More Related Content

PDF
Neural text-to-speech and voice conversion 
PDF
![[DL輪読会]Wav2CLIP: Learning Robust Audio Representations From CLIP](https://cdn.slidesharecdn.com/ss_thumbnails/dlwav2clip1-211105022837-thumbnail.jpg?width=640&height=640&fit=bounds)
PPTX
[DL輪読会]Wav2CLIP: Learning Robust Audio Representations From CLIP 
PDF

PDF

PDF
ここまで来た&これから来る音声合成 (明治大学 先端メディアコロキウム) 
PPTX
【DL輪読会】Efficiently Modeling Long Sequences with Structured State Spaces 
PDF
What's hot

PDF

PDF

PDF

PDF

PDF
continual learning survey 
PDF

PDF

PDF

PPTX
調波打撃音分離の時間周波数マスクを用いた線形ブラインド音源分離 
PDF
GAN-based statistical speech synthesis (in Japanese) 
PDF
z変換をやさしく教えて下さい (音響学入門ペディア) ![SSII2022 [SS2] 少ないデータやラベルを効率的に活用する機械学習技術 〜 足りない情報をどのように補うか?〜](https://cdn.slidesharecdn.com/ss_thumbnails/ss2ssii2022-220607054716-2760bd30-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
SSII2022 [SS2] 少ないデータやラベルを効率的に活用する機械学習技術 〜 足りない情報をどのように補うか?〜 
PPTX
Curriculum Learning (関東CV勉強会) ![[DL輪読会]Discriminative Learning for Monaural Speech Separation Using Deep Embe...](https://cdn.slidesharecdn.com/ss_thumbnails/201912227dldiscriminativeleraningformanaouraspeechseparationusingdeepembeddingfeaturessumissionver2-191227001259-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
[DL輪読会]Discriminative Learning for Monaural Speech Separation Using Deep Embe... 
PDF
環境音の特徴を活用した音響イベント検出・シーン分類 
PPTX
音響メディア信号処理における独立成分分析の発展と応用, History of independent component analysis for sou... 
PPTX
半教師あり非負値行列因子分解における音源分離性能向上のための効果的な基底学習法 ![[DL輪読会]Diffusion-based Voice Conversion with Fast Maximum Likelihood Samplin...](https://cdn.slidesharecdn.com/ss_thumbnails/20220318akuzawa-220322065615-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
[DL輪読会]Diffusion-based Voice Conversion with Fast Maximum Likelihood Samplin... 
PDF
Moment matching networkを用いた音声パラメータのランダム生成の検討 
PDF
Similar to 統計的音声合成変換と近年の発展

PDF

PDF
テキスト音声合成技術と多様性への挑戦 (名古屋大学 知能システム特論) 
PDF
ICASSP2019 音声&音響読み会 テーマ発表音声生成 
PDF
音声合成・変換の国際コンペティションへの 参加を振り返って 
PDF
GMMに基づく固有声変換のための変調スペクトル制約付きトラジェクトリ学習・適応 
PDF

PPTX
外国人留学生日本語の音声合成における�話者性を保持した韻律補正 
PDF
深層学習に基づくテキスト音声合成の技術動向_言語音声ナイト 
PDF
フィラーを含む自発音声合成モデルの品質低下原因の調査と一貫性保証による改善 
ODP

PDF
雑音環境下音声を用いた音声合成のための雑音生成モデルの敵対的学習 
PDF

PDF

PDF

PDF

PDF
音学シンポジウム2025「音声研究の知見がニューラルボコーダの発展にもたらす効果」 
PPTX

PDF
分布あるいはモーメント間距離最小化に基づく統計的音声合成 
PDF
差分スペクトル法に基づくDNN声質変換のためのリフタ学習およびサブバンド処理 
PDF
More from Shinnosuke Takamichi

PDF
JTubeSpeech: 音声認識と話者照合のために YouTube から構築される日本語音声コーパス 
PDF
J-KAC:日本語オーディオブック・紙芝居朗読音声コーパス 
PDF
短時間発話を用いた話者照合のための音声加工の効果に関する検討 
PDF
リアルタイムDNN音声変換フィードバックによるキャラクタ性の獲得手法 
PDF
Interspeech 2020 読み会 "Incremental Text to Speech for Neural Sequence-to-Sequ... 
PDF
サブバンドフィルタリングに基づくリアルタイム広帯域DNN声質変換の実装と評価 
PDF
P J S: 音素バランスを考慮した日本語歌声コーパス 
PDF
音響モデル尤度に基づくsubword分割の韻律推定精度における評価 
PDF
論文紹介 Unsupervised training of neural mask-based beamforming 
PDF
論文紹介 Building the Singapore English National Speech Corpus 
PDF
論文紹介 SANTLR: Speech Annotation Toolkit for Low Resource Languages 
PDF
話者V2S攻撃: 話者認証から構築される 声質変換とその音声なりすまし可能性の評価 
PDF

PDF
差分スペクトル法に基づく DNN 声質変換の計算量削減に向けたフィルタ推定 
PDF
ユーザ歌唱のための generative moment matching network に基づく neural double-tracking 
PDF
End-to-end 韻律推定に向けた DNN 音響モデルに基づく subword 分割 
PPTX
多様なカートシスを持つ雑音に対応した低ミュージカルノイズ DNN 音声強調 
PPTX
End-to-end 韻律推定に向けた subword lattice 構造を考慮した DNN 音響モデル学習 
PPTX
Generative moment matching net に基づく歌声のランダム変調ポストフィルタと double-tracking への応用 
PDF
SLP研究会201902 正弦関数摂動 von Mises 分布 DNN の モード近似を用いた位相復元 統計的音声合成変換と近年の発展
- 1.
- 2.
/46
自己紹介
名前
– 高道慎之介 (たかみち しんのすけ)
経歴
– 2009年 熊本電波高専 電子工学科 卒業 … 半導体など
– 2011年 長岡技科大 工学部 卒業 … 立体音響など
– 2016年 奈良先端大 博士課程 修了 … 音声合成など
– 2016年~ 東京大学 猿渡・小山研 助教 (2018年まで特任助教)
専門
– 統計的音声合成・変換など
2
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
/46
深層生成モデル:
Generative Adversarial Network(GAN)
Generative adversarial network
– 分布間の近似 Jensen-Shannon divergence を最小化
– 生成モデルと,学習/生成データを識別する識別モデルを敵対
– 音声合成に適用されだしたのは2016年 (我々のグループ)
13
𝒚
1: natural
0: synthesized
Discriminator
Natural
[Goodfellow14]
Generator
Input
- 14.
- 15.
- 16.
- 17.
- 18.
/46
人文学 & 工学研究のための
オープンな日本語音声コーパス
18
大学研究所企業・非研究者
人文学系
工学系
人文学系
工学系工学系
ここは有ったここが無かった
人文学研究のための音声コーパスは豊富
– 国語研を中心に整備 [IEICE会誌 vol.102, no.6 の小特集を参照]
工学研究 (特に音声合成の研究) のための音声コーパスは?
– 2015年頃から,専門知識不要の音声合成方式が加速
– 音声合成のコモディティ化が進み,研究分野・身分・国を超えた
技術・製品開発が加速すると予想
→ 2016年時点で,それに適切な日本語音声コーパスが無かった
- 19.
/46
JSUTコーパス
19
[Sonobe17]
スペック
– 単一話者読み上げ音声,10時間(約7,600発話),48 kHzサンプリング
– 日本語常用漢字の音読み・訓読みを全てカバー
• Wikipedia やクラウドソーシング作文を利用
• 日本語end-to-end音声合成をサポートするため
– 身分などに依らず非商用なら無償利用可 (商用転換も可能)
成果
– 2017/10に公開して60か国以上からダウンロード (約75%は国内)
– End-to-end 音声合成でも使用されるように [Ueno18]
– 商用利用への転換の実績も有り
日本語End-to-end音声合成のサンプル音声は,京都大学 河原先生・上乃さまに提供して頂いた
- 20.
- 21.
- 22.
- 23.
/46
話者埋め込み (speaker embedding)
話者埋め込み … 発話者を何らかの数値で表現すること
– 声色制御への応用 … ユーザの所望する声色で話す音声合成
– 言語横断への応用 … 言語を超えて同じ人の声で話す音声合成
従来法 … 客観値(音声特徴量間の距離)に基づく embedding
– 識別器 (d-vector) や auto-encoder の中間層の値で潜在空間を張る
– 話者性は「客観的に似ている = 主観的に似ている」ではない
– 張られた潜在空間は,人間の知覚と対応しておらず,解釈しにくい
23
1
0
0
0
0
⋯
Speaker
codes
Speech
params.
⋯
Softmax
cross-entropy
𝐿SCE 𝒄, 𝒄
𝑑-vector
𝒄 𝒄
- 24.
- 25.
- 26.
- 27.
/4627
話者埋め込みと話者間類似度スコアの
散布図・相関
(1) Conv. (2)Prop. (vec) (3) Prop. (mat) (4) Prop. (mat-re)
0.0 1.0−1.0
1.0
0.0
−1.0
Value of kernel 𝑘 𝒅𝑖, 𝒅𝑗
Similarityscore𝑠𝑖,𝑗
(a)Closed-Closed(b)Closed-Open
提案法により, 主観的類似度と高い相関を持つ話者埋め込みが学習可能
[Saito19]
- 28.
- 29.
/46
外国語スピーキング学習への挑戦
外国語学習の目的
– 対象の外国語(例:英語) を用いた円滑な音声コミュニケーション
スピーキング学習では何を目標にすべきか?
– 母語話者 (例:英語話者) を目指すべき? → No.
– 外国語話者はある程度の発音逸脱を許容しているため,その許容
範囲に収まる発音であれば,訛った外国語でもOKなのでは?
ノンネイティブ音声合成
– 学習者の訛りを生かしつつ,外国語話者に伝わる音声を生成
29
- 30.
- 31.
- 32.
- 33.
- 34.
- 35.
/46
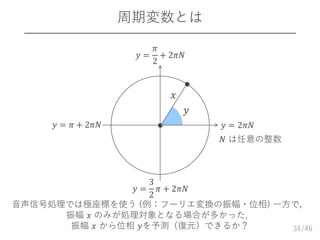
DNNを用いた位相推定
位相:2𝜋の周期をもつ周期変数
– 2𝜋の周期性を持つ周期変数𝒚 𝑡 = 𝑦𝑡,0, ⋯ , 𝑦𝑡,𝑓, ⋯ , 𝑦𝑡,𝐹
⊤
– 𝑦𝑡,𝑓 と 𝑦𝑡,𝑓 + 2𝜋𝑁 は等価(𝑁は整数)
DNN学習に通常の二乗誤差最小化規範 (MSE) を使えない
– 二乗誤差最小化規範は等方性ガウス分布の尤度最大化に対応
– ガウス分布は変数の周期性に対応できない
35
argmax 𝑁 𝒚 𝑡; 𝒚 𝑡, 𝜎2
𝑰 → argmin 𝒚 𝑡 − 𝒚 𝑡
⊤
𝒚 𝑡 − 𝒚 𝑡
DNN
MSE
𝒚 𝑡
ならば,周期変数に対応する確率分布を導入すれば良い!
振幅 𝒙 𝑡 位相 𝒚 𝑡
- 36.
/46
von Mises 分布
von Mises 分布 … 周期変数のための確率分布
– 2次元の等方性ガウス分布から導出される対称周期分布
36
[Mardia99]
𝑃(vm) 𝑦; 𝜇, 𝜅 =
exp 𝜅 cos 𝑦 − 𝜇
2𝜋𝐼0 𝜅
𝑦
𝜋 2𝜋
𝜇
𝜅
0
𝑃(vm)𝑦;𝜇,𝜅
- 37.
/46
von Mises 分布DNN を用いた
位相モデリング
37
von Mises 分布 DNN … 周期変数のための深層生成モデル
– 集中度パラメータ固定の von Mises 分布を条件付き確率分布に持つ
von Mises 分布 DNN は,データ分布の対称性を暗に仮定
– ↓のような分布のモデル化精度は悪い.どうする?
𝜽 = argmin 𝐿(vm) 𝒚 𝑡, 𝜽 = argmin −cos 𝑦𝑡,𝑓 − 𝜇 𝑡,𝑓
𝑓
DNN 𝜽
振幅 𝒙 𝑡 𝐿 vm ⋅ 位相 𝒚 𝑡
平均 𝝁 𝑡
𝑦
0 𝜋 2𝜋
Count
[Takamichi18]
- 38.
/46
正弦関数摂動 von Mises分布
von Mises 分布𝑃 vm 𝑦, 𝜇, 𝜅 に摂動項をかけた非対称周期分布
38
[Abe11]
𝑃 ssvm 𝑦, 𝜇, 𝜅, 𝜆 = 𝑃 vm 𝑦, 𝜇, 𝜅 ⋅ 1 + 𝜆 sin 𝑦 − 𝜇
𝑦
0 𝜋 2𝜋
𝑃ssvm
𝑦,𝜇,𝜅,𝜆
摂動パラメータ
- 39.
/46
正弦関数摂動 von Mises分布DNNによる
位相推定(正確には群遅延推定)
39
0
1
𝐹
𝑦𝑡,∗
𝐿 vm ⋅
𝜎 ⋅
× 𝛼 𝜅
(const.)
0
𝐹
𝜇 𝑡,∗
𝜅 𝑡,∗
tanh ⋅
× 𝛼 𝜆
(const.)
𝜆 𝑡,∗
𝐿 ss ⋅Mean
Concentration
Skew
Freq. index
𝑥 𝑡,∗
DNN学習時の損失関数は 𝐿 vm ⋅ と 𝐿 ss ⋅ の和
(von Mises由来) (正弦関数摂動由来)
摂動項の
対数
[Takamichi18]
- 40.
- 41.
- 42.
- 43.
- 44.
- 45.
- 46.






![/46
DNN-based real-time voice conversion
6
http://www.ytv.co.jp/conan
/item/tai.html
https://www.youtube.com/watch?v=P9rGqoYnfCg
[Arakawa19]](https://image.slidesharecdn.com/slide-190620124350/85/slide-6-320.jpg)
![/46
Neural double-tracking
7
[Tamaru19]
NDT
Random pitch modulation
based on deep generative models
深層生成モデルを用いて「人間の音声はこう間違う」を学習](https://image.slidesharecdn.com/slide-190620124350/85/slide-7-320.jpg)


![/46
Neural double-tracking
10
[Tamaru19]
NDT
Random pitch modulation
based on deep generative models
これをどうやって実現しているのかを話します!](https://image.slidesharecdn.com/slide-190620124350/85/slide-10-320.jpg)
![/46
一期一会音声合成
11
「正しく喋る」から「正しく間違えて喋る」音声合成へ
Human
Noise
Current TTS
Noise
Our approach
[Takamichi17]](https://image.slidesharecdn.com/slide-190620124350/85/slide-11-320.jpg)

![/46
深層生成モデル:
Generative Adversarial Network (GAN)
Generative adversarial network
– 分布間の近似 Jensen-Shannon divergence を最小化
– 生成モデルと,学習/生成データを識別する識別モデルを敵対
– 音声合成に適用されだしたのは2016年 (我々のグループ)
13
𝒚
1: natural
0: synthesized
Discriminator
Natural
[Goodfellow14]
Generator
Input](https://image.slidesharecdn.com/slide-190620124350/85/slide-13-320.jpg)
![/46
別の生成モデル:
Generative moment-matching network
Generative moment-matching network
– 分布のモーメント (平均,分散,…) 間の二乗距離を最小化
• モーメントは音声処理との相性が良い
– 実装上は,グラム行列のノルムの差を最小化
14
𝒚
Natural
Generator
Input
[Li15]](https://image.slidesharecdn.com/slide-190620124350/85/slide-14-320.jpg)
![/46
Neural double-tracking の手順
1515
波形
合成
スペクトル
有声/無声
F0
スペクトル
有声/無声
F0
条件付きGMMN
(条件:F0包絡)
遅延
人間の
DT歌声から
学習
[Tamaru19]](https://image.slidesharecdn.com/slide-190620124350/85/slide-15-320.jpg)
![/46
変調したF0系列の例
16
う さ
ぎ
う
さ
ぎ
Pitch(1が半音)
Time [s]
Non-filtered
Post-filtered (4 lines)
童謡「うさぎ」の一節
72
71
70
69
68
67
66
65
64
63
62
0.0 0.5 1.0 1.5 2.0 2.5
[Tamaru19]](https://image.slidesharecdn.com/slide-190620124350/85/slide-16-320.jpg)

![/46
人文学 & 工学研究のための
オープンな日本語音声コーパス
18
大学 研究所企業・非研究者
人文学系
工学系
人文学系
工学系工学系
ここは有ったここが無かった
人文学研究のための音声コーパスは豊富
– 国語研を中心に整備 [IEICE会誌 vol.102, no.6 の小特集を参照]
工学研究 (特に音声合成の研究) のための音声コーパスは?
– 2015年頃から,専門知識不要の音声合成方式が加速
– 音声合成のコモディティ化が進み,研究分野・身分・国を超えた
技術・製品開発が加速すると予想
→ 2016年時点で,それに適切な日本語音声コーパスが無かった](https://image.slidesharecdn.com/slide-190620124350/85/slide-18-320.jpg)
![/46
JSUTコーパス
19
[Sonobe17]
スペック
– 単一話者読み上げ音声,10時間 (約7,600発話),48 kHzサンプリング
– 日本語常用漢字の音読み・訓読みを全てカバー
• Wikipedia やクラウドソーシング作文を利用
• 日本語end-to-end音声合成をサポートするため
– 身分などに依らず非商用なら無償利用可 (商用転換も可能)
成果
– 2017/10に公開して60か国以上からダウンロード (約75%は国内)
– End-to-end 音声合成でも使用されるように [Ueno18]
– 商用利用への転換の実績も有り
日本語End-to-end音声合成のサンプル音声は,京都大学 河原先生・上乃さまに提供して頂いた](https://image.slidesharecdn.com/slide-190620124350/85/slide-19-320.jpg)
![/46
JSUT コレクション:テキスト・歌・環境音を
音声でつなげるコーパス
20
JSUT
JSUT-songJSUT-vi
Singing voice (0.5 hrs)Vocal imitation (0.4 hrs)
Reading-style speech (10 hrs)
Single Japanese speaker’s voice
[new!] JSUT-book
Audiobook
[Future release]
[Takamichi18]
音声による抽象化・具体化を利用した多元的情報の融合へ](https://image.slidesharecdn.com/slide-190620124350/85/slide-20-320.jpg)



![/4624
クラウドソーシングを用いた
話者間類似度の大規模主観スコアリング
話者対の音声を提示し, その主観的な類似度を評価
– JNAS [Itou et al., 1999] の女性話者153名を利用
• 話者毎に異なる発話 (テキスト非依存の話者間類似度を評価)
– 4,060名のワーカーが, 全話者対からランダム抽出された34対を評価
• 評価スコア: -3 (似ていない) ~ +3 (似ている) の整数
• 1つの話者対を異なる10名以上が評価
提示話者対サンプル
[Saito19]](https://image.slidesharecdn.com/slide-190620124350/85/slide-24-320.jpg)
![/4625
類似度スコアに基づく話者グラフを用いた
話者間類似度の可視化
話者の配置は類似度スコアを用いた多次元尺度構成法で決定
F051
F146B
F048
特定の話者に
類似した話者
多数の話者に
類似した話者F093
F127
[Saito19]](https://image.slidesharecdn.com/slide-190620124350/85/slide-25-320.jpg)
![/46
DNNを用いた話者埋め込みへの応用
26
Spk.
1
𝒅1
Spk.
𝑁s
𝒅 𝑁𝐬
⋯
𝐃⊤ 𝐃
⋯
Gram matrix
𝐊 𝐃
Calc.
kernel
𝑘 ⋅
𝐿SIM
mat
⋅
𝑁s
𝑁s
1
1
⋯
⋯
𝑁s1
⋯1
𝑁s
𝑘 𝒅1, 𝒅 𝑵s
𝑠1,𝑁s𝐒
Sim. score
matrix
𝐿SIM
(mat)
𝐃, 𝐒 = 𝐊 𝐃 − 𝐒 𝐹
2
音声特徴量 (客観値) から話者類似度 (主観値) へのマッピング
– DNNを用いた行列ノルム最小化で実現
– 話者性のユニークさも表現可能
[Saito19]](https://image.slidesharecdn.com/slide-190620124350/85/slide-26-320.jpg)
![/4627
話者埋め込みと話者間類似度スコアの
散布図・相関
(1) Conv. (2) Prop. (vec) (3) Prop. (mat) (4) Prop. (mat-re)
0.0 1.0−1.0
1.0
0.0
−1.0
Value of kernel 𝑘 𝒅𝑖, 𝒅𝑗
Similarityscore𝑠𝑖,𝑗
(a)Closed-Closed(b)Closed-Open
提案法により, 主観的類似度と高い相関を持つ話者埋め込みが学習可能
[Saito19]](https://image.slidesharecdn.com/slide-190620124350/85/slide-27-320.jpg)


![/46
日本人英語音声合成
30
従来法で生成
提案法で生成
学習に使用した音声 (ERJデータベースに含まれる
男子大学生のうち,評定スコアが最低)
“I can see that knife now.”
[Oshima16]](https://image.slidesharecdn.com/slide-190620124350/85/slide-30-320.jpg)
![/46
日本人英語の音声合成のための韻律補正
韻律の違い
– 日本語:モーラ等時性・ピッチアクセント
– 英語:ストレス等時性・ストレスアクセント
韻律補正法
– 英語母語話者の韻律を利用
– 同じ枠組みは別言語でも可能
31
[Oshima16]
英語母語話者の
音響モデル
英語母語話者の
英語音声
日本語母語話者の
英語音声
韻律を補正した
日本語母語話者の
音響モデル
スペクトル
音源
パワー
継続長
スペクトル
音源
パワー
継続長
モデル
適応
パワーと継続長を
補正すればよい!](https://image.slidesharecdn.com/slide-190620124350/85/slide-31-320.jpg)
![/46
中国人日本語の音声合成のための韻律補正
32
Conventional
Ours
Chinese-accented Japanese
uttered by a Chinese student
“私のテストの成績の悪さに,
母がカンカンに怒っています”
Text Text-to-speech
Voice building
Make the voice fluent.
[Sekizawa19]](https://image.slidesharecdn.com/slide-190620124350/85/slide-32-320.jpg)


![/46
von Mises 分布
von Mises 分布 … 周期変数のための確率分布
– 2次元の等方性ガウス分布から導出される対称周期分布
36
[Mardia99]
𝑃(vm) 𝑦; 𝜇, 𝜅 =
exp 𝜅 cos 𝑦 − 𝜇
2𝜋𝐼0 𝜅
𝑦
𝜋 2𝜋
𝜇
𝜅
0
𝑃(vm)𝑦;𝜇,𝜅](https://image.slidesharecdn.com/slide-190620124350/85/slide-36-320.jpg)
![/46
von Mises 分布 DNN を用いた
位相モデリング
37
von Mises 分布 DNN … 周期変数のための深層生成モデル
– 集中度パラメータ固定の von Mises 分布を条件付き確率分布に持つ
von Mises 分布 DNN は,データ分布の対称性を暗に仮定
– ↓のような分布のモデル化精度は悪い.どうする?
𝜽 = argmin 𝐿(vm) 𝒚 𝑡, 𝜽 = argmin −cos 𝑦𝑡,𝑓 − 𝜇 𝑡,𝑓
𝑓
DNN 𝜽
振幅 𝒙 𝑡 𝐿 vm ⋅ 位相 𝒚 𝑡
平均 𝝁 𝑡
𝑦
0 𝜋 2𝜋
Count
[Takamichi18]](https://image.slidesharecdn.com/slide-190620124350/85/slide-37-320.jpg)
![/46
正弦関数摂動 von Mises 分布
von Mises 分布𝑃 vm 𝑦, 𝜇, 𝜅 に摂動項をかけた非対称周期分布
38
[Abe11]
𝑃 ssvm 𝑦, 𝜇, 𝜅, 𝜆 = 𝑃 vm 𝑦, 𝜇, 𝜅 ⋅ 1 + 𝜆 sin 𝑦 − 𝜇
𝑦
0 𝜋 2𝜋
𝑃ssvm
𝑦,𝜇,𝜅,𝜆
摂動パラメータ](https://image.slidesharecdn.com/slide-190620124350/85/slide-38-320.jpg)
![/46
正弦関数摂動 von Mises分布DNNによる
位相推定 (正確には群遅延推定)
39
0
1
𝐹
𝑦𝑡,∗
𝐿 vm ⋅
𝜎 ⋅
× 𝛼 𝜅
(const.)
0
𝐹
𝜇 𝑡,∗
𝜅 𝑡,∗
tanh ⋅
× 𝛼 𝜆
(const.)
𝜆 𝑡,∗
𝐿 ss ⋅Mean
Concentration
Skew
Freq. index
𝑥 𝑡,∗
DNN学習時の損失関数は 𝐿 vm ⋅ と 𝐿 ss ⋅ の和
(von Mises由来) (正弦関数摂動由来)
摂動項の
対数
[Takamichi18]](https://image.slidesharecdn.com/slide-190620124350/85/slide-39-320.jpg)
![/46
負の対数尤度の box plot
40
0.80
0.85
0.90
0.95
1.00
1.05
1.10
Negativeloglikelihood
Min
Max
Median
正弦関数摂動の導入により尤度が改善
[Takamichi18]](https://image.slidesharecdn.com/slide-190620124350/85/slide-40-320.jpg)





