Cassandra no sql ecosystem
•
0 likes•1,220 views

Cassandra no sql ecosystem

Recommended
More Related Content
What's hot
What's hot (20)
Viewers also liked
Viewers also liked (10)
Similar to Cassandra no sql ecosystem
Similar to Cassandra no sql ecosystem (20)
More from Sandeep Sharma IIMK Smart City,IoT,Bigdata,Cloud,BI,DW
More from Sandeep Sharma IIMK Smart City,IoT,Bigdata,Cloud,BI,DW (20)
Recently uploaded
Recently uploaded (20)
Cassandra no sql ecosystem
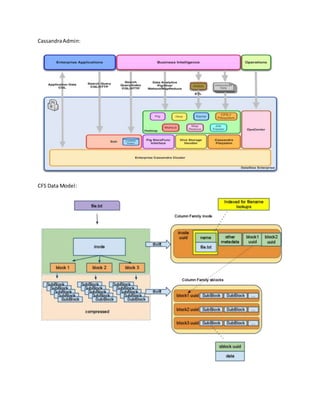
- 2. HDFS NameNode service, that tracks each files metadata and block locations, is replaced with the “inode” column family. two Column Families represent the two primary HDFS services. The HDFS DataNode service, that stores file blocks, is replaced with the “sblocks” Column Family. HDFS CFS NameNode “Inode”columnfamily DataNode “Sblocks”columnfamily CFS Write Path Hadoopblockis single blocknochange injobsplit logicof map-reduce. Data Splitintosubblocksasitreliesonthrift(not supportstreaming). Sys chema like oracle Keyspacesin Cassandra ‘inode’ Column Family contains meta information. CFS Read Path: When a read comes in for a file or part of a file (let’s assume Hadoop looked up the the uuid from the secondary index) it reads the inode info and finds the block and subblock to read. CFS then executes a custom thrift call that returns either the specified sub-block data or, if the call was made on a node with the data locally, the file and offset information of the Cassandra SSTable file with the subblock. It does this since during a mapreduce task the jobtracker tries to put each computation on the node with the actual data. By using the SSTable information it is much faster, since the mapper can access the data directly without needing to serialize/deserialize via thrift.
- 3. second column family ‘sblocks’ stores the actual contents of the file What isreplicationFactorforNodeswhichwe have sethere?(No.of nodes) What isreplicationStrategy? Cassandra workloads A Cassandra real-time application needs very rapid access to Cassandra data.The real-time application accesses data directly by key, large sequential blocks, or sequential slices. KeySpace Configuration: [default@unknown] CREATE KEYSPACE test WITH placement_strategy = 'NetworkTopologyStrategy' AND strategy_options={us-east:6,us-west:3};
- 4. Workload segregation¶ nodes in separate data centers run a mix of: Real-time queries (Cassandra and no other services) Analytics (either DSE Hadoop, Spark, or dual mode DSE Hadoop/Spark) Solr External Hadoop system (BYOH) Schema in Cassandra 1.1 When Cassandra was first released if followed Google Bigtable. ColumnFamilies grouping related columns needed to be defined up-front, but column names were just byte arrays interpreted by the application. It would be fair to characterize this early Cassandra data model as “schemaless.” REATE TABLE users ( id uuid PRIMARY KEY, name varchar, state varchar ); ALTER TABLE users ADD birth_date INT; (Using UUIDs as a surrogate key is common in Cassandra, so that you don’t need to worry about sequence or autoincrement synchronization across multiple machines.) traditional storage engines allocate room for each column in each row.
- 5. In a static-column storage engine, each row must reserve space for every column. Cassandra’s storage engine, each row is sparse: CQL (the Cassandra Query Language) supports defining columnfamilies with compound primary keys. The first column in a compound key definition continues to be used as the partition key, and remaining columns are automatically clustered: that is, all the rows sharing a given partition key will be sorted by the remaining components of the primary key, sblocks table in the CassandraFS data model CREATE TABLE sblocks ( block_id uuid, subblock_id uuid, data blob, PRIMARY KEY (block_id, subblock_id) ) WITH COMPACT STORAGE;
- 6. The first element of the primary key, block_id, is the partition key, which means that all subblocks of a given block will be routed to the same replicas. Logical representation of the denormalized timeline rows The physical layout of this data looks like this to Cassandra’s storage engine: Physical representation of the denormalized timeline rows, WITH COMPACT STORAGE
- 7. Physical representation of the denormalized timeline rows, WITH COMPACT STORAGE Physical representation of the denormalized timeline rows, WITH COMPACT STORAGE
- 8. Replicationstrategy: SimpleStrategy/Network topology Strategy SimpleStrategy:SimpleStrategy places the first replica on a node determined by the partitioner. Additional replicas are placed on the next nodes clockwise in the ring without considering rack or data center location: Below 3 replicas in four {ABCD} nodes. NetworkTopologyStrategy : cluster deployed across multiple data centers (1) being able to satisfy reads locally, without incurring cross-datacenter latency, and (2) failure scenarios (2) Failure Scenarios. Asymmetrical replication groupings are also possible. For example, you can have three replicas per data center to serve real-time application requests and use a single replica for running analytics.
- 9. NetworkTopologyStrategy determines replica placement independently within each data center as follows: The first replica is placed according to the partitioner (same as with SimpleStrategy). Additional replicas are placed by walking the ring clockwise until a node in a different rack is found. If no such node exists, additional replicas are placed in different nodes in the same rack. NetworkTopologyStrategy attempts to place replicas on distinct racks because nodes in the same rack (or similar physical grouping) can fail at the same time due to power, cooling, or network issues. Below is an example of how NetworkTopologyStrategy places replicas spanning two data centers with a total replication factor of 4. When using NetworkToplogyStrategy, you set the number of replicas per data center. In the following graphic, notice the tokens are assigned to alternating racks. For more information, see Calculating Tokens for a Multiple Data Center Cluster.
- 10. Snitches Snitch maps IPs to racks and data centers. It defines how the nodes are grouped together within the overall network topology. Cassandra uses this information to route inter-node requests as efficiently as possible. A consistency level of ONE means that it is possible that 2 of the 3 replicas could miss the write if they happened to be down at the time the request was made If a replica misses a write, the row will be made consistent later via one of Cassandra's built-in repair mechanisms: hinted handoff, read repair or anti-entropy node repair. Cassandra's Built-in Consistency Repair Features Read Repair: To ensure that frequently-read data remains consistent, the coordinator compares the data from all the remaining replicas that own the row in the background, and if they are inconsistent, issues writes to the out-of-date replicas to update the row to reflect the most recently written values Anti-Entropy Node Repair: For data that is not read frequently, or to update data on a node that has been down for a while, the nodetool repair process ensures that all data on a replica is made consistent Hinted Handoff
- 11. If a node happens to be down at the time of write, its corresponding replicas will save hints about the missed writes, and then handoff the affected rows once the node comes back online. Keyspaces: container for column families and a cluster has 1 keyspace per application. CREATE KEYSPACE keyspace_name WITH strategy_class = 'SimpleStrategy' AND strategy_options:replication_factor='2'; Single device per row - Time Series Pattern 1 Partitioning to limit row size - Time Series Pattern 2 The solution is to use a pattern called row partitioning by adding data to the row key to limit the amount of columns you get per device. Reverse order timeseries with expiring columns - Time Series Pattern 3 Data for a dashboard application and we only want to show the last 10 temperature readings. With TTL time to live for data value it is possible. CREATE TABLE latest_temperatures ( weatherstation_id text, event_time timestamp, temperature text, PRIMARY KEY (weatherstation_id,event_time), ) WITH CLUSTERING ORDER BY (event_time DESC); INSERT INTO latest_temperatures(weatherstation_id,event_time,temperature) VALUES ('1234ABCD','2013-04-03 07:03:00','72F') USING TTL 20;
- 12. RDBMS Cassandra Stop service sudo service dse stop Justlike commitbutbefore commit. nodetool drain -h <host name> drain node before losing data.cassandra need not read commit log. Sys schema like oracle KeyspacesinCassandra SELECT * FROM system.schema_keyspaces; Counter Columns¶ A counter is a special kind of column used to store a number that incrementally counts the occurrences of a particular event or process. For example, you might use a counter column to count the number of times a page is viewed.