More Related Content

PPTX

PPTX
監査要件を有するシステムに対する PostgreSQL 導入の課題と可能性 
PDF

PDF

PDF

PDF
オススメのJavaログ管理手法 ~コンテナ編~(Open Source Conference 2022 Online/Spring 発表資料) 
PDF
バイトコードって言葉をよく目にするけど一体何なんだろう?(JJUG CCC 2022 Spring 発表資料) 
PDF
ヤフー社内でやってるMySQLチューニングセミナー大公開 What's hot

PPTX
PostgreSQLクエリ実行の基礎知識 ~Explainを読み解こう~ 
PDF

PDF
今からでも遅くないDBマイグレーション - Flyway と SchemaSpy の紹介 - 
PDF
PostgreSQLレプリケーション10周年!徹底紹介!(PostgreSQL Conference Japan 2019講演資料) 
PDF

PDF
ツール比較しながら語る O/RマッパーとDBマイグレーションの実際のところ 
PDF
怖くないSpring Bootのオートコンフィグレーション 
PDF
binary log と 2PC と Group Commit 
PDF

PPTX
今こそ知りたいSpring Batch(Spring Fest 2020講演資料) ![[Aurora事例祭り]Amazon Aurora を使いこなすためのベストプラクティス](https://cdn.slidesharecdn.com/ss_thumbnails/amazonauroratips-170307140000-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
[Aurora事例祭り]Amazon Aurora を使いこなすためのベストプラクティス 
PDF

PDF
アーキテクチャから理解するPostgreSQLのレプリケーション 
PDF

PDF
Part 0.5: 事例を中心としたユースケース (製造リファレンス・アーキテクチャ勉強会) 
PDF

PDF
pg_hint_planを知る(第37回PostgreSQLアンカンファレンス@オンライン 発表資料) 
PDF
【CEDEC2013】20対20リアルタイム通信対戦オンラインゲームのサーバ開発&運営技法 
PDF

PDF
NAND Flash から InnoDB にかけての話(仮) Similar to さいきんのMySQLに関する取り組み(仮)

PDF

PPTX

PDF
MySQL最新動向と便利ツールMySQL Workbench 
PDF

PDF
MySQL Cluster 新機能解説 7.5 and beyond 
PDF

PPTX
20140518 JJUG MySQL Clsuter as NoSQL 
PDF
20190530 osc hokkaido_public 
PDF

PDF

PDF
20170622_MySQL最新情報 ~MySQL 8.0 開発状況、MySQL InnoDB Cluster、などのご紹介~ by 日本オラクル株式会社... ![[db tech showcase Tokyo 2015] C27:楽天MySQL Backup Structure by 楽天株式会社 粟田啓介](https://cdn.slidesharecdn.com/ss_thumbnails/dbts-tokyo-2015c27mysqlrakuten-150617022225-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
[db tech showcase Tokyo 2015] C27:楽天MySQL Backup Structure by 楽天株式会社 粟田啓介 
PDF
MHA for MySQLとDeNAのオープンソースの話 
PDF
![[db tech showcase Tokyo 2015] C17:MySQL Cluster ユーザー事例紹介~JR東日本情報システム様における導入事例...](https://cdn.slidesharecdn.com/ss_thumbnails/dbts-tokyo-2015c17mysql-clusterhp-150619091220-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
[db tech showcase Tokyo 2015] C17:MySQL Cluster ユーザー事例紹介~JR東日本情報システム様における導入事例... 
PPTX

PDF
MySQL 5.5 Update #denatech 
PDF
Yahoo! JAPANのプライベートRDBクラウドとマルチライター型 MySQL #dbts2017 #dbtsOSS ![[D37]MySQLの真のイノベーションはこれだ!MySQL 5.7と「実験室」 by Ryusuke Kajiyama](https://cdn.slidesharecdn.com/ss_thumbnails/20131115dbtechshowcasemysql57-131119201938-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
[D37]MySQLの真のイノベーションはこれだ!MySQL 5.7と「実験室」 by Ryusuke Kajiyama 
PDF
More from Takanori Sejima

PDF

PDF
さいきんの InnoDB Adaptive Flushing (仮) 
PDF

PDF
MySQL5.7 GA の Multi-threaded slave 
PDF

PDF

PDF

PDF

PDF
さいきんのMySQLに関する取り組み(仮)
- 1.
- 2.
Copyright © GREE,Inc. All Rights Reserved.
自己紹介
● わりと MySQL のひと
● 3.23.58 から使ってる
● むかしは Resource Monitoring も力入れてやってた
● ganglia & rrdcached の(たぶん)ヘビーユーザ
● というわけで、自分は Monitoring を大事にする
● 一時期は Flare という OSS の bugfix などもやってた
● さいきんは、ハードウェアの評価をしている時間が長かった
● たまに Linux の TCP プロトコルスタックについて調べたりもする
2
- 3.
Copyright © GREE,Inc. All Rights Reserved.
● 弊社は、古くからオンプレミス環境で、 MySQL をヘビーに使ってきまし
た。
● 過去に、一部のサービスを AWS に移行した際、マネージドサービスだけ
でなく、 EC2 でも MySQL を使う構成にしまして、ここ数年でいくらかノウ
ハウが溜まってきた気もします。
● また、数年先を見据えて取り組んでいることもあります。
● 今回は、そういったあたり、お話させていただければと思います。
● わたしはいろいろ変なこと考えてますが、オンプレおじさんなので
● パブリッククラウドでは、若手たちが創意工夫して頑張ってくれてます。
本日のお話
3
- 4.
Copyright © GREE,Inc. All Rights Reserved.
● MySQL の話をする際、 InnoDB の話を避けるのが難しいので
● まだ読まれたことのない方は
● 次の資料もあわせて読んでいただけると、よりわかりやすいかと思います
● さいきんの InnoDB Adaptive Flushing (仮)
● できればこちらひととおり読んでいただけると、より理解が深まるかと思います
● https://www.slideshare.net/takanorisejima/
本日のお話の補足資料
4
- 5.
Copyright © GREE,Inc. All Rights Reserved.
● はじめに
● 弊社の環境など
● EC2 で MySQL を使うメリット
● MySQL の EC2 向けパラメータチューニング
● EC2 で MySQL 動かす上での Monitoring
● さいきん取り組んでいること
● こんご取り組んでいきたいこと
Agenda
5
- 6.
- 7.
Copyright © GREE,Inc. All Rights Reserved.
● GREE のサービスは歴史が古い
● むかしから動いてる MySQL のサーバは、かなり sharding されていた
● 2000年代、GREE は SAS HDD 146GB 15krpm * 4本使った RAID10 の前提
で、データベースを設計してるところが多かった
● そういう HDD でも動くように、データベースのサイズは100-200GB 以下のものが多
かった
● 4年くらい前までは、 MySQL 含め、ほとんど HDD で動いていた
● ioDrive ないこともなかったが、全体の数%だった
● かつてほとんど HDD で動いていたことを考えると、最近の block
device は桁違いに性能が良くて、性能面ではとても楽。
むかしの GREE のサーバ
7
- 8.
Copyright © GREE,Inc. All Rights Reserved.
● ここ数年かけて、ほぼ SATA SSD の環境になった。
● いくらか ioMemory 残っているけど、 Endurance 的には、 1DWPD から 3DWPD
程度の SSD がほとんど。
● ストレージの appliance は使っていない。SSD は SATA直結。
● disk I/O のためにネットワークの traffic が発生しないので、ネットワーク機器が安く上
がる。
● private cloud はやっていない。すべてベアメタル。
● 仮想化しないと、ハードウェアから、kernel - TCP プロトコルスタック - MySQL までの
各レイヤーに対して、調査がしやすい。
● 日本では、ランニングコストのうち、電気代の比率が高い。如何にして消費
電力効率を最適化するか、という戦略を取っている。
● NVMe ではなく SATA の SSD 使っているのも、消費電力が低いから。
さいきんの弊社のオンプレミス環境
8
- 9.
Copyright © GREE,Inc. All Rights Reserved.
● 新しいサービスは、パブリッククラウドで立ち上げている。海外展開がしや
すかったり、インスタンスの数を柔軟に調整しやすいなどのメリットが有る。
● その他、かつてオンプレで動いていたサービスの大部分、台数にして
2000台以上のサーバを、 AWS に移行してから数年が経った。
● 計画停止しにくいものをオンプレで安定稼働させつつ、計画停止できるものを、パブリック
クラウドに移行した。
● オンプレから移行してきたサービスは、マネージドサービスも活用している
が、 EC2 で MySQL を立てて運用しているところが多い。
● MySQL を failover させる仕組みは、パブリッククラウドを使う前から内製していたの
で、 failover をマネージドサービスに任せなくても運用できる。
パブリッククラウドの利用状況
9
- 10.
Copyright © GREE,Inc. All Rights Reserved.
● 現状、MySQL 5.6 か 5.7 を使っている。大部分が 5.7。
● MySQL 8.0 は検証中。
● MySQL の Extended Support の期間を意識して新しいバージョンに
移行するというより、可能であれば新しいメジャーバージョンに移行してい
きたいと考えている。
● MySQL のメジャーバージョンは、 Extended Support が終了するまでの間、 GA が
出てからだいたい8年くらいは、 security update がリリースされる。
弊社のMySQL利用状況
10
- 11.
Copyright © GREE,Inc. All Rights Reserved.
● 次のようなものが挙げられる
● Multi Source Replication など、コスト削減につながる機能が追加される。
● Multi Source Replication のおかげで、 DB の統合がとても楽になった。
● バージョンを追うごとに、 InnoDB が mutex の競合に強くなっている。メジャーバー
ジョンアップにより、 InnoDB をより堅牢強固にすることができる
● アプリケーションの不具合や障害などで、意図せず InnoDB が高負荷状態になってしまうこ
とがたまにある。しかし、さいきんの InnoDB は、 innodb_thread_concurrency などを
適切にチューニングしておけば、それでもなんとか持ちこたえてくれたりする。
● ある程度バージョンアップに追随しておけば、security update や大きい bug fix 来
たときなどに、対応しやすい。
● 環境の変化に追随しやすくする
● 現状、GTID や Group Replication がなくても運用できているが、将来はあった方が便利
だろうし
MySQL をバージョンアップする理由
11
- 12.
- 13.
Copyright © GREE,Inc. All Rights Reserved.
● MySQL は portability が高い。
● オンプレから EC2 に移行できたのも、 portability が高かったから。
● 引き続き EC2 でも素の MySQL を運用するならば、今後の状況に応じて、いろいろな
選択肢を残すことができる。
● MySQL は、時代の変化を見据えつつ、機能や性能を改善している。
● かつて私が入社した頃は、オンプレではHDD で MySQL が動いていて、 MyISAM で
動作しているサーバが、今よりも遥かに多かった。
● それから、 InnoDB やレプリケーションなどが改善された結果、最近のHW の性能を
活かせるように進化してきたので、MySQL 一台あたりの性能が改善し、むかしより集約
して台数を減らしやすくなった。
EC2 で素の MySQL を使うメリット・その1
13
- 14.
Copyright © GREE,Inc. All Rights Reserved.
● MySQL は、 Extended Support の期間や、開発のサイクルが明示さ
れている。
● これは重要。何気に超重要。
● パブリッククラウドといえど、 CPU の世代が新しくなると、 kernel や OS を新しくしたく
なる。古い kernel で新しい CPU 使うと、追加された拡張命令で不具合ふんだりするこ
ともある。
● 長年運用しているサービスで新しいOS に移行するのは、工数がかかる。OS の移行
スケジュールと併せて、 MySQL などのアップデートスケジュールを考えていきたい。
● 長期運用しているサービスであれば、OS 入れ替えたりするロードマップなどはちゃんと
考えていきたいので、ライフサイクルがわかりやすいMySQL は、とてもありがたい存
在。
● MySQL は一つのメジャーバージョンに対して8年くらいはメンテンナンスが続く。長期運
用しているサービスとしては、非常に助かる存在。
EC2 で素の MySQL を使うメリット・その2
14
- 15.
Copyright © GREE,Inc. All Rights Reserved.
● MyISAM など InnoDB 以外を使っていても、そのまま動かせる。
● MySQL 5.1 以前からやってるサービスでは、古いバックアップデータをたくさん保存す
るために、 ARCHIVE engine の DB が残っていたりする。
● マネージドサービスと異なり、何かあったらソースコードを読めばいい。
● MySQL で気になることがあれば、 MySQL のソースコードや WorkLog 読むし
● TCP 的によくわからないことがあれば、RFC や Linux の kernel 読むし
● OS まるごとチューニングしたり、調査できる余地があるので、何かあった
ときに対応の選択肢が多い。
● マイナーバージョンアップなどの決定権を、自分たちで持てる。
● バージョンアップのスケジュールを、自分たちで管理できるのは楽でいい。
EC2 で素の MySQL を使うメリット・その3
15
- 16.
Copyright © GREE,Inc. All Rights Reserved.
● slave だけ先行して新しいバージョンを試しやすい。
● 例えば、 MySQL 5.6 の master に 5.7 の slave をぶら下げて、参照を 5.7 の
slave に向けるような対応がやりやすい。
● DB の統合がやりやすい。
● instance のスケールアップをしつつ、 DB を統合して台数を削減したいとき、MySQL
5.7 の Multi Source Replication がとても使いやすい。
● 何か気になることあったとしても、マネージドサービスと違ってソースコード読めるので、安
心して使える。仮に DB 統合して、想定より高負荷になったとしても、ソースコード読めば
いい。
EC2 で素の MySQL を使うメリット・その4
16
- 17.
- 18.
Copyright © GREE,Inc. All Rights Reserved.
● 弊社の一部のサービスは、 EC2 で MySQL を運用していたので、かなり
影響を受けてしまった。
● EC2 で MySQL を使っているところは、 EBS に MySQL の datadir をおいて運用し
ているところがほとんどだったので、多くがEBS の障害に巻き込まれた。
● root volume 、あるいは datadir の volume のいずれかの EBS がハングアップす
ると、そのインスタンスは切り捨てるしかなかった。半死のmysqld が同時に多数発生し
た。
● OS再起動かかったインスタンスもあった。応答しなくなる mysqld もあった。zombie
process になってしまう mysqld もでた。障害が長時間に及んだので、 failover した先の
インスタンスで、 EBS が再びハングアップしてしまうこともあった。
2019-08-23 の東京リージョン大規模障害
18
- 19.
Copyright © GREE,Inc. All Rights Reserved.
● もともと、 MySQL の replication は、ネットワークの断に強いという認識
があった。
● master <-> slave 間の replication の接続切れたとしても、自動で再接続できるの
で
● AZ 内で大規模ネットワーク障害が発生しても、ほとんどのreplication は自動で復旧
できるという想定だった。
● かつて、何度か予期せぬ瞬断などは経験したが、 replication は自動復旧できていた。
● しかし、大規模な EBS 障害は、厳しいものだった
● datadir をおいている volume がハングアップすると、 mysqld は使い物にならなくな
る
● 複数の AZ でレプリケーションしていたし、定期的にS3 にバックアップしてたので、いち
おう復旧はできたのだが
MySQL は、断に強いと期待していた
19
- 20.
Copyright © GREE,Inc. All Rights Reserved.
現状、
EC2 で MySQL を
運用する上での構成など、
見直しているところです。
20
- 21.
- 22.
- 23.
- 24.
- 25.
Copyright © GREE,Inc. All Rights Reserved.
● 弊社は AWS で MySQL を使うとき、ほとんど EBS は gp2 で運用して
いる。
● たまに I3 インスタンス使っているところもあるが
● baseline で 1000IOPS 出なくても動く DB は、少なからずある
● かつてオンプレでは HDD で動いていた DB を、 EC2 で Multi Source Replication
で統合していったわけで。 gp2 でも HDD よりは性能が良いので。
● gp2 で動かせると、 IO 課金発生しないので、コスト削減に繋がる。
● gp2 は volume size に比例して、ある程度 IO の性能は向上するが、 volume size
は、なるべく必要最小限なままに留めている。その方が安いから。
EC2向けにInnoDBのIOを最適化する・その1
25
- 26.
Copyright © GREE,Inc. All Rights Reserved.
● MySQL の master も slave も EBS で動かせると、datadir の
snapshot とるのが楽になる。
● 弊社は伝統的に、 アプリケーションサーバから参照されないslave を配置している。
MySQL のバックアップ取るときは、アプリケーションサーバから参照されないslave で
mysqld を停止して、 datadir を tar ball に固めていた。
● EBS であれば、tar ball 取る代わりに、 datadir の volume をまるごと snapshot 取れ
ばいい。
● EBS snapshot は S3 にバックアップされるので、( S3 は少なくとも3つの AZ でデータが
保存されるから)信頼性も高い。
● slave 構築する際は、その snapshot から datadir 復元できる。
● EBS snapshot で datadir の snapshot 取る仕組みであれば、 snapshot 取るた
めの instance は、とても安価な instance で動かしても良い。
● 具体的には、使えるところは T 系ファミリーの instance を使っている。
● このあたり、若者たちが創意工夫して頑張ってくれました。
EC2向けにInnoDBのIOを最適化する・その2
26
- 27.
- 28.
Copyright © GREE,Inc. All Rights Reserved.
● volume size に比例して I/O の性能が変わる
● 1000GiB 未満の場合、 Credit balance 使い切ると I/O の性能が劣
化する
● EBS は、物理サーバに内蔵されているエンタープライズ向け SSD と比べ
ると、 latency などが不安定になることもある。
● volume size が小さくても Credit balance 残ってれば 3000IOPS で
るので、ピークタイムに Credit balance 使い切らなければ良い。
まずは gp2 について振り返る
28
- 29.
Copyright © GREE,Inc. All Rights Reserved.
● IOPS だけでなく、以下のメトリックなども取得する
● VolumeQueueLength, VolumeTotalWriteTime, VolumeTotalReadTime,
BurstBalance
● I/O が重くなって高負荷状態なサーバがあった場合、 I/O クレジット使い
切っているのか、 I/O にかかっている時間が異常なのかを切り分けられ
るようにする
● read/write にかかっている時間が想定よりも長いのであれば、そのサー
バは諦めてサービスから切り離すなどする
● また、 I/O クレジット使い切りそうなサーバがあるならば、 VolumeSize
の見直しなど行う
そして、 gp2 の monitoring をカッチリやる
29
- 30.
Copyright © GREE,Inc. All Rights Reserved.
● I/O を削減する方向で、InnoDB のチューニングを行う
● 例:
● innodb_log_file_size=1G
● innodb_io_capacity=100
● innodb_flush_log_at_trx_commit=2
● innodb_flush_neighbors=0
● skip_innodb_doublewrite=1
● サービスに投入する master や slave は、InnoDB のクラッシュリカバ
リに期待しない。台数を並べて冗長性を持たせる。
● EBS で障害が発生すると、そもそもクラッシュリカバリも実施できないから、台数を並べ
て、耐障害性を確保する。
● また、 MySQL 側だけでなく、アプリケーションサーバ側の log を収集しておくなど、別の手
段を担保しておくべきである。
● いずれにせよ、アプリケーションサーバの log は、サポート業務や Analytics のために収
集する必要があるし。
gp2 の I/O クレジットを節約するために
30
- 31.
Copyright © GREE,Inc. All Rights Reserved.
● とにかくちょっとでも I/O の burst を避けるために、
innodb_adaptive_flushing_lwm を下げて、ちょっとずつ flush させ
る。
● 例: innodb_adaptive_flushing_lwm=5
● InnoDB Adaptive Flushing で dirty page の flush がはじまって
も、innodb_adaptive_flushing_lwm を下げていると、一秒間に
flush される page の数を減らすことができる。
● innodb_adaptive_flushing_lwm を下げると、 write combining が
効きにくくなるかもしれないが、それは innodb_log_file_size を増やせ
ば良いだけのこと。
● 実際に I/O の burst が発生したとき、 gp2 だと高負荷になってしまう
ケースが有ったので、それの対策で lwm 変えた。
さらに I/O を節約
31
- 32.
- 33.
Copyright © GREE,Inc. All Rights Reserved.
現状、そんなことよりも
如何にして
EBS の障害への耐性を
改善するかの方が
重要になってきました。
33
- 34.
Copyright © GREE,Inc. All Rights Reserved.
● 古い DB で InnoDB 以外の storage engine も使っていたりするの
で、EC2 で MySQL を使うメリットは、引き続きありますし。
● EBS snapshot で MySQL のバックアップを取るというのは、有効な手
法だと思うので、おそらく今後も使う気がしていますが。
● MySQL の耐障害性をさらに改善することについて、取り組んでいく必要
性を感じています。
● 現時点でも、 master の DB が稼働しているのとは別の AZ に slave 置いて、 S3 に
バックアップ取るようにするなどしていますが
● 中途半端にハングアップしている(アクセスできなくなっている)EBS が大量発生した場
合、なかなか対応が難しい、クラッシュリカバリで救うことも難しそうなので
● じっくり対応を考えていきたいと思っています。
● MySQL は portability が高く、考えられる余地も多いですし。
EBS 障害を受けて、今後の取り組み
34
- 35.
- 36.
- 37.
Copyright © GREE,Inc. All Rights Reserved.
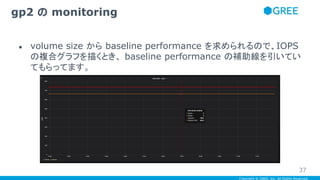
● volume size から baseline performance を求められるので、IOPS
の複合グラフを描くとき、 baseline performance の補助線を引いてい
てもらってます。
gp2 の monitoring
37
- 38.
Copyright © GREE,Inc. All Rights Reserved.
● 弊社は、オンプレでは CPU の clock を P0 state で固定して使ってい
る。
● アプリケーションの response time 改善のため、 clock を落としたくない。
● しかし、パブリッククラウドでは、ホストごと専有しない限り、 CPU の clock
を固定することは難しい。
● そのため、パブリッククラウドでも CPU の clock をメトリックとして保存す
るようにしていたのだが。
● ある日、特定の MySQL の slave だけ CPU の clock がやたら下がっ
てしまい、過負荷になってしまったことがあった。
● それ以来、 CPU の clock が明らかに低いインスタンスがあれば、 alert
を上げるようにしてもらっている。
CPU の clock を監視する
38
- 39.
Copyright © GREE,Inc. All Rights Reserved.
● オンプレと比べて、パブリッククラウドでは、どうしてもパケットの再送など
が増えてしまう。
● アプリケーションサーバだけでなく、 MySQL でも、 /proc/net/netstat
における、例えば以下のような metric は注視している
● ListenOverflows
● TCPFastRetrans
● TCPTimeouts
● TCPTimeWaitOverflow
● TCPSynRetrans
TCP のメトリック
39
- 40.
- 41.
- 42.
Copyright © GREE,Inc. All Rights Reserved.
● 弊社は、MySQL5.1のころから binlog_format=ROW 使っているサー
ビスもあるんですが、ほとんどは binlog_format=STATEMENT でし
た。
● binlog_format=STATEMENT だと、 TRIGGER で online schema change やり
やすいので
● binlog_format=STATEMENT で困っているかというと、そんなに困って
ないんですが
● ただ、さいきんの MySQL は Online DDL が改善されてきましたし、む
かしほど、サービス無停止で online schema change する必要性もなく
なってきているので
● 中長期的に考えて、 statement-based replication(SBR) から
row-based replicaton(RBR) への移行を進めています。
将来を見据えて
42
- 43.
Copyright © GREE,Inc. All Rights Reserved.
● ドキュメントには、次のような記述があります。
○ 5.2.4.2 バイナリログ形式の設定
■ レプリケーションの進行中にマスター上のバイナリロギング形式を変更したり、スレーブ上で
それを変更しなかったりすると、予期しない結果を招いたり、レプリケーションの失敗を招くこ
とがあります。
● といったことを踏まえると、安定して binlog_format=ROW にするので
あれば
SBR から RBR への移行
43
- 44.
- 45.
- 46.
- 47.
- 48.
Copyright © GREE,Inc. All Rights Reserved.
MySQL は OSS なので、
ソースコードを読んで
わたしが挙動を把握できれば
良いのでは?
48
- 49.
Copyright © GREE,Inc. All Rights Reserved.
そして、
ソースコードと WorkLog 、
bugs.mysql.com などを
読み漁った
49
- 50.
- 51.
Copyright © GREE,Inc. All Rights Reserved.
● binlog_format=ROW が導入された歴史的経緯
● binlog_format が起因で replication が止まるのはどのような場合か、
また、ソースコード的にはどのあたりでエラーになるのか
● binlog_format=ROW のとき、 binlog event はどのようにしてbinlog
に出力されるのか。
● binlog_format=ROW のとき、 online schema change はどのよう
に対応すればよいか
● binlog_format=ROW のとき、 master と slave で column の型が
異なる場合は、ソースコード的にどのように対処されているか
● binlog_row_image についてくわしく
● などなど
事前に調べたこと
51
- 52.
Copyright © GREE,Inc. All Rights Reserved.
● だいぶ真面目に調べたので、この話だけでも 40分では足りません。
● 今日のところは、ソースコード以外で読んだ blog, WorkLog,
bugs.mysql.com のチケット等を列挙しておきます。
● 詳しくは後日、ソースコード交えつつ別のかたちでご紹介したいと思いま
す。
詳しくは
52
- 53.
Copyright © GREE,Inc. All Rights Reserved.
● References
○ http://mysqlmusings.blogspot.com/2012/06/binary-log-group-commit-in-mysql-56.html
○ https://bugs.mysql.com/bug.php?id=50935
○ https://dev.mysql.com/worklog/task/?id=4033
○ https://dev.mysql.com/worklog/task/?id=5404
○ https://bugs.mysql.com/bug.php?id=23051
○ https://dev.mysql.com/worklog/task/?id=3339
○ https://dev.mysql.com/worklog/task/?id=3303
○ https://dev.mysql.com/doc/relnotes/mysql/5.7/en/news-5-7-5.html
○ https://dev.mysql.com/doc/relnotes/mysql/5.6/en/news-5-6-20.html
○ https://bugs.mysql.com/bug.php?id=85371
○ https://dev.mysql.com/doc/internals/en/event-data-for-specific-event-types.html
○ https://dev.mysql.com/worklog/task/?id=5092
○ https://dev.mysql.com/worklog/task/?id=3915
○ https://dev.mysql.com/doc/internals/en/table-map-event.html
RBRに関する資料の一部
53
- 54.
Copyright © GREE,Inc. All Rights Reserved.
● 弊社は、サービス無停止で、master 切り替えも行わず
● 稼働中の MySQL に SET GLOBAL binlog_format=ROW を実施し
て
● だいたいの DB が、 SBR から RBR への移行を完了しました。
● 一部の DB は、未だ binlog_format=STATEMENT だったりします
が、今後、じっくり取り組んでいきたいと思います
○ 例:
■ 古いシステムで、 binlog_format=STATEMENT の binlog を監査に使っているものがあ
るので、そういったところは別途対応が必要
その結果
54
- 55.
- 56.
Copyright © GREE,Inc. All Rights Reserved.
1. statement-based replication から row-based replication への移
行
2. MySQL 8.0 への移行
3. GTID への移行
4. Group Replication の導入(時間の都合上、ここだけ補足します)
今後の展望
56
- 57.
Copyright © GREE,Inc. All Rights Reserved.
● 現時点において、(個人的に)Group Replication に期待しているところ
大なので、いつか移行したいと思ってます。
● 現在、 MySQL を failover させるためのソフトウェアを社内で内製してい
るのですが、 Group Replication へ移行することで、そのメンテナンスコ
ストを減らせないかな?という期待があります。
● また、 Group Replication を導入したいという、とても大きな理由が一つ
あります。
Group Replication の導入
57
- 58.
- 59.
- 60.
Copyright © GREE,Inc. All Rights Reserved.
● IaaS を使っていると、host 側のメンテナンス、あるいはセキュリティアッ
プデートで、パブリッククラウド事業者から reboot を求められることがあり
ます。
● IaaS で動いている mysqld の台数が多いと、その対応コストが看過でき
ないものになります。
● アプリケーションサーバは auto scaling のついでに入れ替えたりできますが、
mysqld のようにデータを永続化するものでは、そうもいきません。
● オンプレでも security update のために kernel update することはあります。しか
し、余裕を持って reboot のスケジュールを自社で考えることが、パブリッククラウドでは
できないこともあります。
● 弊社では、 master の mysqld がメンテナンス対象になった場合、サー
ビス無停止で切り替えたい場合、切り替え先の master & slave のセッ
トを、まるごと新規に構築しています。
scheduled reboot の対応コスト削減
60
- 61.
Copyright © GREE,Inc. All Rights Reserved.
● 最近の MySQL の Group Replication は、 Single-Primary Mode
と Multi-Primary Mode を、動的に切り替えられるようになりました
● 普段は Single-Primary Mode で運用して
● primary server がメンテナンス対象になったときだけ、 一時的に
Multi-Primary Mode に切り替えて、 primary server を Group
Replication から外せばいいかな、と
● これができると、 IaaS で mysqld 運用するのがグッと楽になるかと
● Group Replication は今後も継続的に改善されていく機能でしょうから、
じっくり腰を据えて取り組んでいければ、と考えています
Group Replication に期待すること
61
- 62.
Copyright © GREE,Inc. All Rights Reserved.
● EBS snapshot で datadir のバックアップを取るついでに、 instance
の stop & start ができないか
● scheduled reboot の対象になっても、自動的に対応できるようになるから
● i3 や i3en などのインスタンスを、もっと活用できないか
● いままでは gp2 で安価に運用してきたが、 EBS 障害への耐性を上げたいので
● NVMe 一本専有できるインスタンスを使って、MySQL の datadir をそちらに置けない
かと。
● root volume も datadir も EBS だと、どちらか一方がハングアップしただけで使えな
くなる。しかし、 datadir が local の storage だと、root volume がハングアップしな
い限りは、 EBS の障害に耐えられるようになる。
● また、i3 の NVMe はかなり高性能なので、 Multi-Threaded slave と組み合わせつ
つ、台数を集約できそうな余地はある。
その他、EC2でやっていきたいこと
62
- 63.