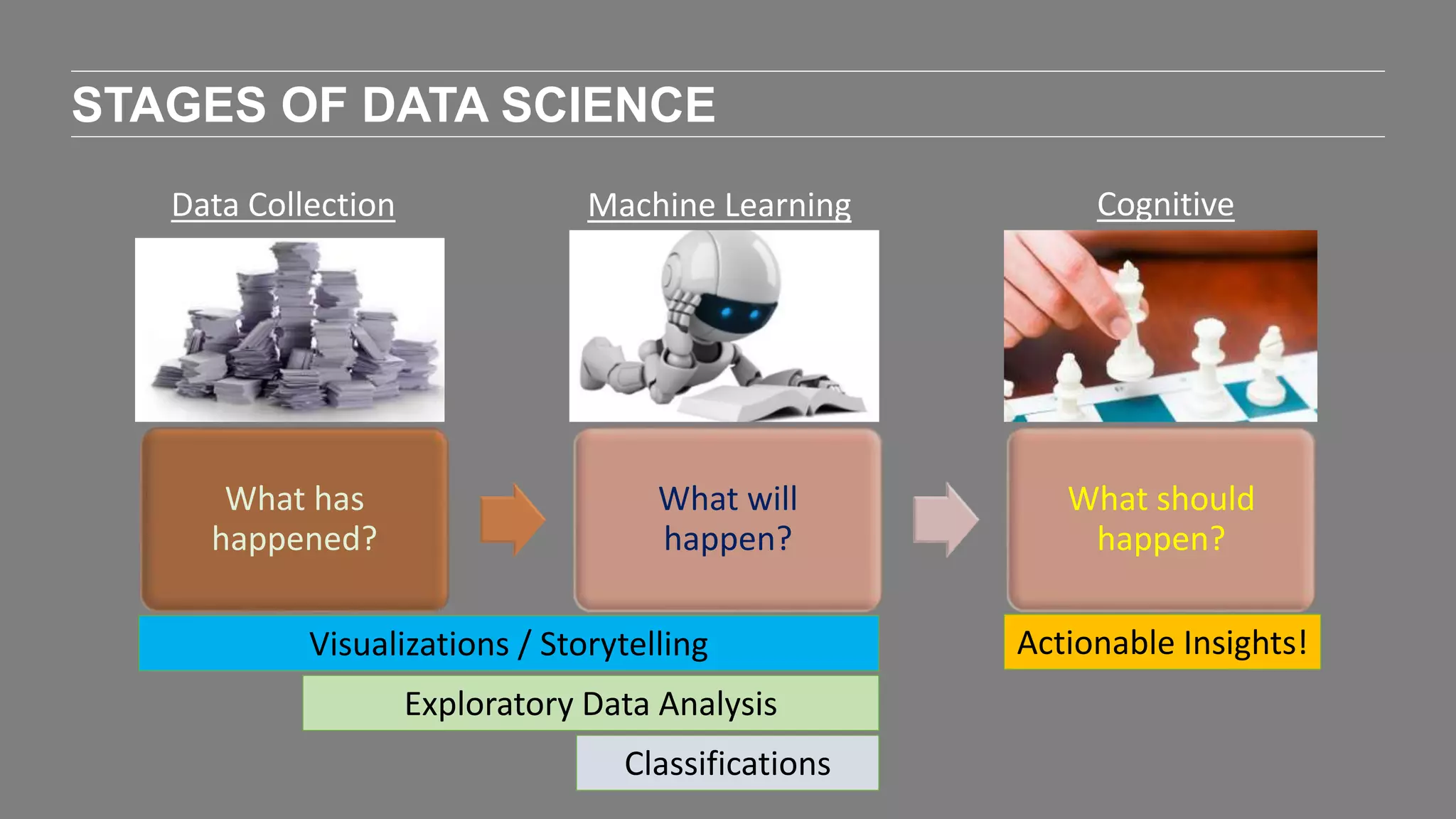
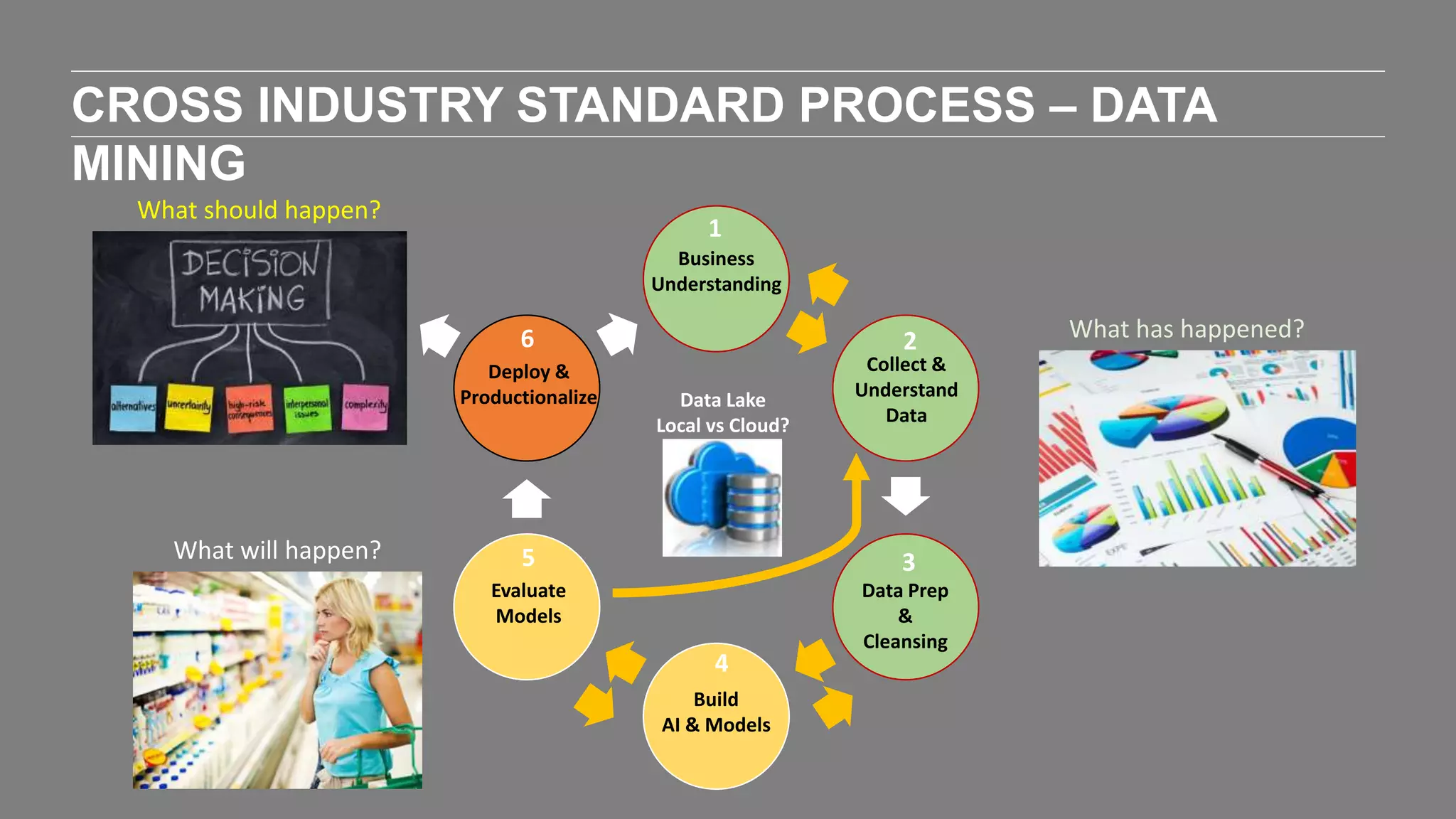
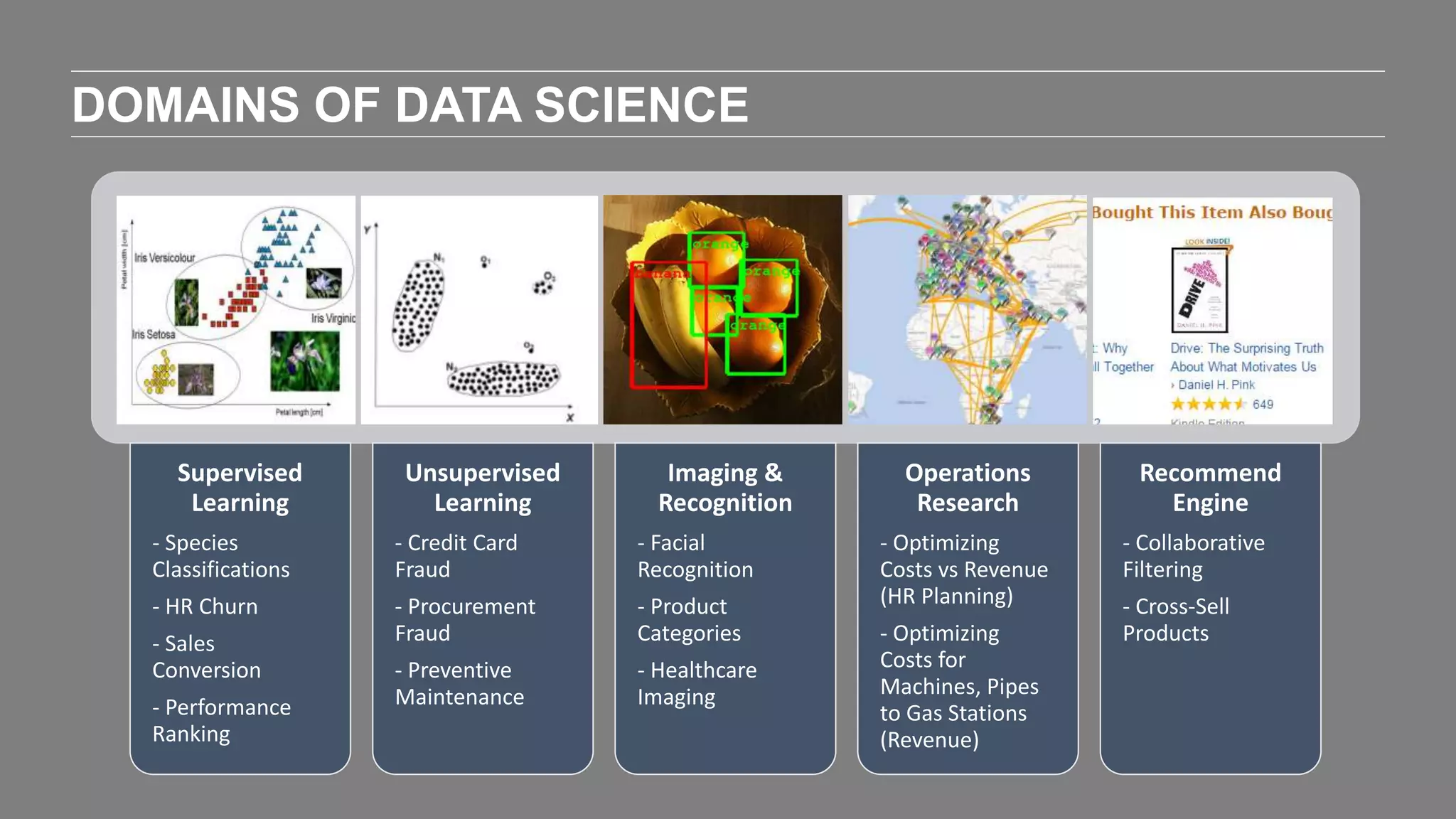
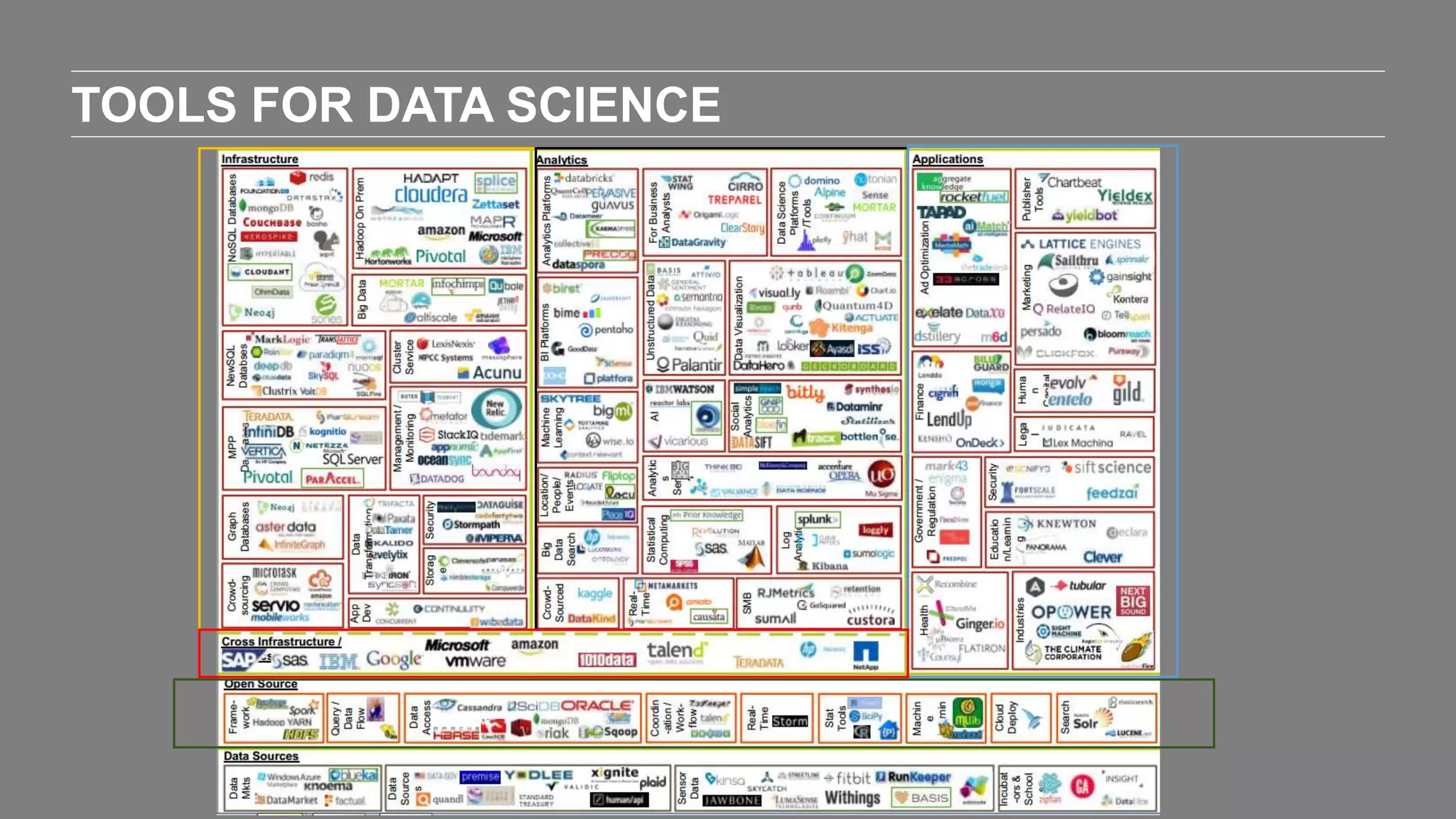
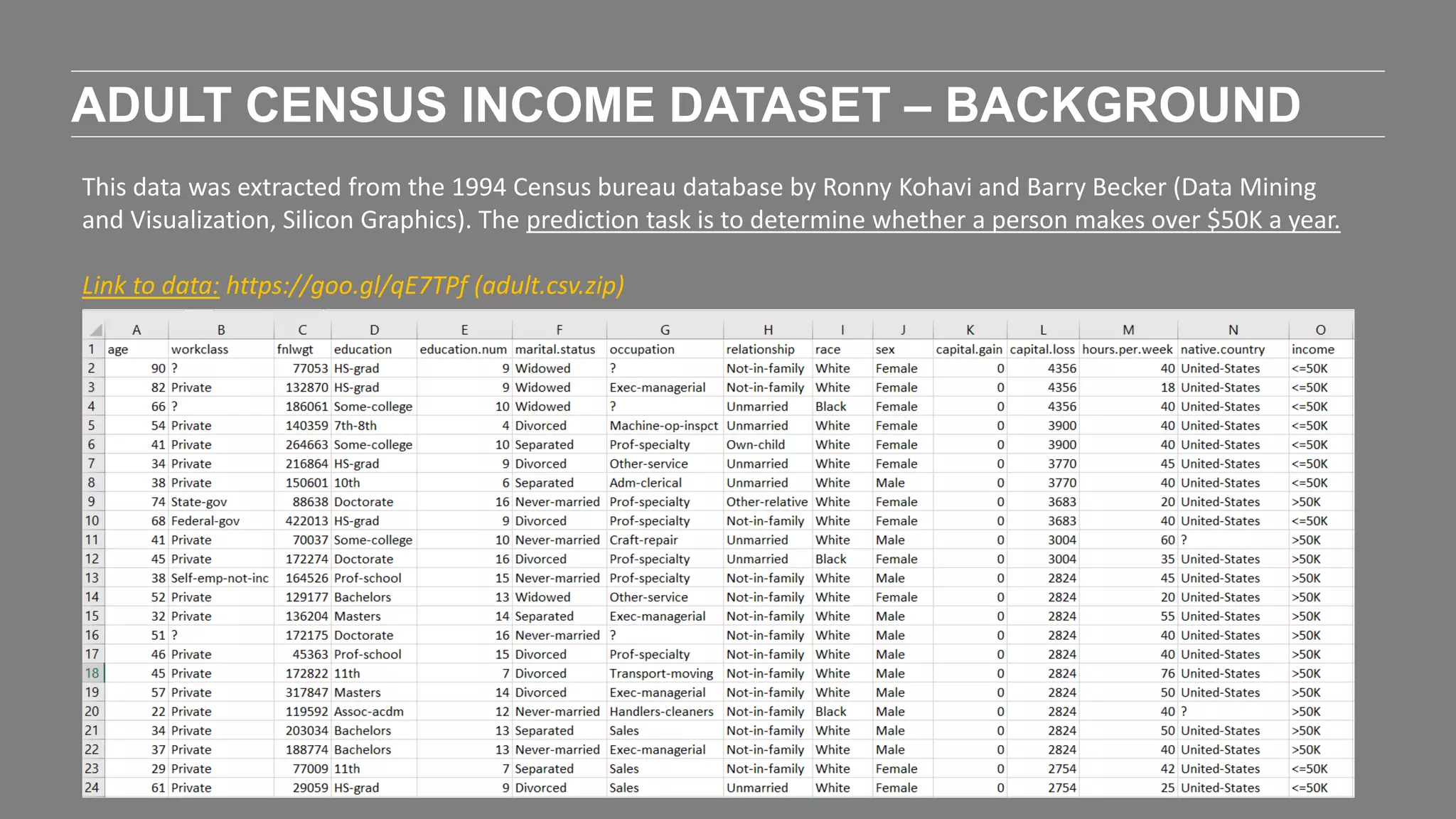
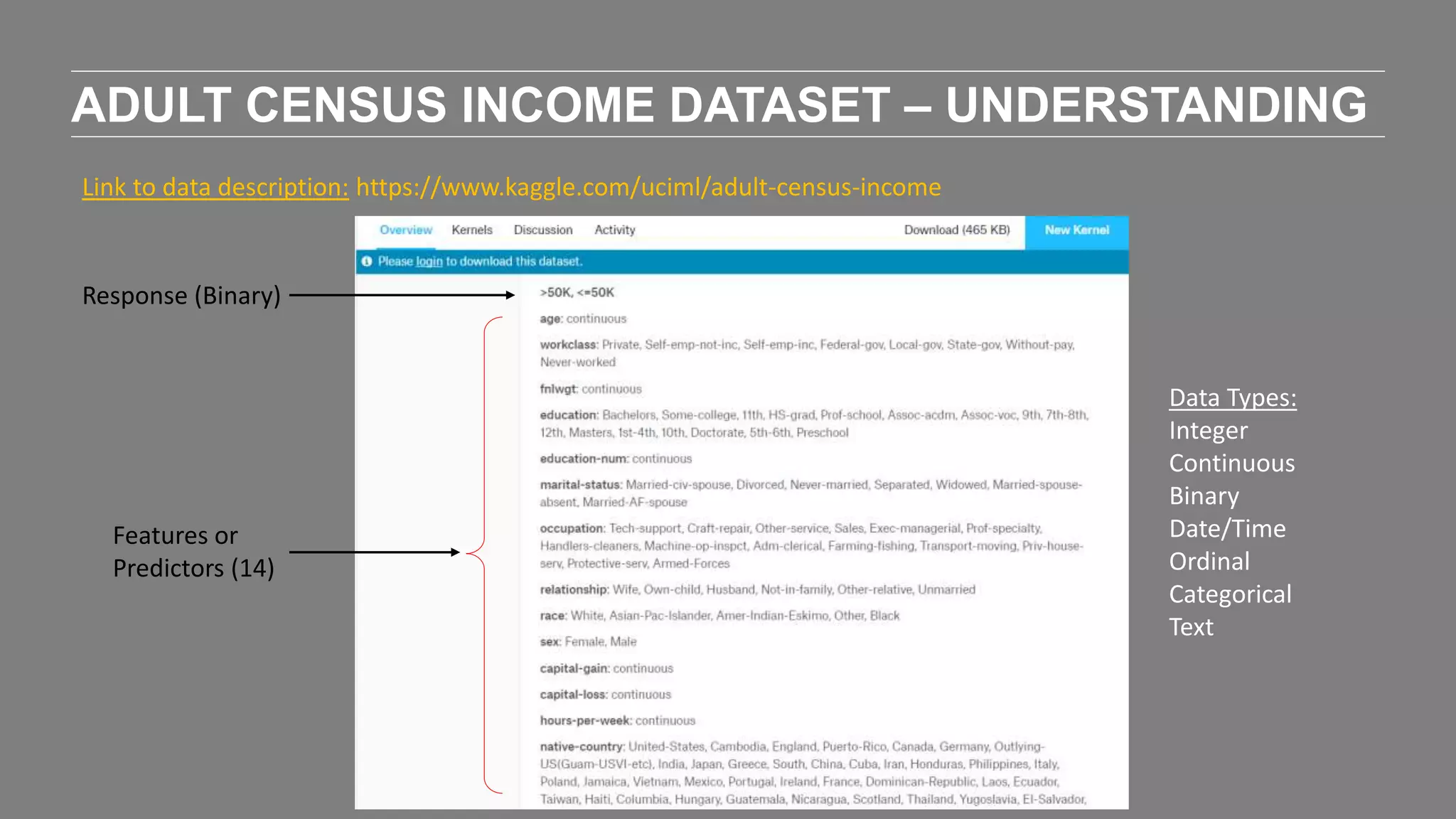
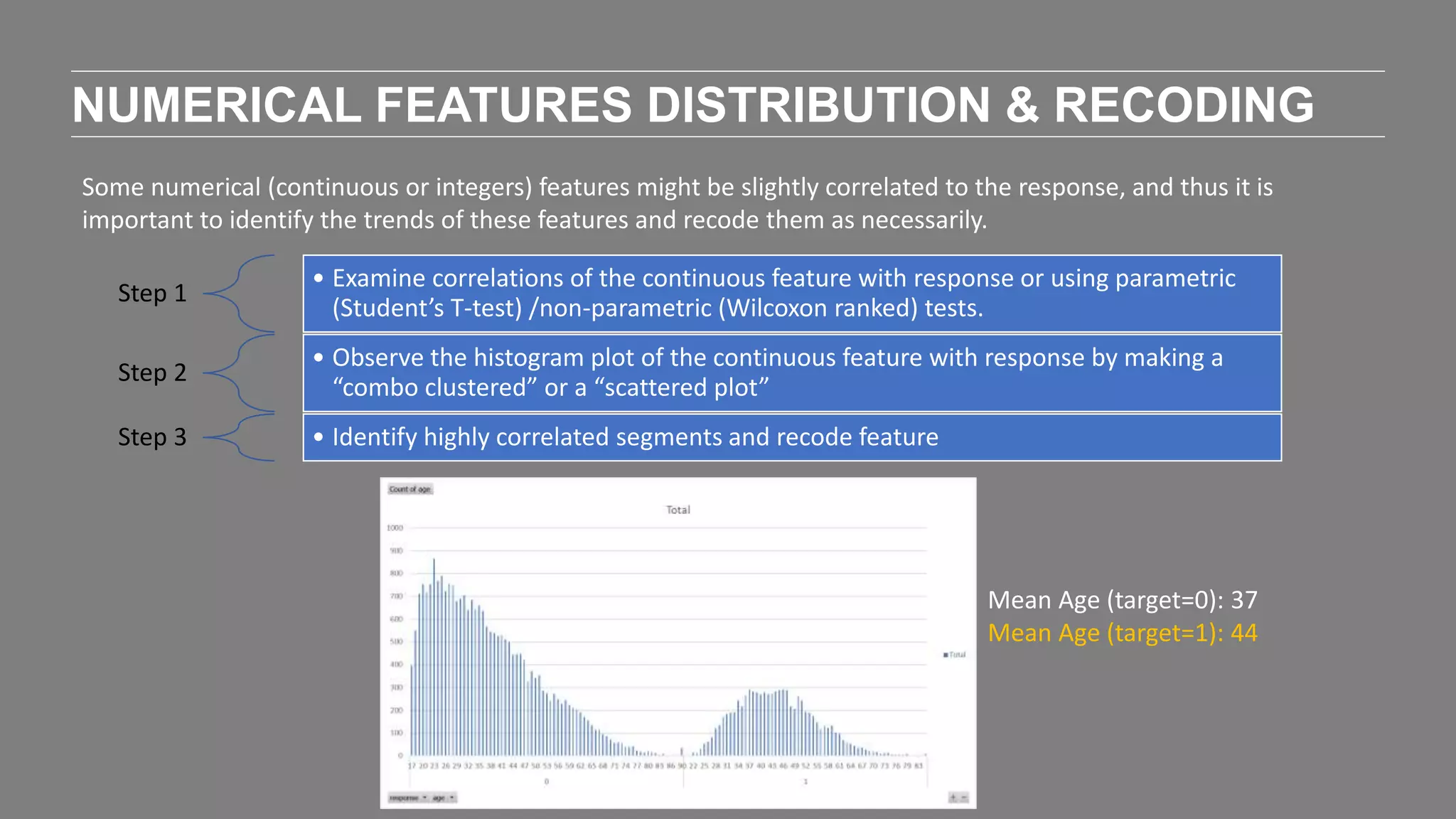
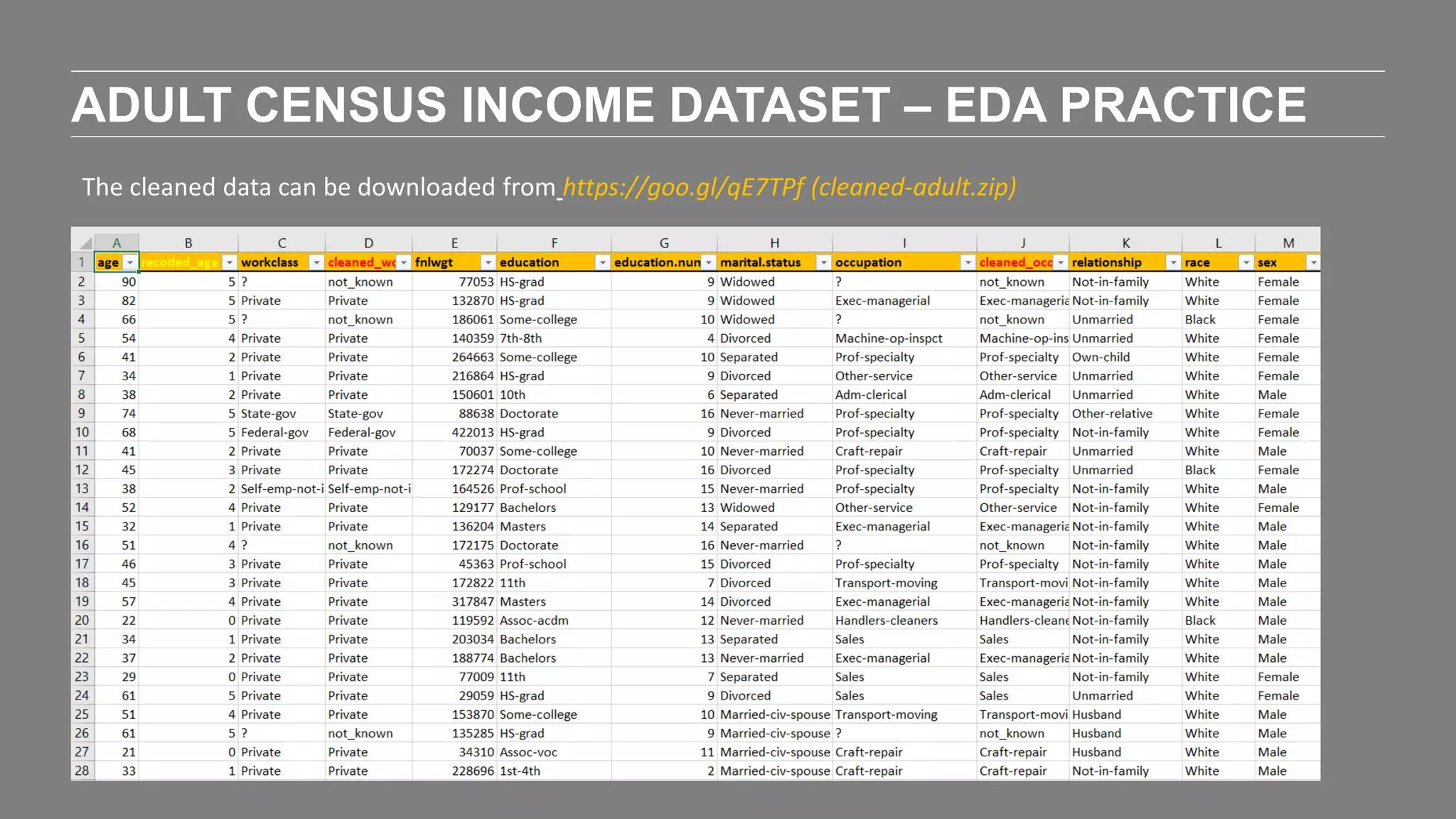
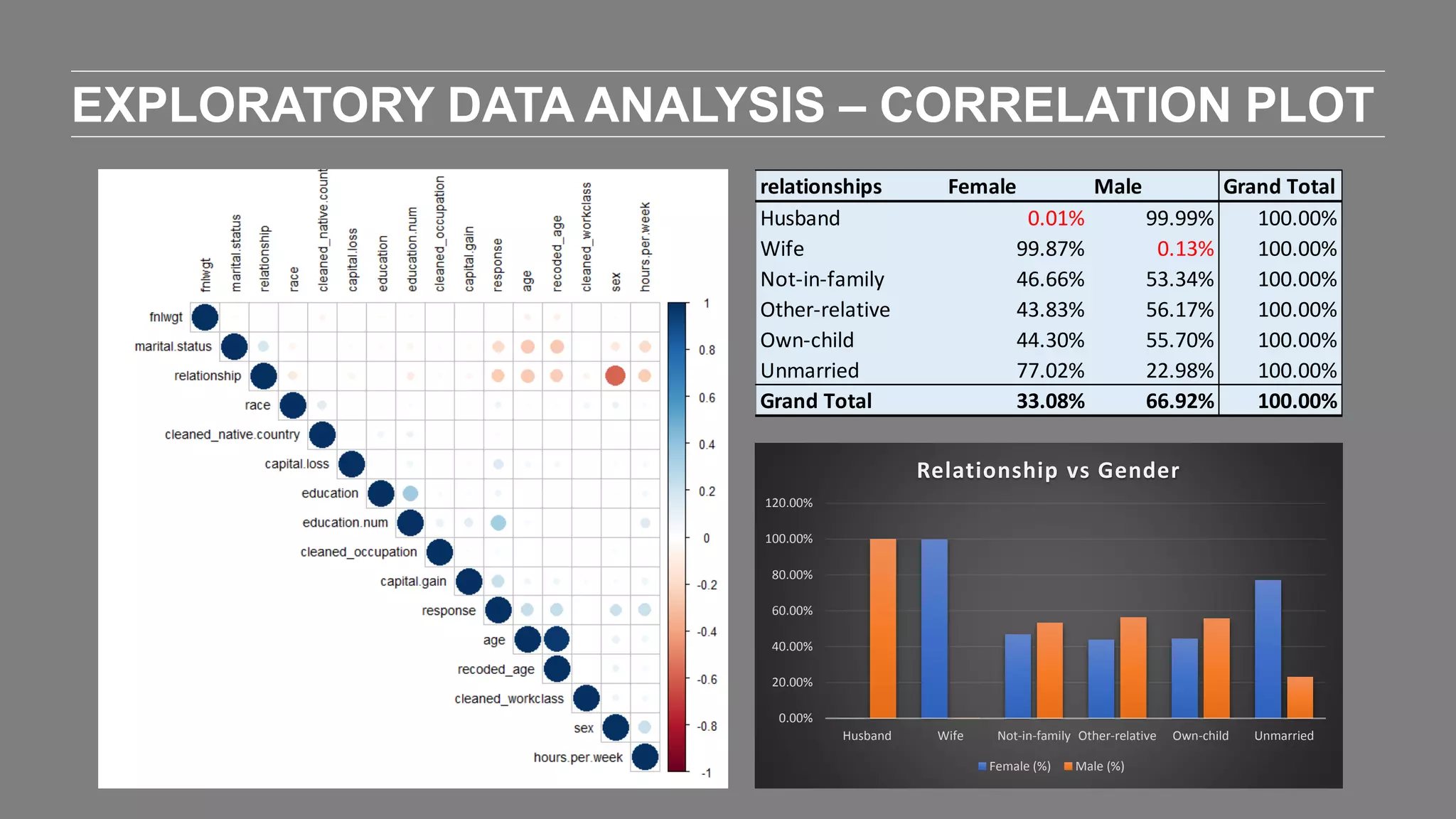
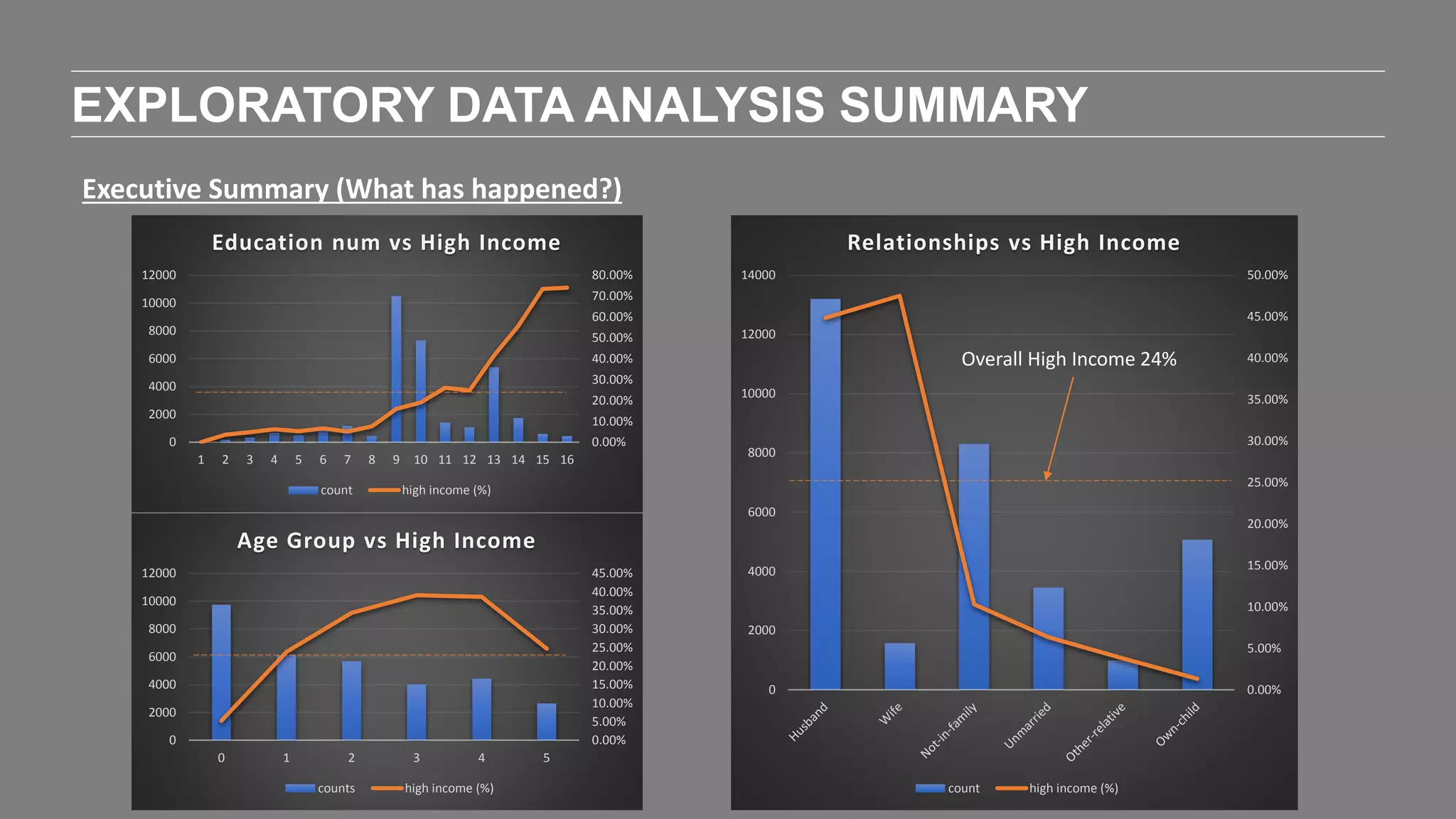
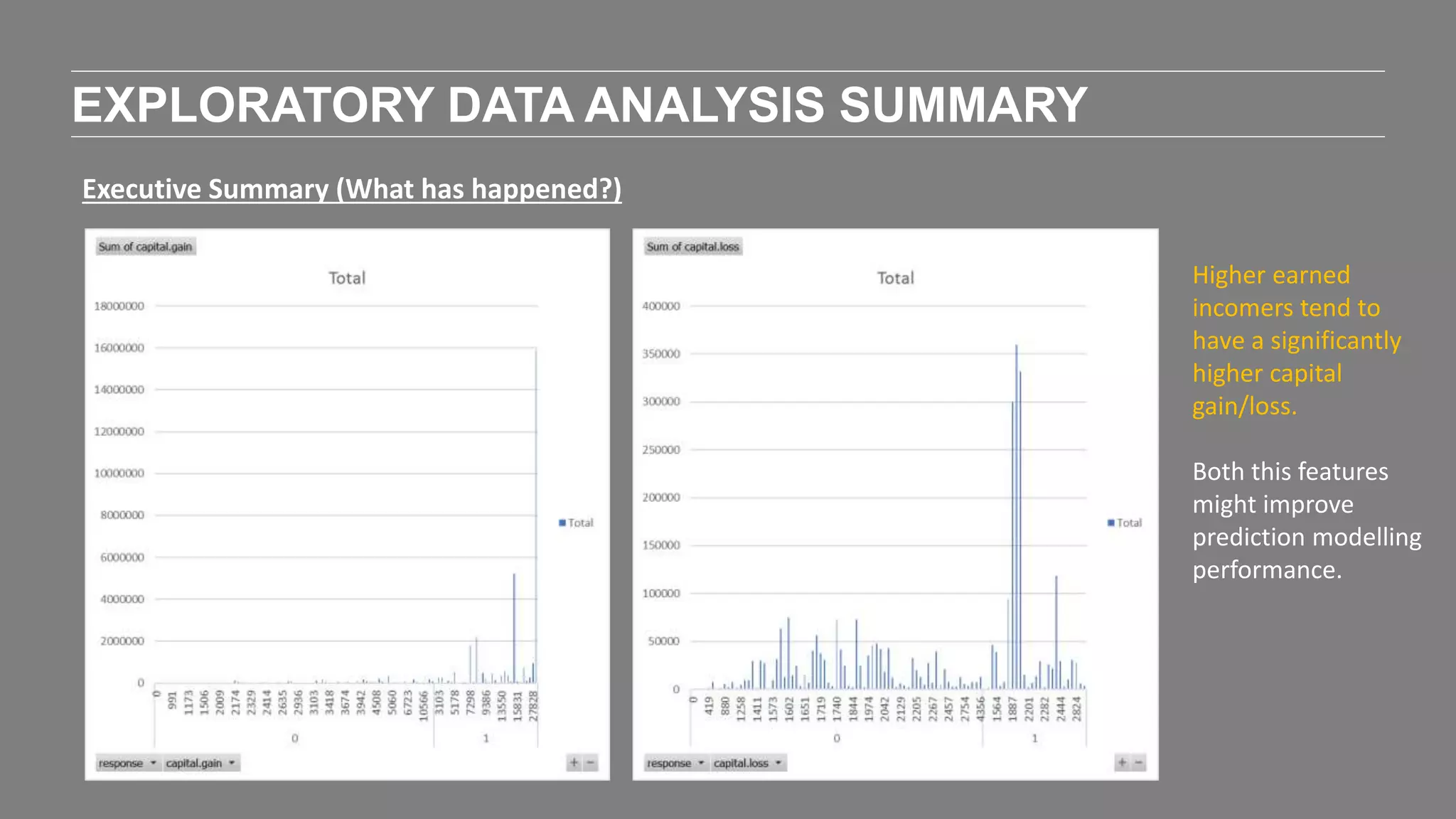
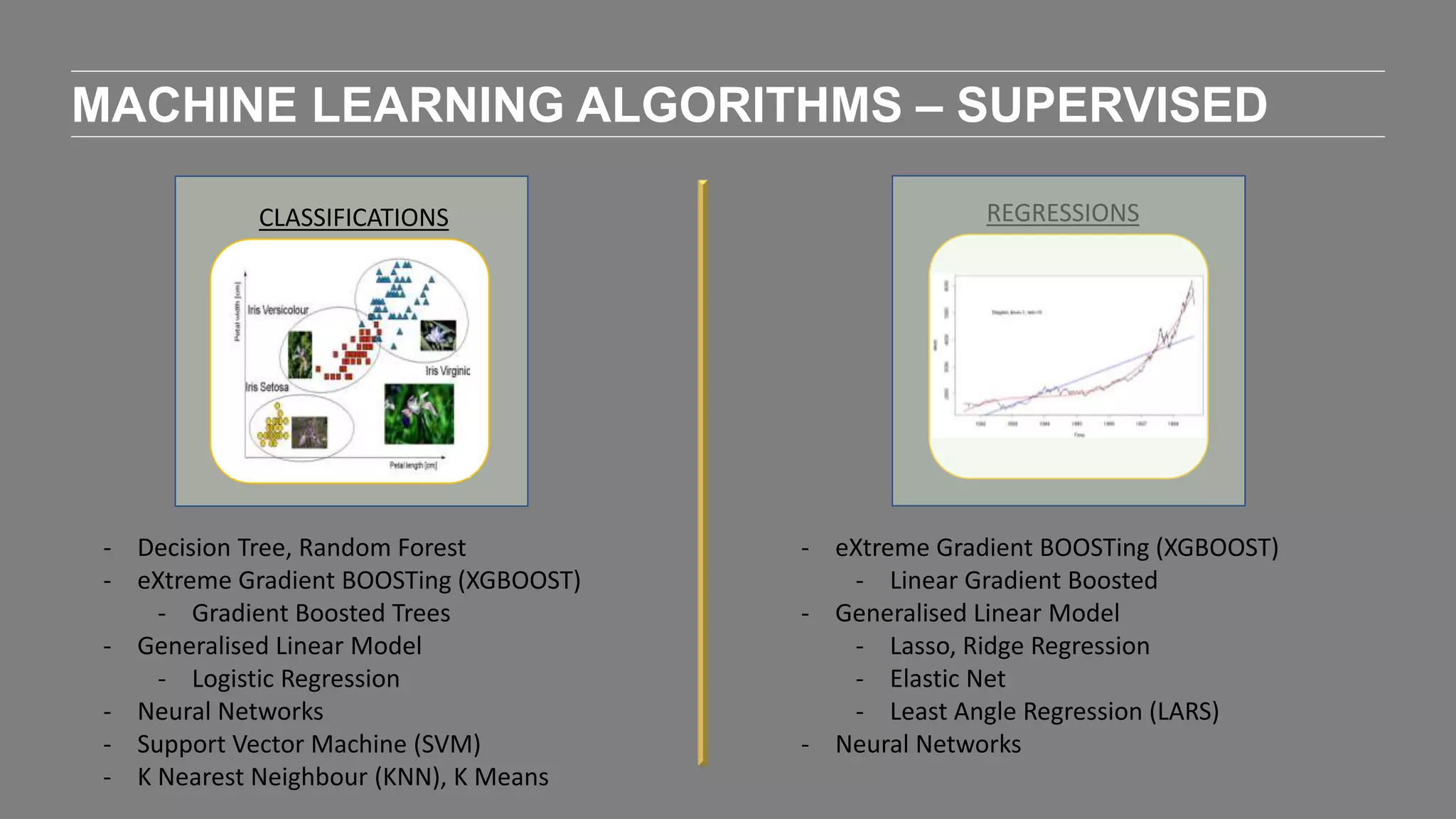
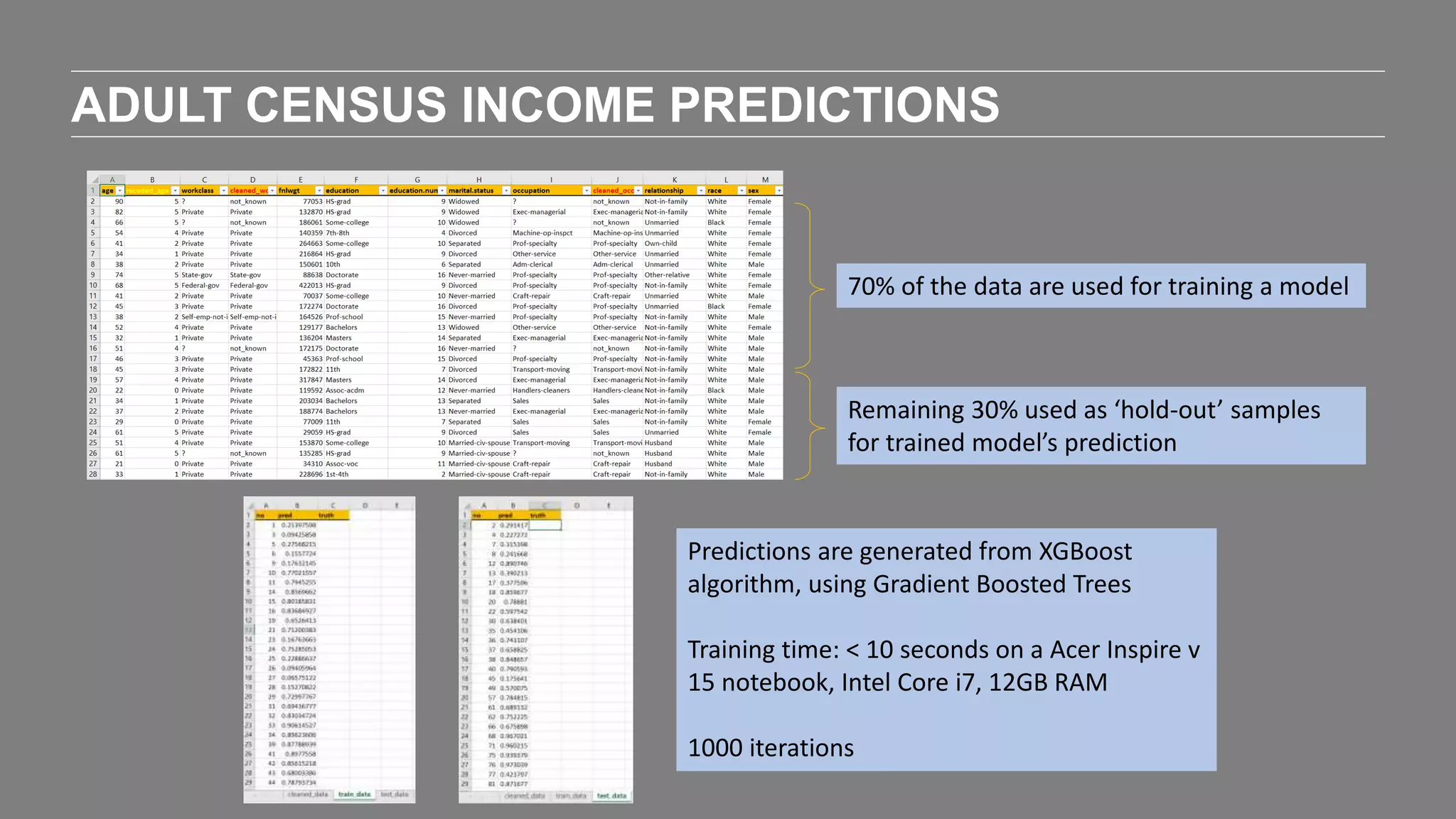
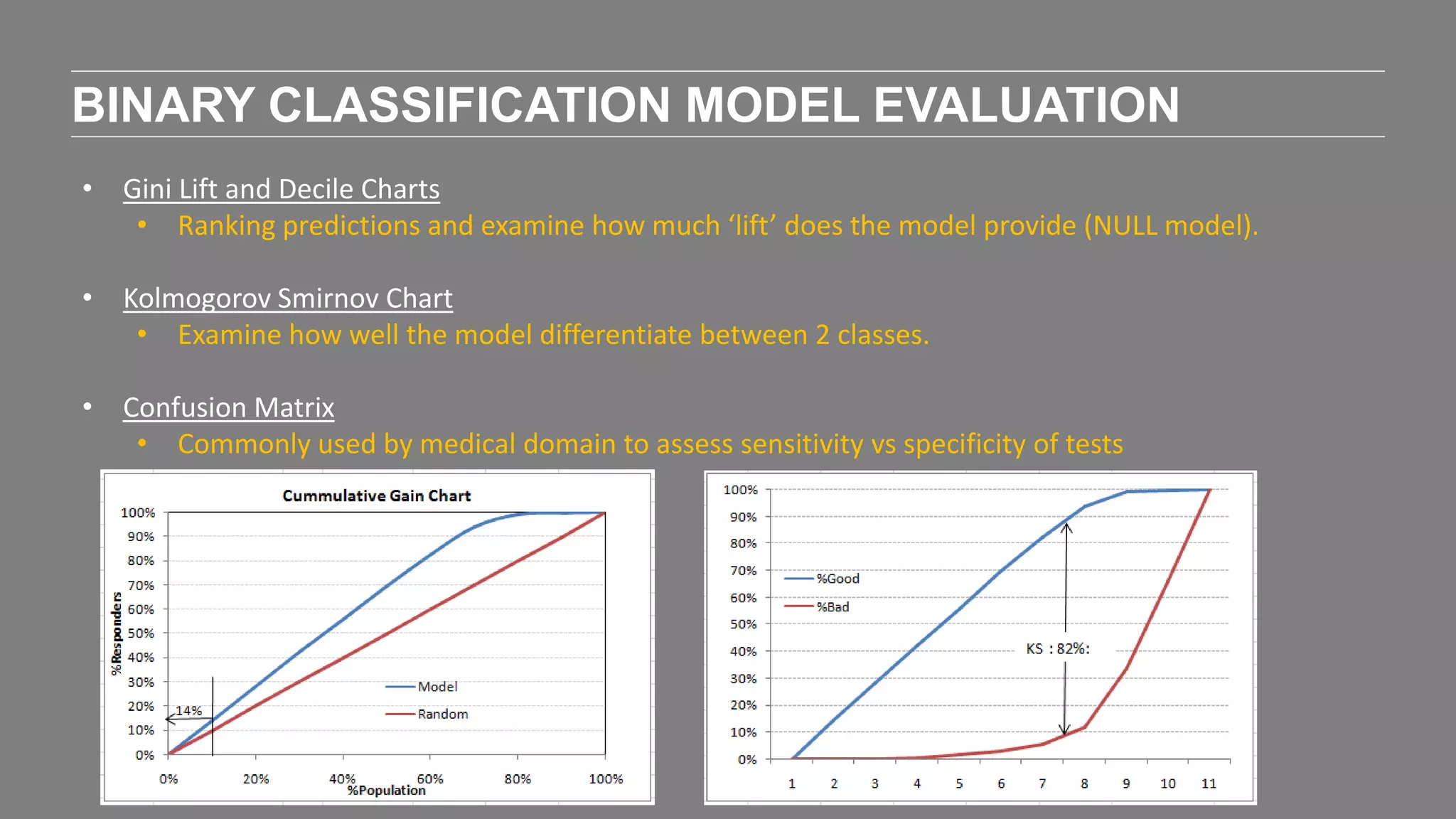
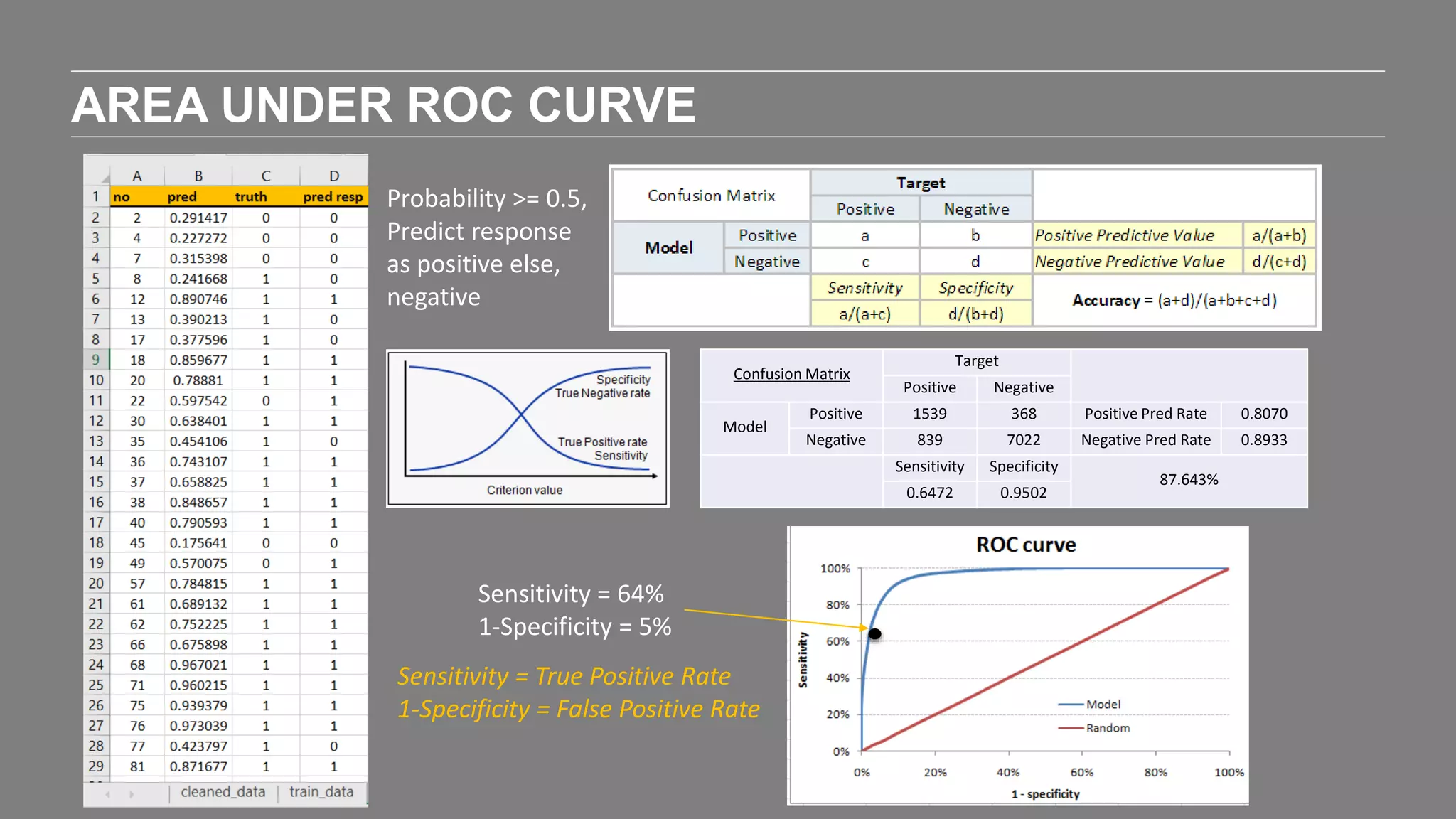
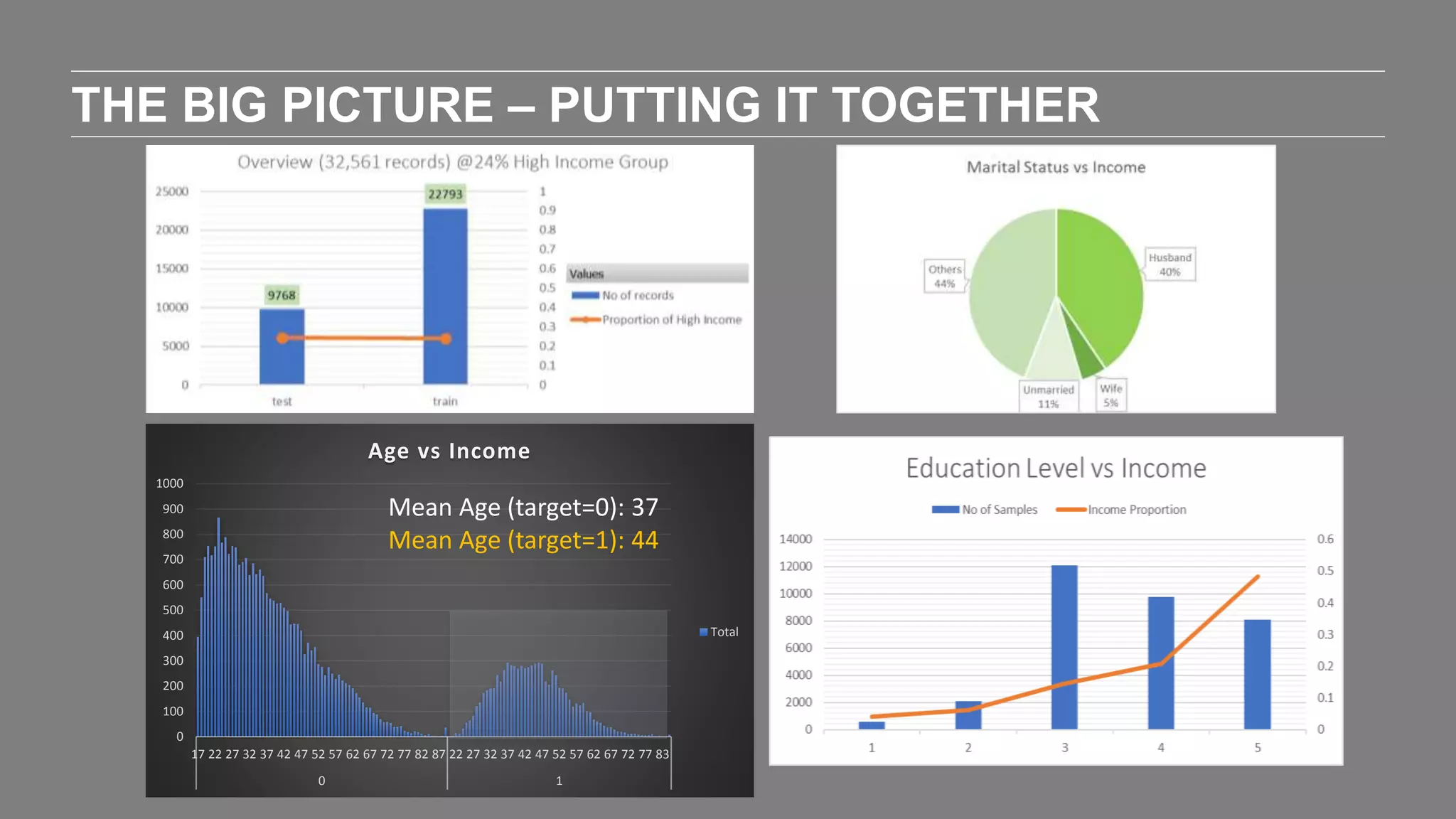
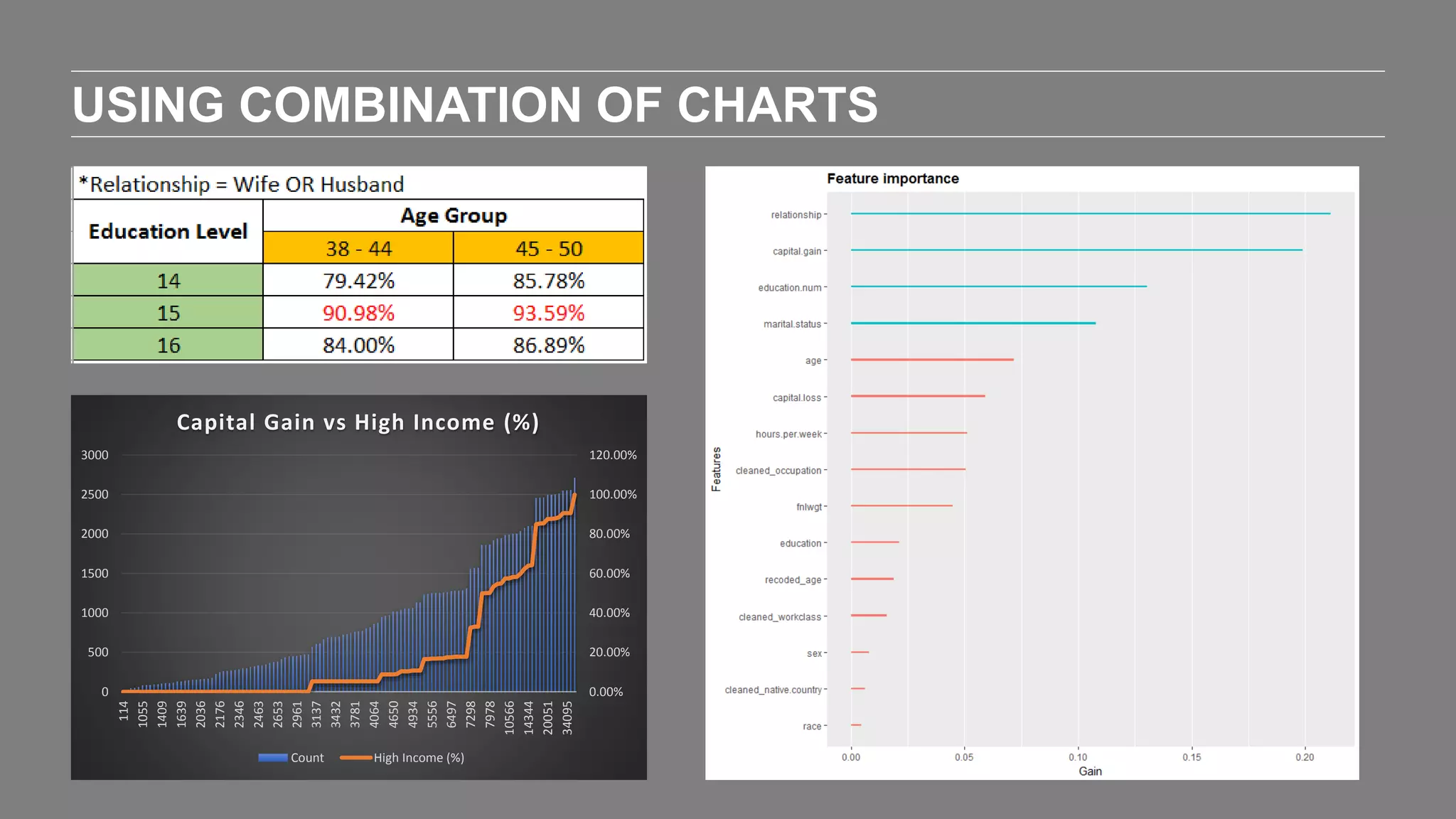
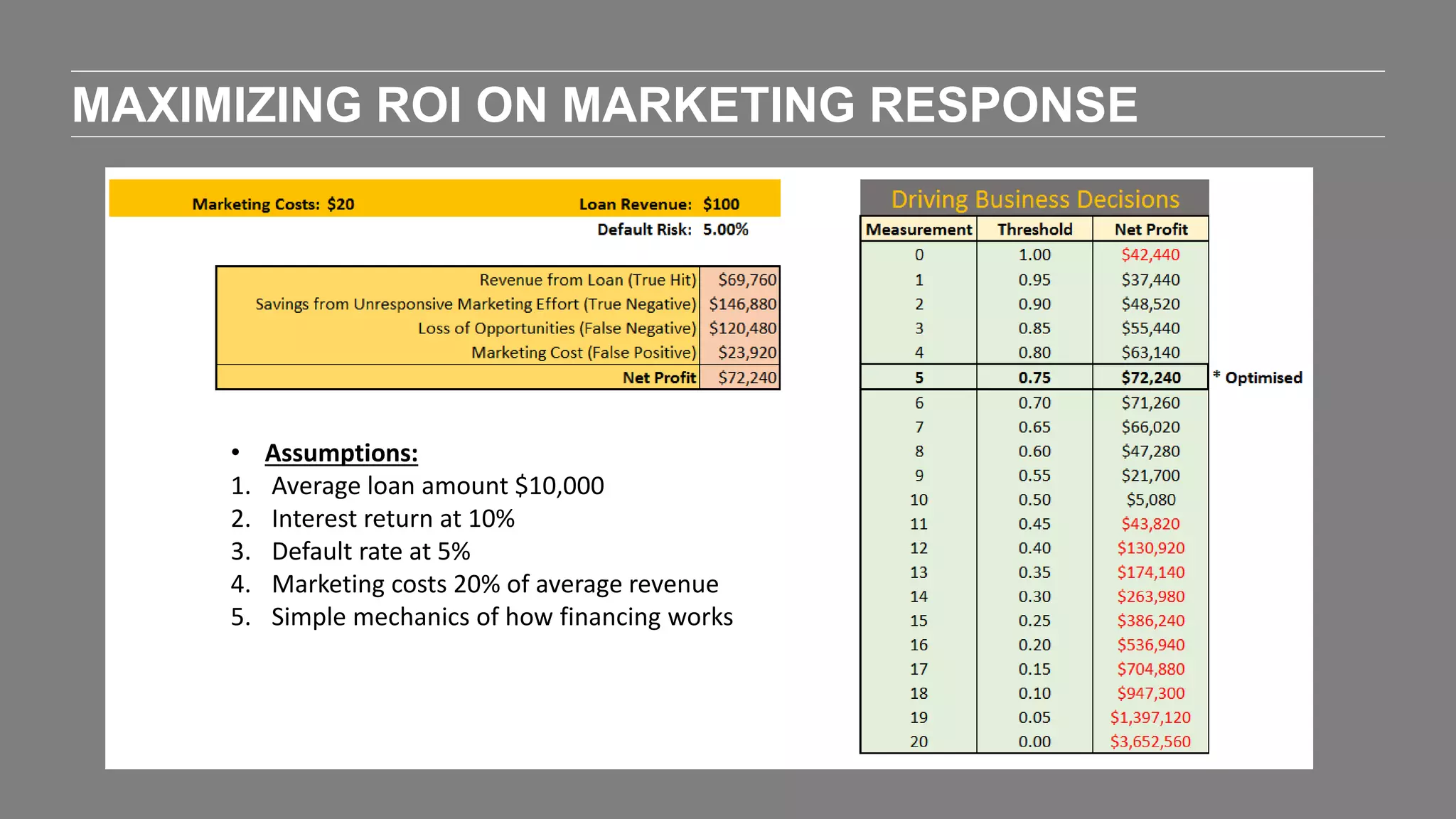
The document outlines the agenda and content of a workshop focused on data science principles, including fundamentals, exploratory data analysis, and machine learning methods, scheduled for June 29, 2017. It discusses various data science domains and techniques, evaluation metrics for predictive models, and the importance of data visualization and storytelling in data analysis. Additionally, it includes practical steps for cleaning and preparing datasets, such as the Adult Census Income dataset, along with insights into machine learning algorithms for both supervised and unsupervised learning.
![ECHELON
ASIA SUMMIT 2017
STARTUP ACADEMY
[WORKSHOP]
INTRODUCTION TO
DATA SCIENCE
29th June 2017
Garrett Teoh Hor Keong](https://image.slidesharecdn.com/echelonasiasummitpresogarrettteoh-170629165116/75/Echelon-Asia-Summit-2017-Startup-Academy-Workshop-1-2048.jpg)