Download as PDF, PPTX



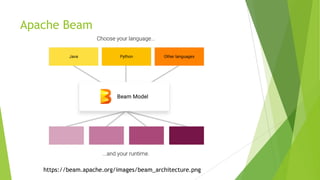





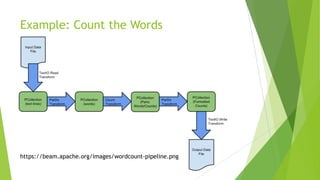


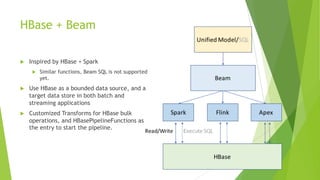




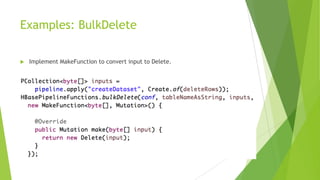

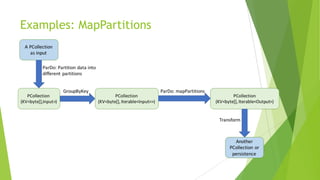


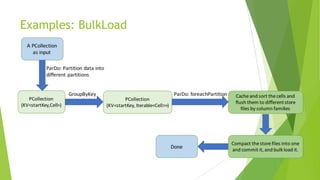

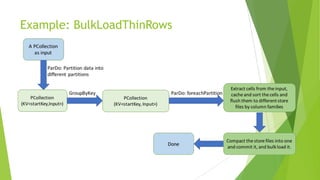



Apache Beam is an open-source programming model for batch and streaming data processing pipelines, initially contributed by Google and stable since May 17, 2017. It supports multiple languages, allows for a unified model with runners for various data processing engines, and incorporates custom transformations for working with HBase as a data source. Future aspirations include contributing code to Apache Beam and enabling Beam SQL support for HBase.























































































