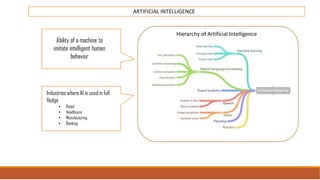
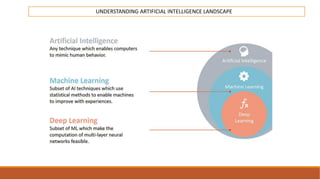
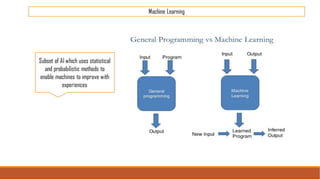
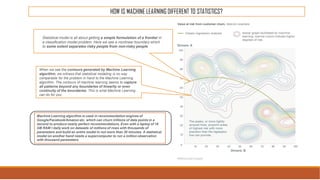
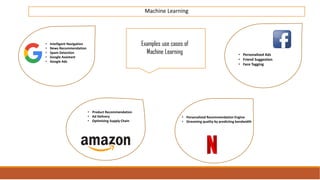
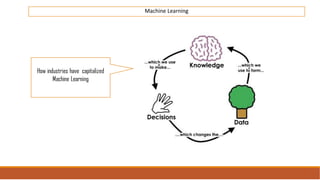
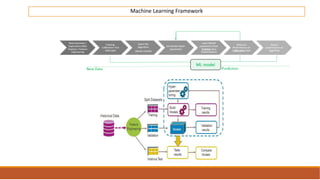
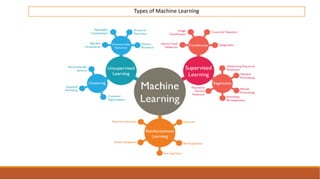
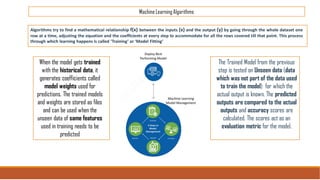
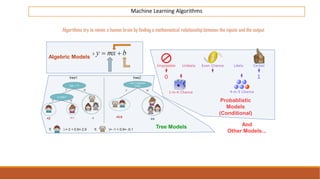
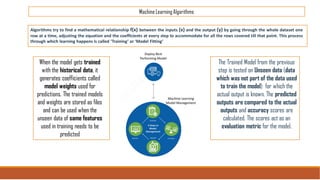
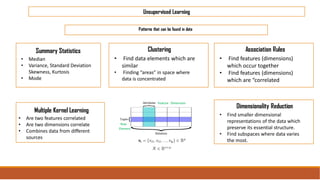
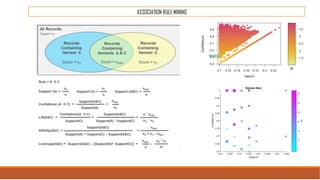
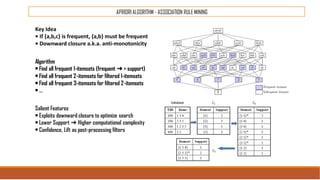
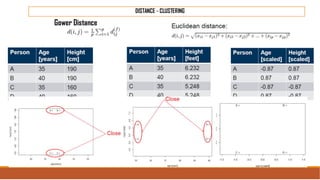
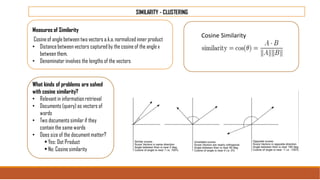
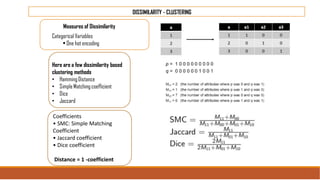
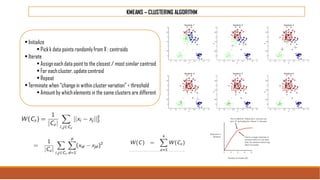
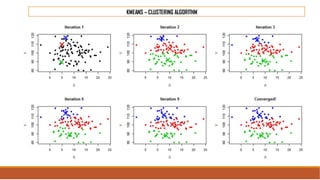
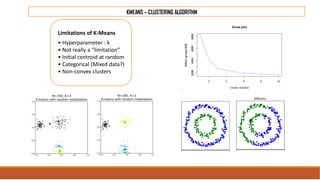
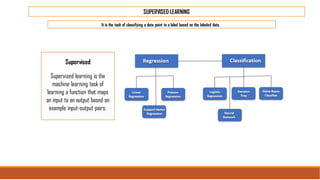
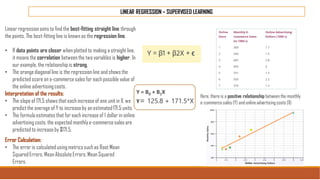
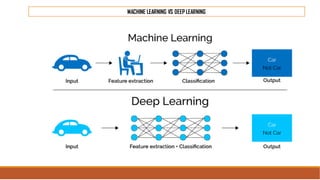
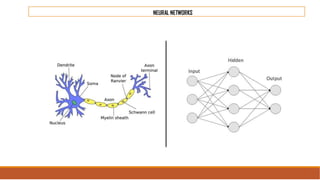
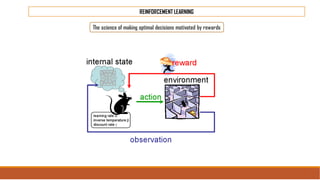
The document provides an overview of machine learning, its history, and its relationship with artificial intelligence, emphasizing its applications across various industries such as retail, healthcare, and banking. It covers the different types of machine learning, including supervised and unsupervised learning, along with algorithms and practical use cases, such as recommendation systems and predictive modeling. Additionally, the document highlights the importance of statistical methods and the role of long-term memory in understanding AI processes.