Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
Shinnosuke Takamichi
PDF, PPTX
1,740 views
ここまで来た&これから来る音声合成 (明治大学 先端メディアコロキウム)
明治大学 先端メディアコロキウム (2021/01/27)
Technology
◦
Read more
4
Save
Share
Embed
Embed presentation
Download
Download as PDF, PPTX
1
/ 34
2
/ 34
3
/ 34
4
/ 34
5
/ 34
6
/ 34
7
/ 34
8
/ 34
9
/ 34
10
/ 34
11
/ 34
12
/ 34
13
/ 34
14
/ 34
15
/ 34
16
/ 34
17
/ 34
18
/ 34
19
/ 34
20
/ 34
21
/ 34
22
/ 34
23
/ 34
24
/ 34
25
/ 34
26
/ 34
27
/ 34
28
/ 34
29
/ 34
30
/ 34
31
/ 34
32
/ 34
33
/ 34
34
/ 34
More Related Content
PDF
音声合成のコーパスをつくろう
by
Shinnosuke Takamichi
PDF
テキスト音声合成技術と多様性への挑戦 (名古屋大学 知能システム特論)
by
Shinnosuke Takamichi
PDF
深層学習と音響信号処理
by
Yuma Koizumi
PPTX
独立低ランク行列分析に基づくブラインド音源分離(Blind source separation based on independent low-rank...
by
Daichi Kitamura
PPTX
マルチモーダル深層学習の研究動向
by
Koichiro Mori
PDF
音情報処理における特徴表現
by
NU_I_TODALAB
PDF
雑音環境下音声を用いた音声合成のための雑音生成モデルの敵対的学習
by
Shinnosuke Takamichi
ODP
音声生成の基礎と音声学
by
Akinori Ito
音声合成のコーパスをつくろう
by
Shinnosuke Takamichi
テキスト音声合成技術と多様性への挑戦 (名古屋大学 知能システム特論)
by
Shinnosuke Takamichi
深層学習と音響信号処理
by
Yuma Koizumi
独立低ランク行列分析に基づくブラインド音源分離(Blind source separation based on independent low-rank...
by
Daichi Kitamura
マルチモーダル深層学習の研究動向
by
Koichiro Mori
音情報処理における特徴表現
by
NU_I_TODALAB
雑音環境下音声を用いた音声合成のための雑音生成モデルの敵対的学習
by
Shinnosuke Takamichi
音声生成の基礎と音声学
by
Akinori Ito
What's hot
PDF
ウィナーフィルタと適応フィルタ
by
Toshihisa Tanaka
PPTX
深層学習を用いた音源定位、音源分離、クラス分類の統合~環境音セグメンテーション手法の紹介~
by
Yui Sudo
PDF
リアルタイムDNN音声変換フィードバックによるキャラクタ性の獲得手法
by
Shinnosuke Takamichi
PDF
3D CNNによる人物行動認識の動向
by
Kensho Hara
PDF
音声感情認識の分野動向と実用化に向けたNTTの取り組み
by
Atsushi_Ando
PDF
サブバンドフィルタリングに基づくリアルタイム広帯域DNN声質変換の実装と評価
by
Shinnosuke Takamichi
PPTX
音源分離における音響モデリング(Acoustic modeling in audio source separation)
by
Daichi Kitamura
PPTX
非負値行列分解の確率的生成モデルと 多チャネル音源分離への応用 (Generative model in nonnegative matrix facto...
by
Daichi Kitamura
PDF
WaveNetが音声合成研究に与える影響
by
NU_I_TODALAB
PDF
音声コーパス設計と次世代音声研究に向けた提言
by
Shinnosuke Takamichi
PDF
深層学習を利用した音声強調
by
Yuma Koizumi
PDF
音源分離 ~DNN音源分離の基礎から最新技術まで~ Tokyo bishbash #3
by
Naoya Takahashi
ODP
音声認識の基礎
by
Akinori Ito
PDF
音声の声質を変換する技術とその応用
by
NU_I_TODALAB
PDF
ICASSP 2019での音響信号処理分野の世界動向
by
Yuma Koizumi
PDF
日本語モーラの持続時間長: 単音節語提示による知覚実験(JSLS2015)
by
Kosuke Sugai
ODP
音声合成の基礎
by
Akinori Ito
PPTX
半教師あり非負値行列因子分解における音源分離性能向上のための効果的な基底学習法
by
Daichi Kitamura
PDF
音声信号の分析と加工 - 音声を自在に変換するには?
by
NU_I_TODALAB
PDF
私がビギナーの頃を振り返って ~20代の代表として~
by
Shinnosuke Takamichi
ウィナーフィルタと適応フィルタ
by
Toshihisa Tanaka
深層学習を用いた音源定位、音源分離、クラス分類の統合~環境音セグメンテーション手法の紹介~
by
Yui Sudo
リアルタイムDNN音声変換フィードバックによるキャラクタ性の獲得手法
by
Shinnosuke Takamichi
3D CNNによる人物行動認識の動向
by
Kensho Hara
音声感情認識の分野動向と実用化に向けたNTTの取り組み
by
Atsushi_Ando
サブバンドフィルタリングに基づくリアルタイム広帯域DNN声質変換の実装と評価
by
Shinnosuke Takamichi
音源分離における音響モデリング(Acoustic modeling in audio source separation)
by
Daichi Kitamura
非負値行列分解の確率的生成モデルと 多チャネル音源分離への応用 (Generative model in nonnegative matrix facto...
by
Daichi Kitamura
WaveNetが音声合成研究に与える影響
by
NU_I_TODALAB
音声コーパス設計と次世代音声研究に向けた提言
by
Shinnosuke Takamichi
深層学習を利用した音声強調
by
Yuma Koizumi
音源分離 ~DNN音源分離の基礎から最新技術まで~ Tokyo bishbash #3
by
Naoya Takahashi
音声認識の基礎
by
Akinori Ito
音声の声質を変換する技術とその応用
by
NU_I_TODALAB
ICASSP 2019での音響信号処理分野の世界動向
by
Yuma Koizumi
日本語モーラの持続時間長: 単音節語提示による知覚実験(JSLS2015)
by
Kosuke Sugai
音声合成の基礎
by
Akinori Ito
半教師あり非負値行列因子分解における音源分離性能向上のための効果的な基底学習法
by
Daichi Kitamura
音声信号の分析と加工 - 音声を自在に変換するには?
by
NU_I_TODALAB
私がビギナーの頃を振り返って ~20代の代表として~
by
Shinnosuke Takamichi
Similar to ここまで来た&これから来る音声合成 (明治大学 先端メディアコロキウム)
PDF
【Deep Learning研修】 音声認識・音声合成技術とその応用 -基礎から最新動向まで-
by
Sony - Neural Network Libraries
PDF
Neural text-to-speech and voice conversion
by
Yuki Saito
PDF
深層生成モデルに基づく音声合成技術
by
NU_I_TODALAB
PDF
音声合成の今昔と深層学習を用いた音声合成
by
Genki Ishibashi
PDF
統計的ボイチェン研究事情
by
Shinnosuke Takamichi
PDF
[DL輪読会]Towards End-to-End Prosody Transfer for Expressive Speech Synthesis wi...
by
Deep Learning JP
PDF
統計的音声合成変換と近年の発展
by
Shinnosuke Takamichi
PDF
音声合成研究を加速させるためのコーパスデザイン
by
Shinnosuke Takamichi
PDF
深層学習に基づくテキスト音声合成の技術動向_言語音声ナイト
by
Deep Learning Lab(ディープラーニング・ラボ)
PDF
音声認識の仕組みを知ろう
by
kthrlab
PPTX
ICASSP2020音声&音響読み会Mellotron
by
Kentaro Tachibana
PPTX
NIPS2017報告 SPEECH & AUDIO
by
Koichiro Mori
PPTX
Kmcn demo
by
Yoshinori Hayashi
PDF
Thesis introduction audo_signal_processing
by
MakotoShirasu
【Deep Learning研修】 音声認識・音声合成技術とその応用 -基礎から最新動向まで-
by
Sony - Neural Network Libraries
Neural text-to-speech and voice conversion
by
Yuki Saito
深層生成モデルに基づく音声合成技術
by
NU_I_TODALAB
音声合成の今昔と深層学習を用いた音声合成
by
Genki Ishibashi
統計的ボイチェン研究事情
by
Shinnosuke Takamichi
[DL輪読会]Towards End-to-End Prosody Transfer for Expressive Speech Synthesis wi...
by
Deep Learning JP
統計的音声合成変換と近年の発展
by
Shinnosuke Takamichi
音声合成研究を加速させるためのコーパスデザイン
by
Shinnosuke Takamichi
深層学習に基づくテキスト音声合成の技術動向_言語音声ナイト
by
Deep Learning Lab(ディープラーニング・ラボ)
音声認識の仕組みを知ろう
by
kthrlab
ICASSP2020音声&音響読み会Mellotron
by
Kentaro Tachibana
NIPS2017報告 SPEECH & AUDIO
by
Koichiro Mori
Kmcn demo
by
Yoshinori Hayashi
Thesis introduction audo_signal_processing
by
MakotoShirasu
More from Shinnosuke Takamichi
PDF
JTubeSpeech: 音声認識と話者照合のために YouTube から構築される日本語音声コーパス
by
Shinnosuke Takamichi
PDF
短時間発話を用いた話者照合のための音声加工の効果に関する検討
by
Shinnosuke Takamichi
PPTX
外国人留学生日本語の音声合成における 話者性を保持した韻律補正
by
Shinnosuke Takamichi
PDF
国際会議 interspeech 2020 報告
by
Shinnosuke Takamichi
PDF
J-KAC:日本語オーディオブック・紙芝居朗読音声コーパス
by
Shinnosuke Takamichi
PDF
論文紹介 Unsupervised training of neural mask-based beamforming
by
Shinnosuke Takamichi
PDF
差分スペクトル法に基づく DNN 声質変換の計算量削減に向けたフィルタ推定
by
Shinnosuke Takamichi
PDF
JVS:フリーの日本語多数話者音声コーパス
by
Shinnosuke Takamichi
PPTX
多様なカートシスを持つ雑音に対応した低ミュージカルノイズ DNN 音声強調
by
Shinnosuke Takamichi
PDF
話者V2S攻撃: 話者認証から構築される 声質変換とその音声なりすまし可能性の評価
by
Shinnosuke Takamichi
PDF
P J S: 音素バランスを考慮した日本語歌声コーパス
by
Shinnosuke Takamichi
PDF
音声合成・変換の国際コンペティションへの 参加を振り返って
by
Shinnosuke Takamichi
PDF
論文紹介 SANTLR: Speech Annotation Toolkit for Low Resource Languages
by
Shinnosuke Takamichi
PPTX
Generative moment matching net に基づく歌声のランダム変調ポストフィルタと double-tracking への応用
by
Shinnosuke Takamichi
PDF
論文紹介 Building the Singapore English National Speech Corpus
by
Shinnosuke Takamichi
PDF
Interspeech 2020 読み会 "Incremental Text to Speech for Neural Sequence-to-Sequ...
by
Shinnosuke Takamichi
PDF
音響モデル尤度に基づくsubword分割の韻律推定精度における評価
by
Shinnosuke Takamichi
PDF
End-to-end 韻律推定に向けた DNN 音響モデルに基づく subword 分割
by
Shinnosuke Takamichi
PPTX
End-to-end 韻律推定に向けた subword lattice 構造を考慮した DNN 音響モデル学習
by
Shinnosuke Takamichi
PDF
ユーザ歌唱のための generative moment matching network に基づく neural double-tracking
by
Shinnosuke Takamichi
JTubeSpeech: 音声認識と話者照合のために YouTube から構築される日本語音声コーパス
by
Shinnosuke Takamichi
短時間発話を用いた話者照合のための音声加工の効果に関する検討
by
Shinnosuke Takamichi
外国人留学生日本語の音声合成における 話者性を保持した韻律補正
by
Shinnosuke Takamichi
国際会議 interspeech 2020 報告
by
Shinnosuke Takamichi
J-KAC:日本語オーディオブック・紙芝居朗読音声コーパス
by
Shinnosuke Takamichi
論文紹介 Unsupervised training of neural mask-based beamforming
by
Shinnosuke Takamichi
差分スペクトル法に基づく DNN 声質変換の計算量削減に向けたフィルタ推定
by
Shinnosuke Takamichi
JVS:フリーの日本語多数話者音声コーパス
by
Shinnosuke Takamichi
多様なカートシスを持つ雑音に対応した低ミュージカルノイズ DNN 音声強調
by
Shinnosuke Takamichi
話者V2S攻撃: 話者認証から構築される 声質変換とその音声なりすまし可能性の評価
by
Shinnosuke Takamichi
P J S: 音素バランスを考慮した日本語歌声コーパス
by
Shinnosuke Takamichi
音声合成・変換の国際コンペティションへの 参加を振り返って
by
Shinnosuke Takamichi
論文紹介 SANTLR: Speech Annotation Toolkit for Low Resource Languages
by
Shinnosuke Takamichi
Generative moment matching net に基づく歌声のランダム変調ポストフィルタと double-tracking への応用
by
Shinnosuke Takamichi
論文紹介 Building the Singapore English National Speech Corpus
by
Shinnosuke Takamichi
Interspeech 2020 読み会 "Incremental Text to Speech for Neural Sequence-to-Sequ...
by
Shinnosuke Takamichi
音響モデル尤度に基づくsubword分割の韻律推定精度における評価
by
Shinnosuke Takamichi
End-to-end 韻律推定に向けた DNN 音響モデルに基づく subword 分割
by
Shinnosuke Takamichi
End-to-end 韻律推定に向けた subword lattice 構造を考慮した DNN 音響モデル学習
by
Shinnosuke Takamichi
ユーザ歌唱のための generative moment matching network に基づく neural double-tracking
by
Shinnosuke Takamichi
Recently uploaded
PDF
2025→2026宙畑ゆく年くる年レポート_100社を超える企業アンケート総まとめ!!_企業まとめ_1229_3版
by
sorabatake
PDF
自転車ユーザ参加型路面画像センシングによる点字ブロック検出における性能向上方法の模索 (20260123 SeMI研)
by
Yuto Matsuda
PDF
ST2024_PM1_2_Case_study_of_local_newspaper_company.pdf
by
akipii ogaoga
PDF
第21回 Gen AI 勉強会「NotebookLMで60ページ超の スライドを作成してみた」
by
嶋 是一 (Yoshikazu SHIMA)
PDF
Team Topology Adaptive Organizational Design for Rapid Delivery of Valuable S...
by
akipii ogaoga
PDF
Starlink Direct-to-Cell (D2C) 技術の概要と将来の展望
by
CRI Japan, Inc.
PDF
100年後の知財業界-生成AIスライドアドリブプレゼン イーパテントYouTube配信
by
e-Patent Co., Ltd.
PDF
Reiwa 7 IT Strategist Afternoon I Question-1 3C Analysis
by
akipii ogaoga
PDF
FY2025 IT Strategist Afternoon I Question-1 Balanced Scorecard
by
akipii ogaoga
PDF
Reiwa 7 IT Strategist Afternoon I Question-1 Ansoff's Growth Vector
by
akipii ogaoga
PDF
PMBOK 7th Edition_Project Management Process_WF Type Development
by
akipii ogaoga
PDF
PMBOK 7th Edition Project Management Process Scrum
by
akipii ogaoga
PDF
PMBOK 7th Edition_Project Management Context Diagram
by
akipii ogaoga
2025→2026宙畑ゆく年くる年レポート_100社を超える企業アンケート総まとめ!!_企業まとめ_1229_3版
by
sorabatake
自転車ユーザ参加型路面画像センシングによる点字ブロック検出における性能向上方法の模索 (20260123 SeMI研)
by
Yuto Matsuda
ST2024_PM1_2_Case_study_of_local_newspaper_company.pdf
by
akipii ogaoga
第21回 Gen AI 勉強会「NotebookLMで60ページ超の スライドを作成してみた」
by
嶋 是一 (Yoshikazu SHIMA)
Team Topology Adaptive Organizational Design for Rapid Delivery of Valuable S...
by
akipii ogaoga
Starlink Direct-to-Cell (D2C) 技術の概要と将来の展望
by
CRI Japan, Inc.
100年後の知財業界-生成AIスライドアドリブプレゼン イーパテントYouTube配信
by
e-Patent Co., Ltd.
Reiwa 7 IT Strategist Afternoon I Question-1 3C Analysis
by
akipii ogaoga
FY2025 IT Strategist Afternoon I Question-1 Balanced Scorecard
by
akipii ogaoga
Reiwa 7 IT Strategist Afternoon I Question-1 Ansoff's Growth Vector
by
akipii ogaoga
PMBOK 7th Edition_Project Management Process_WF Type Development
by
akipii ogaoga
PMBOK 7th Edition Project Management Process Scrum
by
akipii ogaoga
PMBOK 7th Edition_Project Management Context Diagram
by
akipii ogaoga
ここまで来た&これから来る音声合成 (明治大学 先端メディアコロキウム)
1.
01/27/2021©Shinnosuke Takamichi, The University
of Tokyo 先端メディアコロキウム@明治大学 ここまで来た&これから来る音声合成 高道 慎之介 (東京大学)
2.
/34 自己紹介 2 経歴 専門 名前 高道 慎之介 (たかみち
しんのすけ) 熊本高専(熊本)→長岡技大(新潟)→ 奈良先端大(奈良) 音声情報処理 現職 東京大学 情報理工学系研究科 助教
3.
3 今日の内容 ここまで来た&これから来る音声合成 何をできるように なったのか? 何を研究 しているのか?
4.
ここまで来た音声合成 4
5.
/34 音声とは ➢ 物理信号である – 肺からの呼気を声帯と声道で制御 –
空気中や通信回路を介して利き手に伝播 ➢ 情報を伝達・享受する手段である – 話し手は,コンセプト(言語・意図など)を音声にエンコード – 聞き手は,音声からコンセプトをデコード ➢ 個人情報である – 言語性 (氏名,住所,…) – 話者性・文化性・身体性 … 5 音声は,物理世界と情報世界をまたぐメディアである.
6.
/34 (広義の)音声合成が目指すもの 6
7.
/34 音声合成バーチャルアナウンサー 7 20200101 TBSテレビ「令和も見せます!森田さんのニッポンの初日の出」 [Koguchi20 (現在,森勢研M1)] *
製作者から許諾を得て利用しております 公開版につき内容を削除しました
8.
/34 リアルタイム音声変換 (名探偵コナンの蝶ネクタイ型変声機) 8 https://www.youtube.com/watch?v=P9rGqoYnfCg 更に… https://www.youtube.com/watch?v=vFSHxn_G2iQ [Arakawa19][Saeki20] * 製作者から許諾を得て利用しております
9.
/34 なぜ出来るようになった? ➢ 基本的な仕組み – テキスト・音声データの対を用意 –
その対応関係を機械学習 (深層学習) ➢ なぜ出来るようになった? – 共有資源としての音声資源創出 (後述) – 深層学習技術の発達 (本講義では省略) 9 Text 機械学習 機械学習
10.
これから来る音声合成 10
11.
音声なりすまし 11
12.
/34 音声なりすまし ➢ 音声なりすましとは – 音声で他人になりすますセキュリティ攻撃 –
電話口で実在人物になりすまし,不当な利益を得るなど ➢ なぜ起こる? – (有名人などは) 動画サイトに大量の音声データがある – そのデータを使って音声合成 … 音声合成に無関係の話ではない ➢ 身近なところでは起こらない? -> No. – スマートスピーカの利用 [Nakamura19] 12
13.
/34 話者 verification-to-synthesis (V2S)
攻撃 13 音声なりすまし 音声で個人認証 話者認証を暴露 変換 [Nakamura19] ➢ スマートスピーカにおける話者認証 (話者認識) – スマートスピーカの中に音声データは保存されない – 音声から話者を推定する話者認証機能がある ➢ 話者 V2S 攻撃 – 音声ではなく話者認証から,その人の声になる音声変換はできて しまうのか? “〇〇さん こんにちは!”
14.
/34 V2S攻撃における音声変換の学習 14 音声変換の目的関数 = 話者性の復元関数
+ 内容の保存関数 変換側(攻撃側) 認証側 攻撃対象話者の 話者ラベル 話者認証モデル Mean squared error 音声変換モデル 音声認識 モデル 音素事後確率 Softmax cross-entropy 変換前後で発話内容を保存 攻撃対象話者の話者性を復元 攻撃者の 音声特徴量
15.
/34 結果 ➢ 変換音声の品質 – 本人の少量
(~1分) の音声データを入手した音声変換と同程度 – 本人の実際の音声とはやや異なるのが現状 ➢ 今後はどう進む? – 防御側も当然研究されている • 人間の音声 or 人工音声? • 人間の音声 or 録音音声? – しばらくはいたちごっこが続く 15 変換 本人の音声 V2S攻撃 少量の音声を入手した 通常の音声変換
16.
音声の非実在性のモデリング 16
17.
/34 音声の非実在性 ➢ 人間が許容できるメディアは実在データだけか? ->
No. – 人間はメディアの逸脱に対して許容範囲を持つ • 例:ボイスチェンジャで非実在の音声を作っても,人格を認める • 例:発音が多少訛っていても,内容を聞き取れる – この許容範囲 (知覚分布) を計算機でモデル化できないか? • 実在しない音声をもつ音声エージェントなど ➢ ヒント:GAN (敵対的生成ネットワーク) [Goodfellow14] – 実在データ分布を表現するDNN – 実在データと生成データを識別する識別器を騙して学習 • “人工知能が絵を描いた!” 17 人間を騙せば,知覚分布を表現するDNNを作るのでは?
18.
/34 GANと人間GAN 18 Prior distr. Generated data Generator Discriminator Natu- ral Train to
fool computer-based discriminator. GAN Training Distribution of training data Generation Crowdworkers Natu- ral Train to fool crowdworkers (= crowd-based discriminator). HumanGAN Training Distribution of human perception Generation [Fujii20]
19.
/34 GAN:DNNで記述される識別器を騙す 19 Natural Generated ⋯ ⋯ ⋯ ⋯ Generator Generated Discri- minator Prior distr. 生成モデルも識別モデルも微分可能なので, backpropagation で学習可能 [Goodfellow14]
20.
/34 人間の知覚する話者性(明るいほど「人間らし い声」と主観的に評価された合成音声) 20 1st dim. of
speech feature 2nd dim. of speech feature 実在音声の分布 (GANで表現可能) 知覚分布 (GANで表現不可. 人が評価しないと 分からない) 生成モデルは微分可能だが識別モデル (=人間) は微分不可能. どうやって生成モデルを学習する?
21.
/34 人間を「事後確率差分を出力するblack-box」と みなし,勾配を近似 21 生成データに微少な摂動を加え,摂動の影響を人間に評価させる. それらの比で勾配を近似して生成モデルを学習 [Fujii20]
22.
/34 人間GAN:人間で記述される識別器を騙す 22 ⋯ ⋯ ⋯ ⋯ Generator Generated Prior distr. Crowdworkers * 学習時にカラーマップを使用しないことに注意 人間を微分してDNNを学習できるようになった! [Fujii20]
23.
自己音声VR 23
24.
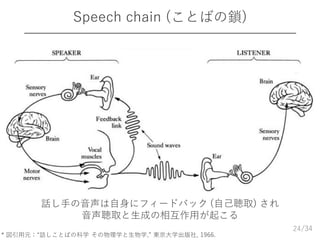
/34 Speech chain (ことばの鎖) 24 *
図引用元:“話しことばの科学 その物理学と生物学,” 東京大学出版社, 1966. 話し手の音声は自身にフィードバック (自己聴取) され 音声聴取と生成の相互作用が起こる
25.
/34 Computational speech chain
(SCOPE 2019~) 25 音声聴取 音声生成 リアルタイム 音声変換 高没入感 フィードバック 自己聴取音を制御して,人間の音声生成を制御できる? 人間参加 機械学習
26.
/34 我々は何までならなれる? 26 公開版につき内容を削除しました
27.
アバター共生社会の音声合成 27
28.
/34 内閣府ムーンショット目標1「2050年までに、人が身体、 脳、空間、時間の制約から解放された社会を実現」 28 * 図引用元:https://www.jst.go.jp/moonshot/program/goal1/files/goal1_explanation1.pdf
29.
/34 音声合成は何ができるか? ➢ 人間を中心とした音声合成技術 – いかに手軽に音声コピーを作れるか –
信頼できる不確実性をもった音声合成 – さらにさらに本人らしく ➢ アバターを中心とした音声合成技術 – アバターの中の人への没入 – 非実在性音声の実現 – 音声コミュニケーションの半自動化 29 数年かけてやっていくので,お楽しみに!
30.
共通資源としての音声 30
31.
/34 音声合成が発達したのは音声資源のおかげ ➢ なぜ音声合成が出来るようになった? (再掲) –
共有資源としての音声資源(音声データ)創出 ➢ 音声合成ができないことは多々ある – 「少数言語のテキスト読み上げ」の品質が人間と同程度なだけ – 人間の代替を目的としてもまだまだ ➢ 音声は石油である – “Data is the new oil”.音声研究者にとって “データ=音声”. – 音声の分野では,音声資源に特化した国際会議もあるくらい – 音声の献血 (献声?) のようなプロジェクトもあるのでぜひ. • 口から油を垂れ流すのはもったいない! 31
32.
/34 いまから始める音声合成 ➢ 日本語音声合成・音声変換用データ – JSUTコーパス
(“JUST”ではない) … 単一話者読み上げ10時間 – JSSSコーパス … 単一話者ニュース8時間 – JVSコーパス … 100人話者読み上げ30時間 • ググればダウンロードできます! • Qiita, github にもいくつか記事がある ➢ ツール – nnmnkwii (LINE 山本氏) – ESPNet (CMU 渡部氏) 32 音声合成初心者でもすぐ試せるよう整備を進めております
33.
まとめ 33
34.
/34 まとめ ➢ ここまで来た音声合成 – AIアバター –
リアルタイムなりきりボイスチェンジャ ➢ これから来る音声合成 – 音声なりすましとの闘い – 人間参加型 – 音声VR – アバター共生社会 ➢ Take-home メッセージ – 音声合成は,やっと他分野と複合できるくらいの品質になってきた – “音声合成=テキスト読み上げ”,”音声変換=蝶ネクタイ型変声器”の 言葉に呪われない,多様な利用を期待します. 34
Download







![/34
音声合成バーチャルアナウンサー
7
20200101 TBSテレビ「令和も見せます!森田さんのニッポンの初日の出」
[Koguchi20 (現在,森勢研M1)]
* 製作者から許諾を得て利用しております
公開版につき内容を削除しました](https://image.slidesharecdn.com/slidepublic-210127061531/85/slide-7-320.jpg)
![/34
リアルタイム音声変換
(名探偵コナンの蝶ネクタイ型変声機)
8
https://www.youtube.com/watch?v=P9rGqoYnfCg
更に… https://www.youtube.com/watch?v=vFSHxn_G2iQ
[Arakawa19][Saeki20]
* 製作者から許諾を得て利用しております](https://image.slidesharecdn.com/slidepublic-210127061531/85/slide-8-320.jpg)



![/34
音声なりすまし
➢ 音声なりすましとは
– 音声で他人になりすますセキュリティ攻撃
– 電話口で実在人物になりすまし,不当な利益を得るなど
➢ なぜ起こる?
– (有名人などは) 動画サイトに大量の音声データがある
– そのデータを使って音声合成 … 音声合成に無関係の話ではない
➢ 身近なところでは起こらない? -> No.
– スマートスピーカの利用 [Nakamura19]
12](https://image.slidesharecdn.com/slidepublic-210127061531/85/slide-12-320.jpg)
![/34
話者 verification-to-synthesis (V2S) 攻撃
13
音声なりすまし
音声で個人認証 話者認証を暴露
変換
[Nakamura19]
➢ スマートスピーカにおける話者認証 (話者認識)
– スマートスピーカの中に音声データは保存されない
– 音声から話者を推定する話者認証機能がある
➢ 話者 V2S 攻撃
– 音声ではなく話者認証から,その人の声になる音声変換はできて
しまうのか?
“〇〇さん
こんにちは!”](https://image.slidesharecdn.com/slidepublic-210127061531/85/slide-13-320.jpg)



![/34
音声の非実在性
➢ 人間が許容できるメディアは実在データだけか? -> No.
– 人間はメディアの逸脱に対して許容範囲を持つ
• 例:ボイスチェンジャで非実在の音声を作っても,人格を認める
• 例:発音が多少訛っていても,内容を聞き取れる
– この許容範囲 (知覚分布) を計算機でモデル化できないか?
• 実在しない音声をもつ音声エージェントなど
➢ ヒント:GAN (敵対的生成ネットワーク) [Goodfellow14]
– 実在データ分布を表現するDNN
– 実在データと生成データを識別する識別器を騙して学習
• “人工知能が絵を描いた!”
17
人間を騙せば,知覚分布を表現するDNNを作るのでは?](https://image.slidesharecdn.com/slidepublic-210127061531/85/slide-17-320.jpg)
![/34
GANと人間GAN
18
Prior
distr.
Generated
data
Generator Discriminator
Natu-
ral
Train to fool computer-based
discriminator.
GAN
Training
Distribution of training data
Generation
Crowdworkers
Natu-
ral
Train to fool crowdworkers
(= crowd-based discriminator).
HumanGAN
Training
Distribution of human perception
Generation
[Fujii20]](https://image.slidesharecdn.com/slidepublic-210127061531/85/slide-18-320.jpg)
![/34
GAN:DNNで記述される識別器を騙す
19
Natural
Generated
⋯
⋯
⋯
⋯
Generator
Generated
Discri-
minator
Prior
distr.
生成モデルも識別モデルも微分可能なので,
backpropagation で学習可能
[Goodfellow14]](https://image.slidesharecdn.com/slidepublic-210127061531/85/slide-19-320.jpg)

![/34
人間を「事後確率差分を出力するblack-box」と
みなし,勾配を近似
21
生成データに微少な摂動を加え,摂動の影響を人間に評価させる.
それらの比で勾配を近似して生成モデルを学習
[Fujii20]](https://image.slidesharecdn.com/slidepublic-210127061531/85/slide-21-320.jpg)
![/34
人間GAN:人間で記述される識別器を騙す
22
⋯
⋯
⋯
⋯
Generator
Generated
Prior
distr.
Crowdworkers
* 学習時にカラーマップを使用しないことに注意
人間を微分してDNNを学習できるようになった!
[Fujii20]](https://image.slidesharecdn.com/slidepublic-210127061531/85/slide-22-320.jpg)












































![[DL輪読会]Towards End-to-End Prosody Transfer for Expressive Speech Synthesis wi...](https://cdn.slidesharecdn.com/ss_thumbnails/towards-end-to-end-prosody-transfer-for-expressive-speech-synthesis-with-tacotronicml-2018-210625020158-thumbnail.jpg?width=640&height=640&fit=bounds)








































