Download to read offline







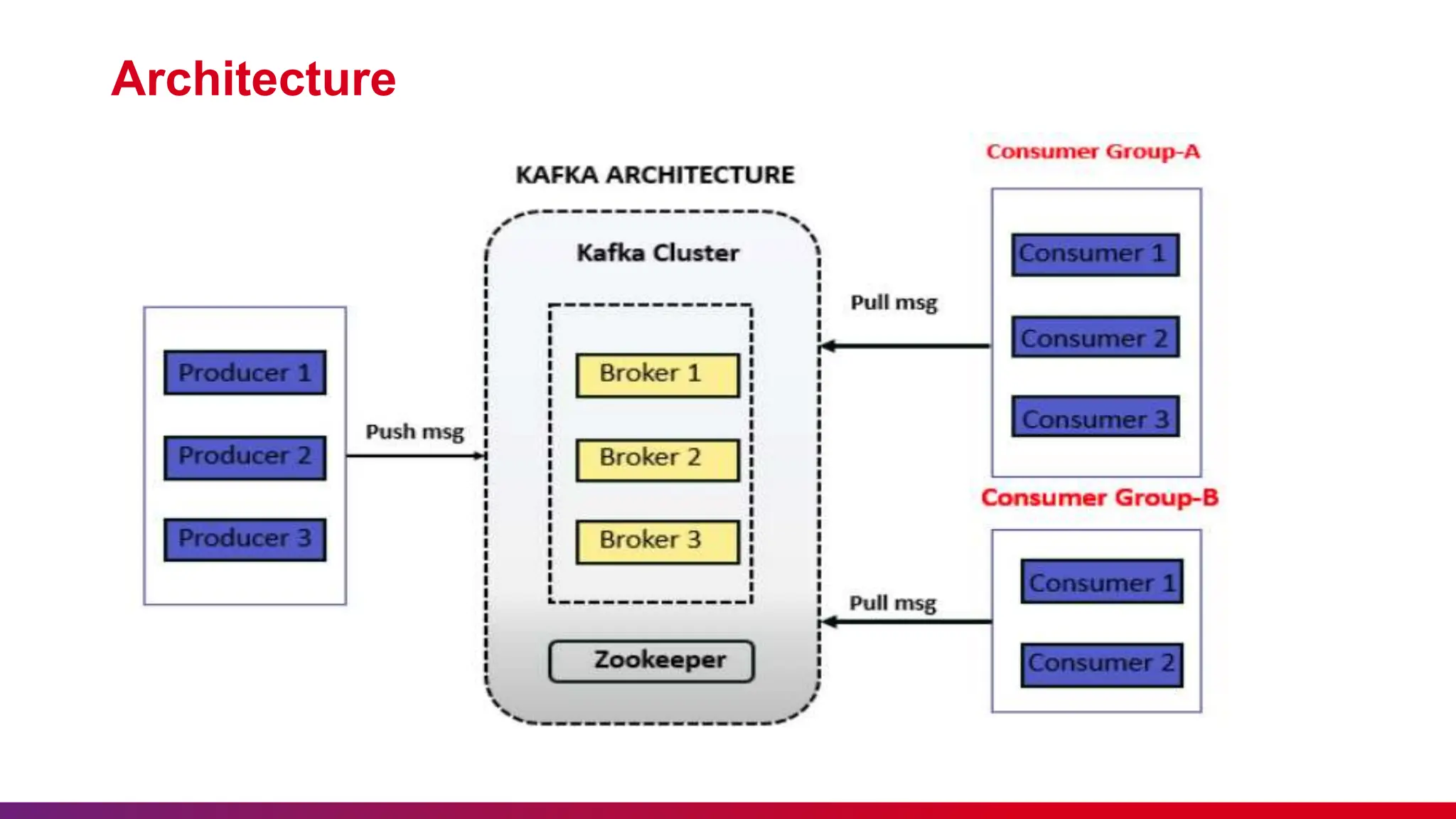









The document presents an overview of Kafka Streams, including etiquette for attendees, key concepts of messaging systems, and detailed functionalities of Apache Kafka. It discusses the architecture, advantages of Kafka Streams, and its application in real-time data processing. Additionally, it outlines the importance of feedback, punctuality, and maintaining silence during the sessions.


































![Building streaming data applications using Kafka*[Connect + Core + Streams] b...](https://cdn.slidesharecdn.com/ss_thumbnails/buildingstreamingdataapplicationsusingapachekafka-171011211455-thumbnail.jpg?width=640&height=640&fit=bounds)




















































