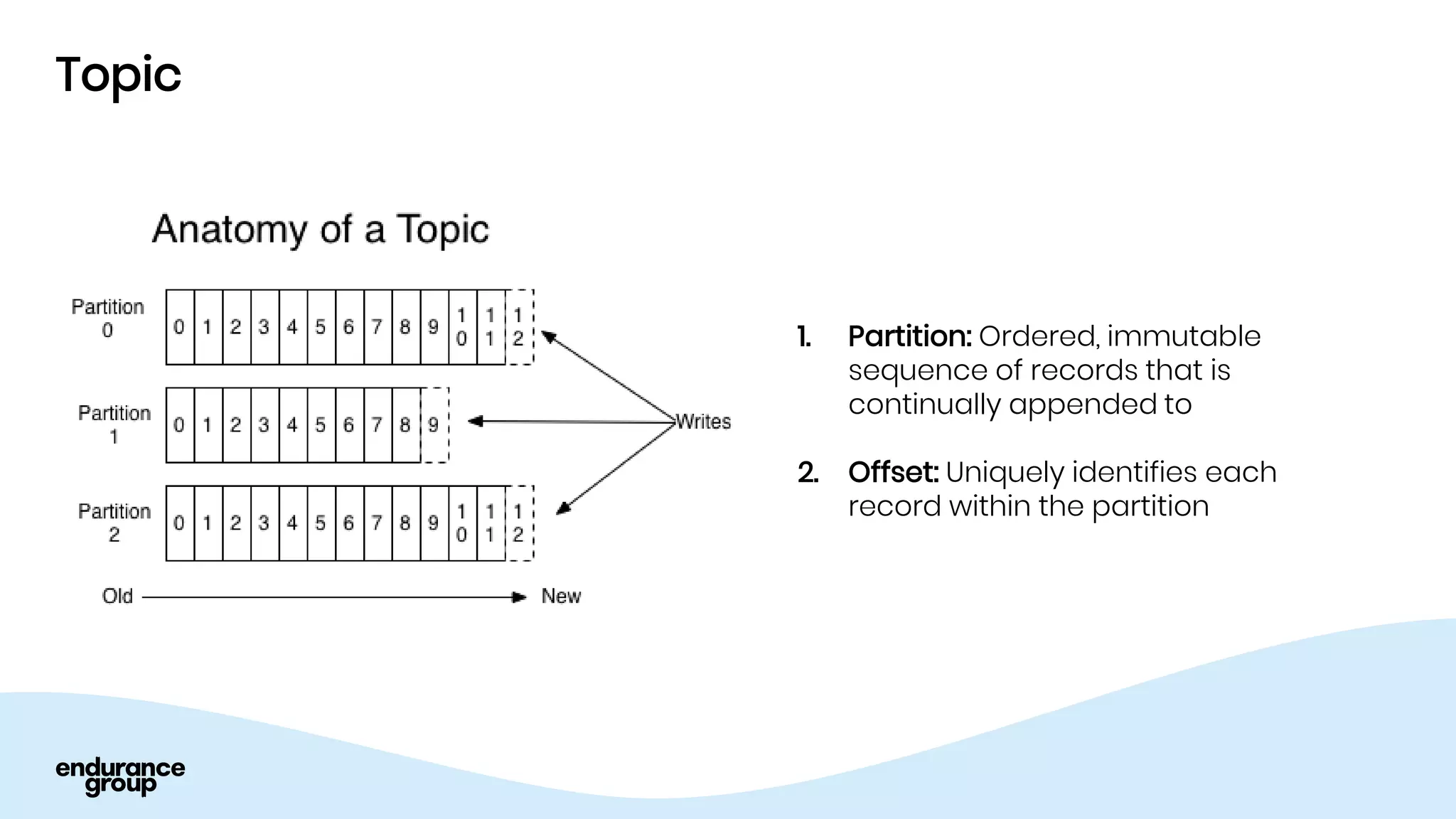
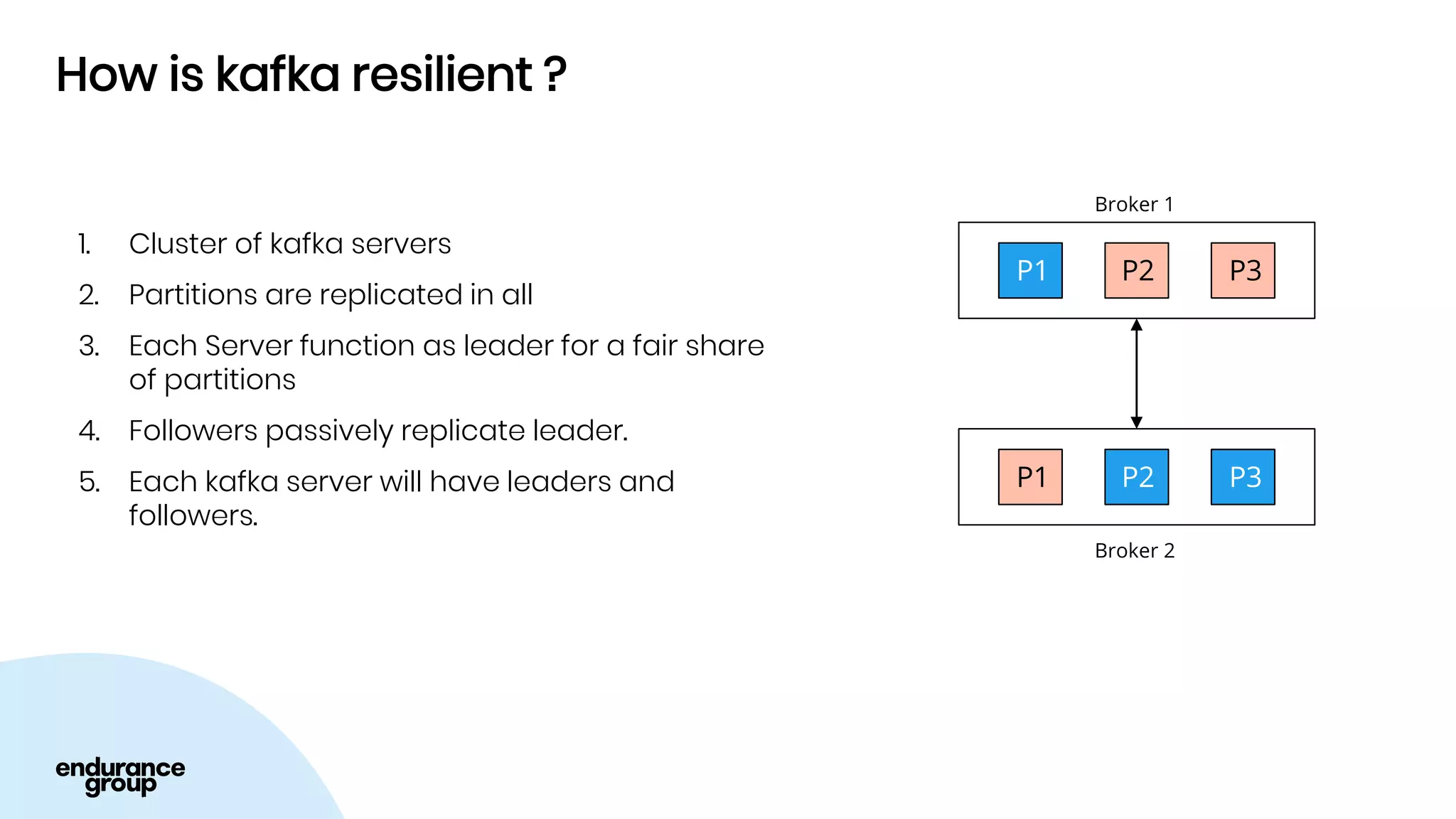
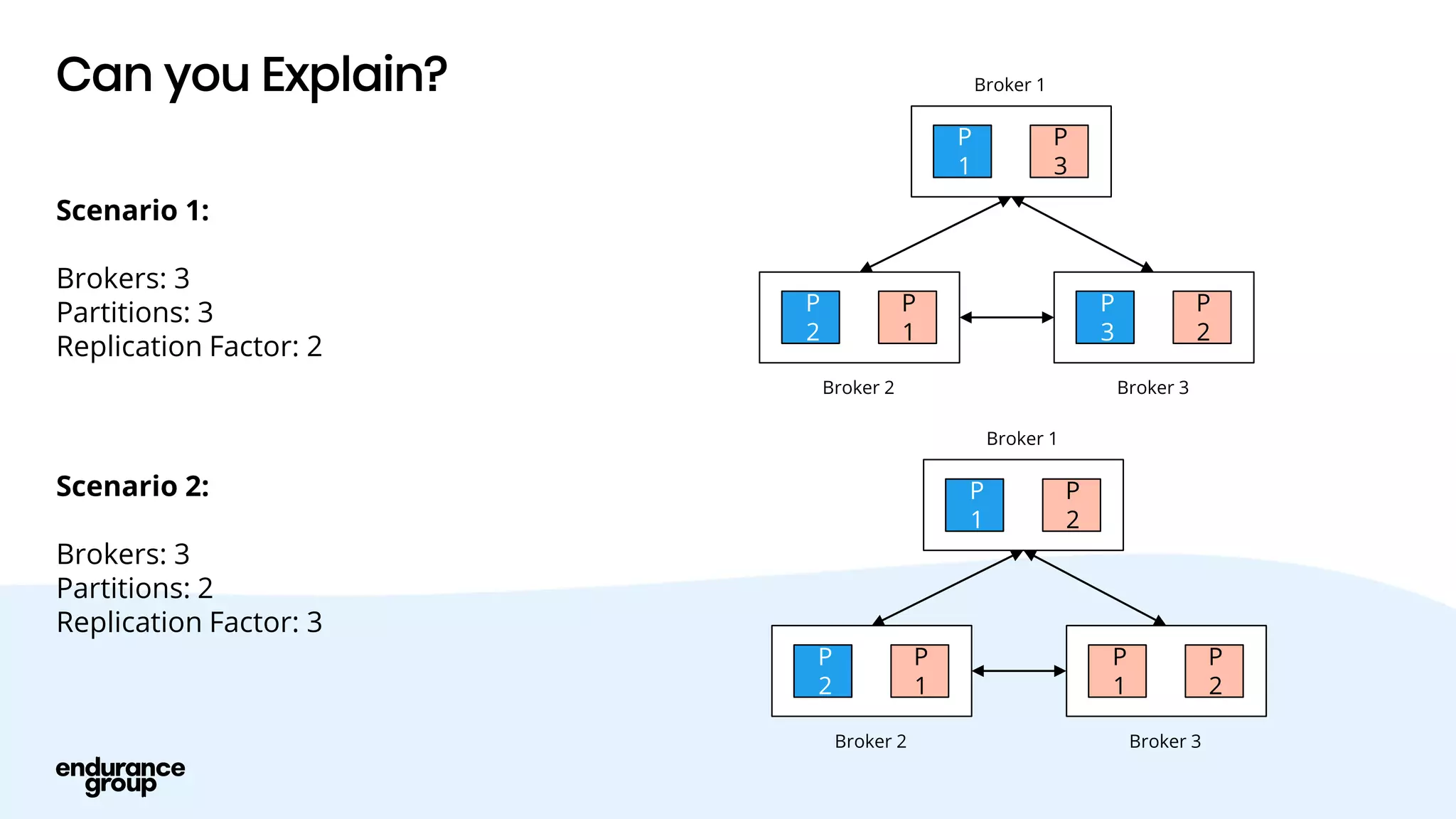
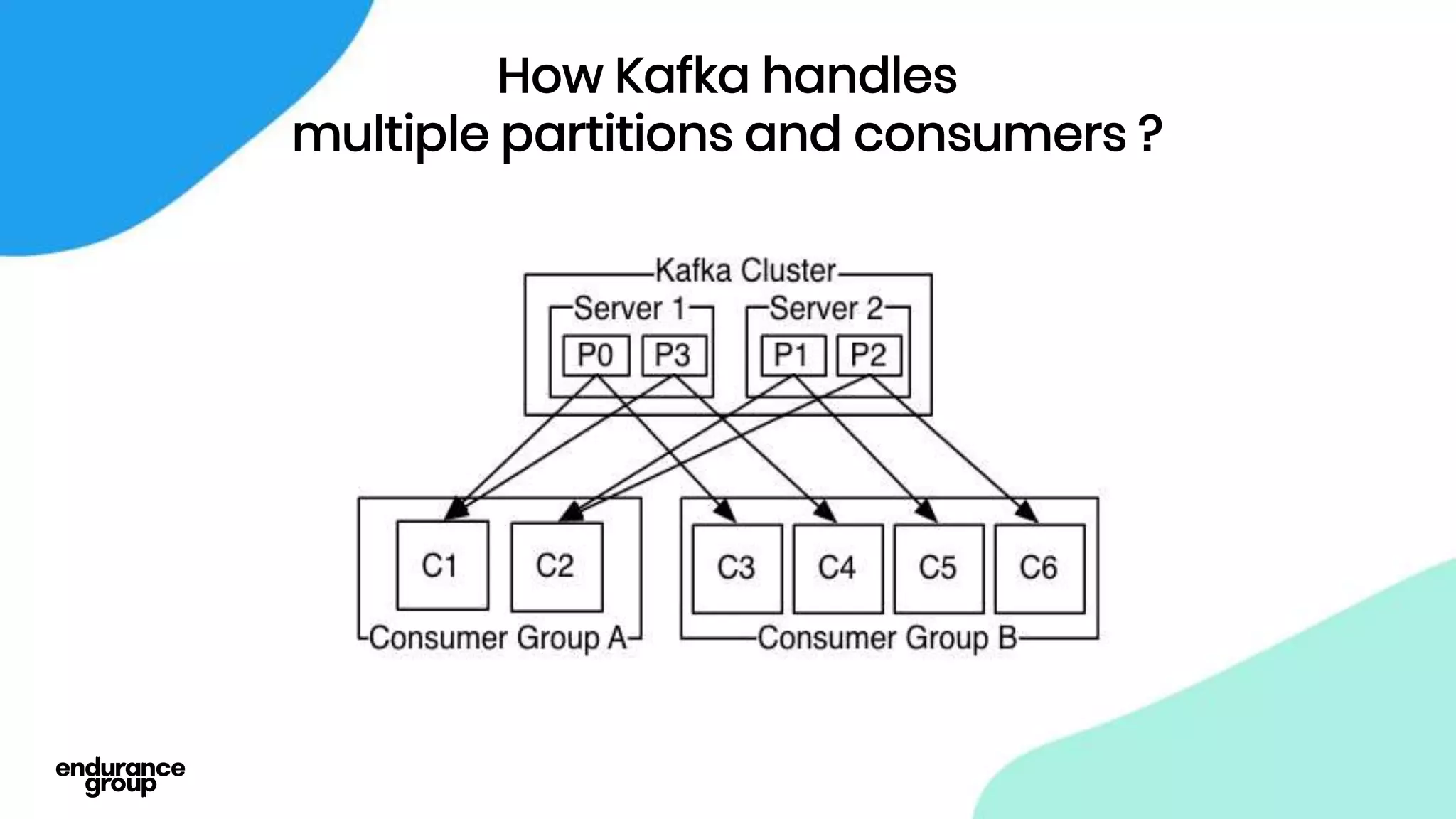
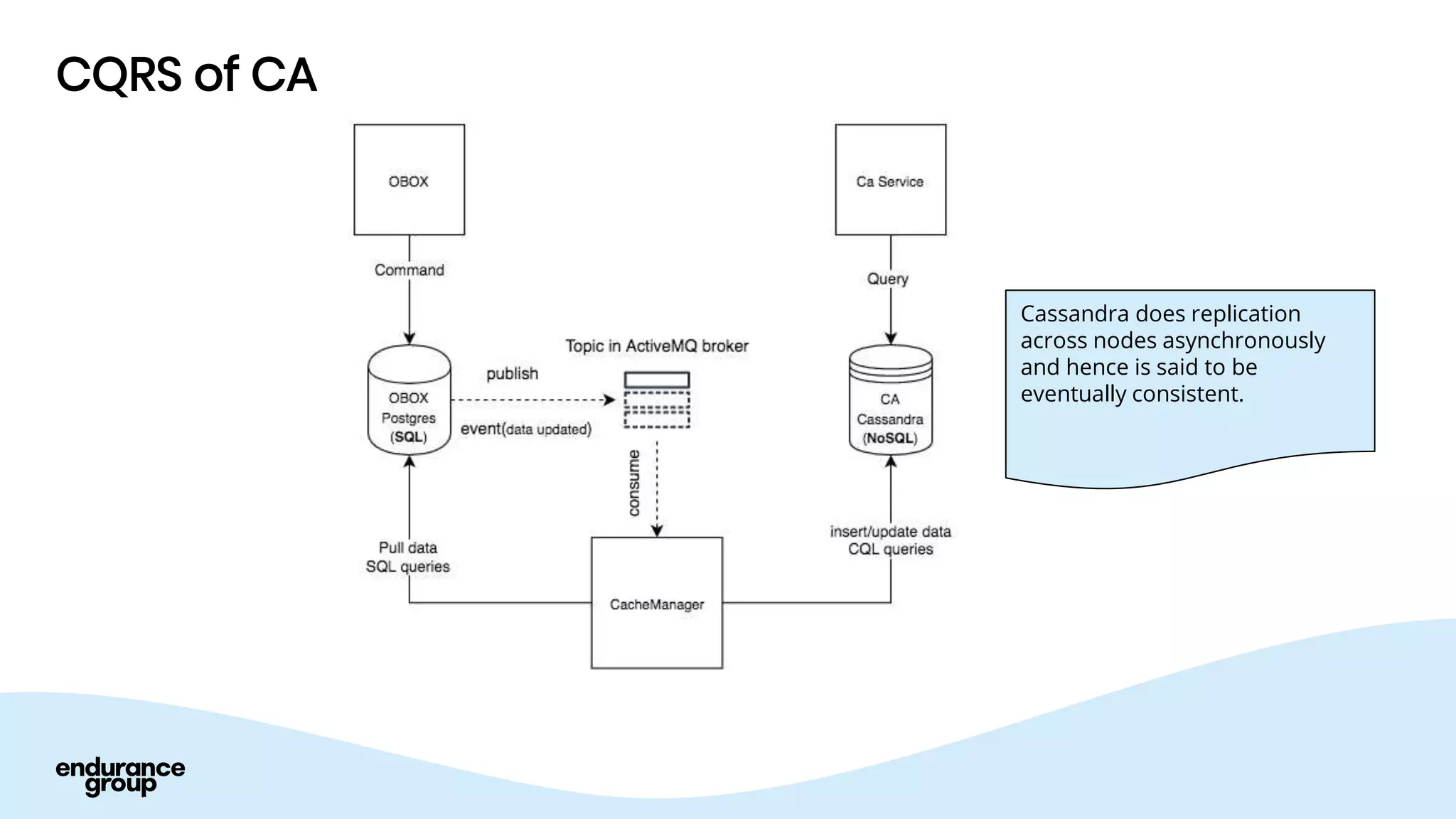
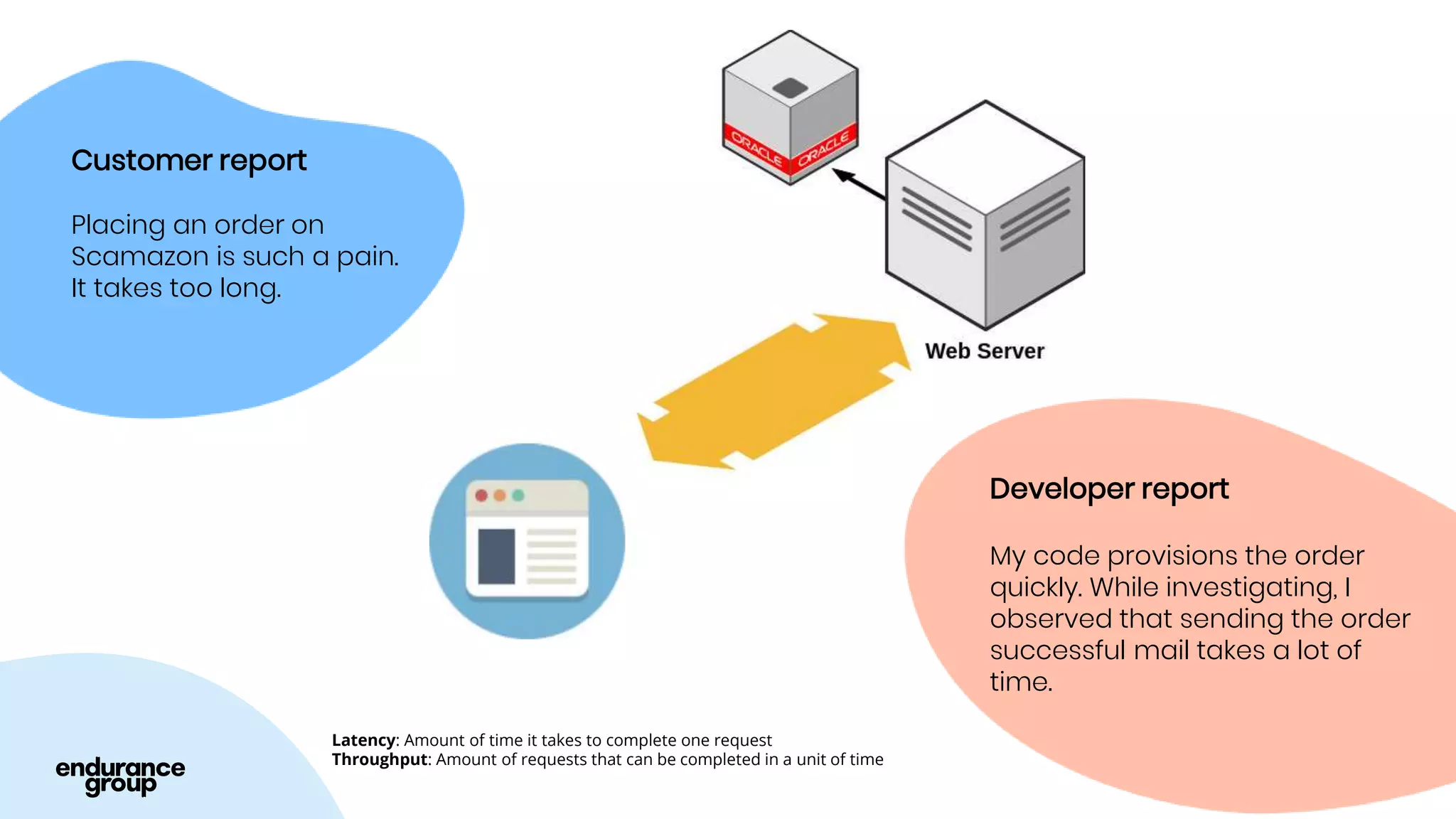
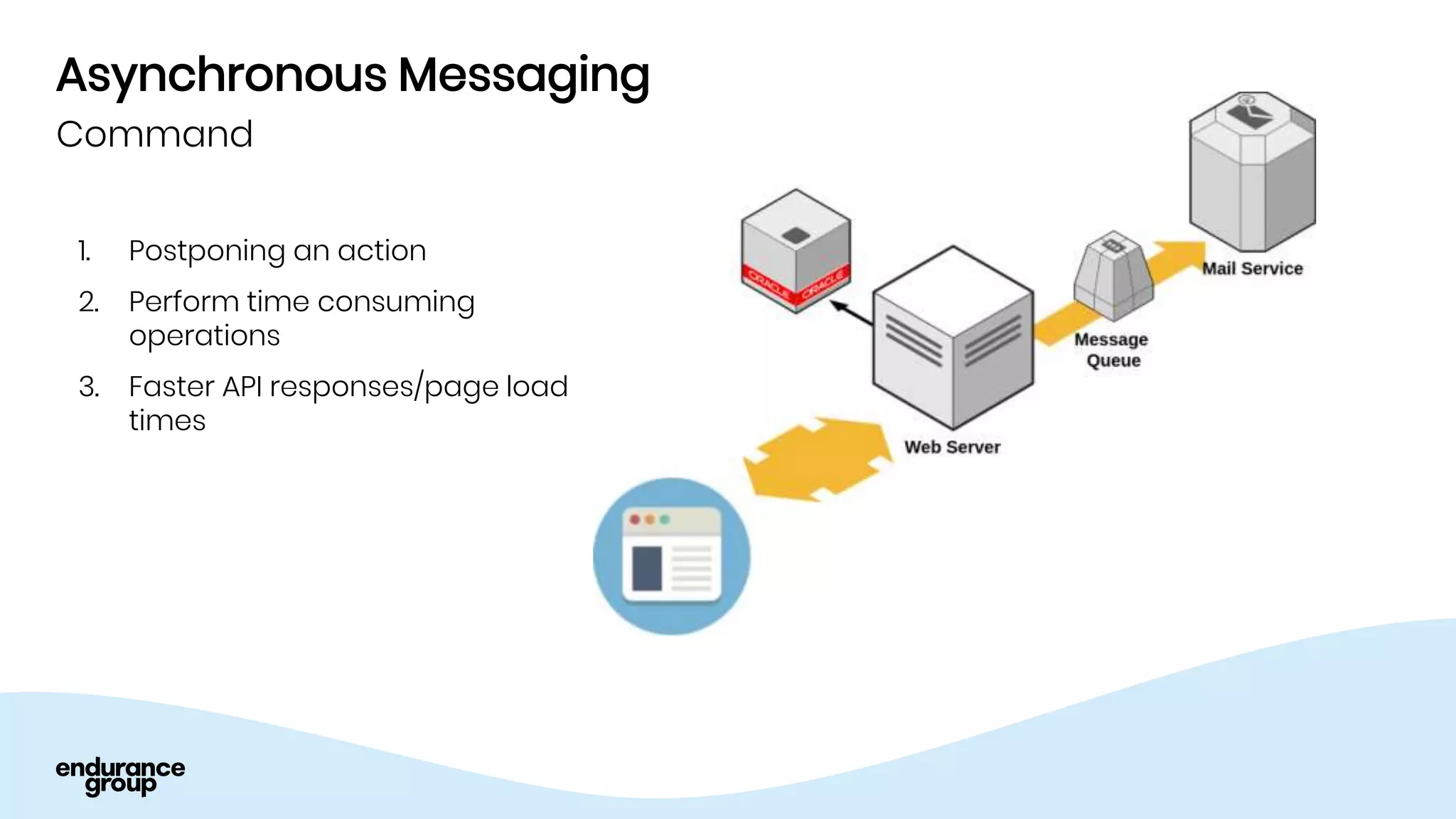
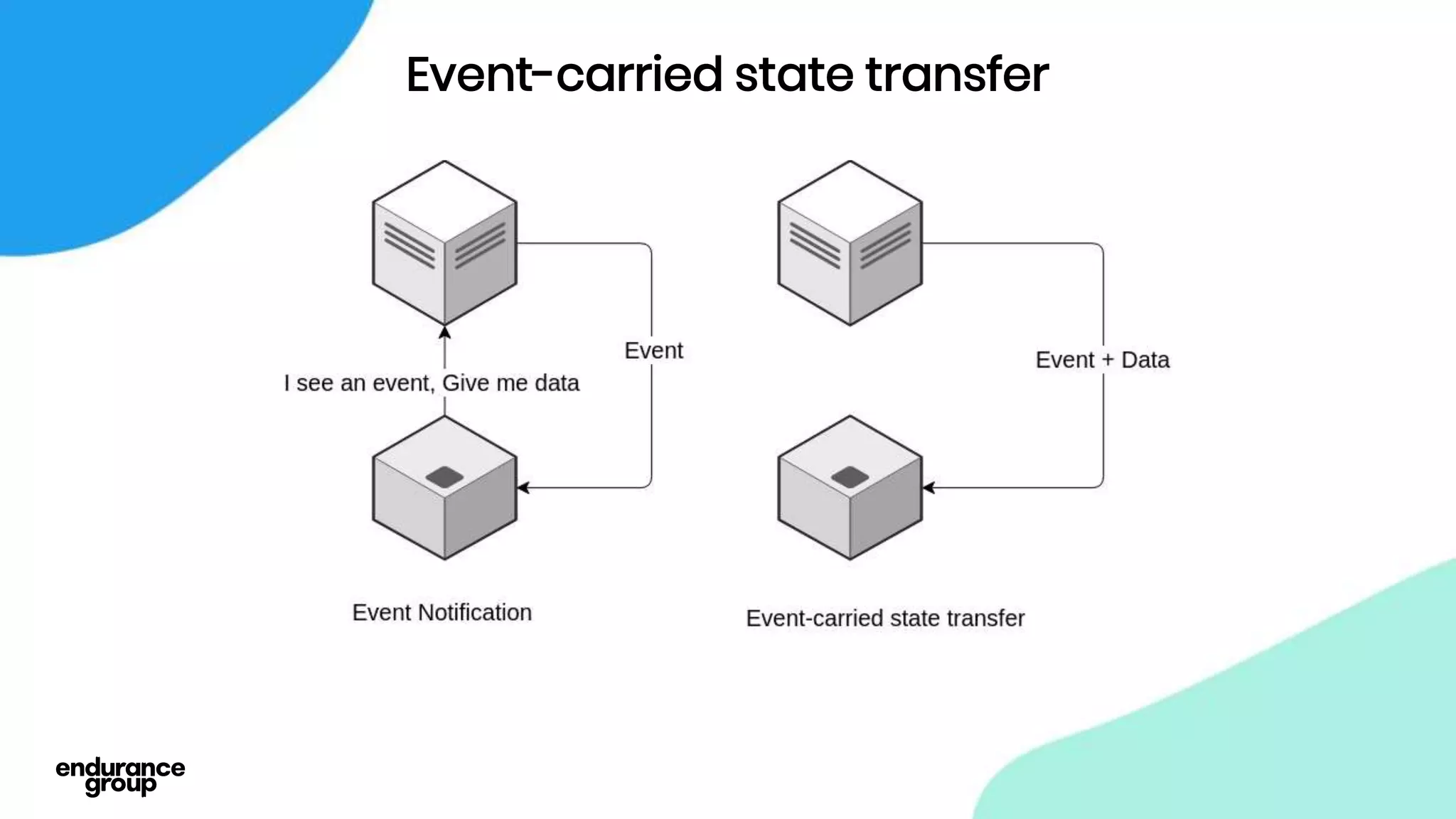
Event Driven Architecture and Apache Kafka were discussed. Key points:
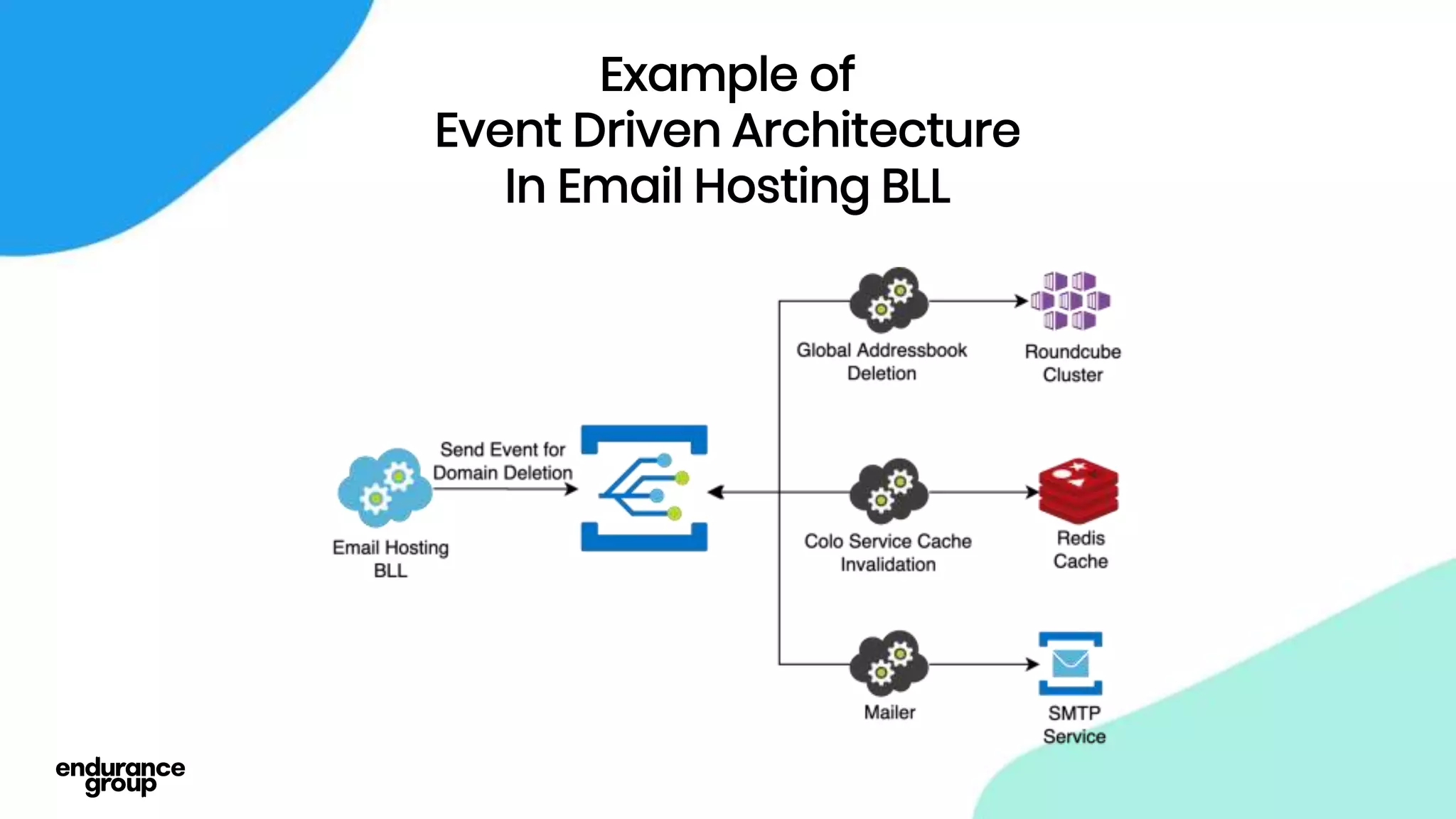
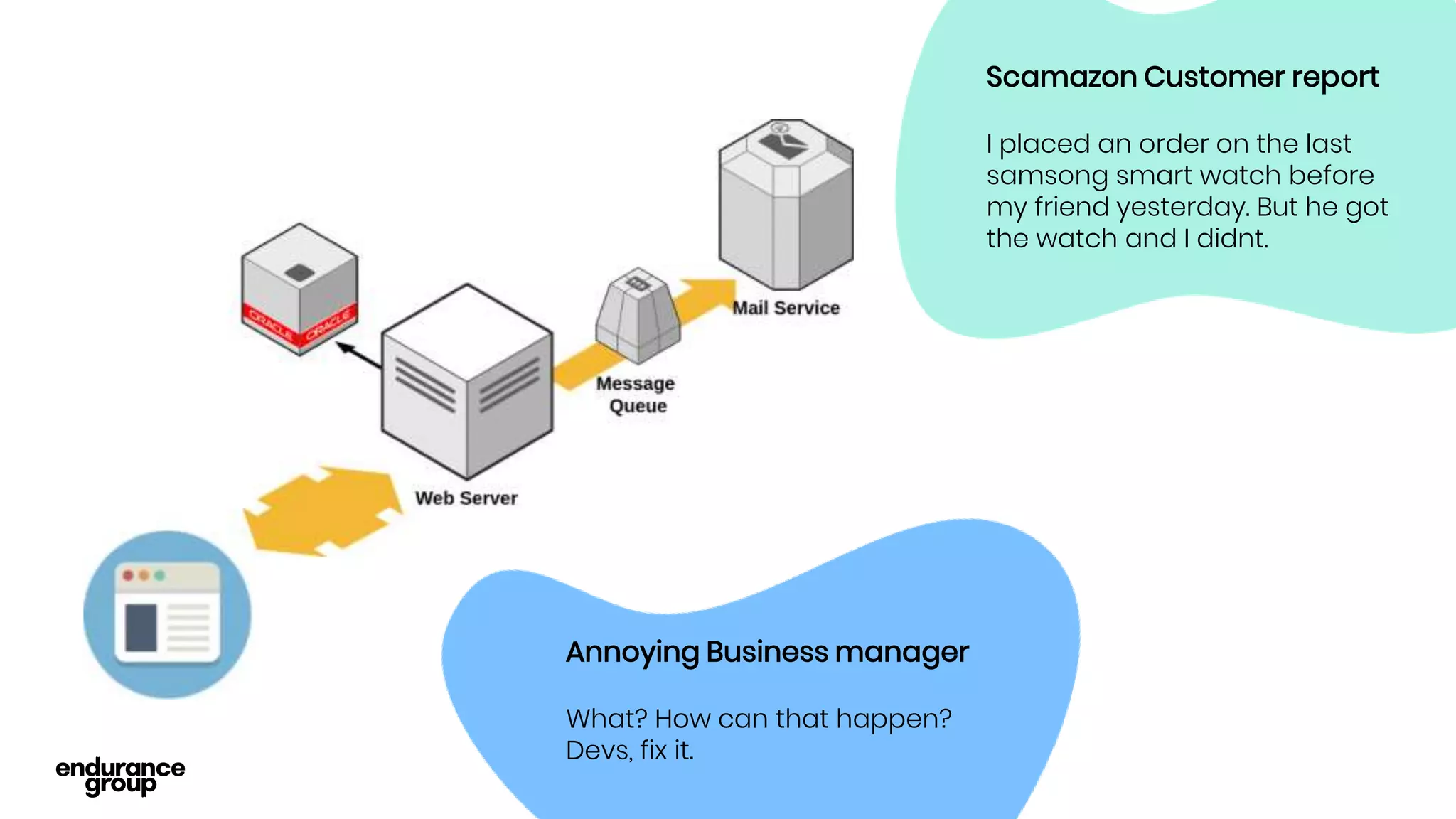
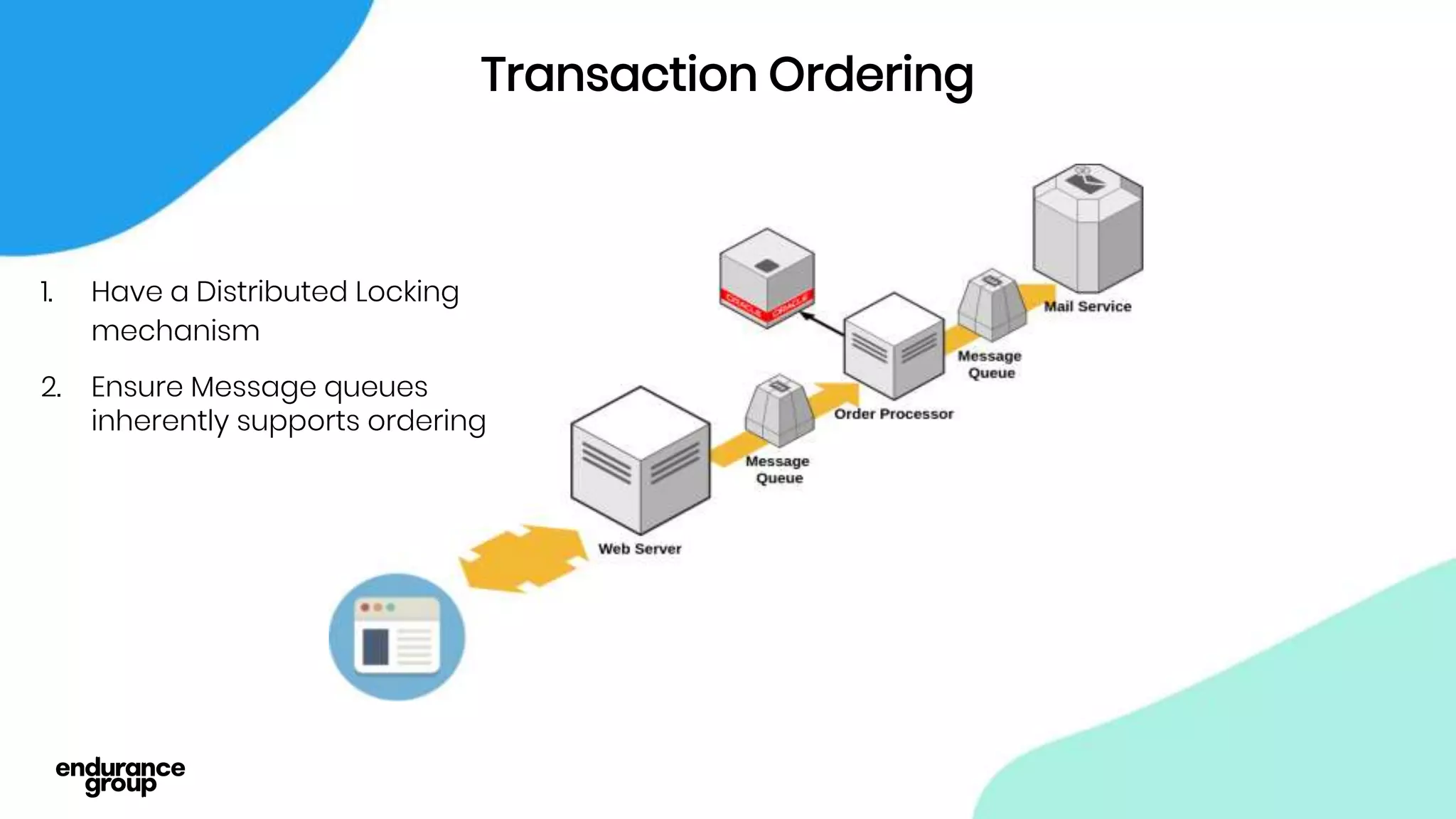
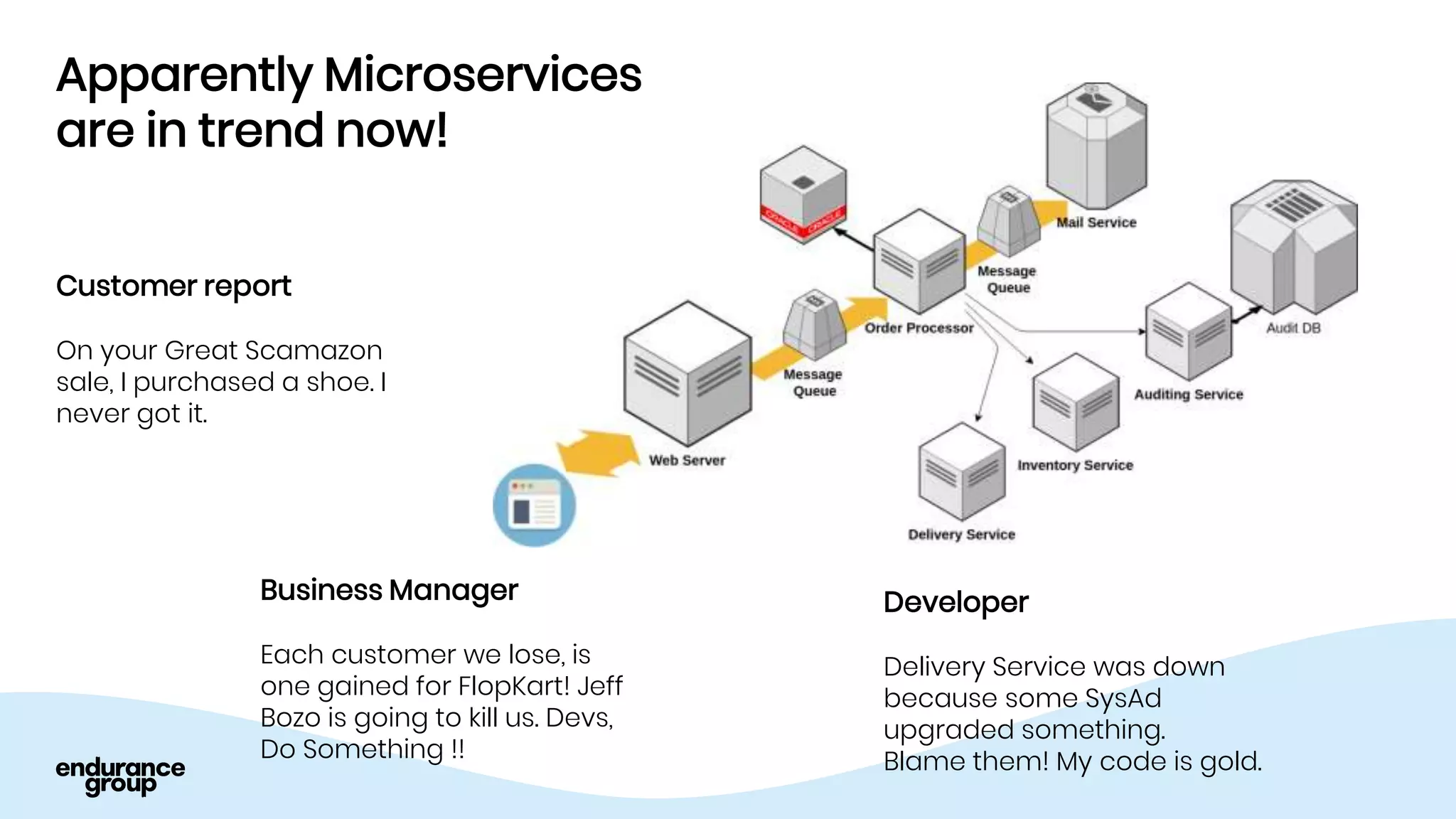
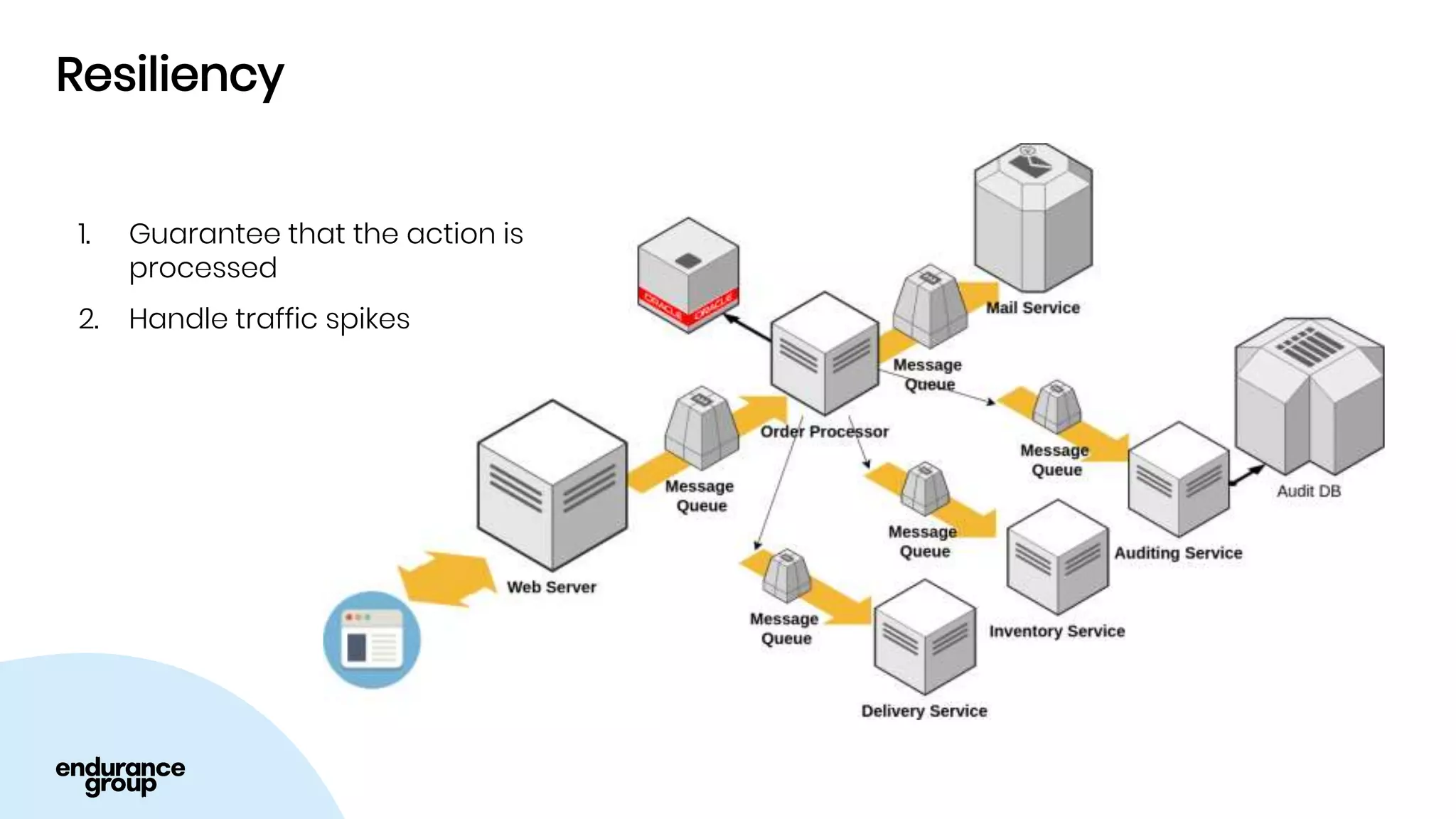
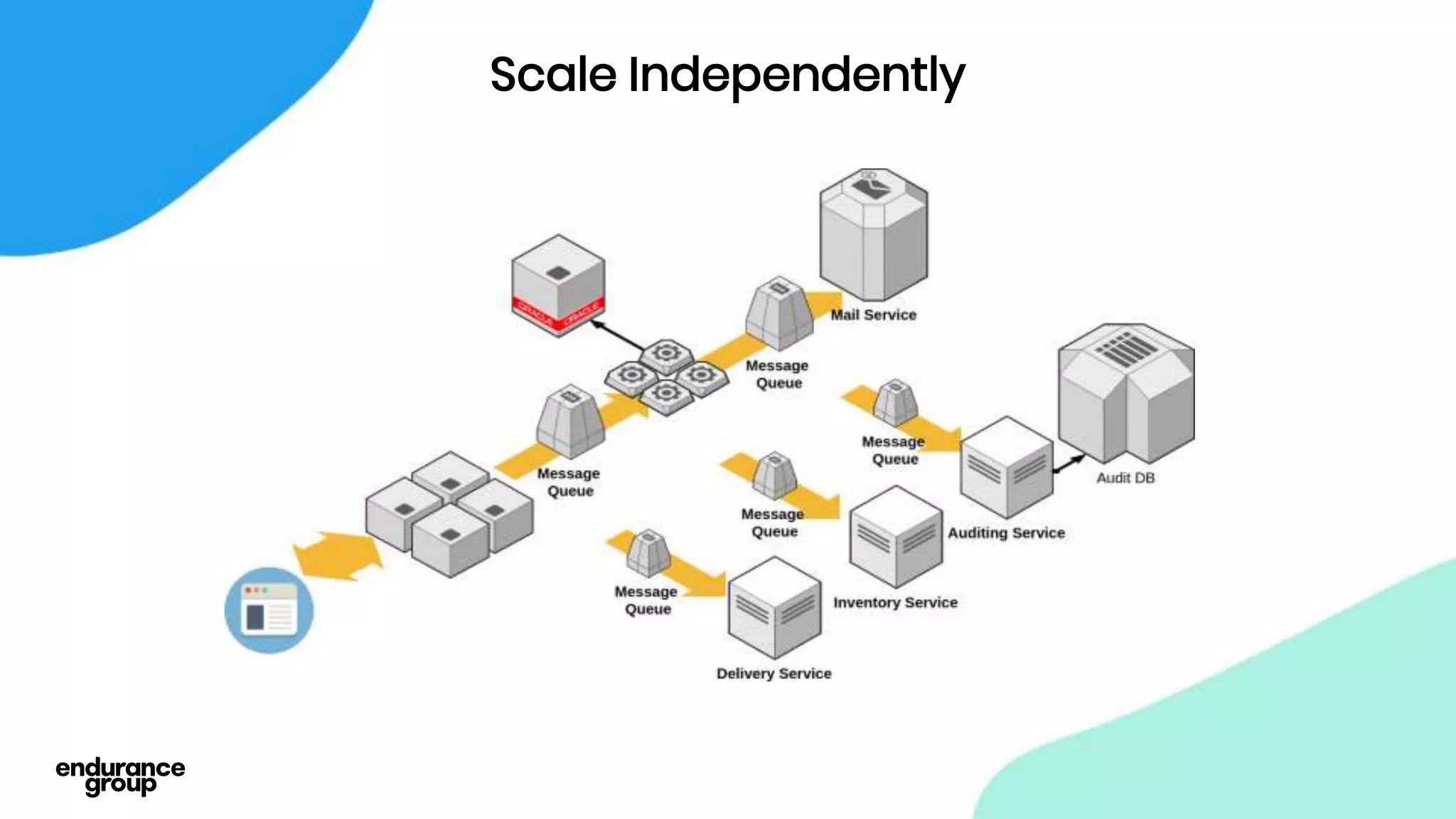
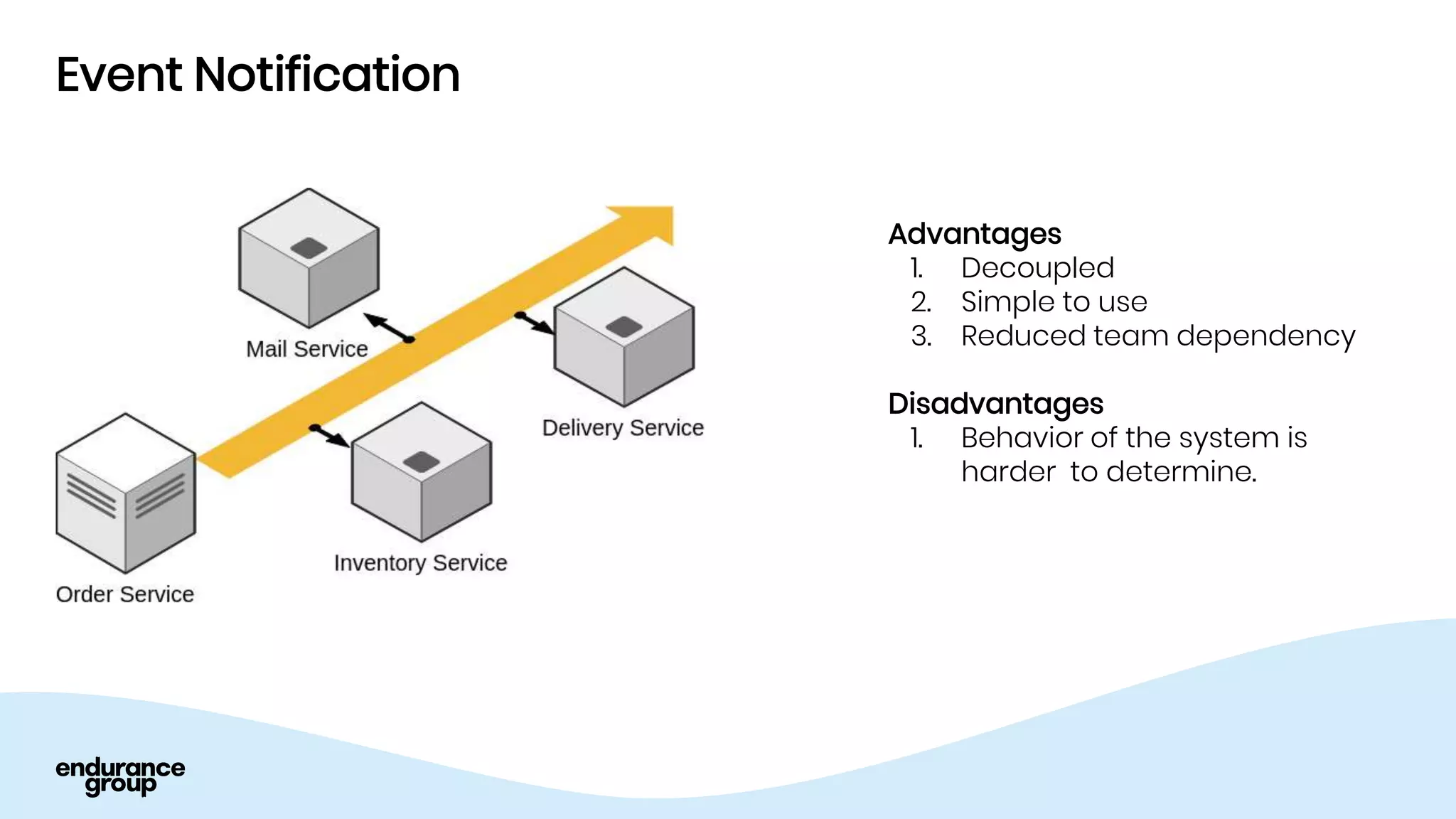
- Event driven systems allow for asynchronous and decoupled communication between services using message queues.
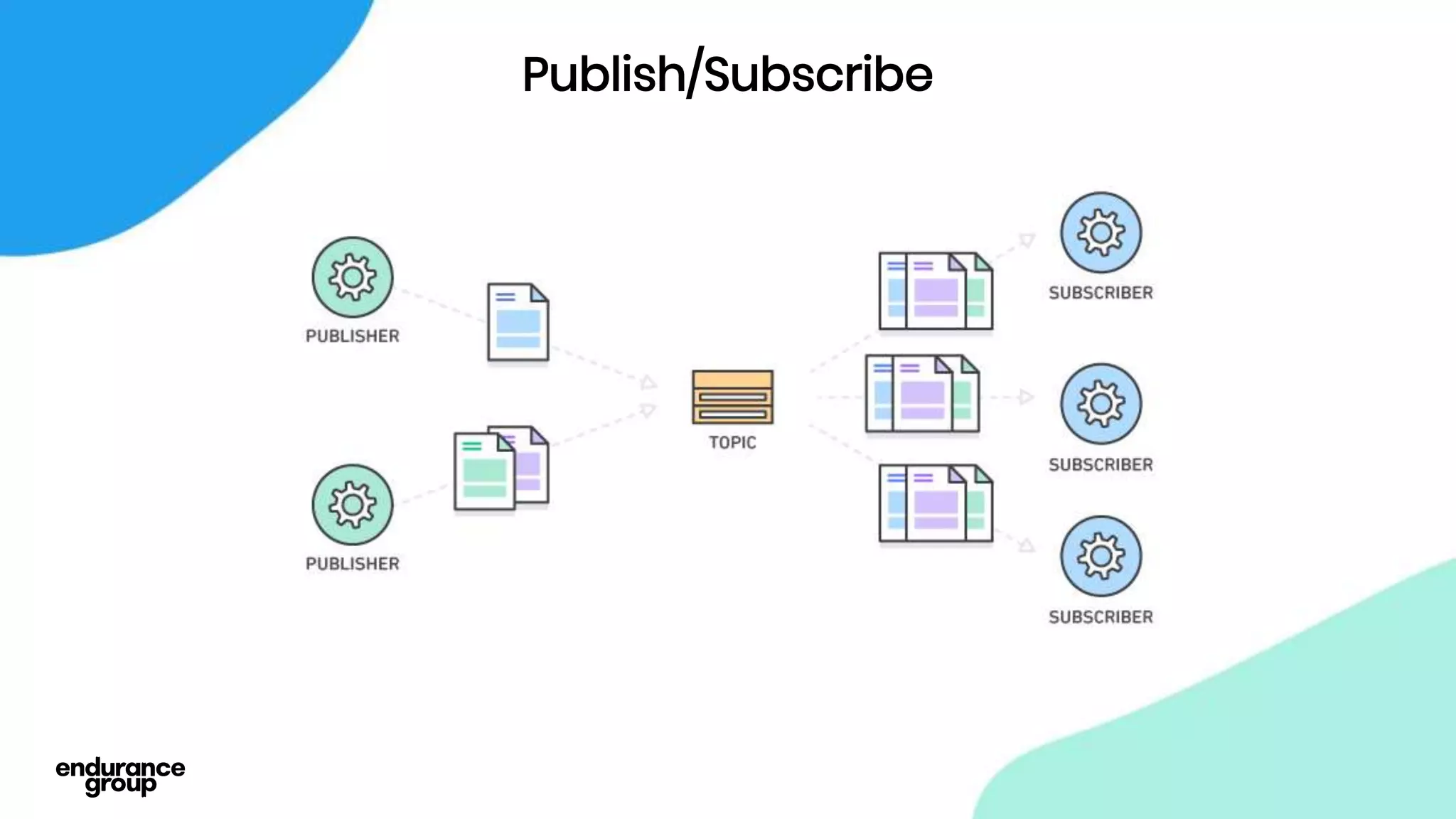
- Apache Kafka is a distributed streaming platform that allows for publishing and subscribing to streams of records across a cluster of servers. It provides reliability through replication and allows for horizontal scaling.
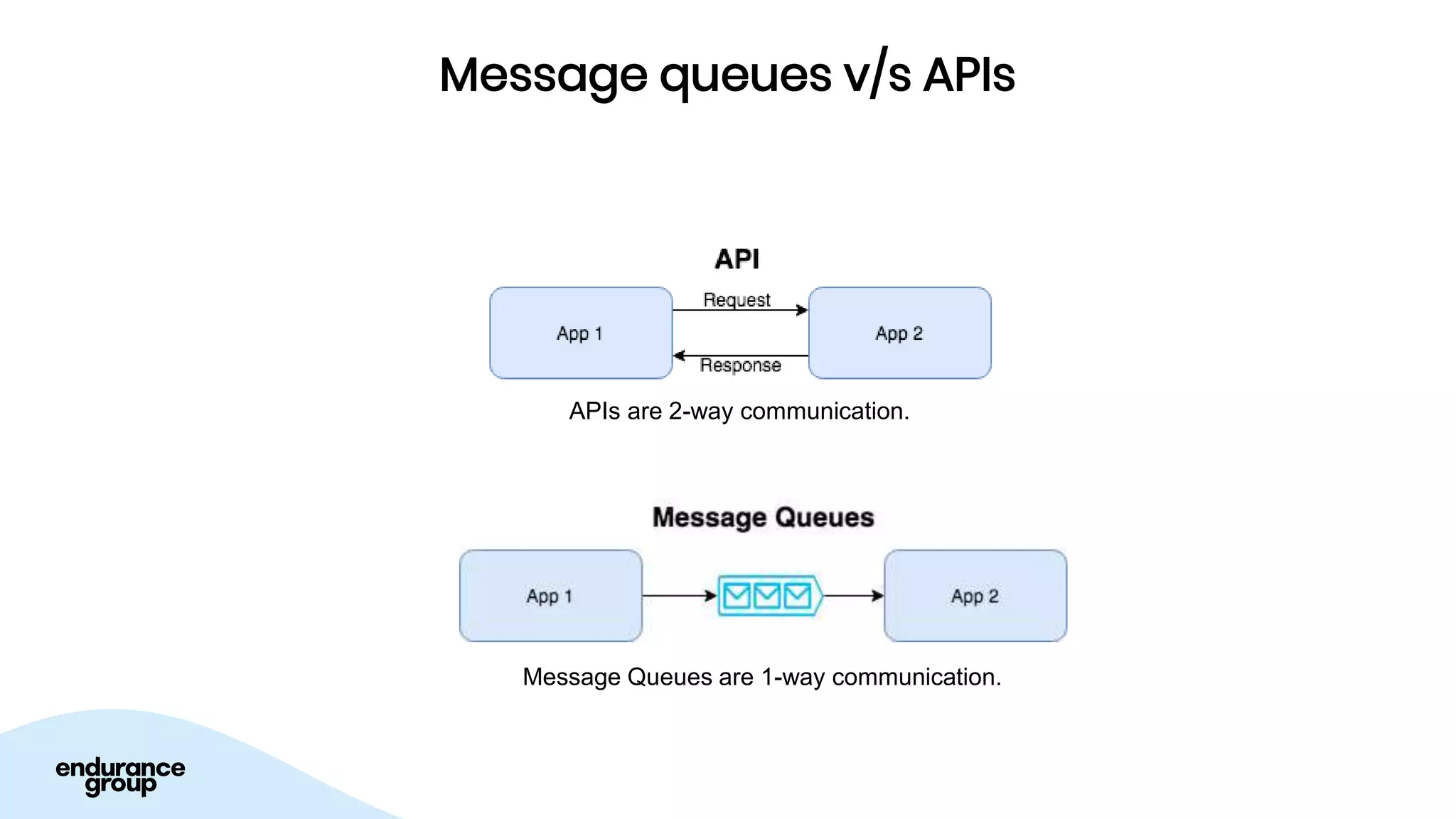
- Kafka provides advantages over traditional queues like decoupling, scalability, and fault tolerance. It also allows for publishing of data and consumption of data independently, unlike traditional APIs.









![Records in Kafka
Each Record(Message) in kafka has:
1. Key
2. Value
3. Timestamp
Key
Value
Timestamp
null
{“orderid”:1,
“cid”: 5}
1322468906767
8461
Abhishek
1592468905404
resellerhosting
{“cid”: 5,
“addons”: []}
1492468905404
Examples:](https://image.slidesharecdn.com/event-driven-arch-210929080635/75/Event-driven-arch-22-2048.jpg)