Downloaded 29 times




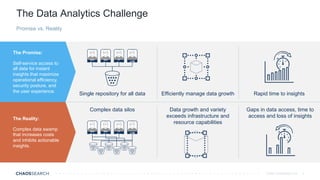

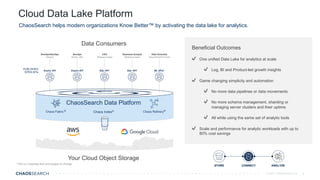

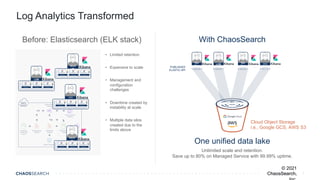









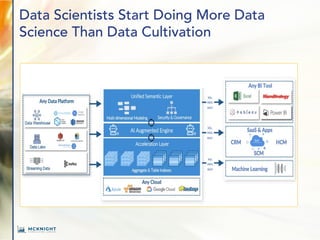
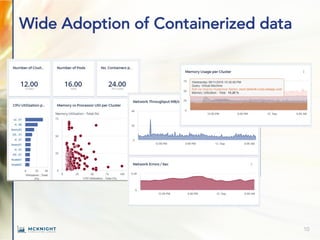


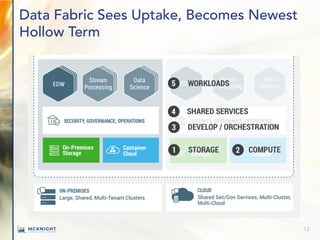



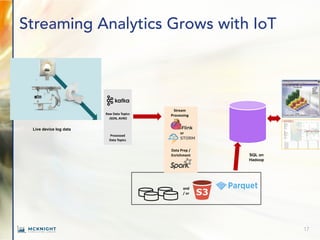










The document outlines key trends in enterprise advanced analytics for 2022, emphasizing the importance of adopting technologies such as AI, data lakes, and containerization. It highlights how organizations can simplify data management and gain insights through the use of Chaossearch's data lake platform, achieving significant cost savings and operational efficiencies. Additionally, it discusses the evolving landscape of analytics, including the rise of data observability and AI-enabled applications.




















































































