Download as PDF, PPTX






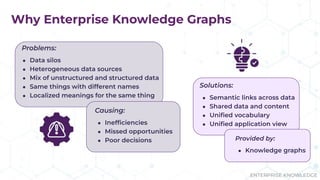
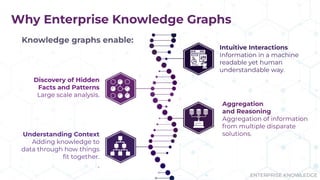

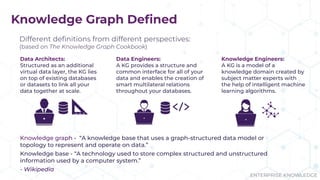
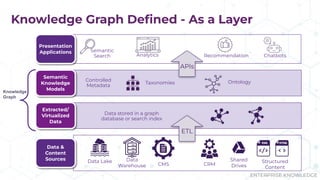

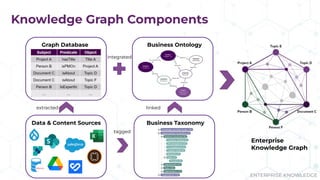
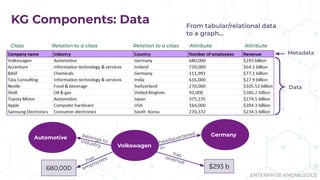
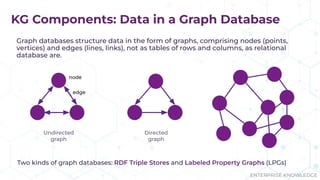
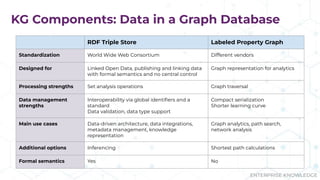








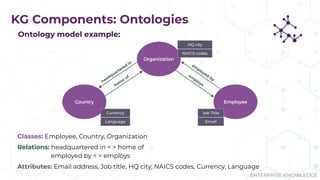





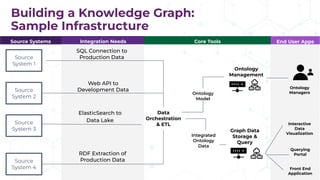


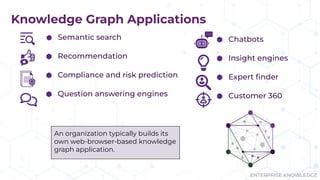


The document discusses the concept of enterprise knowledge graphs, emphasizing the importance of semantics in managing structured and unstructured data across siloed systems. It outlines the components, definitions, and applications of knowledge graphs, including taxonomies and ontologies, and their role in enabling enhanced data discovery and insights. The presentation also highlights the challenges of data silos and heterogeneous sources while proposing knowledge graphs as a solution for improving data interoperability and decision-making.























































































