Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
EN
TS
Uploaded by
Takanori Sejima
15,682 views
5.6 以前の InnoDB Flushing
InnoDB のお話です
Technology
◦
Read more
37
Save
Share
Embed
Embed presentation
Download
Downloaded 91 times
1
/ 74
2
/ 74
3
/ 74
4
/ 74
5
/ 74
6
/ 74
7
/ 74
8
/ 74
9
/ 74
10
/ 74
11
/ 74
12
/ 74
13
/ 74
14
/ 74
15
/ 74
16
/ 74
17
/ 74
18
/ 74
19
/ 74
20
/ 74
21
/ 74
22
/ 74
23
/ 74
24
/ 74
25
/ 74
26
/ 74
27
/ 74
28
/ 74
29
/ 74
30
/ 74
31
/ 74
32
/ 74
33
/ 74
34
/ 74
35
/ 74
36
/ 74
37
/ 74
38
/ 74
39
/ 74
40
/ 74
41
/ 74
42
/ 74
43
/ 74
44
/ 74
45
/ 74
46
/ 74
47
/ 74
48
/ 74
49
/ 74
50
/ 74
51
/ 74
52
/ 74
53
/ 74
54
/ 74
55
/ 74
56
/ 74
57
/ 74
58
/ 74
59
/ 74
60
/ 74
61
/ 74
62
/ 74
63
/ 74
64
/ 74
65
/ 74
66
/ 74
67
/ 74
68
/ 74
69
/ 74
70
/ 74
71
/ 74
72
/ 74
73
/ 74
74
/ 74
More Related Content
PDF
binary log と 2PC と Group Commit
by
Takanori Sejima
PDF
OpenID Connect入門
by
土岐 孝平
PPTX
PostgreSQLのロール管理とその注意点(Open Source Conference 2022 Online/Osaka 発表資料)
by
NTT DATA Technology & Innovation
PDF
MySQLレプリケーションあれやこれや
by
yoku0825
PPTX
Apache Bigtopによるオープンなビッグデータ処理基盤の構築(オープンデベロッパーズカンファレンス 2021 Online 発表資料)
by
NTT DATA Technology & Innovation
PDF
MySQLバックアップの基本
by
yoyamasaki
PDF
さいきんの InnoDB Adaptive Flushing (仮)
by
Takanori Sejima
PDF
AWS Black Belt Online Seminar 2018 Amazon DynamoDB Advanced Design Pattern
by
Amazon Web Services Japan
binary log と 2PC と Group Commit
by
Takanori Sejima
OpenID Connect入門
by
土岐 孝平
PostgreSQLのロール管理とその注意点(Open Source Conference 2022 Online/Osaka 発表資料)
by
NTT DATA Technology & Innovation
MySQLレプリケーションあれやこれや
by
yoku0825
Apache Bigtopによるオープンなビッグデータ処理基盤の構築(オープンデベロッパーズカンファレンス 2021 Online 発表資料)
by
NTT DATA Technology & Innovation
MySQLバックアップの基本
by
yoyamasaki
さいきんの InnoDB Adaptive Flushing (仮)
by
Takanori Sejima
AWS Black Belt Online Seminar 2018 Amazon DynamoDB Advanced Design Pattern
by
Amazon Web Services Japan
What's hot
PDF
システムアーキテクト~My batis編~
by
Shinichi Kozake
PDF
高負荷に耐えうるWeb application serverの作り方
by
yuta-ishiyama
PDF
[Aurora事例祭り]Amazon Aurora を使いこなすためのベストプラクティス
by
Amazon Web Services Japan
PDF
Amazon Redshift パフォーマンスチューニングテクニックと最新アップデート
by
Amazon Web Services Japan
PDF
オンプレを少しずつコンテナ化する
by
Kenkichi Okazaki
PPTX
監査要件を有するシステムに対する PostgreSQL 導入の課題と可能性
by
Ohyama Masanori
PDF
Vacuum徹底解説
by
Masahiko Sawada
PDF
20190424 AWS Black Belt Online Seminar Amazon Aurora MySQL
by
Amazon Web Services Japan
PPTX
SQLアンチパターン メンター用資料
by
Hironori Miura
PDF
マイクロにしすぎた結果がこれだよ!
by
mosa siru
PPTX
SQL Server 入門
by
Tsuyoshi Kitagawa
PDF
Pacemakerを使いこなそう
by
Takatoshi Matsuo
PPTX
[社内勉強会]ELBとALBと数万スパイク負荷テスト
by
Takahiro Moteki
PDF
AWS Black Belt Online Seminar 2017 Amazon DynamoDB
by
Amazon Web Services Japan
PDF
MySQLで論理削除と正しく付き合う方法
by
yoku0825
PDF
[Games on AWS 2019] AWS 사용자를 위한 만랩 달성 트랙 | AWS에서 분산 서비스 거부 공격(DDoS)을 고민하지 않는 ...
by
Amazon Web Services Korea
PDF
MySQL負荷分散の方法
by
佐久本正太
PPTX
iostat await svctm の 見かた、考え方
by
歩 柴田
PPTX
Sql server のバックアップとリストアの基礎
by
Masayuki Ozawa
PDF
あなたの知らないPostgreSQL監視の世界
by
Yoshinori Nakanishi
システムアーキテクト~My batis編~
by
Shinichi Kozake
高負荷に耐えうるWeb application serverの作り方
by
yuta-ishiyama
[Aurora事例祭り]Amazon Aurora を使いこなすためのベストプラクティス
by
Amazon Web Services Japan
Amazon Redshift パフォーマンスチューニングテクニックと最新アップデート
by
Amazon Web Services Japan
オンプレを少しずつコンテナ化する
by
Kenkichi Okazaki
監査要件を有するシステムに対する PostgreSQL 導入の課題と可能性
by
Ohyama Masanori
Vacuum徹底解説
by
Masahiko Sawada
20190424 AWS Black Belt Online Seminar Amazon Aurora MySQL
by
Amazon Web Services Japan
SQLアンチパターン メンター用資料
by
Hironori Miura
マイクロにしすぎた結果がこれだよ!
by
mosa siru
SQL Server 入門
by
Tsuyoshi Kitagawa
Pacemakerを使いこなそう
by
Takatoshi Matsuo
[社内勉強会]ELBとALBと数万スパイク負荷テスト
by
Takahiro Moteki
AWS Black Belt Online Seminar 2017 Amazon DynamoDB
by
Amazon Web Services Japan
MySQLで論理削除と正しく付き合う方法
by
yoku0825
[Games on AWS 2019] AWS 사용자를 위한 만랩 달성 트랙 | AWS에서 분산 서비스 거부 공격(DDoS)을 고민하지 않는 ...
by
Amazon Web Services Korea
MySQL負荷分散の方法
by
佐久本正太
iostat await svctm の 見かた、考え方
by
歩 柴田
Sql server のバックアップとリストアの基礎
by
Masayuki Ozawa
あなたの知らないPostgreSQL監視の世界
by
Yoshinori Nakanishi
Similar to 5.6 以前の InnoDB Flushing
PDF
サバフェス上位入賞者にみる ioMemory×MySQL 最新チューニング教えます
by
IDC Frontier
PDF
MySQL 初めてのチューニング
by
Craft works
PPTX
dimSTATから見るベンチマーク
by
hiroi10
PDF
Devsの常識、DBAは非常識
by
yoku0825
PPT
Linux/DB Tuning (DevSumi2010, Japanese)
by
Yoshinori Matsunobu
PDF
片手間MySQLチューニング戦略
by
yoku0825
PDF
NAND Flash から InnoDB にかけての話(仮)
by
Takanori Sejima
PPT
081108huge_data.ppt
by
Naoya Ito
PDF
Innodb Deep Talk #2 でお話したスライド
by
Yasufumi Kinoshita
PDF
MySQL 5.5 Update #denatech
by
Mikiya Okuno
PDF
MySQL5.7 GA の Multi-threaded slave
by
Takanori Sejima
ODP
MySQl 5.6新機能解説@第一回 中国地方DB勉強会
by
Mikiya Okuno
PDF
Index shotgun on mysql5.6
by
yoku0825
PDF
Percona ServerをMySQL 5.6と5.7用に作るエンジニアリング(そしてMongoDBのヒント)
by
Colin Charles
PDF
サバフェス! 2015 Spring LT資料
by
Takashi Takizawa
PDF
MySQL 5.7 Technical Update (日本語)
by
Shinya Sugiyama
PDF
MySQL Cluster 新機能解説 7.5 and beyond
by
Mikiya Okuno
PDF
[db tech showcase Tokyo 2016] D24: データベース環境における検証結果から理解する失敗しないフラッシュ活用法 第三章 ~デ...
by
Insight Technology, Inc.
サバフェス上位入賞者にみる ioMemory×MySQL 最新チューニング教えます
by
IDC Frontier
MySQL 初めてのチューニング
by
Craft works
dimSTATから見るベンチマーク
by
hiroi10
Devsの常識、DBAは非常識
by
yoku0825
Linux/DB Tuning (DevSumi2010, Japanese)
by
Yoshinori Matsunobu
片手間MySQLチューニング戦略
by
yoku0825
NAND Flash から InnoDB にかけての話(仮)
by
Takanori Sejima
081108huge_data.ppt
by
Naoya Ito
Innodb Deep Talk #2 でお話したスライド
by
Yasufumi Kinoshita
MySQL 5.5 Update #denatech
by
Mikiya Okuno
MySQL5.7 GA の Multi-threaded slave
by
Takanori Sejima
MySQl 5.6新機能解説@第一回 中国地方DB勉強会
by
Mikiya Okuno
Index shotgun on mysql5.6
by
yoku0825
Percona ServerをMySQL 5.6と5.7用に作るエンジニアリング(そしてMongoDBのヒント)
by
Colin Charles
サバフェス! 2015 Spring LT資料
by
Takashi Takizawa
MySQL 5.7 Technical Update (日本語)
by
Shinya Sugiyama
MySQL Cluster 新機能解説 7.5 and beyond
by
Mikiya Okuno
[db tech showcase Tokyo 2016] D24: データベース環境における検証結果から理解する失敗しないフラッシュ活用法 第三章 ~デ...
by
Insight Technology, Inc.
More from Takanori Sejima
PDF
InnoDBのすゝめ(仮)
by
Takanori Sejima
PDF
さいきんのMySQLに関する取り組み(仮)
by
Takanori Sejima
PDF
sysloadや監視などの話(仮)
by
Takanori Sejima
PDF
TIME_WAITに関する話
by
Takanori Sejima
PDF
MySQLやSSDとかの話 その後
by
Takanori Sejima
PDF
InnoDB Table Compression
by
Takanori Sejima
PDF
MySQLやSSDとかの話 後編
by
Takanori Sejima
PDF
MySQLやSSDとかの話 前編
by
Takanori Sejima
PDF
EthernetやCPUなどの話
by
Takanori Sejima
PDF
CPUに関する話
by
Takanori Sejima
InnoDBのすゝめ(仮)
by
Takanori Sejima
さいきんのMySQLに関する取り組み(仮)
by
Takanori Sejima
sysloadや監視などの話(仮)
by
Takanori Sejima
TIME_WAITに関する話
by
Takanori Sejima
MySQLやSSDとかの話 その後
by
Takanori Sejima
InnoDB Table Compression
by
Takanori Sejima
MySQLやSSDとかの話 後編
by
Takanori Sejima
MySQLやSSDとかの話 前編
by
Takanori Sejima
EthernetやCPUなどの話
by
Takanori Sejima
CPUに関する話
by
Takanori Sejima
5.6 以前の InnoDB Flushing
1.
5.6 以前の InnoDB Flushing 瀬島
貴則 revision 2
2.
免責事項 - 本資料は個人の見解であり、私が所属する組 織の見解とは必ずしも一致しません。 - 内容の一部に偏ったものがあるかもしれません が、各自オトナの判断でよろしくお願いします。
3.
自己紹介 - わりとMySQLでごはんたべてます - 3.23.58
あたりから使ってます - 一時期は Resource Monitoring もよくやってま した - Twitter: @ts4th
4.
今日のお題 - SSDはたくさん書いたら壊れます - checkpoint
や InnoDB Adaptive Flushing や double write buffer によって発生する書き込み 処理を踏まえ - 要件を整理し - 減らせるところは書き込みを減らして - SSDの寿命を延ばせないか考えます
5.
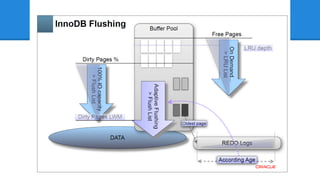
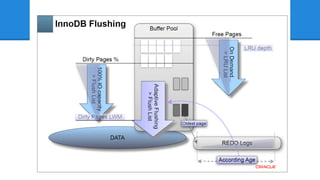
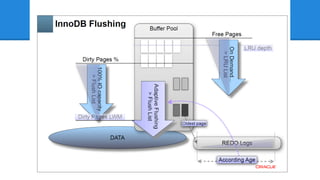
InnoDB Adaptive Flushing -
かつてInnoDB Plugin 1.0.4 で追加されました - MySQL5.5 でInnoDB本体に組み込まれました - 当時としては、わりと画期的だったんですが - 5.6 でかなり良くなりました - 次の資料から図を拝借すると、現状こうです - MySQL Performance: Demystified Tuning and Best Practices [CON5097]
7.
一つ一つ 見て行きましょう
8.
InnoDBのファイル群 - ibdata1 - internal
data dictionary・・・tableやindexのメタデータ - double write buffer・・・耐障害性上げるためのバッファ - undo log・・・rollback segment - ib_log_file* - transaction log・・・ redo logs、 write ahead log - *.ibd - table space・・・ table のdataや index
9.
redo log(write ahead
log) - 更新内容は先ず log に書いて、 table space に はあとでゆっくり反映 - 他のRDBMS でも用いられる手法 - logへの書き込みは sequential write になるの で、HDDでも速い - table space に反映するとき更新処理がまとめ られることも。 write combining
10.
Log Sequence Number(LSN) -
transaction log(ib_log_file*) のサイズは InnoDB の起動時に innodb_log_file_size で 指定して決める(固定長) - transaction log は ring buffer というか cyclic というか circular fashion - InnoDB が transaction log を初期化して以降、 log の buffer に書いてきたバイト数が Log Sequence Number。
11.
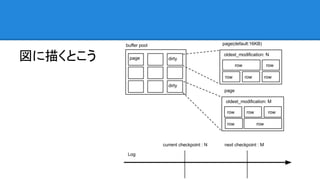
oldest_modification - page には
oldest_modification というメンバ変 数がある - その page が dirty になった最初のイベントが 書かれている log の position(LSN) が oldest_modification - dirty page をflushしてdiskに同期させると、そ の page の oldest_modification は 0 でリセッ ト
12.
Last checkpoint at -
buffer pool 上にある更新内容を、LSN 的に *. ibd にどこまで書きだしたか示すものが Last checkpoint at。 - SHOW ENGINE INNODB STATUS で見える やつ
13.
write combining - Last
checkpoint at の進み方と disk I/O は必 ずしも比例しない - 同一の page への更新は まとめて disk に flush できる - 同一の page に格納されている複数の row への更新を、一回で disk に書けることも - log に溜めこみ、まとめて flush できるとお得
14.
図に描くとこう
15.
InnoDB Adaptive Flushing -
log は有限なので使いきってはいけない - 具体的に言うと、(LSN - Last checkpoint at) が max_modified_age_sync(75%くらい)を超え ると強制的に dirty page の flush 走る - 75%というのは定数ではなく、 log/log0log.cc の log_calc_max_ages() で計算してる - なるべく強制 flush 走らないように、 adaptive に flushing する機能
16.
InnoDB Adaptive Flushing
ない時代 - InnoDB Adaptive Flushing がない頃、いずれ かの状況にならないと flush されにくかった - buffer pool 上で dirty page の比率が innodb_max_dirty_pages_pct(昔はdefault90、いまは default 75)を超える - redo log の使用率が max_modified_age_sync 超える
17.
原初の InnoDB Adaptive
Flushing - 5.1や5.5 の InnoDB Adaptive flushing は、 master_thread という background で動いてる thread が、 innodb_io_capacity に応じて 他の タスクの合間に flush してた - むかしの master_thread は goto たのしいのでいちどよ んでみるとよいです
18.
5.5以前のinnodb_io_capacity - io_capacity は正確にいうと
iops ではない - master thread が一秒間にいくつ page の i/o してもいいかという閾値 - 昔は、(select が多いなどして) disk read が多 いときは、 dirty page の flush を手加減してた - 例えば、ピークタイムに dirty page をあまり flush しない ことがあったとしたら、それは read が多いことが原因 だったり
19.
- 5.5 以前の
InnoDB Adaptive Flushing は、 io_capacity の範囲内で flush してたので - 高速なストレージだからといって io_capacity 上げすぎ ると、 write combining が効かない - redo logを溜めずにつどつどflushしてしまう
20.
もったいない
21.
ここでもう一度、 Dimitri さんの図を 思い出してみましょう
23.
5.6 で何が変わったのか - 公式ドキュメントとコードの乖離が激しくなった -
コード読もう - InnoDB team blog には意外と説明が書いてある - back ground thread の種類が劇的に増えた - 5.5以前だと master_thread でこなしていたタスクが複 数の thread で分散 - purge や dirty page の flush など特定のタスクが重 い場合、他のタスクがそれに引っ張られてしまうケー スがあったが、それが軽減された
24.
- 関連する parameter
が増えた - 重要なのはこのへん - innodb_adaptive_flushing_lwm(lwmは low water mark の略) - innodb_io_capacity - innodb_io_capacity_max - MySQL5.6 の公式ドキュメントに書いてある io_capacity 関係の記述は説明不足感 - innodb_max_dirty_pages_pct_lwm
25.
page cleaner thread -
MySQL5.5までは、 InnoDB で master thread と呼ばれる thread がいろいろやってた - dirty page の flush - change buffering - purge - 5.6 でこれらの機能が複数の thread に分割 - 5.6 で追加された thread の一つが page cleaner thread blogだと このへん
26.
flush list と
LRU list - buffer pool 上の page は、昔から二種類の list で管理されている - flush list は更新された順(oldest_modification 順)に dirty page を管理 - LRU list はすべてのpage を対象に、参照され た順に管理 - 5.6 ではpage cleaner thread がこれらに対し てback ground でタスクをこなす
27.
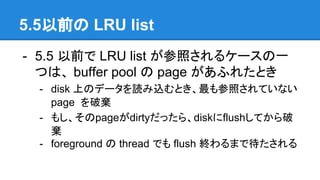
5.5以前の LRU list -
5.5 以前で LRU list が参照されるケースの一 つは、 buffer pool の page があふれたとき - disk 上のデータを読み込むとき、最も参照されていない page を破棄 - もし、そのpageがdirtyだったら、diskにflushしてから破 棄 - foreground の thread でも flush 終わるまで待たされる
28.
page cleaner thread
のタスク・その一 - 5.5以前は buffer pool をぜんぶ使い切る仕様 だったが、 5.6 からは innodb_lru_scan_depth で指定されただけ、 buffer pool の free page を残すようになった - 関数的には buf_flush_LRU_tail()
29.
buf_flush_LRU_tail() - page cleaner
thread は一定間隔でLRU listを 参照し、 innodb_lru_scan_depth で指定され ただけ free page を確保しようとする。その際、 参照されてない page から破棄する。 - page を破棄する際、 その page が dirty であ れば disk に flush する。複数あればまとめて flush する
30.
- 他のthreadは free
page 確保するために dirty page の flush を待たなくて良くなった - innodb_lru_scan_depth は、 free page 枯渇し ないなら、そんなに上げなくてもよいのでは? - buffer pool の miss hit が多い場合は検討して もよいかも
31.
page cleaner thread
のタスク・その二 - flush list を見て dirty page を flush する - 5.6でここのアルゴリズムが賢くなった - 関数的には page_cleaner_flush_pages_if_needed()
32.
page_cleaner_flush_pages_if_needed() - 一秒間にflush する
page の数を redo log の 残量に合わせてコントロールするようになった - redo log の使用率がinnodb_adaptive_flushing_lwm を超えない限りは積極的に flush しないので、write combining 狙いやすい - innodb_io_capacity_max 重要 - redo log の使用率が 60% くらいいくと io_capacity_max で指定しただけ flush する
33.
- redo log
の残量に比例して flush が激しくなる == io_capacity_max に近づくので、書き込み の多いサーバに高性能なストレージを割り当て ると、 default の設定でもそこそこ flush するよ うになった
34.
innodb_max_dirty_pages_pct_lwm - default の
0 じゃないなら - これ と これ の比較をしてflush の頻度が変わ る - transaction log より buffer poolの方がサイズ 大きいケースがほとんどだと思うので、そこまで 意識しなくてもいい気がする
35.
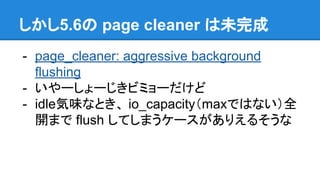
しかし5.6の page cleaner
は未完成 - page_cleaner: aggressive background flushing - いやーしょーじきビミョーだけど - idle気味なとき、 io_capacity(maxではない)全 開まで flush してしまうケースがありえるそうな
36.
- make dirty
page flushing more adaptive - すごいざっくりいうと - いまの Adaptive Flushing は flush list 優先の 仕組みで、 ほとんどのケースはうまくいくんだけ ど、 状況に応じて LRU list の flush をもっと優 先できるといいよね
37.
なるほど
38.
中の人がドキュメントで 説明したくない気持ちが わかった
39.
(めんどくさい)
40.
しょうじき 言いたい かもしれない
41.
///) /,.=゙''"/ / i
f ,.r='"-‐'つ____ こまけぇこたぁいいんだよ!! / / _,.-‐'~/⌒ ⌒\ / ,i ,二ニ⊃( ●). (●)\ / ノ il゙フ::::::⌒(__人__)⌒::::: \ ,イ「ト、 ,!,!| |r┬-| | / iトヾヽ_/ィ"\ `ー'´ /
42.
これらを踏まえて もう一度
44.
とりあえず、 5.6 では -
5.5 以前から 5.6 に移行するだけで、 Adaptive Flushing が賢くなる - SSD使ってるなら 5.6 にした方がよい - innodb_log_file_size を増やしたり、 innodb_adaptive_flushing_lwm を上げたりす るのは、SSDの書き込み寿命を伸ばすのに効 果的ですねきっと
45.
ただ、やりすぎは禁物で - innodb_log_file_size や、 innodb_adaptive_flushing_lwm
を増やすと、 クラッシュリカバリの時間ふえます。 - log_file_size がデカすぎると page cache 持っ て行かれます - innodb_io_capacity_max はうまく使いましょう
46.
あるいは、平滑化したいのであれば - innodb_flushing_avg_loops - innodb_adaptive_flushing_lwm
上げ過ぎない ほうがいいかも - 実際に検証するのが一番なんだけど - page_cleaner_flush_pages_if_needed() 読む のオススメ
47.
次に
48.
double write buffer -
耐障害性を上げるための機能 - 具体的には torn page 対策 - double write するからといって、 iops が倍にな るというわけではない。ほぼバッファリングされ る - 書き込まれる量は倍くらいになる - 詳しくは buf/buf0dblwr.cc
49.
- double write
buffer は 合計 64*2 page、 page cleaner が主に使うのはそのうちの 120 page - page cleaner が LRU list や flush list から page を flush するとき、対象の page を buf_dblwr_add_to_batch() して double write buffer にためて、最後に ibdata1 と *.ibd に書 き出す。
50.
- LRU list
や flush list から buf_dblwr_add_to_batch() で double write buffer buffer にのせてる最中に 120 page 使 いきったら、その時点で buffer から flush する
51.
やや細かく言うと - 120 page
を ibdata1 に書くときは 64*16KB と (64-8)*16KB の二回に分けて。 - メモリ上の double write buffer から ibdata1 に 書きだしたら、次は *.ibd へ io_submit() - このへんから - 最後に io_handler_thread が更新された *.ibd を fsync() して終わり
52.
閑話休題 - innodb_flush_method - O_DIRECT
で fsync() する? - O_DIRECT_NO_FSYNC - filesystem 過信しない
53.
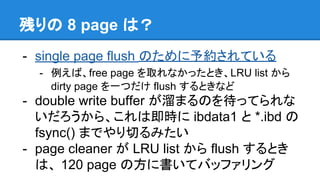
残りの 8 page
は? - single page flush のために予約されている - 例えば、free page を取れなかったとき、LRU list から dirty page を一つだけ flush するときなど - double write buffer が溜まるのを待ってられな いだろうから、これは即時に ibdata1 と *.ibd の fsync() までやり切るみたい - page cleaner が LRU list から flush するとき は、 120 page の方に書いてバッファリング
54.
つまるところ - page cleaner
が buffer pool から *.ibd に flush するところは、 buffering されている - disk へ書き出すところは double write buffer によって serialize されてる - single page flush で double write buffer を flush してるとき、 page cleaner は待たされる 可能性がある。逆もある。
55.
補足 - 5.6 の
page cleaner は buffer pool instance の数だけループを回しているところがあるんで すが、 LRU list からの flush や flush list から の flush は、そのループの中で実行されてい て、 double write buffer から ibdata1 への flush も、その中で行われるので、 instance 多 いと fsync() ふえます。
56.
考えうる残念なシナリオ - page cleaner
が flush list から大量に flush し まくってるとき(120page*N回 flush してるとき) に single page flush がくると、 single page flush と mutex 取り合いになりそう
57.
performance killer? - Dimitri
さんが double write buffer がボトルネッ クだと言うのもわかる気がする - buf_dblwr_add_to_batch() は 120 page 溜ま ると、それがはけるまで buf_dblwr->mutex とり あう可能性がある - よっぽど write intensive なときだろうけど
58.
時代が変わった - HDDだと double
write buffer 良かったと思う - いまはPCI-e SSD、コアたくさんのCPUとかあ るので、よもやまさかのボトルネックになる可能 性 - ただ、性能面に関していうと、 Dimitri さん未来 に生きてるから - 彼は未来に備えてボトルネックとなりうる要素を潰さない といけないと思うから
59.
- Dimitri さんが懸念するような問題は、現状では あまり普及してないハイエンドなサーバじゃない と発生しにくいと思うので -
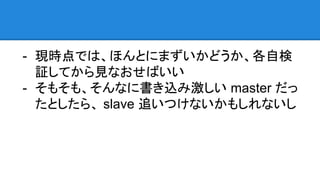
現時点では、ほんとにまずいかどうか、各自検 証してから見なおせばいい - そもそも、そんなに書き込み激しい master だっ たとしたら、 slave 追いつけないかもしれないし
60.
double write buffer
でみるところ - どれくらいの頻度で double write buffer から disk に flush されてるか気になるなら Innodb_dblwr_writes や Innodb_dblwr_pages_written を見ればOK - single page flush でも +1 されるので、 free page たりなくって Innodb_dblwr_writes 増えて るなら、 innodb_lru_scan_depth 見なおすとか
61.
double write buffer
無効化する前に - 以下の対応で性能改善できるかも - single page flush を抑制するために、 free page が枯 渇しないよう、 innodb_lru_scan_depth みなおす - flush list からの flush を最適化(write combining)する ために、 innodb_log_file_size を大きくする。 - innodb_adaptive_flushing_lwm 見直す - SSD なら innodb_flush_neighbors = 0 - 古くない page なら double write buffer に書き込む のを先送りしても良い感
62.
5.7 の Atomic
Write - Fusion-io 使うなら、MySQL5.7から Atomic Write が使えるようになる - すごいざっくり言うと、 double write しなくても書 き込みの完全性が保証される - double write buffer の代わりに atomic write 使えば、Fusion-io への書き込み減らせるし性 能も改善されるようだし良いコトずくめ
63.
ext4 の data=journal -
double write buffer の代わりに file system に 頑張ってもらう案 - Dimitri さんオススメで、 percona の人も検証し てたのですが - percona の人も言ってるけど、環境に依存する から、ちゃんとテストしてから使ったほうがいい - filesystem からだって bug は出ることがある
64.
- あと、 data=journal
にしちゃうと O_DIRECT 使えないそうな。これはツライ - https://www.kernel. org/doc/Documentation/filesystems/ext4.txt - Enabling this mode will disable delayed allocation and O_DIRECT support.
65.
あと、5.7ではこれが入る - innodb_log_write_ahead_size - 詳しくは
(4) Avoiding the ‘read-on-write’ during transaction log writing - facebook も percona もやってた件ですね - これで page cache に載り切らないくらい redo log を大きくしたときの性能が改善するので - とにかくでかくして flush 減らすのもありかも
66.
ここから先は、 人によって見解が分かれる (はずなので) 自己責任でお願いします
67.
skip-innodb-doublewrite - innodb_flush_log_at_trx_commit={0,2} なら -
そもそも、 commit 時に disk への sync が保証 されてないので、 skip しても良いのでわ - これで書き込む量ほぼ半分 - master がHAクラスタなら、slaveは検討しても よいのでわ - あるいはMHA使ってるなら
68.
innodb_log_group_home_dir - slave 壊れたとき、データ復旧しないなら -
redo log は disk 上になくてもいいんじゃない? - innodb_log_group_home_dir=/dev/shm - log_file_size は InnoDB 起動時にサイズが固 定されるので、 tmpfs 向き - もともと redo log は O_DIRECT で open され ないので、 page cache でメモリ持っていくし
69.
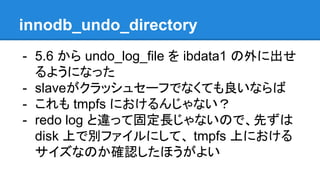
innodb_undo_directory - 5.6 から
undo_log_file を ibdata1 の外に出せ るようになった - slave 壊れたとき、データ復旧しないなら - これも tmpfs におけるんじゃない? - redo log と違って固定長じゃないので、先ずは disk 上で別ファイルにして、 tmpfs 上における サイズなのか確認したほうがよい
70.
- undo log
を ibdata1 の外に出そうとすると ibdata1 作りなおしなので、試すのがめんどくさ いけど - skip-innodb-doublewrite や redo log を tmpfs に移動するだけなら、 mysqld 再起動だけで済 むので、運用上試しやすい
71.
おまけ - 今後気になることは、このblogに書かれてる - http://mysqlserverteam.com/mysql-5-7-improves- dml-oriented-workloads/ -
Future improvements - Implementing improvements to the adaptive flushing algorithm (suggestion by Dimitri Kravtchuk) - これは実装されたらコード読みたい
72.
参考 - Configuring InnoDB
for MySQL 5.6: innodb_io_capacity, innodb_lru_scan_depth - MySQL 5.6: IO-bound, update-only workloads - InnoDB adaptive flushing in MySQL 5.6: checkpoint age and io capacity
73.
まとめ - 5.6 の
Adaptive Flushing オススメです - SSD使ってる人は5.6以降にあげましょう - log_file_size や adaptive_flushing_lvm 意識しましょう - double write buffer 切る前に - I/O減らせる要素はあります - Dimitri さんは未来に生きてます(きっと) - ともあれ、じっさいに検証しましょう
74.
おわり
Download





![InnoDB Adaptive Flushing
- かつてInnoDB Plugin 1.0.4 で追加されました
- MySQL5.5 でInnoDB本体に組み込まれました
- 当時としては、わりと画期的だったんですが
- 5.6 でかなり良くなりました
- 次の資料から図を拝借すると、現状こうです
- MySQL Performance: Demystified Tuning
and Best Practices [CON5097]](https://image.slidesharecdn.com/innodbflushing-150306180558-conversion-gate01/85/5-6-InnoDB-Flushing-5-320.jpg)




































































![[Aurora事例祭り]Amazon Aurora を使いこなすためのベストプラクティス](https://cdn.slidesharecdn.com/ss_thumbnails/amazonauroratips-170307140000-thumbnail.jpg?width=640&height=640&fit=bounds)









![[社内勉強会]ELBとALBと数万スパイク負荷テスト](https://cdn.slidesharecdn.com/ss_thumbnails/elbalb-160822022623-thumbnail.jpg?width=640&height=640&fit=bounds)


![[Games on AWS 2019] AWS 사용자를 위한 만랩 달성 트랙 | AWS에서 분산 서비스 거부 공격(DDoS)을 고민하지 않는 ...](https://cdn.slidesharecdn.com/ss_thumbnails/gamesonaws-waf-191014023704-thumbnail.jpg?width=640&height=640&fit=bounds)





















![[db tech showcase Tokyo 2016] D24: データベース環境における検証結果から理解する失敗しないフラッシュ活用法 第三章 ~デ...](https://cdn.slidesharecdn.com/ss_thumbnails/d6uypm5osrop0rxlhdef-signature-2d11c0bd82acade7267e98773c5eb2fdeb5e2d37143247ecfa1a77486c63a28f-poli-160721021336-thumbnail.jpg?width=640&height=640&fit=bounds)









