Downloaded 24 times



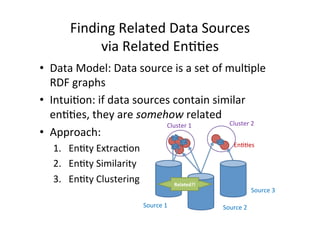
![Related
En&&es
(2)
1. En&ty
Extrac&on
– Sample
over
en&&es
in
data
graphs
in
D
– For
each
en&ty
crawl
its
surrounding
sub-‐graph
[1]
2. En&ty
Similarity
– Define
dissimilarity
measure
between
two
en&&es
based
on
kernel
func&ons
– Compare
en&ty
structure
and
literals
via
different
kernels
[2,3]
3. En&ty
Clustering
– Apply
k-‐means
clustering
to
discover
similar
en&&es
[4]](https://image.slidesharecdn.com/semstats-131021223958-phpapp02/85/Discovering-Related-Data-Sources-in-Data-Portals-7-320.jpg)





![References
[1]
G.
A.
Grimnes,
P.
Edwards,
and
A.
Preece.
Instance
based
clustering
of
seman:c
web
resources.
In
ESWC,
2008.
[2]
U.
Lösch,
S.
Bloehdorn,
and
A.
Reenger.
Graph
kernels
for
RDF
data.
In
ESWC,
2012.
[3]
J.
Shawe-‐Taylor
and
N.
Cris&anini.
Kernel
Methods
for
PaPern
Analysis.
2004.
[4]
R.
Zhang
and
A.
Rudnicky.
A
large
scale
clustering
scheme
for
kernel
k-‐means.
In
PaVern
Recogni&on,
2002.](https://image.slidesharecdn.com/semstats-131021223958-phpapp02/85/Discovering-Related-Data-Sources-in-Data-Portals-17-320.jpg)

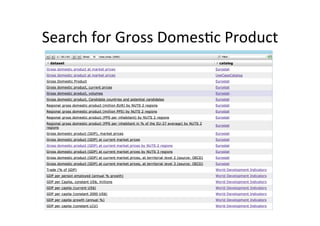
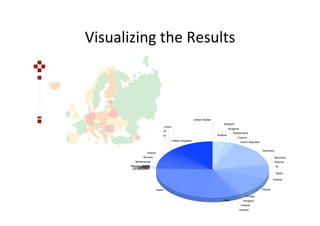
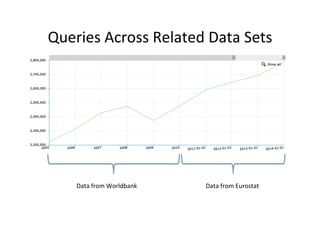
The document discusses methods for discovering related data sources within data portals, emphasizing the importance of integrating and querying multiple open data sets. It outlines a framework utilizing entity extraction, similarity measures, and clustering to identify complementary data sources, illustrated through examples like GDP comparisons. Additionally, it presents future work on user interfaces for querying across data sets and enhancing interactive visualizations.













































































