





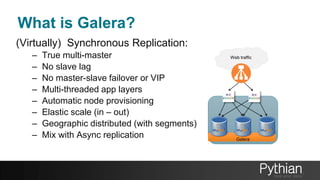

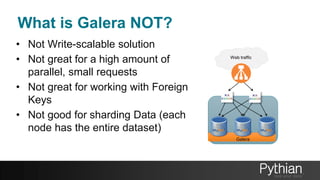

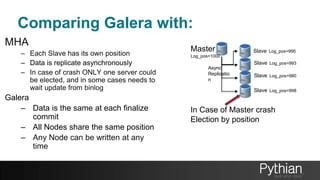
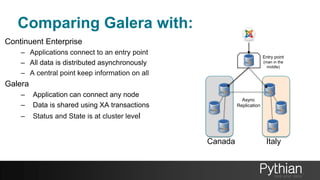






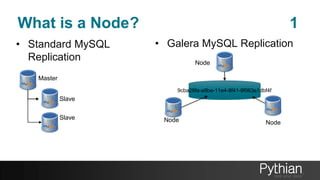


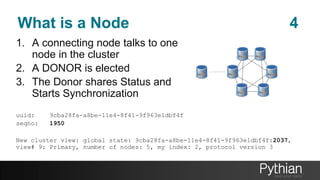


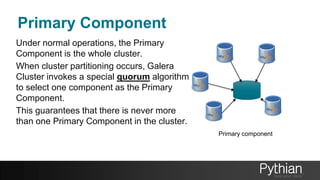
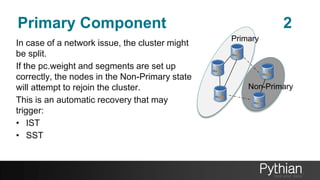








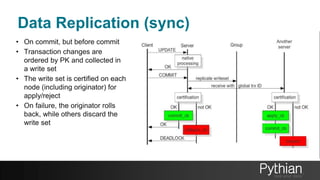
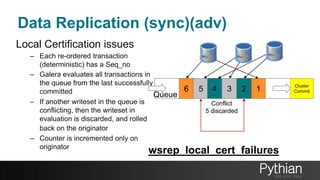
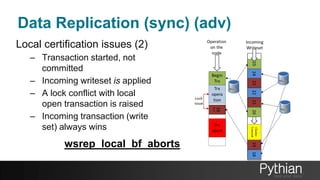

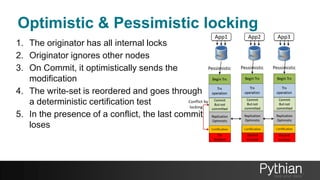












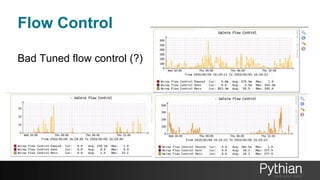












The document presents a comprehensive tutorial on the Galera Cluster, focusing on its functionality, components, and differences from traditional MySQL replication. It highlights the advantages of Galera's synchronous replication, such as high availability and improved performance, while also addressing its limitations regarding write scalability and data sharding. The tutorial covers technical aspects including node status, quorum management, data replication methods, and flow control mechanisms essential for understanding and utilizing Galera Cluster effectively.


































































































