration (CI), continuous delivery (CD), and continuous monitoring can be used to safely deliver ML features to customers. The benefits of this approach include continuous value delivery, end-to-end ownership by data science teams, consistent processes, quality/cadence improvements, and regulatory compliance. Key aspects covered are experiment tracking, model versioning, packaging and deployment, and monitoring models in production.






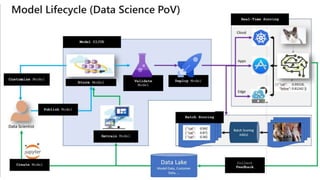

![App Developer IDE
Data Scientist
[ { "cat": 0.99218,
"feline": 0.81242 }]
IDE
Consume Model
DevOps
Pipeline
Predict
Update
Application
Publish Model
Deploy
Application
Validate
App](https://image.slidesharecdn.com/devopsforml-240304153127-8bc78867/85/DevOps-for-Machine-Learning-overview-en-us-15-320.jpg)
![App Developer IDE
Data Scientist
[ { "cat": 0.99218,
"feline": 0.81242 }]
Model Store
Consume Model
DevOps
Pipeline
Predict
Validate
App
Update
Application
Deploy
Application
Publish Model](https://image.slidesharecdn.com/devopsforml-240304153127-8bc78867/85/DevOps-for-Machine-Learning-overview-en-us-16-320.jpg)
![App Developer IDE
[ { "cat": 0.99218,
"feline": 0.81242 }]
Model Store
Consume Model
DevOps
Pipeline
Validate
Model
Predict
Validate
Model + App
Update
Application
Deploy
Application
Data Scientist
Publish Model](https://image.slidesharecdn.com/devopsforml-240304153127-8bc78867/85/DevOps-for-Machine-Learning-overview-en-us-17-320.jpg)
![App Developer IDE
[ { "cat": 0.99218,
"feline": 0.81242 }]
Model Store
Consume Model
DevOps
Pipeline
Validate
Model
Predict
Validate
Model + App
Update
Application
Deploy
Application
Data Scientist
Publish Model
Collect
Feedback
Retrain Model
AB Test](https://image.slidesharecdn.com/devopsforml-240304153127-8bc78867/85/DevOps-for-Machine-Learning-overview-en-us-18-320.jpg)

![App Developer
Cloud Services
IDE
Data Scientist
[ { "cat": 0.99218,
"feline": 0.81242 }]
IDE
Apps
Edge Devices
Model Store
Consume Model
DevOps
Pipeline
Customize Model
Deploy Model
Predict
Validate
&
Flight
Model
+
App
Update
Application
Publish Model
Collect
Feedback
Deploy
Application
Model
Telemetry
Retrain Model](https://image.slidesharecdn.com/devopsforml-240304153127-8bc78867/85/DevOps-for-Machine-Learning-overview-en-us-20-320.jpg)







































![[AI] ML Operationalization with Microsoft Azure](https://cdn.slidesharecdn.com/ss_thumbnails/wds-mlops-trainer-kyle-akepanidtaworn-v03-190924094657-thumbnail.jpg?width=640&height=640&fit=bounds)

































![谷歌留痕技术教程[ 𝙩𝙤𝙥 𝟮𝟯𝟯. 𝙘 𝙤𝙢 ]](https://cdn.slidesharecdn.com/ss_thumbnails/top233-260130173900-2eb784f9-thumbnail.jpg?width=640&height=640&fit=bounds)
