Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
Shinnosuke Takamichi
PDF, PPTX
946 views
論文紹介 SANTLR: Speech Annotation Toolkit for Low Resource Languages
https://connpass.com/event/152316/
Technology
◦
Read more
2
Save
Share
Embed
Embed presentation
Download
Download as PDF, PPTX
1
/ 15
2
/ 15
3
/ 15
4
/ 15
5
/ 15
6
/ 15
7
/ 15
8
/ 15
9
/ 15
10
/ 15
11
/ 15
12
/ 15
13
/ 15
14
/ 15
15
/ 15
More Related Content
PDF
JVS:フリーの日本語多数話者音声コーパス
by
Shinnosuke Takamichi
PDF
論文紹介 Building the Singapore English National Speech Corpus
by
Shinnosuke Takamichi
PPTX
日本語の語彙特性について
by
AsakuraYasunobu
PDF
音声合成研究を加速させるためのコーパスデザイン
by
Shinnosuke Takamichi
PDF
J-KAC:日本語オーディオブック・紙芝居朗読音声コーパス
by
Shinnosuke Takamichi
PDF
20180602 kawamura presentation_final
by
Yoshitake Misaki
PDF
小学生の読解支援に向けた語釈文による換言
by
長岡技術科学大学 自然言語処理研究室
PDF
江戸時代のバーチャルリアリティ
by
Tsukasa Makino
JVS:フリーの日本語多数話者音声コーパス
by
Shinnosuke Takamichi
論文紹介 Building the Singapore English National Speech Corpus
by
Shinnosuke Takamichi
日本語の語彙特性について
by
AsakuraYasunobu
音声合成研究を加速させるためのコーパスデザイン
by
Shinnosuke Takamichi
J-KAC:日本語オーディオブック・紙芝居朗読音声コーパス
by
Shinnosuke Takamichi
20180602 kawamura presentation_final
by
Yoshitake Misaki
小学生の読解支援に向けた語釈文による換言
by
長岡技術科学大学 自然言語処理研究室
江戸時代のバーチャルリアリティ
by
Tsukasa Makino
What's hot
PPTX
外国人留学生日本語の音声合成における 話者性を保持した韻律補正
by
Shinnosuke Takamichi
PDF
「やさしい日本語」のための語彙制限の検討
by
長岡技術科学大学 自然言語処理研究室
PDF
統計的ボイチェン研究事情
by
Shinnosuke Takamichi
PDF
HMMに基づく日本人英語音声合成における中学生徒の英語音声を用いた評価
by
Shinnosuke Takamichi
PDF
日本語モーラの持続時間長: 単音節語提示による知覚実験(JSLS2015)
by
Kosuke Sugai
PDF
公的文書に対する「やさしい日本語」換言辞書作成のための調査
by
長岡技術科学大学 自然言語処理研究室
PDF
読解支援 5 19
by
kentshioda
外国人留学生日本語の音声合成における 話者性を保持した韻律補正
by
Shinnosuke Takamichi
「やさしい日本語」のための語彙制限の検討
by
長岡技術科学大学 自然言語処理研究室
統計的ボイチェン研究事情
by
Shinnosuke Takamichi
HMMに基づく日本人英語音声合成における中学生徒の英語音声を用いた評価
by
Shinnosuke Takamichi
日本語モーラの持続時間長: 単音節語提示による知覚実験(JSLS2015)
by
Kosuke Sugai
公的文書に対する「やさしい日本語」換言辞書作成のための調査
by
長岡技術科学大学 自然言語処理研究室
読解支援 5 19
by
kentshioda
More from Shinnosuke Takamichi
PDF
テキスト音声合成技術と多様性への挑戦 (名古屋大学 知能システム特論)
by
Shinnosuke Takamichi
PDF
音声コーパス設計と次世代音声研究に向けた提言
by
Shinnosuke Takamichi
PDF
ここまで来た&これから来る音声合成 (明治大学 先端メディアコロキウム)
by
Shinnosuke Takamichi
PDF
音声合成・変換の国際コンペティションへの 参加を振り返って
by
Shinnosuke Takamichi
PDF
JTubeSpeech: 音声認識と話者照合のために YouTube から構築される日本語音声コーパス
by
Shinnosuke Takamichi
PDF
P J S: 音素バランスを考慮した日本語歌声コーパス
by
Shinnosuke Takamichi
PDF
統計的音声合成変換と近年の発展
by
Shinnosuke Takamichi
PPTX
多様なカートシスを持つ雑音に対応した低ミュージカルノイズ DNN 音声強調
by
Shinnosuke Takamichi
PDF
リアルタイムDNN音声変換フィードバックによるキャラクタ性の獲得手法
by
Shinnosuke Takamichi
PDF
ユーザ歌唱のための generative moment matching network に基づく neural double-tracking
by
Shinnosuke Takamichi
PDF
音響モデル尤度に基づくsubword分割の韻律推定精度における評価
by
Shinnosuke Takamichi
PDF
短時間発話を用いた話者照合のための音声加工の効果に関する検討
by
Shinnosuke Takamichi
PDF
End-to-end 韻律推定に向けた DNN 音響モデルに基づく subword 分割
by
Shinnosuke Takamichi
PDF
話者V2S攻撃: 話者認証から構築される 声質変換とその音声なりすまし可能性の評価
by
Shinnosuke Takamichi
PDF
論文紹介 Unsupervised training of neural mask-based beamforming
by
Shinnosuke Takamichi
PDF
Interspeech 2020 読み会 "Incremental Text to Speech for Neural Sequence-to-Sequ...
by
Shinnosuke Takamichi
PDF
国際会議 interspeech 2020 報告
by
Shinnosuke Takamichi
PDF
差分スペクトル法に基づく DNN 声質変換の計算量削減に向けたフィルタ推定
by
Shinnosuke Takamichi
PDF
音声合成のコーパスをつくろう
by
Shinnosuke Takamichi
PDF
サブバンドフィルタリングに基づくリアルタイム広帯域DNN声質変換の実装と評価
by
Shinnosuke Takamichi
テキスト音声合成技術と多様性への挑戦 (名古屋大学 知能システム特論)
by
Shinnosuke Takamichi
音声コーパス設計と次世代音声研究に向けた提言
by
Shinnosuke Takamichi
ここまで来た&これから来る音声合成 (明治大学 先端メディアコロキウム)
by
Shinnosuke Takamichi
音声合成・変換の国際コンペティションへの 参加を振り返って
by
Shinnosuke Takamichi
JTubeSpeech: 音声認識と話者照合のために YouTube から構築される日本語音声コーパス
by
Shinnosuke Takamichi
P J S: 音素バランスを考慮した日本語歌声コーパス
by
Shinnosuke Takamichi
統計的音声合成変換と近年の発展
by
Shinnosuke Takamichi
多様なカートシスを持つ雑音に対応した低ミュージカルノイズ DNN 音声強調
by
Shinnosuke Takamichi
リアルタイムDNN音声変換フィードバックによるキャラクタ性の獲得手法
by
Shinnosuke Takamichi
ユーザ歌唱のための generative moment matching network に基づく neural double-tracking
by
Shinnosuke Takamichi
音響モデル尤度に基づくsubword分割の韻律推定精度における評価
by
Shinnosuke Takamichi
短時間発話を用いた話者照合のための音声加工の効果に関する検討
by
Shinnosuke Takamichi
End-to-end 韻律推定に向けた DNN 音響モデルに基づく subword 分割
by
Shinnosuke Takamichi
話者V2S攻撃: 話者認証から構築される 声質変換とその音声なりすまし可能性の評価
by
Shinnosuke Takamichi
論文紹介 Unsupervised training of neural mask-based beamforming
by
Shinnosuke Takamichi
Interspeech 2020 読み会 "Incremental Text to Speech for Neural Sequence-to-Sequ...
by
Shinnosuke Takamichi
国際会議 interspeech 2020 報告
by
Shinnosuke Takamichi
差分スペクトル法に基づく DNN 声質変換の計算量削減に向けたフィルタ推定
by
Shinnosuke Takamichi
音声合成のコーパスをつくろう
by
Shinnosuke Takamichi
サブバンドフィルタリングに基づくリアルタイム広帯域DNN声質変換の実装と評価
by
Shinnosuke Takamichi
Recently uploaded
PDF
エンジニアが選ぶべきAIエディタ & Antigravity 活用例@ウェビナー「触ってみてどうだった?Google Antigravity 既存IDEと...
by
NorihiroSunada
PDF
Machine Tests Benchmark Suite. Explain github.com/alexziskind1/machine_tests #2
by
Tasuku Takahashi
PPTX
楽々ナレッジベース「楽ナレ」3種比較 - Dify / AWS S3 Vector / Google File Search Tool
by
Kiyohide Yamaguchi
PDF
流行りに乗っかるClaris FileMaker 〜AI関連機能の紹介〜 by 合同会社イボルブ
by
Evolve LLC.
PDF
Machine Tests Benchmark Suite. Explain github.com/alexziskind1/machine_tests #1
by
Tasuku Takahashi
PDF
20251210_MultiDevinForEnterprise on Devin 1st Anniv Meetup
by
Masaki Yamakawa
エンジニアが選ぶべきAIエディタ & Antigravity 活用例@ウェビナー「触ってみてどうだった?Google Antigravity 既存IDEと...
by
NorihiroSunada
Machine Tests Benchmark Suite. Explain github.com/alexziskind1/machine_tests #2
by
Tasuku Takahashi
楽々ナレッジベース「楽ナレ」3種比較 - Dify / AWS S3 Vector / Google File Search Tool
by
Kiyohide Yamaguchi
流行りに乗っかるClaris FileMaker 〜AI関連機能の紹介〜 by 合同会社イボルブ
by
Evolve LLC.
Machine Tests Benchmark Suite. Explain github.com/alexziskind1/machine_tests #1
by
Tasuku Takahashi
20251210_MultiDevinForEnterprise on Devin 1st Anniv Meetup
by
Masaki Yamakawa
論文紹介 SANTLR: Speech Annotation Toolkit for Low Resource Languages
1.
11/24/2019©Shinnosuke Takamichi, The University
of Tokyo SANTLR: Speech Annotation Toolkit for Low Resource Languages 高道 慎之介 (東京大学) Interspeech2019&サテライト読み会
2.
/15 自己紹介 2 高道 慎之介 東京大学 猿渡研
助教 @forthshinji 他の情報はググってください
3.
/15 研究背景:rich resource から
low resource へ 音声言語処理の高精度化 – 音声言語資源の豊富な言語 (rich-resource language) では高精度化 – 世界中のあらゆる言語のカバーへ • 文化保存,多様性 希少言語 (low-resource language) に向けたプロジェクト – UNESCO 2019年を先住民族言語年に [URL] – DARPA LORELEI [URL] (アメリカ) – 科研費「日本語諸方言コーパスの構築とコーパスを使った方言研究 の開拓」(国語研 木部先生) – 科研費「多方言音声合成のための地理情報を利用した音韻・アクセ ントモデリングに関する研究」(高道) 3
4.
/15 希少言語の音声言語処理に向けた研究 統計モデルの学習法 – Rich-resource
language からの転移学習 – 音声言語規則の教師なし推定 音声言語資源の収集 – WikiMatrix: 1,620言語の対訳テキスト – CMU WMSD: 700言語の音声コーパス アノテーション技術 – SPICE (2007) – SANTLR (本発表) 4
5.
SANTLR: Speech Annotation
Toolkit for Low Resource Languages X. Li (CMU) et al., Interspeech 5 Paper Code (公開予定?) Demo
6.
/15 概要と機能 概要: – ウェブベースのアノテーションツール –
(希少)言語の収集・アノテーションを容易に – “very user-friendly user interface” 機能1:transcription – 提供された音声を容易にアノテートできる 機能2:recording – 提供されたテキストを容易に収録できる 6
7.
/15 ポスター 7
8.
/15 デモ 8 https://www.dictate.app/
9.
/15 Section 2: User
interface (UI) ハイライト – 研究者とアノテータの両方にとって簡単なUIを用意 全自動の前処理 – HTMLタグや絵文字の自動除去 – 音声区間検出(VAD)により長い発話を自動分割 – 前処理後に共有可能な固有リンクを生成 研究者・アノテータ間の進捗共有 – 固有リンクを共有すると互いの進捗が分かる – 複数のアノテータによる処理も可能 9
10.
/15 Section 3: Utterance
ranking 今までのアノノーションツール – 対象音声を順々にアノテーションするしかなかった しかし実際には,音声のアノテーション優先度が存在する – アノテーションが簡単な音声や,音響モデル(構築)に有効な音声を 優先的にアノテーションすべき – 雑音の多い音声の優先度は低い 2つの ranking 機能を搭載 (次ページ) – Audio ranking (アノテーション時に動作) – Text ranking (レコーディング時に動作) 10
11.
/15 Audio ranking Step
1: sort by duration – 発話の短い音声ほどアノテーションしやすい – 発話長でソート (VADが入っているかは不明) Step 2: signal-to-noise (SN ratio) calculation – SN比の高い音声ほどアノテーションしやすい – Step 1の ranking の結果を,SN比の結果で補正 • アルゴリズムの詳細は不明 Step 3: ranking by phoneme overlaps – 大量のテキスト・音声で学習すると似たような発話が入る(英語の “year,” “no” など)が,これは音響モデルの学習精度を落とす – 当該発話の音素が他の発話の音素と強く重複する場合,rankを落とす • 英語の pre-trained 音響モデルでアライメント 11
12.
/15 Text ranking Step
1: sort by perplexity – 希少単語よりも頻用単語の方が発話しやすい – テキストから言語モデルを構築,文毎のパープレキシティを計算 – パープレキシティの小さい順にソート • 直感的には,頻用単語の多い順にソート Step 2: text overlap calculation – アノテータに多様な音声を発話させるため – Audio ranking と同じように,他の発話とテキストが重複している ものは,ランクを下げる 12
13.
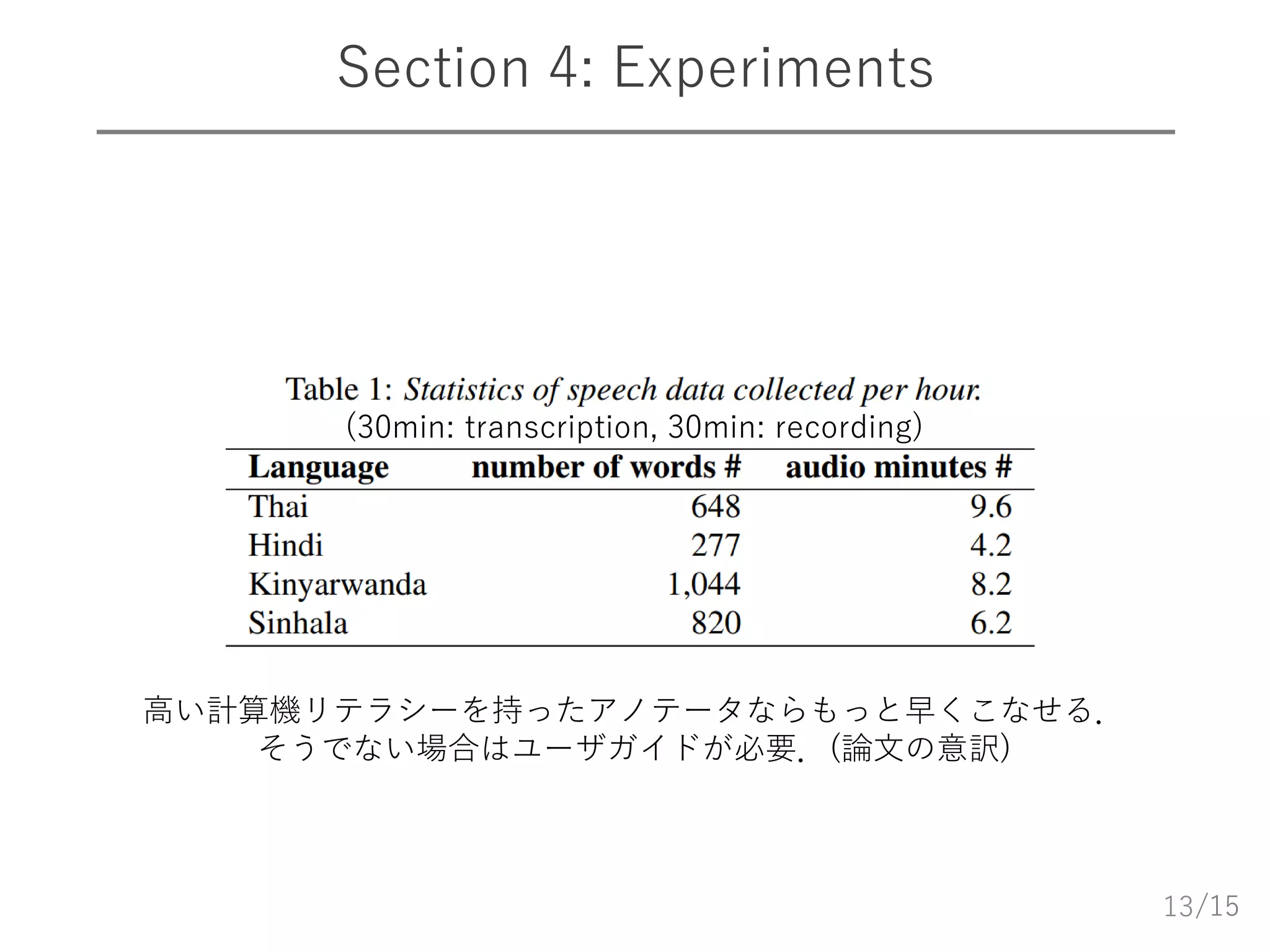
/15 Section 4: Experiments 13 (30min:
transcription, 30min: recording) 高い計算機リテラシーを持ったアノテータならもっと早くこなせる. そうでない場合はユーザガイドが必要.(論文の意訳)
14.
/15 まとめ アノテーションツールSANTLR – 音声収録・アノテーション –
やさしいUI – アノテーション優先度の計算 個人的な見解 – 強力なモデル(DNNなど)の登場によって我々のできることは拡大. – だからこそ高品質・安価・大量のアノテーション法の確立が必須. – 次の課題は「プロの専門技術をどうやってマイクロ化するか」 • 論文中でも近いことが言及されている 14
15.
/15 その他の関連発表 15 https://www.isca-speech.org/archive/Interspeech_2019/
Download


![/15
研究背景:rich resource から low resource へ
音声言語処理の高精度化
– 音声言語資源の豊富な言語 (rich-resource language) では高精度化
– 世界中のあらゆる言語のカバーへ
• 文化保存,多様性
希少言語 (low-resource language) に向けたプロジェクト
– UNESCO 2019年を先住民族言語年に [URL]
– DARPA LORELEI [URL] (アメリカ)
– 科研費「日本語諸方言コーパスの構築とコーパスを使った方言研究
の開拓」(国語研 木部先生)
– 科研費「多方言音声合成のための地理情報を利用した音韻・アクセ
ントモデリングに関する研究」(高道)
3](https://image.slidesharecdn.com/slide-191123081731/75/SANTLR-Speech-Annotation-Toolkit-for-Low-Resource-Languages-3-2048.jpg)