Download to read offline



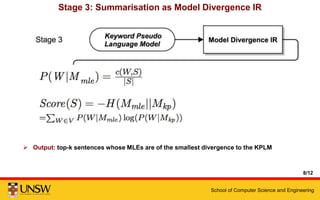
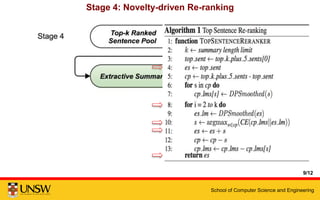
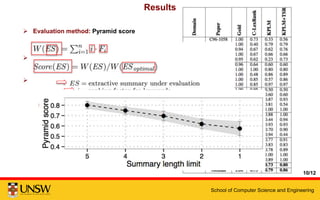



This document presents a multi-stage framework for extractive summarization of scientific papers based on keyword profiling and language modeling. The framework first identifies keywords that capture a paper's most important contributions, then creates a keyword profile language model. It ranks sentences by divergence from this model and re-ranks them based on novelty to generate a 5-sentence summary. Evaluation shows the framework achieves state-of-the-art performance on summarizing individual papers and remains effective under more stringent length limits.
































































