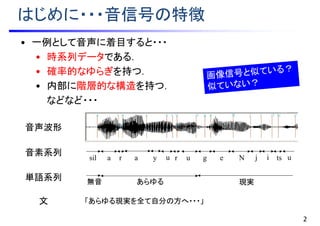
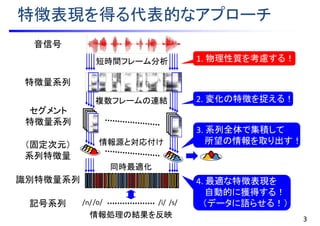
音声波形
a r ay u rsil u g e N j i ts u
音素系列
あらゆる 現実無音
単語系列
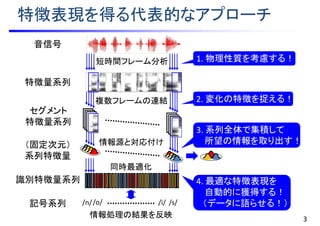
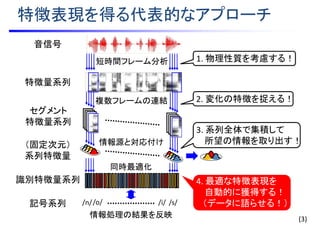
はじめに・・・音信号の特徴
文 「あらゆる現実を全て自分の方へ・・・」
• 一例として音声に着目すると・・・
• 時系列データである.
• 確率的なゆらぎを持つ.
• 内部に階層的な構造を持つ.
などなど・・・
2
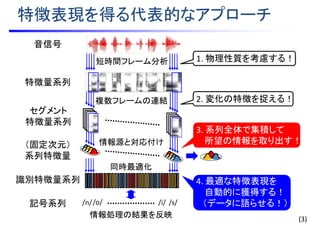
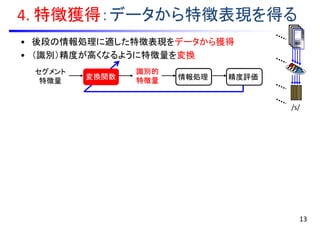
• 系列中のフレーム特徴量は独立同分布に従うと仮定
• 混合正規分布モデル(GMM)による確率密度のモデル化
•例:音声の話者性を捉える特徴量を抽出
3. 集積:フレーム特徴量を集積する
T
t
M
m
m
s
m
s
tm
T
t
ss
t
ss
T
s
PP
1 1
)()(
1
)()()()()(
1 ,;||,, Σμxλxλxx N
M個の正規分布の足し合わせ
= 音韻依存性を周辺化により緩和
話者 s の特徴量系列
(音韻・話者依存)
混合重み
(音韻依存)
平均ベクトル
(音韻・話者依存)
共分散行列
(音韻依存)
系列中の全ての
特徴量をまとめ上げ
10
19.
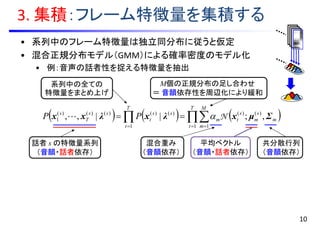
• 系列中のフレーム特徴量は独立同分布に従うと仮定
• 混合正規分布モデル(GMM)による確率密度のモデル化
•例:音声の話者性を捉える特徴量を抽出
• 平均ベクトルセットを系列単位の特徴量として使用
• 音韻系列が異なる場合,異なるモデル間で
各混合要素の対応をとるのは困難
3. 集積:フレーム特徴量を集積する
T
t
M
m
m
s
m
s
tm
T
t
ss
t
ss
T
s
PP
1 1
)()(
1
)()()()()(
1 ,;||,, Σμxλxλxx N
M個の正規分布の足し合わせ
= 音韻依存性を周辺化により緩和
話者 s の特徴量系列
(音韻・話者依存)
混合重み
(音韻依存)
平均ベクトル
(音韻・話者依存)
共分散行列
(音韻依存)
系列中の全ての
特徴量をまとめ上げ
音韻A
音韻B
音韻C
音韻C
音韻A
音韻C
?
10

![スペクトル包絡
周波数
パワー
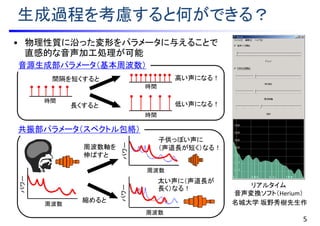
1. 物理性質:生成過程を考慮する
• 短時間フレーム分析
• 短時間区間において定常性を仮定して特徴量を抽出
)(zH
)(ne
)(*)()( nenhnx
励振源周期音源
非周期音源
音信号
音源生成(ソース)部 共振(フィルタ)部
M
m
m
zmc
K
zH
1
)(1
)(
線形時不変フィルタ
M
m
m
zmczH
0
)(exp)(
時間
周波数
基本周波数
※HTS Slides より一部引用
http://hts.sp.nitech.ac.jp/ 4
線形予測分析
ケプストラム分析
切り出し
[板倉 他, 1966]
[今井 他, 1987]](https://image.slidesharecdn.com/slides20160803miruxkikutoda-170521035412/85/slide-7-320.jpg)
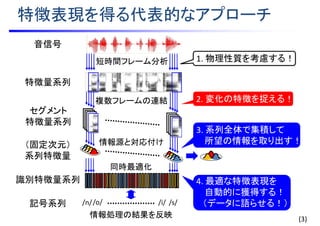
![周波数
時間
振幅スペクトル
• 低周波数帯域を重視
• オールパスフィルタによる周波数軸伸縮
• メルフィルタバンク
2. 物理性質:聴覚特性を考慮する
伸縮後の周波数(rad)
周波数 (rad)
伸縮関数
メルスケール
2
0 2/
フィルタバンク出力
1
周波数
※HTS Slides より一部引用
http://hts.sp.nitech.ac.jp/
※豊橋技科大 山本一公先生の資料から引用
http://www.slp.cs.tut.ac.jp/~kyama/Lecture/AdvSLP/slide/AdvSLP_02.pdf
パワー
周波数 周波数
パワー
メルフィルタバンク出力
バンクID
時間
6
MFCC (Mel-Frequency
Cepstral Coefficient)
[Oppenheim et al., 1972]
[Davis et al., 1980]](https://image.slidesharecdn.com/slides20160803miruxkikutoda-170521035412/85/slide-9-320.jpg)
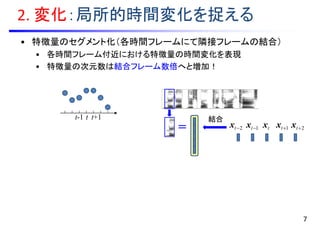
![to
2. 変化:局所的時間変化を捉える
• 特徴量のセグメント化(各時間フレームにて隣接フレームの結合)
• 各時間フレーム付近における特徴量の時間変化を表現
• 特徴量の次元数は結合フレーム数倍へと増加!
• 動的(デルタ)特徴量の利用:関数フィッティング [Furui, 1981]
t-1 t
tx 1tx 2tx1tx2tx
tx
tx
tx
to 1to2to 1to 2to
線形変換
7
t+1
t
0-1-2 1 2
tt bfx )0(
tt afx 2)0(
ttt cbaf 2
)(二次関数:
一次微分:
二次微分:
前後2フレーム
(計5フレーム)
を使う場合の例
=
結合](https://image.slidesharecdn.com/slides20160803miruxkikutoda-170521035412/85/slide-12-320.jpg)
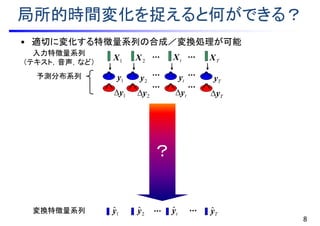
![?
局所的時間変化を捉えると何ができる?
• 適切に変化する特徴量系列の合成/変換処理が可能
8
TXtX2X1X
Tyˆ1
ˆy 2
ˆy tyˆ
T
t
ttttT pp
T
1
,,
1 ||maxargˆ,,ˆ
1
XyXyyy
yy
目標特徴量に
対する予測分布
局所的変化特徴量
に対する予測分布
特徴量系列の関数
変換
特徴量系列
生成処理 [Tokuda et al., 1995]
入力特徴量系列
(テキスト,音声,など)
予測分布系列 1y 2y ty Ty
フレーム毎に
予測しても・・・
系列単位の
予測が可能!
リアルタイム
統計的音声変換ソフト
奈良先端科学技術大学院大学
小林和弘さん作
1y 2y ty Ty
変換特徴量系列
TTp XXyy ,,|,, 11 ](https://image.slidesharecdn.com/slides20160803miruxkikutoda-170521035412/85/slide-14-320.jpg)
![2. 変化:大局的時間変動量を捉える
• 特徴量系列全体における変動量を抽出
0 1 2 3
Time [sec]
特徴量系列 特徴量の各次元における分散
考慮しない:誤差,音質
(=特徴量系列に対する非線形
変換により得られる特徴量)
9
T
t
tt pp
T
1
,,1
maxarg yy
yy
),,(maxarg 1
1
,,1
T
T
t
tt fppp
T
yyyy
yy
考慮する:誤差,音質
[Toda et al., 2007]](https://image.slidesharecdn.com/slides20160803miruxkikutoda-170521035412/85/slide-15-320.jpg)
![2. 変化:大局的時間変動量を捉える
• 特徴量系列全体における変動量を抽出
0 1 2 3
Time [sec]
特徴量系列
変調周波数
0 Hz
0.25 Hz
0.5 Hz
~ Hz
=…
特徴量の各次元における分散
考慮しない:誤差,音質
特徴量系列の変調スペクトル
へと拡張
(特徴量系列を各変調周波数
成分に分解して分散を計算)
(=特徴量系列に対する非線形
変換により得られる特徴量)
9
T
t
tt pp
T
1
,,1
maxarg yy
yy
),,(maxarg 1
1
,,1
T
T
t
tt fppp
T
yyyy
yy
考慮する:誤差,音質
[Toda et al., 2007]
[Takamichi et al., 2016]](https://image.slidesharecdn.com/slides20160803miruxkikutoda-170521035412/85/slide-16-320.jpg)
![3. 集積:因子分解を行う
スーパーベクトル
=平均ベクトルの連結
(音韻・話者依存)
)(
)(
2
)(
1
)1(
)1(
2
)1(
1
,,
J
M
J
J
M b
b
b
b
b
b
)(
)(
1
s
J
s
w
w
)0(
)0(
2
)0(
1
Mb
b
b
(s)
バイアスベクトル
=平均的な話者性
(音韻依存)
+
重みベクトル
(話者依存)×
+×
基底ベクトルセット
=代表的な話者性
(音韻依存)
=
このベクトルのみを制御
)(
)(
2
)(
1
s
M
s
s
μ
μ
μ
=
=
+
11
(s)
• 平均ベクトルセットに対して制約を導入 [Dehak et al., 2011]](https://image.slidesharecdn.com/slides20160803miruxkikutoda-170521035412/85/slide-20-320.jpg)
![• 知覚的な情報を操作して特徴量系列を加工することが可能
例.多数の歌唱者の歌声データに対して知覚年齢を付与しておき・・・
知覚年齢を説明変数として平均ベクトルセットをモデル化すると・・・
知覚年齢操作を可能とするボーカルエフェクターが完成
系列単位の特徴を使うと何ができる?
15歳 50歳35歳
変換処理
知覚年齢若い声色 老いた声色
歌唱者 変換処理
12
(s)
+×=
(s)
35歳
50歳
[Kobayashi et al., 2014]](https://image.slidesharecdn.com/slides20160803miruxkikutoda-170521035412/85/slide-21-320.jpg)

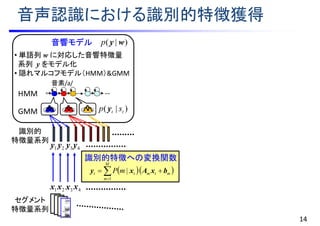
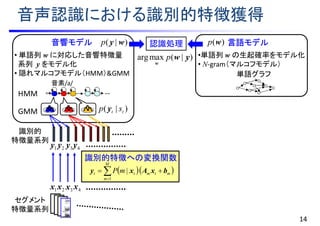
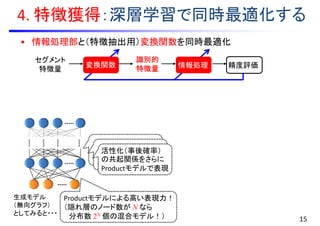
![音声認識における識別的特徴獲得
14
音素/a/
GMM
識別的特徴への変換関数
)|( tt sp y
)|( wyp
)()|( )()( rr
pp wwy
)|(ln; )(
ywwy r
pI
w
wwy )()|( pp
正解単語系列に対する確率
候補単語系列に対する確率
相互情報量最大化基準による
変換関数最適化
1x 2x 3x 4x
1y 2y 4y3y
音響モデル
• 単語列 w に対応した音響特徴量
系列 y をモデル化
• 隠れマルコフモデル(HMM)&GMM
)(wp 言語モデル
•単語列 w の生起確率をモデル化
• N-gram(マルコフモデル)
単語グラフ
認識処理
M
m
mtmtt mP
1
| bxAxy
識別的
特徴量系列
セグメント
特徴量系列
HMM
w
wwy
wwy
)()|(
)()|(
ln
)()(
pp
pp rr
)|(maxarg yw
w
p
[Povey et al., 2008]](https://image.slidesharecdn.com/slides20160803miruxkikutoda-170521035412/85/slide-27-320.jpg)
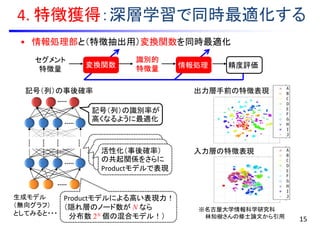

![• 各フレームにおいて各HMM状態出力確率をDNNで推定(脱GMM)
• フレーム単位の多クラス分類問題としてDNNを学習
• 各フレームに対してHMM状態を割り当て
• クロスエントロピー最小化により最適化
研究動向1:ハイブリッドアプローチ
17
Deep Neural
Network (DNN)
音素/a/ 音素/r/
各HMM状態の
事後確率を推定
)(
)|(
)|(
t
tt
tt
sp
sp
sp
y
y HMM状態の出力確率密度:
DNNで直接推定
学習データから事前に計算
音素/a/音素/r/
出力確率:DNNでフレーム毎に計算
遷移確率:HMMにより計算
[Seide et al., 2011]](https://image.slidesharecdn.com/slides20160803miruxkikutoda-170521035412/85/slide-32-320.jpg)
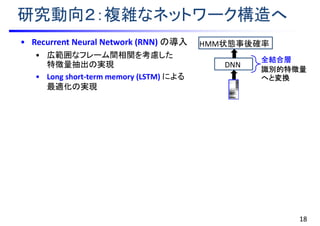
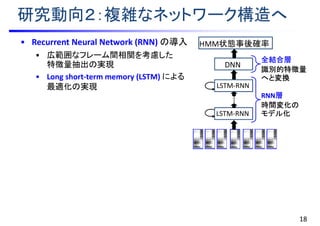
![研究動向2:複雑なネットワーク構造へ
• Recurrent Neural Network (RNN) の導入
• 広範囲なフレーム間相関を考慮した
特徴量抽出の実現
• Long short-term memory (LSTM) による
最適化の実現
• Convolutional Neural Network (CNN) の導入
• 周波数方向のシフト(および時間方向の
変動)に頑健な特徴量抽出
• 各フレームのセグメント特徴量を入力
DNN
[Sainath et al., 2015]
全結合層
識別的特徴量
へと変換
LSTM-RNN
LSTM-RNN
RNN層
時間変化の
モデル化
CNN
CNN
畳み込み層
変動に頑健な
特徴抽出
HMM状態事後確率
畳み込み
部分サンプリング
画像情報処理の知見を活用!
18](https://image.slidesharecdn.com/slides20160803miruxkikutoda-170521035412/85/slide-35-320.jpg)
![研究動向3:系列レベルの最適化へ
• HMMとのハイブリッドシステムの性能改善
• これまでに培われた最適化手法を適用可能
• 系列レベルの識別学習
• 言語モデルも考慮した最適化が可能
19
HMM状態系列
特徴量系列
出力系列
[Vesely et al., 2013]](https://image.slidesharecdn.com/slides20160803miruxkikutoda-170521035412/85/slide-36-320.jpg)
![研究動向3:系列レベルの最適化へ
• HMMとのハイブリッドシステムの性能改善
• これまでに培われた最適化手法を適用可能
• 系列レベルの識別学習
• 言語モデルも考慮した最適化が可能
• HMMをRNNで置き換え(脱HMM)
• Connectionist Temporal Classification (CTC)
• 空文字を挿入することで系列長の違いを吸収
例.青い⇒/a o i/⇒/aφφ oφφ i/, /aφ o φφφ i/
/a oφφφφ i/, /aφφφφ o i/,・・・
• HMM同様Forward-Backwardアルゴリズムを適用可
19
HMM状態系列
特徴量系列
出力系列
拡張音素系列
特徴量系列
出力系列
[Vesely et al., 2013]
[Graves et al., 2006]](https://image.slidesharecdn.com/slides20160803miruxkikutoda-170521035412/85/slide-37-320.jpg)
![研究動向3:系列レベルの最適化へ
• HMMとのハイブリッドシステムの性能改善
• これまでに培われた最適化手法を適用可能
• 系列レベルの識別学習
• 言語モデルも考慮した最適化が可能
• HMMをRNNで置き換え(脱HMM)
• Connectionist Temporal Classification (CTC)
• 空文字を挿入することで系列長の違いを吸収
例.青い⇒/a o i/⇒/aφφ oφφ i/, /aφ o φφφ i/
/a oφφφφ i/, /aφφφφ o i/,・・・
• HMM同様Forward-Backwardアルゴリズムを適用可
• 特徴量系列から音素系列に変換(ブラックボックス化)
• AttentionベースEncoder-Decoderの適用
• 全処理をニューラルネットワークで表現
画像情報処理との距離はどんどん縮まっている!
19
HMM状態系列
特徴量系列
出力系列
拡張音素系列
特徴量系列
出力系列
出力系列
特徴量系列
[Vesely et al., 2013]
[Graves et al., 2006]
[Bahdanau et al., 2016]](https://image.slidesharecdn.com/slides20160803miruxkikutoda-170521035412/85/slide-38-320.jpg)
![[DL輪読会]Wavenet a generative model for raw audio](https://cdn.slidesharecdn.com/ss_thumbnails/wavenetagenerativemodelforrawaudio-160920054055-thumbnail.jpg?width=640&height=640&fit=bounds)









![[DL輪読会]Diffusion-based Voice Conversion with Fast Maximum Likelihood Samplin...](https://cdn.slidesharecdn.com/ss_thumbnails/20220318akuzawa-220322065615-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DL輪読会]Parallel WaveNet: Fast High-Fidelity Speech Synthesis](https://cdn.slidesharecdn.com/ss_thumbnails/0105-180105000252-thumbnail.jpg?width=640&height=640&fit=bounds)










![[DL輪読会]相互情報量最大化による表現学習](https://cdn.slidesharecdn.com/ss_thumbnails/20190913iwasawa-190913002312-thumbnail.jpg?width=640&height=640&fit=bounds)







































