The document provides an overview of text analysis tools and methodologies within digital humanities, emphasizing the use of computational psycholinguistics. It discusses various text analysis methods, including statistical, syntactic, and semantic approaches, and introduces the BEAGLE model for creating a holographic mental lexicon. Additionally, it highlights practical applications, limitations, and the importance of careful interpretation in analysis.





















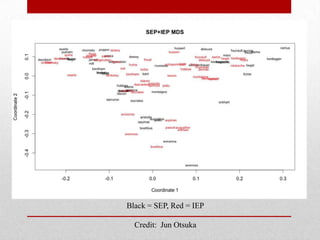
![MDS
• A way to view a multi-dimensional similarity space
• Collapses multi-dimensional space in way that tries to
mutually preserve distances between vectors
• Collapsing dimensions often reveals most significant
[higher-order] dimensions](https://image.slidesharecdn.com/dhtools-121022141919-phpapp02/85/DH-Tools-Workshop-1-Text-Analysis-22-320.jpg)