Recommended
PPTX
PPTX
[DL輪読会]Set Transformer: A Framework for Attention-based Permutation-Invariant...
PPTX
Differentiable neural conputers
PDF
[第2版]Python機械学習プログラミング 第13章
PDF
PPTX
Hessian-free Optimization for Learning Deep Multidimensional Recurrent Neural...
PDF
Guiding neural machine translation with retrieved translation pieces
PDF
PPTX
PDF
PDF
Learning Phrase Representations using RNN Encoder-Decoder for Statistical Mac...
PPTX
PDF
PDF
ACL Reading @NAIST: Fast and Robust Neural Network Joint Model for Statistica...
PDF
PPTX
Sequence Level Training with Recurrent Neural Networks (関東CV勉強会 強化学習論文読み会)
PPTX
A convolutional encoder model for neural machine translation
PDF
PDF
Query and output generating words by querying distributed word representatio...
PDF
[DL輪読会]Convolutional Sequence to Sequence Learning
PDF
Generalized data augmentation for low resource translation
PPT
PDF
Semantic_Matching_AAAI16_論文紹介
PDF
PPTX
PDF
PDF
[修論発表会資料] 目的言語の文書文脈を用いたニューラル機械翻訳
PPTX
第3回アジア翻訳ワークショップの人手評価結果の分析
PDF
Bi-Directional Block Self-Attention for Fast and Memory-Efficient Sequence Mo...
PDF
Lexically constrained decoding for sequence generation using grid beam search
More Related Content
PPTX
PPTX
[DL輪読会]Set Transformer: A Framework for Attention-based Permutation-Invariant...
PPTX
Differentiable neural conputers
PDF
[第2版]Python機械学習プログラミング 第13章
PDF
PPTX
Hessian-free Optimization for Learning Deep Multidimensional Recurrent Neural...
PDF
Guiding neural machine translation with retrieved translation pieces
PDF
Similar to Memory-augmented Neural Machine Translation
PPTX
PDF
PDF
Learning Phrase Representations using RNN Encoder-Decoder for Statistical Mac...
PPTX
PDF
PDF
ACL Reading @NAIST: Fast and Robust Neural Network Joint Model for Statistica...
PDF
PPTX
Sequence Level Training with Recurrent Neural Networks (関東CV勉強会 強化学習論文読み会)
PPTX
A convolutional encoder model for neural machine translation
PDF
PDF
Query and output generating words by querying distributed word representatio...
PDF
[DL輪読会]Convolutional Sequence to Sequence Learning
PDF
Generalized data augmentation for low resource translation
PPT
PDF
Semantic_Matching_AAAI16_論文紹介
PDF
PPTX
PDF
PDF
[修論発表会資料] 目的言語の文書文脈を用いたニューラル機械翻訳
PPTX
第3回アジア翻訳ワークショップの人手評価結果の分析
More from Satoru Katsumata
PDF
Bi-Directional Block Self-Attention for Fast and Memory-Efficient Sequence Mo...
PDF
Lexically constrained decoding for sequence generation using grid beam search
PDF
Deep Neural Machine Translation with Linear Associative Unit
PDF
Corpora Generation for Grammatical Error Correction
PDF
On the Limitations of Unsupervised Bilingual Dictionary Induction
PDF
Exploiting Monolingual Data at Scale for Neural Machine Translation
PDF
How Contextual are Contextualized Word Representations?
PDF
Understanding Back-Translation at Scale
PDF
Incorporating Syntactic and Semantic Information in Word Embeddings using Gra...
PDF
PDF
Memory-augmented Neural Machine Translation 1. 2. 概要
● NMTの低頻度語 (infrequent words) をうまく扱えてない問題に焦点を当てた。
○ memory-augented NMT (M-NMT) を提案
○ 各単語の(特に低頻度語に対しての)翻訳を memoryに貯めて、従来のneural modelの翻訳を手伝う
モデル
● out-of-vocabulary (OOV) 問題についても取り組んだ。
● 実験: Chinese-Englishを2task
○ 従来のNMT(memoryなし)と比べてM-NMTはそれぞれ9.0 BLEUと2.7 BLEU向上した
2
3. 4. 原因は’neural’ ?
● 低頻度の分散表現が微妙とか考えられるけど、そもそも ↓
‘the deeper reason should be attributed to the nature of neural models.’
○ 高頻度語を翻訳するとき、低頻度語を翻訳するとき、どちらも共通のパラメータを用いる。
高頻度語が学習データの大部分を占めているのだから結果として出来上がったモデルは高頻度語
により焦点を当てたものになるはず。
なんなら低頻度語は学習中にノイズになって無視されるまである。
● 一方でSMT
○ NMTと比べてパラメータ共有全然しない。
高頻度語は低頻度語対に対してそれほど全然影響を与えない。
ただし、データが十分にあれば NMTの方がSMTより良さげ。
4
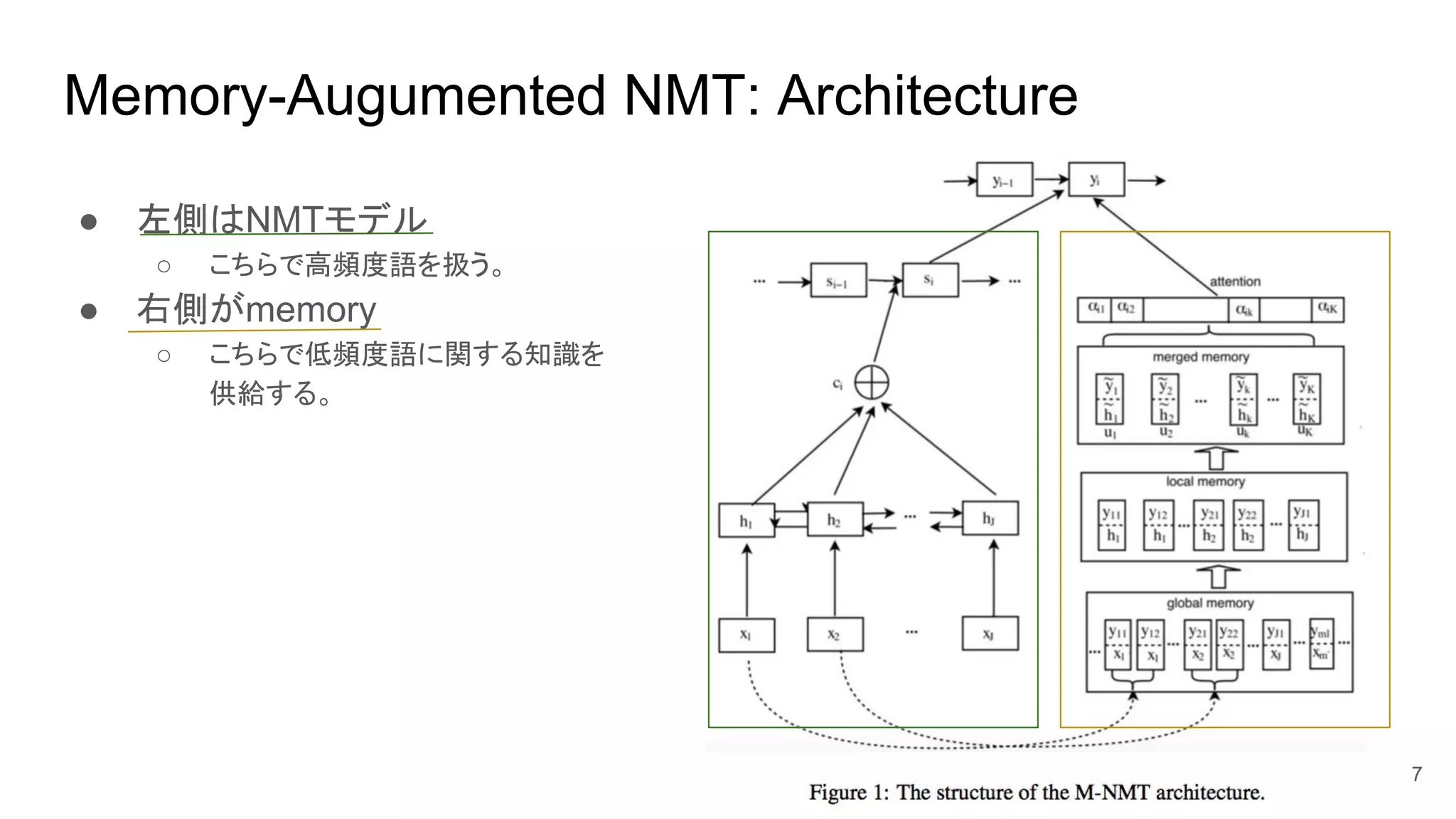
5. 6. NMTモデル (Bahdanau et al., 2015)
● attentionに基づくモデル。
○ encoder-decoderの構造
○ encoder: 双方向GRU
○ attention: 下の式で i番目の単語を出力する際に j番目のsrcの隠れ層をどれくらい見るか (α) を計
算、そのαに基づいて各ステップ iのcontext vector c_iを求める。
○ decoder: context vector c_i、1つ前の出力y_i-1とhidden state s_i-1をrecurrent function (GRU)
に通して隠れ層s_iを更新する。← (1)式
(2)式のようにsoftmax (σ) に通してy_iの確率を求める。
j
a(*,*): MLP (Multiple Layer Perceptron) based relevance function
(関連度合いを測る)
attention decoder
6
g(): maxout ← y_i-1, s_i-1, c_iを活性化関数に通してz_iを求める。
このz_iを(パラメタWで)単語ベクトルの次元に持っていきsoftmax
h: encoder hidden state
s: decoder hidden state
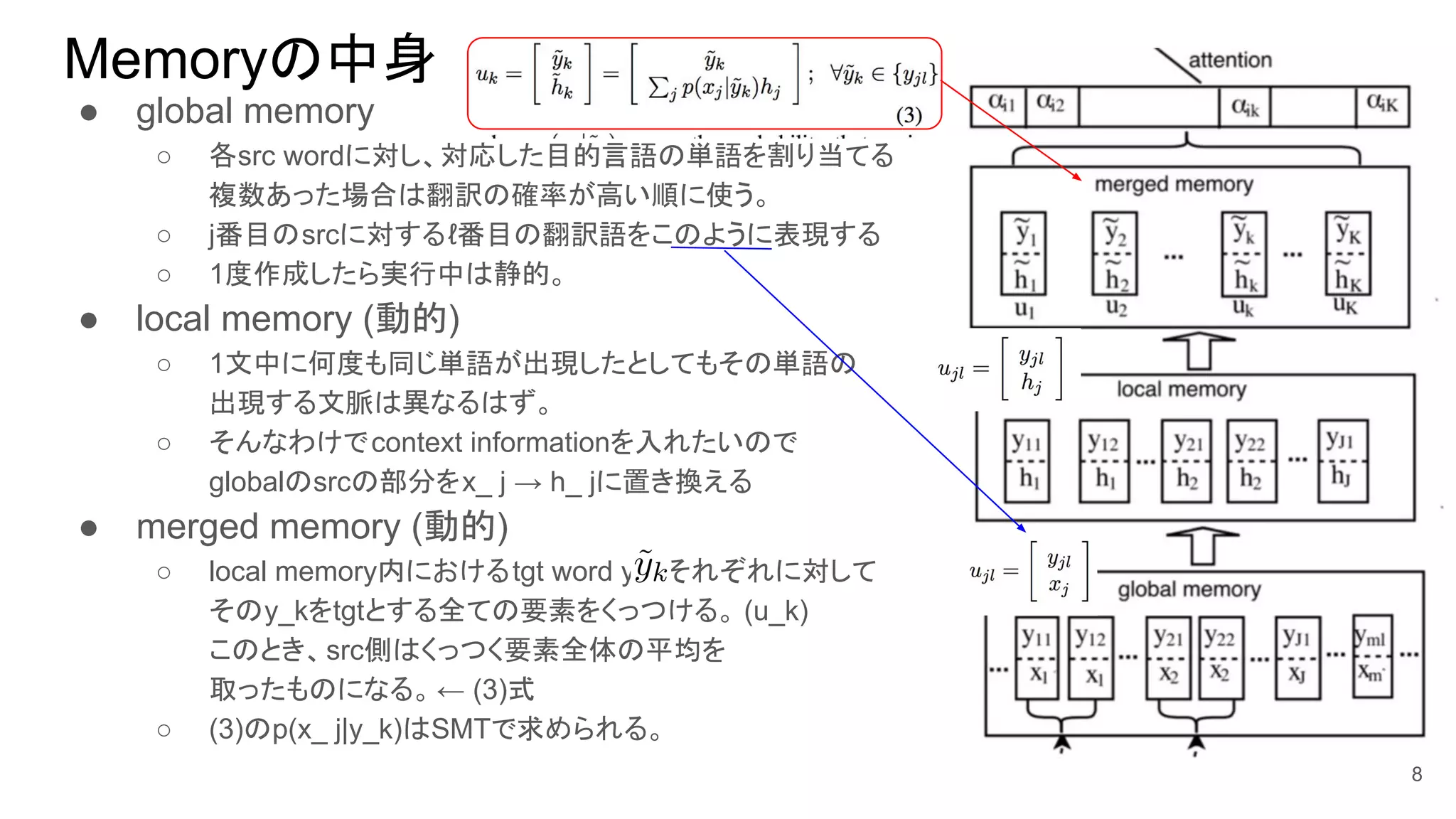
7. 8. Memoryの中身
● global memory
○ 各src wordに対し、対応した目的言語の単語を割り当てる
複数あった場合は翻訳の確率が高い順に使う。
○ j番目のsrcに対するℓ番目の翻訳語をこのように表現する
○ 1度作成したら実行中は静的。
● local memory (動的)
○ 1文中に何度も同じ単語が出現したとしてもその単語の
出現する文脈は異なるはず。
○ そんなわけでcontext informationを入れたいので
globalのsrcの部分をx_ j → h_ jに置き換える
● merged memory (動的)
○ local memory内におけるtgt word y_kそれぞれに対して
そのy_kをtgtとする全ての要素をくっつける。 (u_k)
このとき、src側はくっつく要素全体の平均を
取ったものになる。← (3)式
○ (3)のp(x_ j|y_k)はSMTで求められる。
8
9. Memory Attention: 構造
● NMTに類似したattention機構を用いてmemoryから適切な要素を取ってくる。
○ 各u_kに対してのstep iの時のattention factorをα_ikとする。(iの時にu_kをどれだけ見るか)
○ attention factorはneural modelのdecoder state s_i-1と1つ前の出力y_i-1、merged memoryの要
素u_kを用いて求める。
○ memory attentionのパラメータは
● attention factorは次の単語を出力する確率として使用する。
○ attention factorはmemory内の単語に基づいて正規化を行う。
語彙の単語全てで正規化を行なっていないため近似になっているが、実験はうまくいった。
○ 具体的には→ (p(y_i)は式(2)で求めた確率)
9
K: merged memory内のtgt wordsの数
β: 事前に決めておく係数
attention
10. k_iはmerged memoryにおける
y_iの位置
Memory Attention: 学習
● memory attentionはneural modelとは別に学習を行う。
● 目的関数
○ できるだけ正確にmemoryにattentionを張れるようにしたい。
→ 学習中におけるn番目seqでstep iのとき、現在の単語y_iならtgt attentionは1であるべきで、そうで
なければ0になるはず。
○ というわけで、目的関数は tgt attentionとattention functionの出力のcross entropyで記述される。
○ を最適化していく。最適化アルゴリズムは AdaDeltaを用いる。
● 同時にmemoryとneural modelを学習も可能ではある。
○ だが、大量のGPUメモリや過学習の危険がある。
→ 今回はmemoryのみ学習した。
● パラメータβについて
○ βを調整することでmodelとmemory、どちらを見るか最適化することは可能だろう。
だが、学習データへの過学習を避けるために制約を慎重に定める必要がある。
10
11. 12. OOVに対する処理
● 人手でOOV wordがどのように翻訳されるかを指定した辞書を用いた。
○ この辞書はlocal memory構築時に知識として用いられる。
○ 具体的には、srcやtgtでOOV wordがあったとき、類似語のベクトルを用いて OOV wordを表現す
る。
→ この類似語を人手で定義する。
○ ただし、あるOOV wordの類似語として定義した単語がその OOV wordと同じ文に存在するべきで
はないため、各OOV wordに対していくつかの候補を定義しておく。
○ ただしneural modelはOOV wordの確率は出力できないので、ある OOV wordに対する類似語をそ
のOOV wordで上書きすることでその類似語の予測が OOV wordへ’リダイレクト’される。(表層形:
OOV word、vector: similar wordでやってる?)
12
13. Related Work
● neural networks + external memoryは結構ある
○ NMT + memory (Wang et al., 2016) ← memoryをdecoder stateの拡張に用いた。
提案手法が’辞書’だとしたら、これは’ノート用紙’。
● NMT + SMTも結構ある
○ ただし多くはSMTベース。
○ Cohn ら (2016) はNMT + アライメント情報でより attentionを当てる研究を行った。
○ Arthurら (2016) が今回と近いこと(語彙の知識を用いて特に低頻度語の翻訳を手助けする)を
行っている。
違いとしては、Arhturら: tgt wordを選ぶためにattention情報を用いる。
提案手法: src wordとtgt wordに基づいて別々のattentionを学習している。
● OOV処理の関連研究
○ 色々ある。が、今回は Luong ら (2015) とLi ら (2016) と比較する。
○ LuongらもLiらも後処理を用いる手法だが、提案手法は前処理寄りである。
(OOVの類似語決めてるから)
decoderがどのtgtが適切か、各OOVに対して複数のtgtを簡単に扱うことができるため、
この手法は後処理手法よりも柔軟性がある。(結局類似語を用いてしまっているが) 13
太字 → 今回の比較対象
14. 実験: Data (Chinese - English)
● IWSLT (小さいデータ)
○ 学習データ: 44k sents (旅行系)
○ 開発データ: IWSLT2005のASR devset 1とdevset 2
○ テストデータ: IWSLT 2005のtest set
● NIST(大きいデータ)
○ 学習データ: 1M sents (19M src tokens and 24M tgt tokens) ← LDCコーパスから持ってきた。
○ 開発データ: NIST 2002 test set
○ テストデータ: NIST 2003 test set
● Memory data
○ GIZA++を用いた。
○ global memoryは IWSLTで80K、NISTで500Kのサイズだった。
○ 各単語対は の値でフィルターをかけた。 (w_t: tgt word、w_s: src_word)
○ 各 src wordに対して多くとも2つのtgt wordを持つように設定。
14
15. 実験: System
● SMT
○ Mosesのデフォルト設定。
● NMT
○ Bahdnauら (2015) のやつを再実装したもの。 GroundHogと比べてそんな変わんない感じ。
● M-NMT
○ neural model: NMT (↑)
○ memoryのattentionだけ学習した。
学習中にtgt wordが<unk>だったりtgt wordがmemoryの中になかったらback-propagationはス
キップする。
○ memory attentionを計算するときに decoderの隠れ層と1つ前の出力、merged memory を見るわ
けだが、どれが効いているのか調べたい。
具体的には、’Attending’としてdecoderの隠れ層や1つ前の出力をつけたり外したり、
‘Attended’としてmerged memory、特にsrc側とtgt側をそれぞれつけたり外したりしてみた。
● setting
○ NMTとM-NMTは同一の設定。
hidden units: 500、embedding: 310、vocab: 30k、batch: 80、optim: AdaDelta、beam: 5 15
16. Result: 最初の推測は正しかったのか
● IWSLTでSMT強い
○ そもそも datasetが小さいから。
○ NISTのように大量のデータを使うと NMTの方が
よくなる。
● M-NMTはどの設定でも素のNMTより良い
○ attention計算に必要なものを足していくと
どんどん良くなっていることがわかる。
○ best systemはbaselineのNMTよりそれぞれ9.0 BLEUと2.7 BLEUの向上が見られる。
○ 特にIWSLTの方はSMTよりもよくなっている 。
→ NMTは低頻度語を扱う構造を用いる必要があるという推測を支持している。
(NMTとmemoryの組み合わせが1番良かった)
○ IWSLTの結果を見るとlow-resource taskに用いて良さそうである。
16
NMT-Lが元論文より低い理由は neural modelを
再学習していないため。
(今回の提案手法との比較)
17. Experiments: OOVの処理
● NISTコーパスに対してOOV wordを含んだ312 test sents を用い、さらにこれを2
つに分ける。
○ src側のみにOOV wordが入っているT-INV set
○ src、tgtどちらにもOOV wordが入っているT-OOV set
○ src側の491 OOV wordに対して、tgtが語彙として入っているのが 276単語
tgtもOOV wordであるのは215単語
● 各 OOV word に対して次の3つの要素を含む翻訳テーブルを作成する。
○ 1. その翻訳語 2.その類似語 3. もしその翻訳もOOVだったら翻訳語の類似語
○ 今回は↑を人手で行った。
(OOV wordのいくつかはシステムに対して完全に新しいものである可能性があるから)
● 今回の実験の提案手法で用いたモデルは1つ目の実験で1番良かった全部使う奴
○ OOVの処理とかしてない M-NMTと↑のOOVの処理を行ったM-NMT + OOVを比べる。
(あとLunong ら(2015) NMT-PL)
17
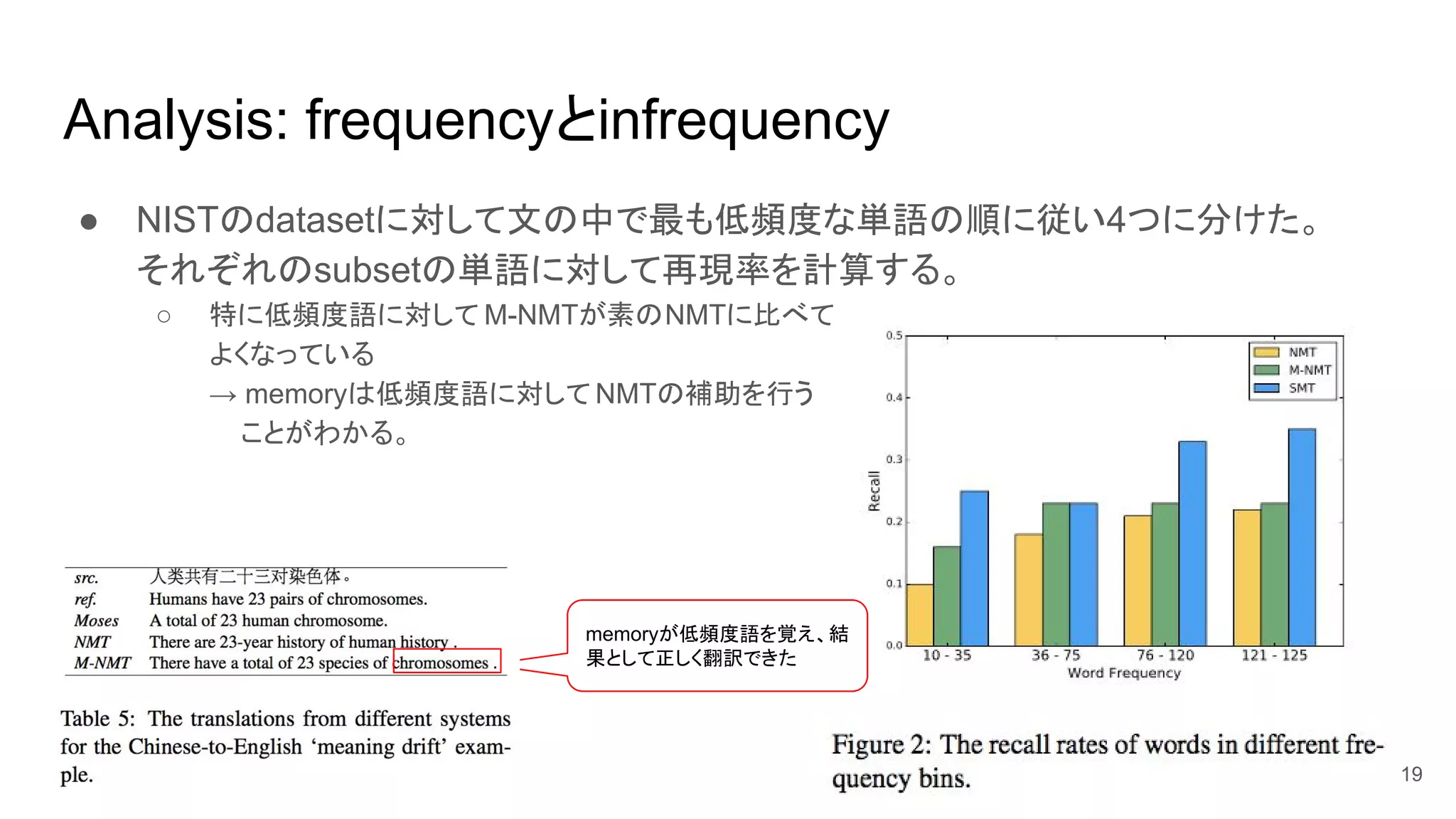
18. Result: OOVの処理
● 今回はBLEU以外にOOV の再現率も調べた。
○ 正しく翻訳されたOOV wordの割合。
● 素のNMTやM-NMTは全然ダメ。
○ tgt側が語彙に含まれているときはちょっとだけ ...
● NMT-PLとM-NMT+OOV
○ NMT-PLでも再現率はそれほど高くない。
○ 一方でM-NMT+OOVの再現率が高く、OOV memoryを用いることは有効であることがわかる。
○ Li ら (2016) による手法も実装したが、 T-INVが 13.9 BLEU、T-OOVが 13.3 BLEUと低かった。
これはneural modelの再学習を行っていないからかもしれない。
18
19. 20. まとめ
● memory-augmented NMTを提案した。
○ NMT + memory
○ memory: neural modelだけでは充分学習できない単語の翻訳を手伝う役割を持つ。
○ Chinese - Englishの2つのコーパスでそれぞれ 9.0と2.7 BLEU向上した。
● 柔軟性があり、効果的なOOVの処理も行った。
○ OOVの再現率はtgt wordがINVで28%、OOVで40%で他の手法より大幅に改善した。
● future work
○ modelとmemoryをもっといい感じに統合したい
○ 例えばjoint学習とか
● 個人的感想
○ 1つ目の実験でSMTよりよくなったのはすごいと思った。(小並感)
1つ目の実験で、SMTと比べてNMT+memoryがどう良くなったのか(おそらく程頻度周りだと思う
が)そのあたりの例が欲しかった。
○ memory attentionがテストの時にどれだけ当てられているか知りたかった。 20
21. 参考文献
● Neural machine translation by jointly learning to align and translate.
Bahdanau et al., ICLR 2015
● Memory-enhanced decoder for neural machine translation. Wang et al.,
EMNLP 2016
● Incorporating structural alignment biases into an attentional neural translation
model. Cohn et al., NAACL 2016
● Incorporating discrete translation lexicons into neural machine translation.
Arthur et al., EMNLP 2016
● Addressing the rare word problem in neural machine translation. Luong et al.,
ACL 2015
● Towards zero unknown word in neural machine translation. Li et al., IJCAI
2016 21



















![[DL輪読会]Set Transformer: A Framework for Attention-based Permutation-Invariant...](https://cdn.slidesharecdn.com/ss_thumbnails/20200221settransformer-200221020423-thumbnail.jpg?width=640&height=640&fit=bounds)

![[第2版]Python機械学習プログラミング 第13章](https://cdn.slidesharecdn.com/ss_thumbnails/13-190318023252-thumbnail.jpg?width=640&height=640&fit=bounds)















![[DL輪読会]Convolutional Sequence to Sequence Learning](https://cdn.slidesharecdn.com/ss_thumbnails/dl0519-170519005603-thumbnail.jpg?width=640&height=640&fit=bounds)






![[修論発表会資料] 目的言語の文書文脈を用いたニューラル機械翻訳](https://cdn.slidesharecdn.com/ss_thumbnails/shuronpresen-191012004831-thumbnail.jpg?width=640&height=640&fit=bounds)











