2
DNN-HMMからEnd-to-End方式へ
p 音声認識 (ASR): 系列から系列への変換問題
n 音声信号系列を全く性質の異なるシンボル系列へ変換
p 従来方式 : DNN-HMMハイブリッドモデル
n 音響モデル / 言語モデル等の多数のモジュールで構成
n システム全体の最適化が困難
p End-to-End (E2E) 方式: CTC / Seq2Seqモデル
n 単一のネットワークのみで処理が完結
n システム全体の最適化が容易
2018/09/12 日本音響学会秋季研究発表会 1-2-9「End-to-End音声認識のためのMulti-Head Decoderネットワーク」
“あらゆる現実を…”
本研究ではE2E方式の認識率向上に着目
3.
3
p E2E-ASRのための2つのアイデアを提案
本研究の貢献
2018/09/12 日本音響学会秋季研究発表会1-2-9「End-to-End音声認識のためのMulti-Head Decoderネットワーク」
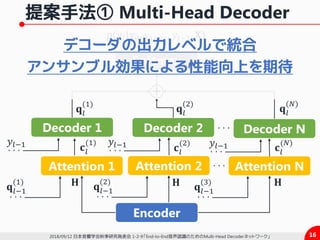
1) E2E-ASRのためのMulti-Head Decoder (MHD)
ü Multi-Head Attention (MHA) を拡張
ü 各々のAttentionに対して異なるデコーダを割当
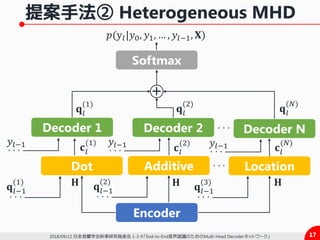
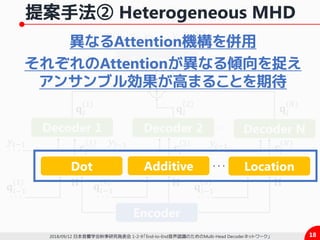
2) 異種のAttentionを併用したHeterogeneous MHA
ü MHAにおいて異種のAttentionを混合して利用
ü 各々のAttentionが異なる傾向を捉えることを可能に
実験的評価によりWERの改善を確認 (10.2 % -> 9.0 %)
それぞれのデコーダが異なる傾向を捉えていることを
Attentionのアライメントから示唆
25
結論と今後の課題
結論
p Heterogeneous MHDを提案
p実験的評価により提案法の有効性を確認
n 平均 CER 10.2 % -> 9.0 %
n 異種のAttentionを併用することの有効性を示唆
n デコーダの出力レベルでの統合の有効性を示唆
今後の課題
p エラー分析
p 他言語のデータセットへの適用
p Attentionの組み合わせの影響の調査
p Head数の影響の調査
2018/09/12 日本音響学会秋季研究発表会 1-2-9「End-to-End音声認識のためのMulti-Head Decoderネットワーク」
26.
26
ESPnet (宣伝)
p E2E音声処理ツールキット
nオープンソース (Apache 2.0)
n Chainer or Pytorch バックエンド
p Kaldi-likeなレシピサポート
n 25の言語 / 15個のレシピ (WSJ, CSJ, …)
p ASRだけでなくTTSもサポート
n Tacotron2-based TTSシステムが構築可能
2018/09/12 日本音響学会秋季研究発表会 1-2-9「End-to-End音声認識のためのMulti-Head Decoderネットワーク」







![8
CTC-based E2E-ASR [Graves+, 2014]
2018/09/12 日本音響学会秋季研究発表会 1-2-9「End-to-End音声認識のためのMulti-Head Decoderネットワーク」
Encoder
Softmax
𝐱" 𝐱#・・・・
𝑝(𝑦"|𝐗) ・・・ 𝑝(𝑦#|𝐗)
𝐇 = {𝐡", 𝐡/, … , 𝐡#}
Encoder
Attention
Encoder
Softmax
𝐱" 𝐱#・・・・
𝐇
𝐜3
𝑦34"
・・・
・・・
・・・
𝐪34"
𝐚34"
𝐪3
𝑝(y3|𝑦8, 𝑦", … , 𝑦34", 𝐗)
① CTC-based ② Attention-based
音響特徴量系列
エンコーダ隠れ状態系列
出力シンボル事後確率](https://image.slidesharecdn.com/201809asjhayashi-181202052440/85/End-to-End-Multi-Head-Decoder-8-320.jpg)
![9
CTC-based E2E-ASR [Graves+, 2014]
2018/09/12 日本音響学会秋季研究発表会 1-2-9「End-to-End音声認識のためのMulti-Head Decoderネットワーク」
Encoder
Softmax
𝐱" 𝐱#・・・・
𝑝(𝑦"|𝐗) ・・・ 𝑝(𝑦#|𝐗)
𝐇 = {𝐡", 𝐡/, … , 𝐡#}
Encoder
Attention
Encoder
Softmax
𝐱" 𝐱#・・・・
𝐇
𝐜3
𝑦34"
・・・
・・・
・・・
𝐪34"
𝐚34"
𝐪3
𝑝(y3|𝑦8, 𝑦", … , 𝑦34", 𝐗)
① CTC-based ② Attention-based
J 発音辞書が不要
L 依然として条件付き
独立性の仮定を利用
L 過去の出力系列を考慮した
予測が不可能](https://image.slidesharecdn.com/201809asjhayashi-181202052440/85/End-to-End-Multi-Head-Decoder-9-320.jpg)
![10
Attention based E2E-ASR [Chorowski+, 2014]
2018/09/12 日本音響学会秋季研究発表会 1-2-9「End-to-End音声認識のためのMulti-Head Decoderネットワーク」
Encoder
Softmax
𝐱" 𝐱#・・・・
𝑝(𝑦"|𝐗) ・・・ 𝑝(𝑦#|𝐗)
𝐇 = {𝐡", 𝐡/, … , 𝐡#}
Encoder
Attention
Decoder
Softmax
𝐱" 𝐱#・・・・
𝐇
𝐜3
𝑦34"
・・・
・・・
・・・
𝐪34"
𝐚34"
𝐪3
𝑝(y3|𝑦8, 𝑦", … , 𝑦34", 𝐗)
① CTC-based ② Attention-based
出力シンボル事後確率
デコーダ隠れ状態
コンテキスト特徴
過去の出力シンボル
過去のデコーダ隠れ状態
過去のAttention重み](https://image.slidesharecdn.com/201809asjhayashi-181202052440/85/End-to-End-Multi-Head-Decoder-10-320.jpg)
![11
Attention based E2E-ASR [Chorowski+, 2014]
2018/09/12 日本音響学会秋季研究発表会 1-2-9「End-to-End音声認識のためのMulti-Head Decoderネットワーク」
Encoder
Softmax
𝐱" 𝐱#・・・・
𝑝(𝑦"|𝐗) ・・・ 𝑝(𝑦#|𝐗)
𝐇 = {𝐡", 𝐡/, … , 𝐡#}
Encoder
Attention
Decoder
Softmax
𝐱" 𝐱#・・・・
𝐇
𝐜3
𝑦34"
・・・
・・・
・・・
𝐪34"
𝐚34"
𝐪3
𝑝(y3|𝑦8, 𝑦", … , 𝑦34", 𝐗)
① CTC-based ② Attention-based
J 発音辞書が不要
J 一切の仮定が不要
L 入力と出力の対応が
非因果的になる
可能性あり](https://image.slidesharecdn.com/201809asjhayashi-181202052440/85/End-to-End-Multi-Head-Decoder-11-320.jpg)
![12
よりよいAttentionを求めて
Joint CTC-attention [Kim+, 2015]
p CTCとAttentionのマルチタスク学習
Multi-Head Attention [Chiu+. 2018]
p 複数のAttentionを計算した後統合して利用
2018/09/12 日本音響学会秋季研究発表会 1-2-9「End-to-End音声認識のためのMulti-Head Decoderネットワーク」](https://image.slidesharecdn.com/201809asjhayashi-181202052440/85/End-to-End-Multi-Head-Decoder-12-320.jpg)
![13
よりよいAttentionを求めて
Joint CTC-attention [Kim+, 2015]
p CTCとAttentionのマルチタスク学習
Multi-Head Attention [Chiu+. 2018]
p 複数のAttentionを計算した後統合して利用
2018/09/12 日本音響学会秋季研究発表会 1-2-9「End-to-End音声認識のためのMulti-Head Decoderネットワーク」
本研究ではこちらの手法の拡張を提案](https://image.slidesharecdn.com/201809asjhayashi-181202052440/85/End-to-End-Multi-Head-Decoder-13-320.jpg)
![14
Multi-Head Attention [Vaswani+, 2018]
2018/09/12 日本音響学会秋季研究発表会 1-2-9「End-to-End音声認識のためのMulti-Head Decoderネットワーク」
𝑦34"
・・・
𝐪3
𝑝(y3|𝑦8, 𝑦", … , 𝑦34", 𝐗)
Attention 1
・・・
𝐪34"
Softmax
Decoder
Attention 2
・・・
𝐪34"
𝐇
Attention N
・・・
𝐪34"
・・・
𝐇𝐇
Encoder
Linear
𝐜3
(/)
𝐜3
(9)
𝐜3
(")
𝐜3](https://image.slidesharecdn.com/201809asjhayashi-181202052440/85/End-to-End-Multi-Head-Decoder-14-320.jpg)


![20
実験結果
Method Eval1-CER [%] Eval2-CER [%] Eval3-CER [%]
Single-Dot 12.7 9.8 10.7
Single-Add 11.1 8.4 9.0
Single-Location 11.7 8.8 10.2
MHA-Dot 11.6 8.5 9.3
MHA-Add 10.7 8.2 9.1
MHA-Location 11.5 8.6 9.0
MHD-Location 11.0 8.4 9.5
HMHD (dot+add+loc+cov) 11.0 8.3 9.0
HMHD (2*loc+2*cov) 10.4 7.7 8.9
2018/09/12 日本音響学会秋季研究発表会 1-2-9「End-to-End音声認識のためのMulti-Head Decoderネットワーク」](https://image.slidesharecdn.com/201809asjhayashi-181202052440/85/End-to-End-Multi-Head-Decoder-20-320.jpg)
![21
実験結果
Method Eval1-CER [%] Eval2-CER [%] Eval3-CER [%]
Single-Dot 12.7 9.8 10.7
Single-Add 11.1 8.4 9.0
Single-Location 11.7 8.8 10.2
MHA-Dot 11.6 8.5 9.3
MHA-Add 10.7 8.2 9.1
MHA-Location 11.5 8.6 9.0
MHD-Location 11.0 8.4 9.5
HMHD (dot+add+loc+cov) 11.0 8.3 9.0
HMHD (2*loc+2*cov) 10.4 7.7 8.9
2018/09/12 日本音響学会秋季研究発表会 1-2-9「End-to-End音声認識のためのMulti-Head Decoderネットワーク」
MHAの利用による性能の向上を確認](https://image.slidesharecdn.com/201809asjhayashi-181202052440/85/End-to-End-Multi-Head-Decoder-21-320.jpg)
![22
実験結果
Method Eval1-CER [%] Eval2-CER [%] Eval3-CER [%]
Single-Dot 12.7 9.8 10.7
Single-Add 11.1 8.4 9.0
Single-Location 11.7 8.8 10.2
MHA-Dot 11.6 8.5 9.3
MHA-Add 10.7 8.2 9.1
MHA-Location 11.5 8.6 9.0
MHD-Location 11.0 8.4 9.5
HMHD (dot+add+loc+cov) 11.0 8.3 9.0
HMHD (2*loc+2*cov) 10.4 7.7 8.9
2018/09/12 日本音響学会秋季研究発表会 1-2-9「End-to-End音声認識のためのMulti-Head Decoderネットワーク」
タスク3以外でMHDによる性能向上を確認](https://image.slidesharecdn.com/201809asjhayashi-181202052440/85/End-to-End-Multi-Head-Decoder-22-320.jpg)
![23
実験結果
Method Eval1-CER [%] Eval2-CER [%] Eval3-CER [%]
Single-Dot 12.7 9.8 10.7
Single-Add 11.1 8.4 9.0
Single-Location 11.7 8.8 10.2
MHA-Dot 11.6 8.5 9.3
MHA-Add 10.7 8.2 9.1
MHA-Location 11.5 8.6 9.0
MHD-Location 11.0 8.4 9.5
HMHD (dot+add+loc+cov) 11.0 8.3 9.0
HMHD (2*loc+2*cov) 10.4 7.7 8.9
2018/09/12 日本音響学会秋季研究発表会 1-2-9「End-to-End音声認識のためのMulti-Head Decoderネットワーク」
HMHDが最も良い性能を達成
提案手法の有効性を確認](https://image.slidesharecdn.com/201809asjhayashi-181202052440/85/End-to-End-Multi-Head-Decoder-23-320.jpg)






![[DL輪読会]Diffusion-based Voice Conversion with Fast Maximum Likelihood Samplin...](https://cdn.slidesharecdn.com/ss_thumbnails/20220318akuzawa-220322065615-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Parallel WaveNet: Fast High-Fidelity Speech Synthesis](https://cdn.slidesharecdn.com/ss_thumbnails/0105-180105000252-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Wavenet a generative model for raw audio](https://cdn.slidesharecdn.com/ss_thumbnails/wavenetagenerativemodelforrawaudio-160920054055-thumbnail.jpg?width=640&height=640&fit=bounds)








![[DL輪読会]data2vec: A General Framework for Self-supervised Learning in Speech,...](https://cdn.slidesharecdn.com/ss_thumbnails/220204nonakadl1-220204025334-thumbnail.jpg?width=640&height=640&fit=bounds)










![[DL輪読会]Wav2CLIP: Learning Robust Audio Representations From CLIP](https://cdn.slidesharecdn.com/ss_thumbnails/dlwav2clip1-211105022837-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DL輪読会]VOICEFILTER: Targeted Voice Separation by Speaker-Conditioned Spectrog...](https://cdn.slidesharecdn.com/ss_thumbnails/20181116dlvoicefiltertargetedvoiceseparationbyspeaker-conditionedspectrogrammaskingver3-181116070937-thumbnail.jpg?width=640&height=640&fit=bounds)

































