Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
Shinnosuke Takamichi
62,695 views
やさしく音声分析法を学ぶ: ケプストラム分析とLPC分析
音声分析法のであるケプストラム分析とLPC分析について、 簡単に説明したものです。 音声研究の初学者向け。 twitter: forthshinji
Education
◦
Read more
19
Save
Share
Embed
Embed presentation
Download
Downloaded 295 times
1
/ 17
2
/ 17
3
/ 17
4
/ 17
5
/ 17
6
/ 17
7
/ 17
8
/ 17
9
/ 17
10
/ 17
11
/ 17
12
/ 17
13
/ 17
14
/ 17
Most read
15
/ 17
Most read
16
/ 17
Most read
17
/ 17
More Related Content
PDF
深層学習を利用した音声強調
by
Yuma Koizumi
PPTX
音響メディア信号処理における独立成分分析の発展と応用, History of independent component analysis for sou...
by
Daichi Kitamura
PDF
Interspeech2022 参加報告
by
Yuki Saito
PPTX
音源分離における音響モデリング(Acoustic modeling in audio source separation)
by
Daichi Kitamura
PDF
グラフィカル Lasso を用いた異常検知
by
Yuya Takashina
PDF
ICASSP 2019での音響信号処理分野の世界動向
by
Yuma Koizumi
PDF
Neural text-to-speech and voice conversion
by
Yuki Saito
PPTX
ウェーブレット変換の基礎と応用事例:連続ウェーブレット変換を中心に
by
Ryosuke Tachibana
深層学習を利用した音声強調
by
Yuma Koizumi
音響メディア信号処理における独立成分分析の発展と応用, History of independent component analysis for sou...
by
Daichi Kitamura
Interspeech2022 参加報告
by
Yuki Saito
音源分離における音響モデリング(Acoustic modeling in audio source separation)
by
Daichi Kitamura
グラフィカル Lasso を用いた異常検知
by
Yuya Takashina
ICASSP 2019での音響信号処理分野の世界動向
by
Yuma Koizumi
Neural text-to-speech and voice conversion
by
Yuki Saito
ウェーブレット変換の基礎と応用事例:連続ウェーブレット変換を中心に
by
Ryosuke Tachibana
What's hot
PDF
SSII2021 [OS2-01] 転移学習の基礎:異なるタスクの知識を利用するための機械学習の方法
by
SSII
PDF
SSII2022 [TS1] Transformerの最前線〜 畳込みニューラルネットワークの先へ 〜
by
SSII
PDF
【メタサーベイ】数式ドリブン教師あり学習
by
cvpaper. challenge
PDF
敵対的学習による統合型ソースフィルタネットワーク
by
NU_I_TODALAB
PDF
深層生成モデルに基づく音声合成技術
by
NU_I_TODALAB
PDF
coordinate descent 法について
by
京都大学大学院情報学研究科数理工学専攻
PPTX
深層学習を用いた音源定位、音源分離、クラス分類の統合~環境音セグメンテーション手法の紹介~
by
Yui Sudo
PPTX
深層学習の数理
by
Taiji Suzuki
PPTX
半教師あり非負値行列因子分解における音源分離性能向上のための効果的な基底学習法
by
Daichi Kitamura
PDF
最近のDeep Learning (NLP) 界隈におけるAttention事情
by
Yuta Kikuchi
PDF
AHC-Lab M1勉強会 論文の読み方・書き方
by
Shinagawa Seitaro
PDF
音声認識と深層学習
by
Preferred Networks
PDF
GAN(と強化学習との関係)
by
Masahiro Suzuki
PDF
実環境音響信号処理における収音技術
by
Yuma Koizumi
PDF
音声合成のコーパスをつくろう
by
Shinnosuke Takamichi
ODP
音声認識の基礎
by
Akinori Ito
PDF
WaveNetが音声合成研究に与える影響
by
NU_I_TODALAB
PPTX
独立低ランク行列分析に基づくブラインド音源分離(Blind source separation based on independent low-rank...
by
Daichi Kitamura
PDF
環境音の特徴を活用した音響イベント検出・シーン分類
by
Keisuke Imoto
PDF
異常音検知の実用化に向けて
by
Ryohei Yamaguchi
SSII2021 [OS2-01] 転移学習の基礎:異なるタスクの知識を利用するための機械学習の方法
by
SSII
SSII2022 [TS1] Transformerの最前線〜 畳込みニューラルネットワークの先へ 〜
by
SSII
【メタサーベイ】数式ドリブン教師あり学習
by
cvpaper. challenge
敵対的学習による統合型ソースフィルタネットワーク
by
NU_I_TODALAB
深層生成モデルに基づく音声合成技術
by
NU_I_TODALAB
coordinate descent 法について
by
京都大学大学院情報学研究科数理工学専攻
深層学習を用いた音源定位、音源分離、クラス分類の統合~環境音セグメンテーション手法の紹介~
by
Yui Sudo
深層学習の数理
by
Taiji Suzuki
半教師あり非負値行列因子分解における音源分離性能向上のための効果的な基底学習法
by
Daichi Kitamura
最近のDeep Learning (NLP) 界隈におけるAttention事情
by
Yuta Kikuchi
AHC-Lab M1勉強会 論文の読み方・書き方
by
Shinagawa Seitaro
音声認識と深層学習
by
Preferred Networks
GAN(と強化学習との関係)
by
Masahiro Suzuki
実環境音響信号処理における収音技術
by
Yuma Koizumi
音声合成のコーパスをつくろう
by
Shinnosuke Takamichi
音声認識の基礎
by
Akinori Ito
WaveNetが音声合成研究に与える影響
by
NU_I_TODALAB
独立低ランク行列分析に基づくブラインド音源分離(Blind source separation based on independent low-rank...
by
Daichi Kitamura
環境音の特徴を活用した音響イベント検出・シーン分類
by
Keisuke Imoto
異常音検知の実用化に向けて
by
Ryohei Yamaguchi
More from Shinnosuke Takamichi
PDF
JTubeSpeech: 音声認識と話者照合のために YouTube から構築される日本語音声コーパス
by
Shinnosuke Takamichi
PDF
JVS:フリーの日本語多数話者音声コーパス
by
Shinnosuke Takamichi
PDF
ここまで来た&これから来る音声合成 (明治大学 先端メディアコロキウム)
by
Shinnosuke Takamichi
PDF
リアルタイムDNN音声変換フィードバックによるキャラクタ性の獲得手法
by
Shinnosuke Takamichi
PDF
論文紹介 Unsupervised training of neural mask-based beamforming
by
Shinnosuke Takamichi
PDF
サブバンドフィルタリングに基づくリアルタイム広帯域DNN声質変換の実装と評価
by
Shinnosuke Takamichi
PDF
国際会議 interspeech 2020 報告
by
Shinnosuke Takamichi
PDF
J-KAC:日本語オーディオブック・紙芝居朗読音声コーパス
by
Shinnosuke Takamichi
PDF
短時間発話を用いた話者照合のための音声加工の効果に関する検討
by
Shinnosuke Takamichi
PDF
P J S: 音素バランスを考慮した日本語歌声コーパス
by
Shinnosuke Takamichi
PDF
話者V2S攻撃: 話者認証から構築される 声質変換とその音声なりすまし可能性の評価
by
Shinnosuke Takamichi
PDF
差分スペクトル法に基づく DNN 声質変換の計算量削減に向けたフィルタ推定
by
Shinnosuke Takamichi
PDF
論文紹介 SANTLR: Speech Annotation Toolkit for Low Resource Languages
by
Shinnosuke Takamichi
PDF
音声合成・変換の国際コンペティションへの 参加を振り返って
by
Shinnosuke Takamichi
PDF
ユーザ歌唱のための generative moment matching network に基づく neural double-tracking
by
Shinnosuke Takamichi
PDF
論文紹介 Building the Singapore English National Speech Corpus
by
Shinnosuke Takamichi
PDF
音声合成研究を加速させるためのコーパスデザイン
by
Shinnosuke Takamichi
PDF
音響モデル尤度に基づくsubword分割の韻律推定精度における評価
by
Shinnosuke Takamichi
PDF
End-to-end 韻律推定に向けた DNN 音響モデルに基づく subword 分割
by
Shinnosuke Takamichi
PDF
Interspeech 2020 読み会 "Incremental Text to Speech for Neural Sequence-to-Sequ...
by
Shinnosuke Takamichi
JTubeSpeech: 音声認識と話者照合のために YouTube から構築される日本語音声コーパス
by
Shinnosuke Takamichi
JVS:フリーの日本語多数話者音声コーパス
by
Shinnosuke Takamichi
ここまで来た&これから来る音声合成 (明治大学 先端メディアコロキウム)
by
Shinnosuke Takamichi
リアルタイムDNN音声変換フィードバックによるキャラクタ性の獲得手法
by
Shinnosuke Takamichi
論文紹介 Unsupervised training of neural mask-based beamforming
by
Shinnosuke Takamichi
サブバンドフィルタリングに基づくリアルタイム広帯域DNN声質変換の実装と評価
by
Shinnosuke Takamichi
国際会議 interspeech 2020 報告
by
Shinnosuke Takamichi
J-KAC:日本語オーディオブック・紙芝居朗読音声コーパス
by
Shinnosuke Takamichi
短時間発話を用いた話者照合のための音声加工の効果に関する検討
by
Shinnosuke Takamichi
P J S: 音素バランスを考慮した日本語歌声コーパス
by
Shinnosuke Takamichi
話者V2S攻撃: 話者認証から構築される 声質変換とその音声なりすまし可能性の評価
by
Shinnosuke Takamichi
差分スペクトル法に基づく DNN 声質変換の計算量削減に向けたフィルタ推定
by
Shinnosuke Takamichi
論文紹介 SANTLR: Speech Annotation Toolkit for Low Resource Languages
by
Shinnosuke Takamichi
音声合成・変換の国際コンペティションへの 参加を振り返って
by
Shinnosuke Takamichi
ユーザ歌唱のための generative moment matching network に基づく neural double-tracking
by
Shinnosuke Takamichi
論文紹介 Building the Singapore English National Speech Corpus
by
Shinnosuke Takamichi
音声合成研究を加速させるためのコーパスデザイン
by
Shinnosuke Takamichi
音響モデル尤度に基づくsubword分割の韻律推定精度における評価
by
Shinnosuke Takamichi
End-to-end 韻律推定に向けた DNN 音響モデルに基づく subword 分割
by
Shinnosuke Takamichi
Interspeech 2020 読み会 "Incremental Text to Speech for Neural Sequence-to-Sequ...
by
Shinnosuke Takamichi
やさしく音声分析法を学ぶ: ケプストラム分析とLPC分析
1.
高道 慎之介 ケプストラム分析 &
LPC分析
2.
/34 スライドについて 音声の特徴とは? – 基本周波数、声道の特性など
何故そんなことをするのか? – 少ないパラメータで音声波形を表現できる – 音声を効率的・直感的に扱える – 複数の特徴を分離できる – など 2 音声の特徴を分析する手法を理解しよう! スライドの目的
3.
復習 ~音声の生成過程~ 3
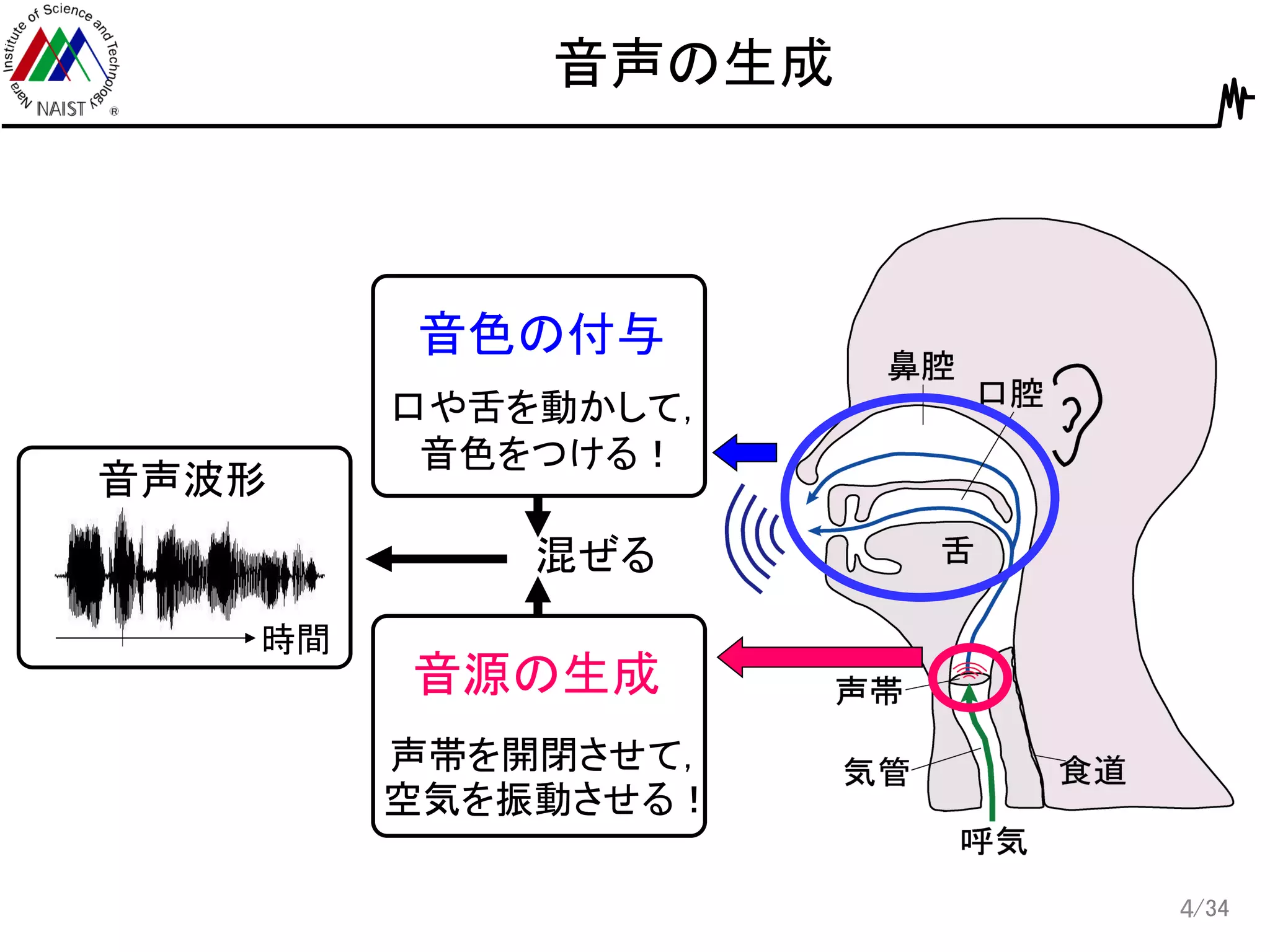
4.
/34 音声の生成 4 音色の付与 口や舌を動かして, 音色をつける! 声帯を開閉させて, 空気を振動させる! 音源の生成 音声波形 時間 混ぜる
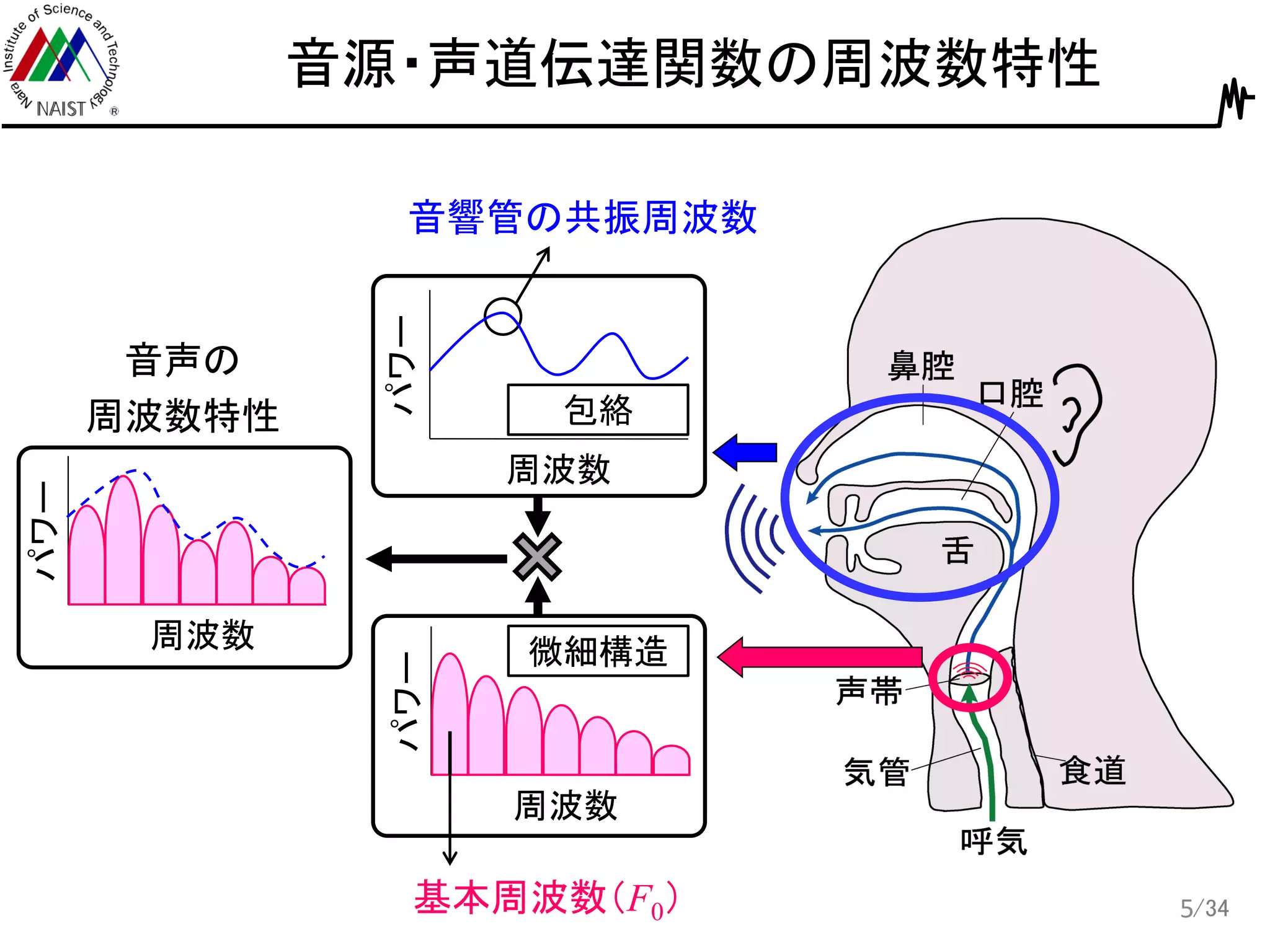
5.
/34 音源・声道伝達関数の周波数特性 5 周波数 パワー 周波数 パワー 基本周波数(F0) 音響管の共振周波数 周波数 パワー 音声の 周波数特性 微細構造 包絡
6.
分析法① ~ケプストラム分析~ 6
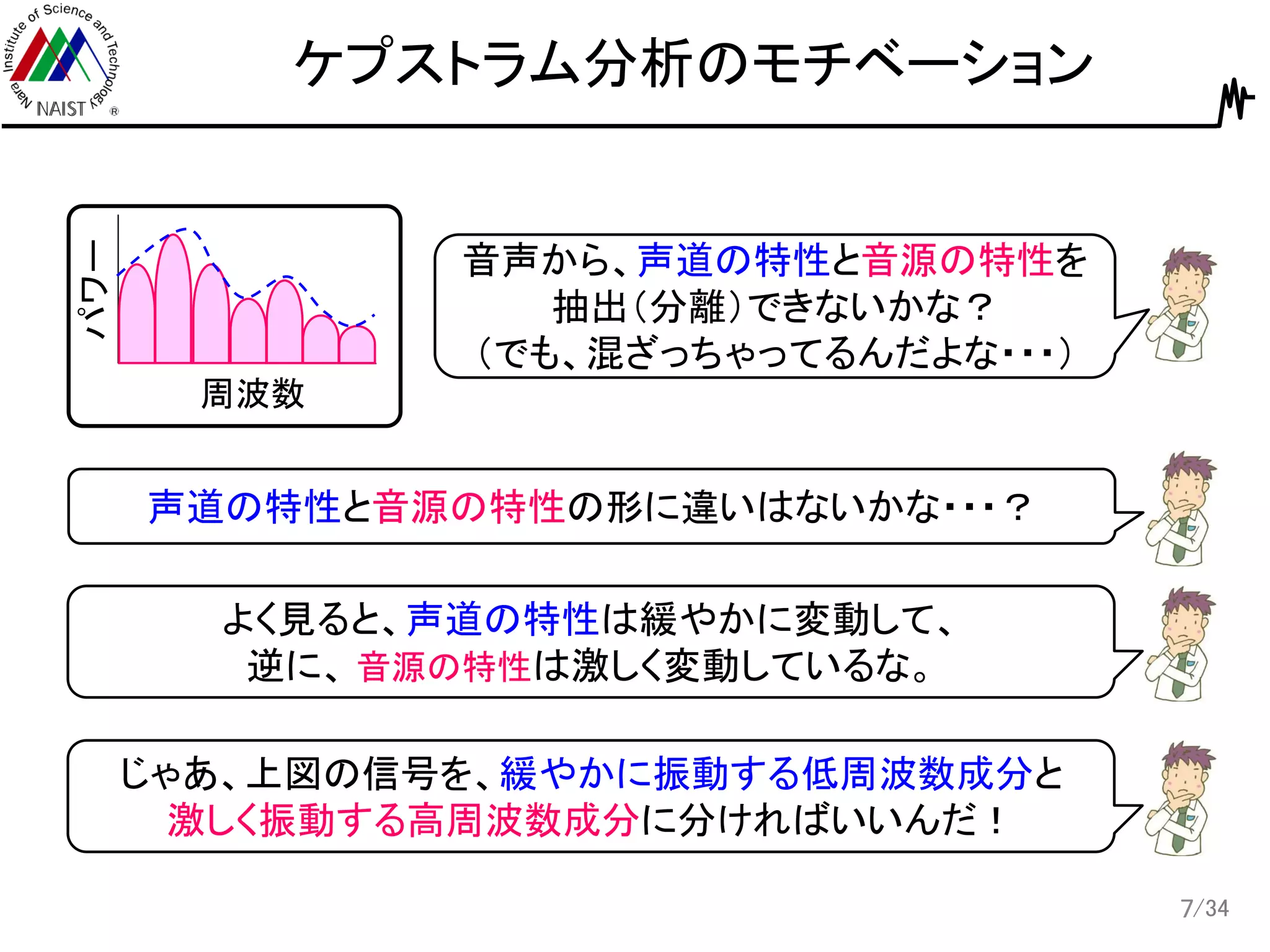
7.
/34 ケプストラム分析のモチベーション 7 周波数 パワー 音声から、声道の特性と音源の特性を 抽出(分離)できないかな? (でも、混ざっちゃってるんだよな・・・) 声道の特性と音源の特性の形に違いはないかな・・・? よく見ると、声道の特性は緩やかに変動して、 逆に、 音源の特性は激しく変動しているな。 じゃあ、上図の信号を、緩やかに振動する低周波数成分と 激しく振動する高周波数成分に分ければいいんだ!
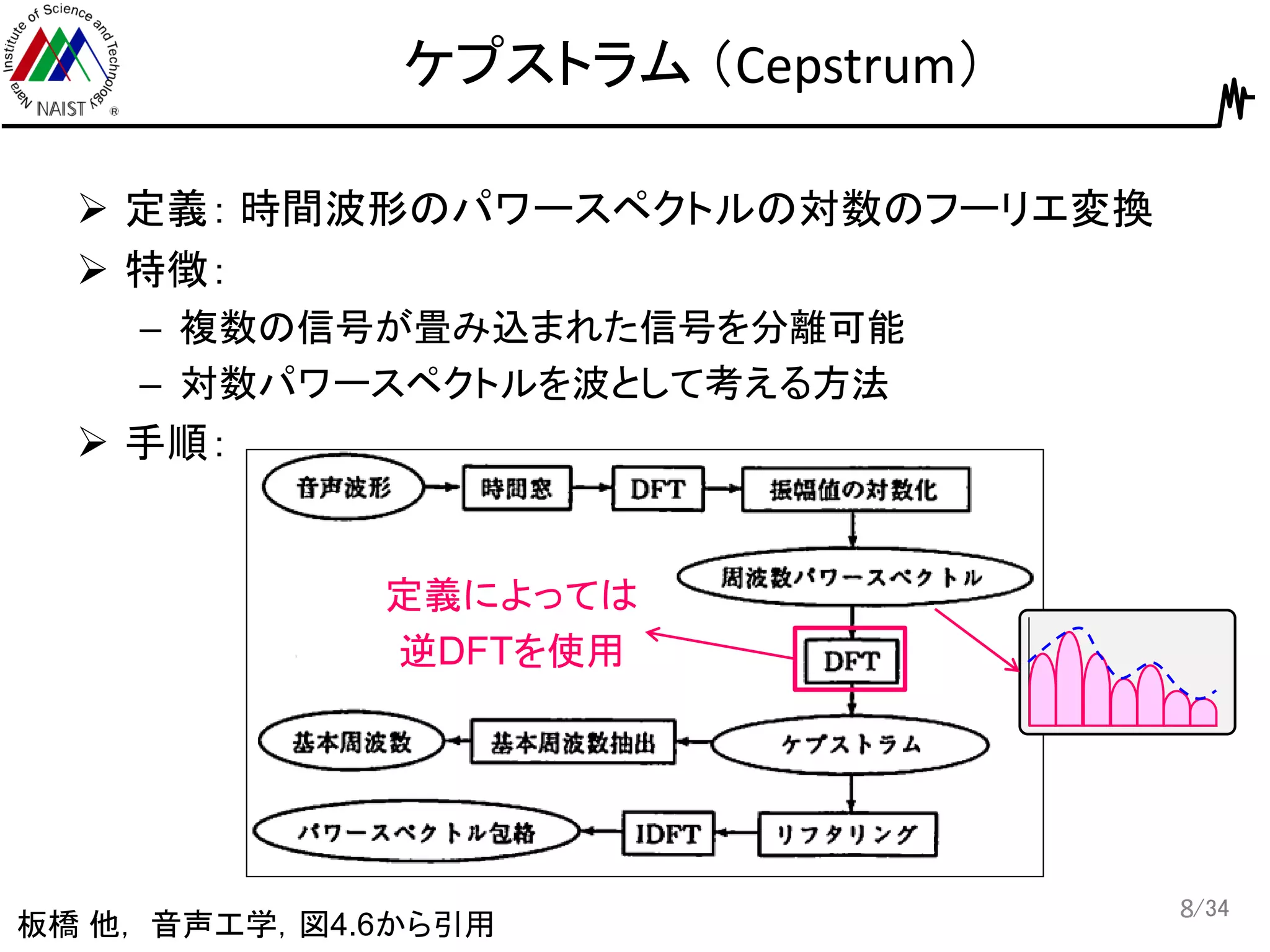
8.
/34 ケプストラム (Cepstrum) 定義:
時間波形のパワースペクトルの対数のフーリエ変換 特徴: – 複数の信号が畳み込まれた信号を分離可能 – 対数パワースペクトルを波として考える方法 手順: 8 定義によっては 逆DFTを使用 板橋 他, 音声工学,図4.6から引用
9.
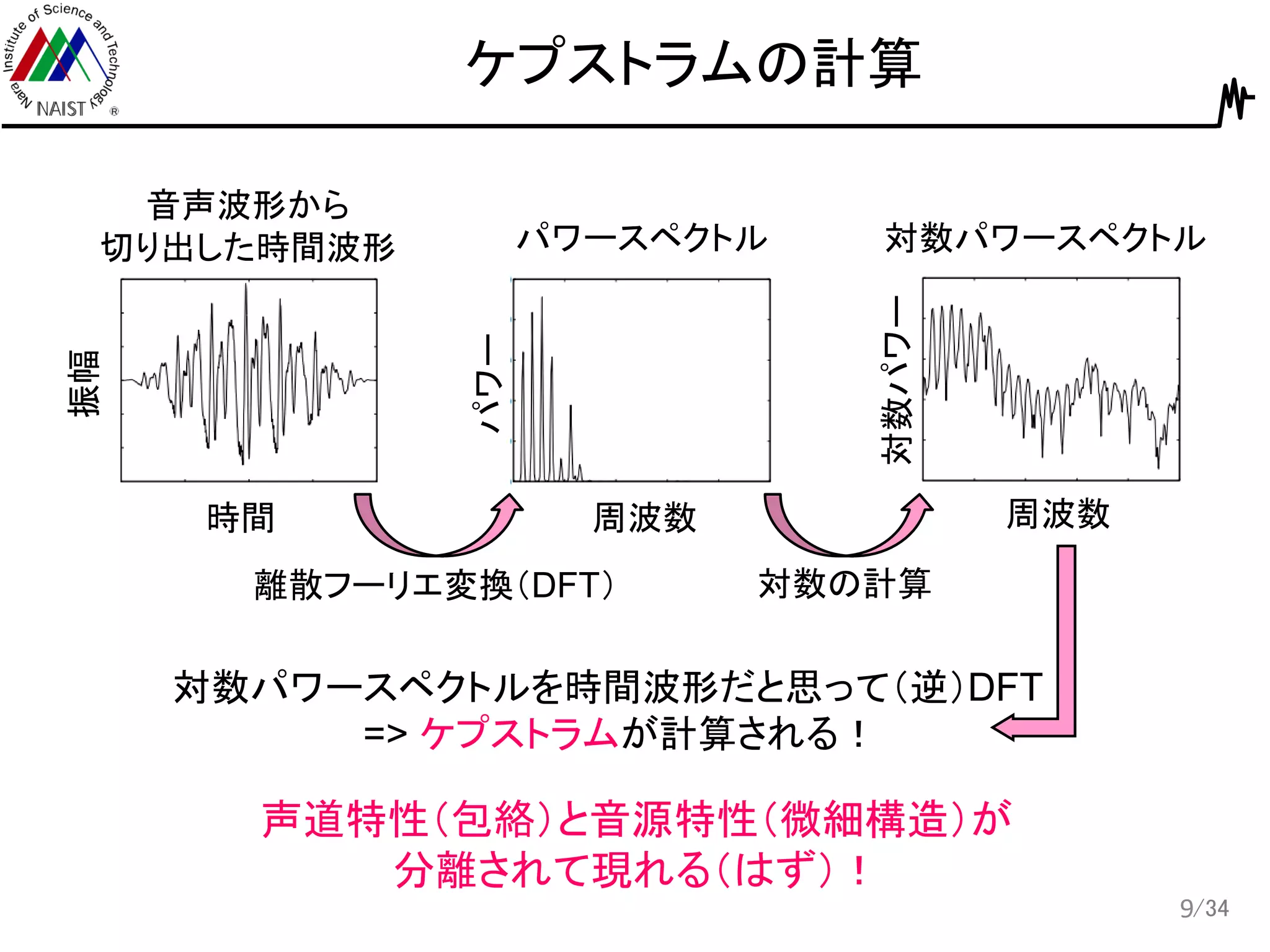
/34 ケプストラムの計算 9 時間 振幅 周波数 パワー 周波数 対数パワー 音声波形から 切り出した時間波形 パワースペクトル 対数パワースペクトル 離散フーリエ変換(DFT)
対数の計算 対数パワースペクトルを時間波形だと思って(逆)DFT => ケプストラムが計算される! 声道特性(包絡)と音源特性(微細構造)が 分離されて現れる(はず)!
10.
/34 ケプストラムの例 10 ケフレンシー ケプストラム 低次のケプストラムは 声道特性(スペクトル包絡)に対応 高次のケプストラムは 音源特性(スペクトル微細構造)に対応 リフタ: ケプストラムに対するフィルタ リフタを掛けることで低次/高次の情報を分離できる!
11.
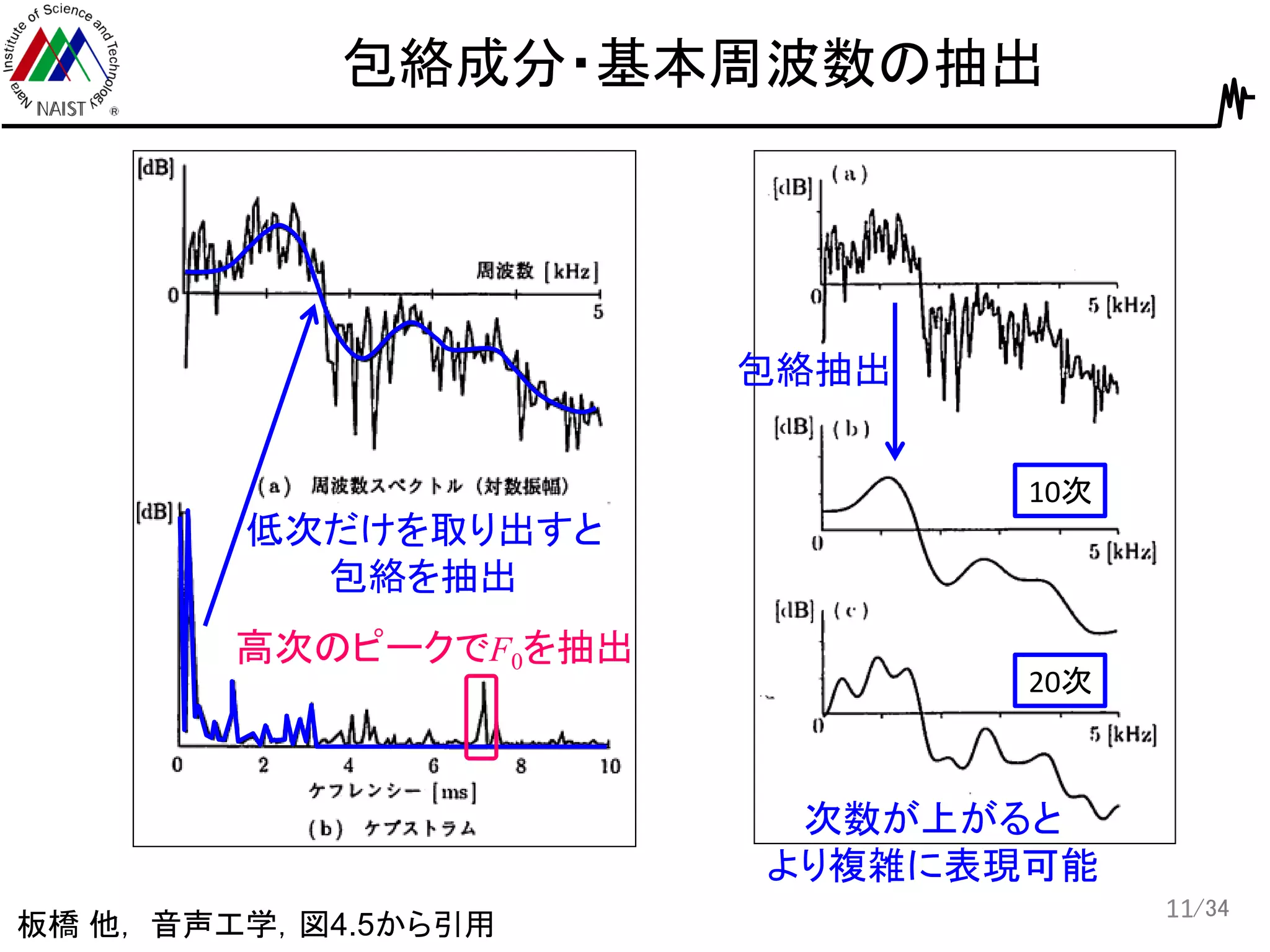
/34 包絡成分・基本周波数の抽出 11 板橋 他, 音声工学,図4.5から引用 低次だけを取り出すと 包絡を抽出 高次のピークでF0を抽出 10次 20次 包絡抽出 次数が上がると より複雑に表現可能
12.
分析法② ~線形予測分析~ 12
13.
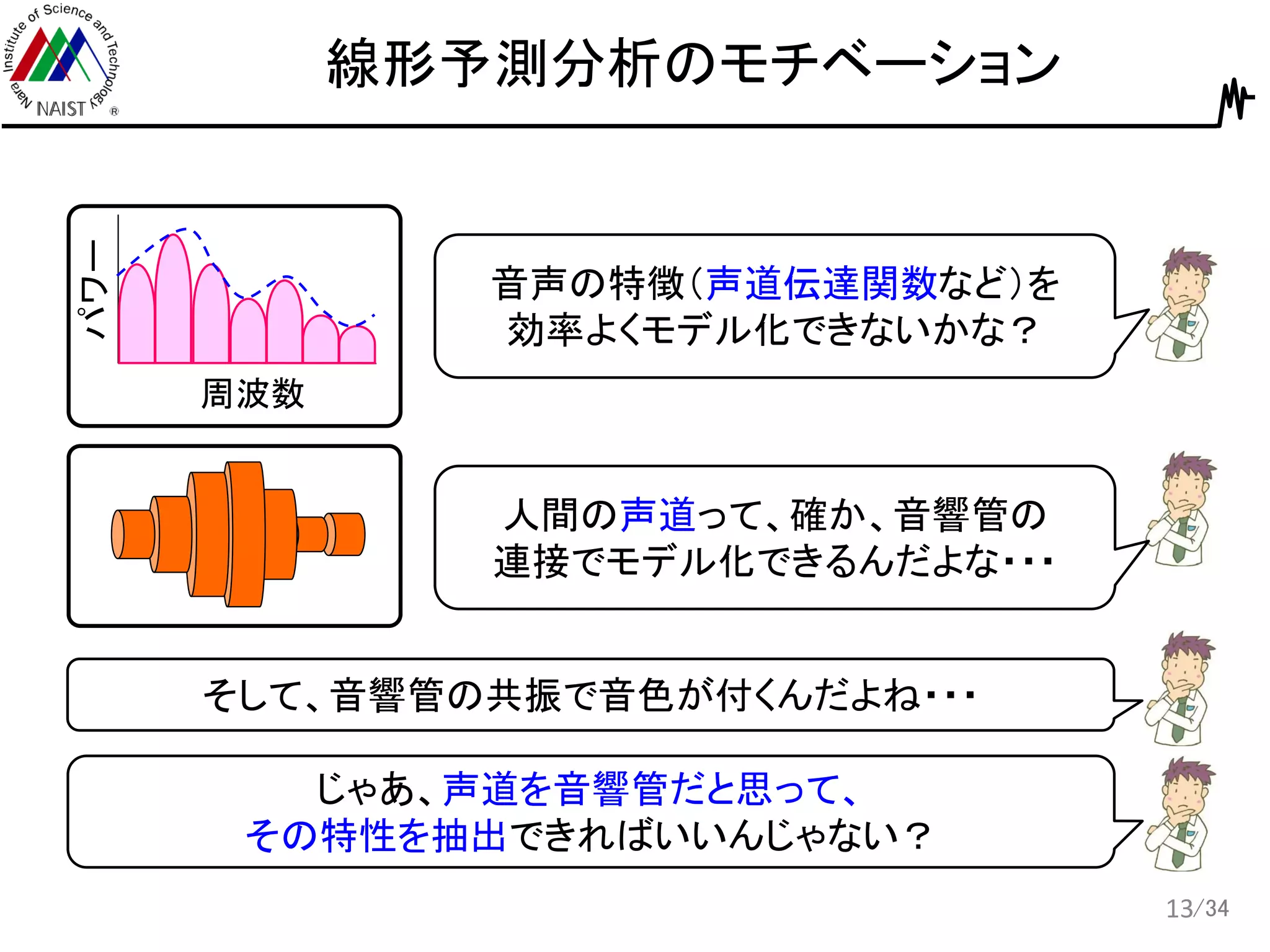
/34 線形予測分析のモチベーション 13 周波数 パワー 音声の特徴(声道伝達関数など)を 効率よくモデル化できないかな? じゃあ、声道を音響管だと思って、 その特性を抽出できればいいんじゃない? 人間の声道って、確か、音響管の 連接でモデル化できるんだよな・・・ そして、音響管の共振で音色が付くんだよね・・・
14.
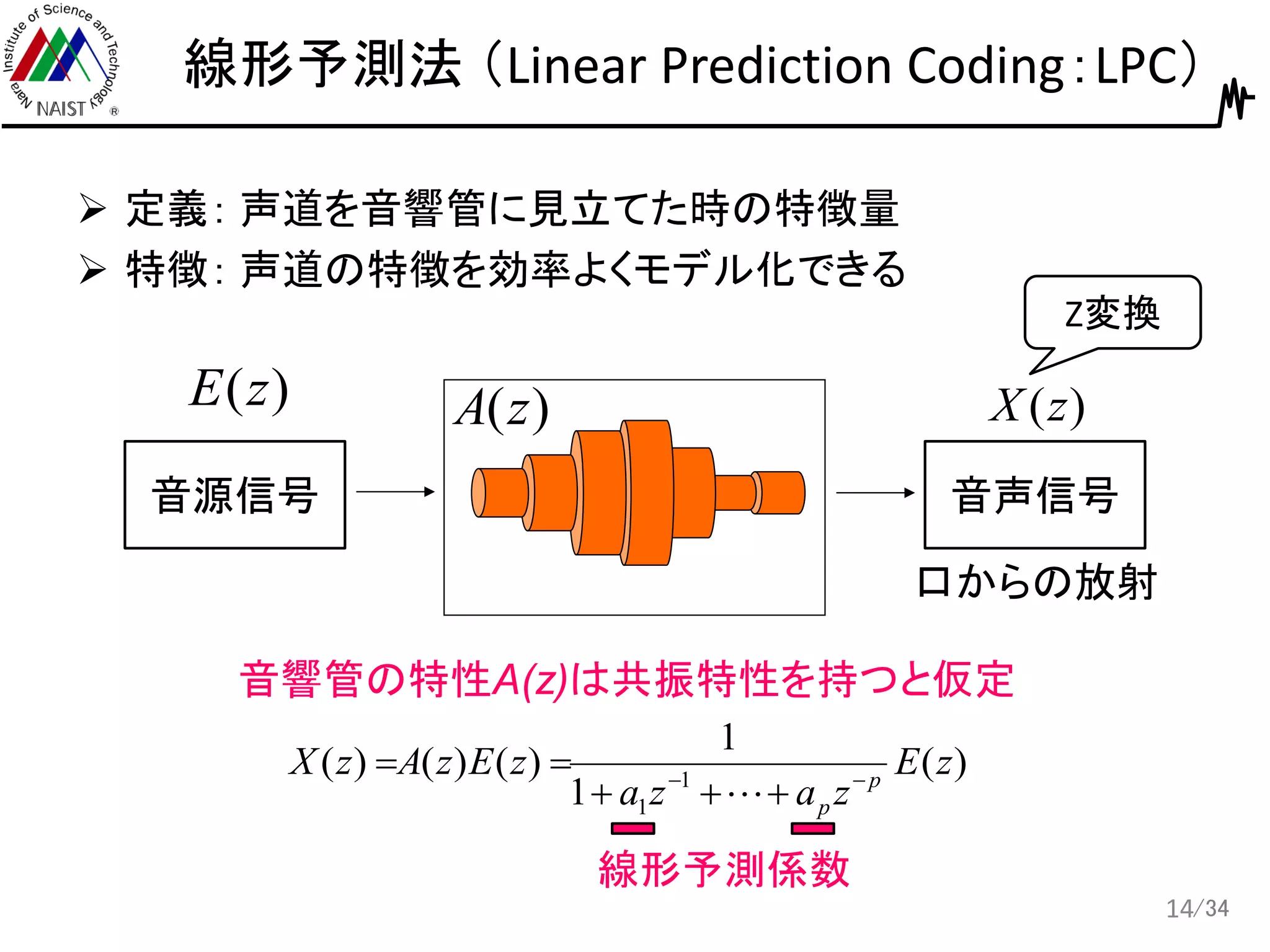
/34 線形予測法 (Linear Prediction
Coding:LPC) 定義: 声道を音響管に見立てた時の特徴量 特徴: 声道の特徴を効率よくモデル化できる 14 口からの放射 )(zE )(zA )(zX 音源信号 音声信号 Z変換 音響管の特性A(z)は共振特性を持つと仮定 )( 1 1 )()()( 1 1 zE zaza zEzAzX p p 線形予測係数
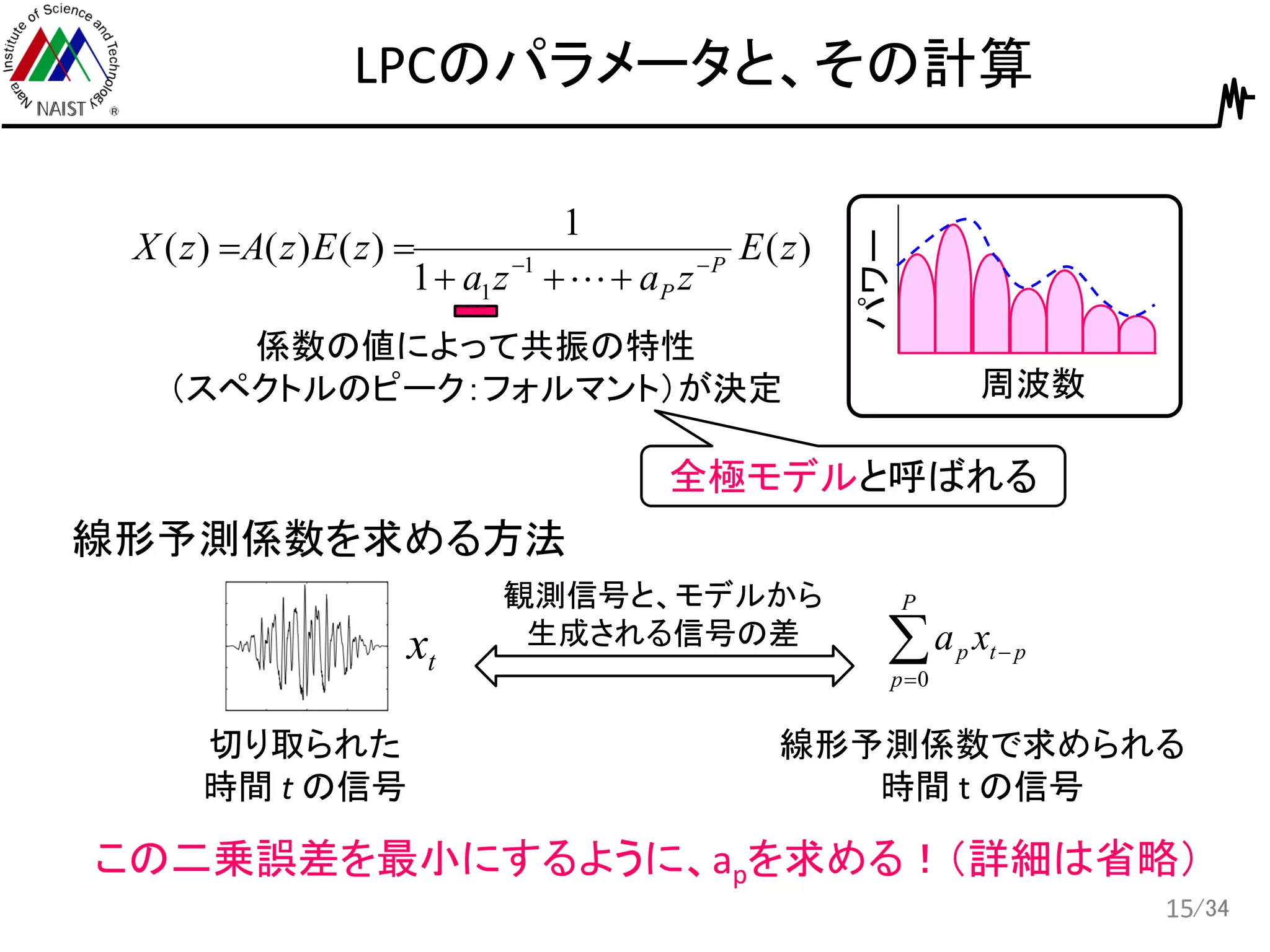
15.
/34 LPCのパラメータと、その計算 15 周波数 パワー )( 1 1 )()()( 1 1 zE zaza zEzAzX P P 係数の値によって共振の特性 (スペクトルのピーク:フォルマント)が決定 全極モデルと呼ばれる 線形予測係数を求める方法 tx 切り取られた 時間
t の信号 P p ptp xa 0 線形予測係数で求められる 時間 t の信号 この二乗誤差を最小にするように、apを求める!(詳細は省略) 観測信号と、モデルから 生成される信号の差
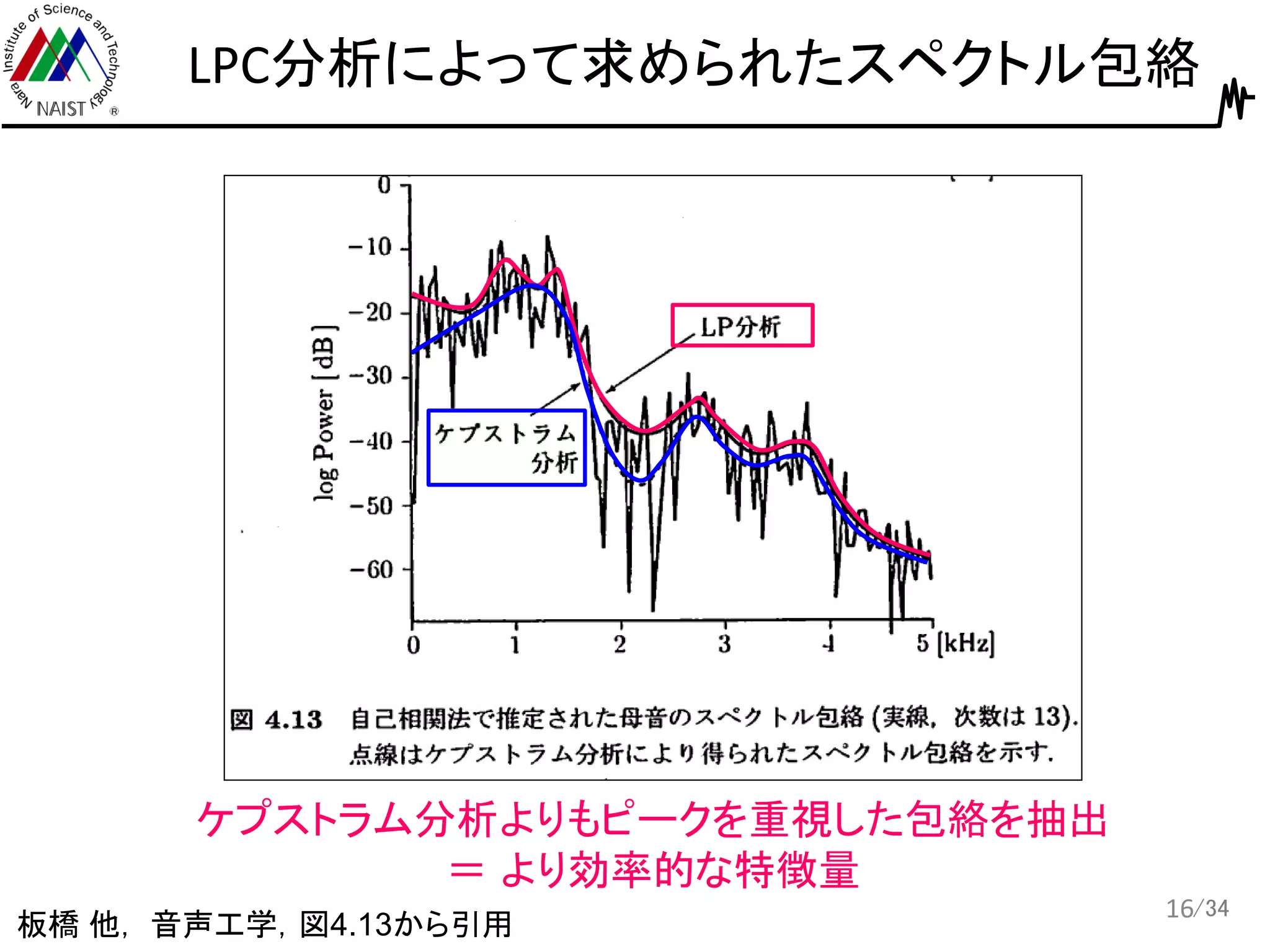
16.
/34 LPC分析によって求められたスペクトル包絡 16 ケプストラム分析よりもピークを重視した包絡を抽出 = より効率的な特徴量 板橋 他,
音声工学,図4.13から引用
17.
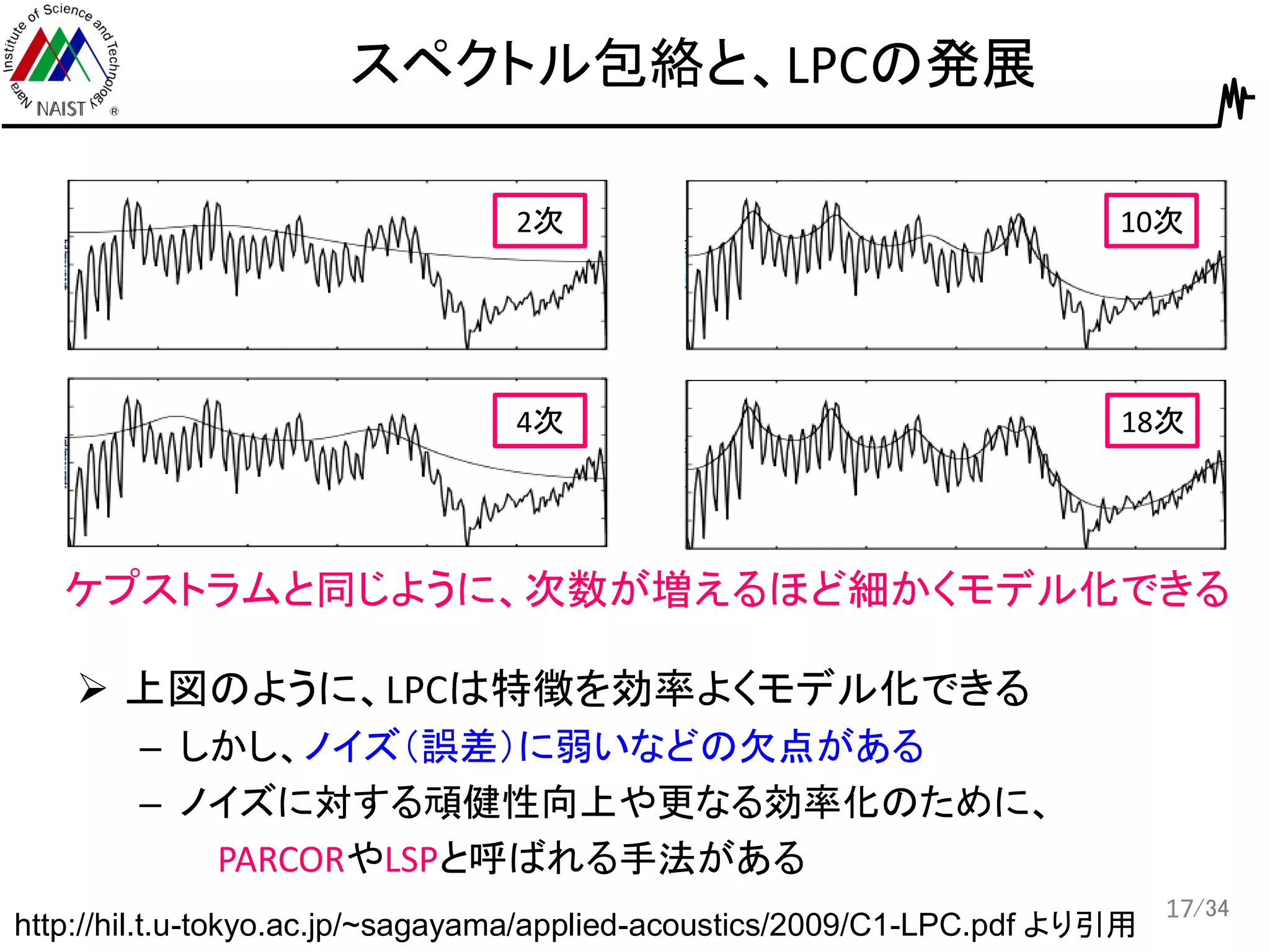
/34 スペクトル包絡と、LPCの発展 17 http://hil.t.u-tokyo.ac.jp/~sagayama/applied-acoustics/2009/C1-LPC.pdf より引用 2次 4次 10次 18次 ケプストラムと同じように、次数が増えるほど細かくモデル化できる 上図のように、LPCは特徴を効率よくモデル化できる –
しかし、ノイズ(誤差)に弱いなどの欠点がある – ノイズに対する頑健性向上や更なる効率化のために、 PARCORやLSPと呼ばれる手法がある
Download














![SSII2021 [OS2-01] 転移学習の基礎:異なるタスクの知識を利用するための機械学習の方法](https://cdn.slidesharecdn.com/ss_thumbnails/os2-02final-210610091211-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2022 [TS1] Transformerの最前線〜 畳込みニューラルネットワークの先へ 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts120220608ssiitransformerr2-220607054025-3adacf07-thumbnail.jpg?width=640&height=640&fit=bounds)





































