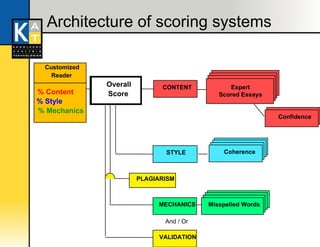
The document discusses latent semantic analysis (LSA), a technique for representing semantic meaning in a machine. LSA learns relationships between words and documents by analyzing large texts. It represents words, documents, and combinations as points in a high-dimensional semantic space based on human judgments. LSA measures semantic content against quality standards and agrees well with human judgments of similarity. The system uses LSA to assess essay content quality rather than surface features alone.