宇根 他,"雑音環境下音声を用いたDNN音声合成のための雑音生成モデルの敵対的学習," 日本音響学会2018年春季研究発表会, 2018. paper: https://sites.google.com/site/shinnosuketakamichi/publication

![• DNNに基づく音声合成 [Zen, 2013]
学習には理想的な環境で収録した音声データが必要
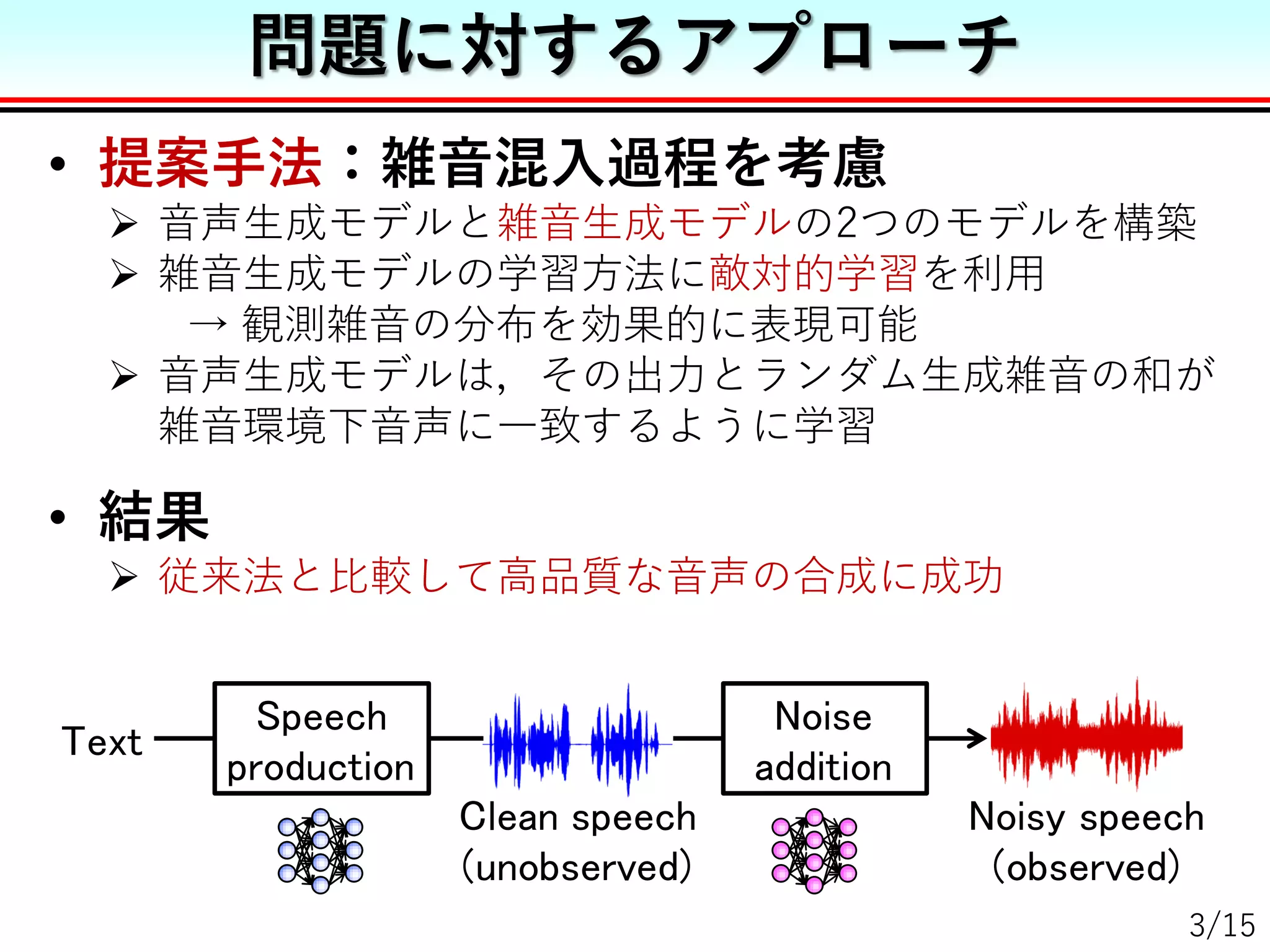
雑音混入音声を学習に利用 → 合成音声も劣化
• 従来手法:雑音抑圧を適用
雑音抑圧を行った音声をモデルの学習に使用
雑音抑圧による推定誤差が音声合成部で重畳
研究背景
2/15
雑音混入音声からクリーンな音声を合成したい!](https://image.slidesharecdn.com/une18asjsnoiseslide-180303165026/75/2018-DNN-2-2048.jpg)

![• 雑音分布を期待値で近似 → 推定誤差の発生
音声成分の歪み
→ クリーン音声の分布の歪み
ミュージカルノイズの発生 [Miyazaki, 2012]
→ 雑音の分布の歪み
SS後の音声合成における問題点
5/15
後段の音声合成モデルの学習に推定誤差が蓄積](https://image.slidesharecdn.com/une18asjsnoiseslide-180303165026/75/2018-DNN-5-2048.jpg)


![• 雑音生成に敵対的学習 (GAN) の導入
雑音の分布を表現可能
観測雑音は観測信号の非音声区間から抽出
雑音生成モデルの学習方法
8/15
:生成雑音 と観測雑音 を識別する.
[Goodfellow et al., 2014]](https://image.slidesharecdn.com/une18asjsnoiseslide-180303165026/75/2018-DNN-8-2048.jpg)
![• 雑音生成に敵対的学習 (GAN) の導入
雑音の分布を表現可能
観測雑音は観測信号の非音声区間から抽出
雑音生成モデルの学習方法
9/15
:生成雑音 を観測雑音と識別させる.
[Goodfellow et al., 2014]](https://image.slidesharecdn.com/une18asjsnoiseslide-180303165026/75/2018-DNN-9-2048.jpg)

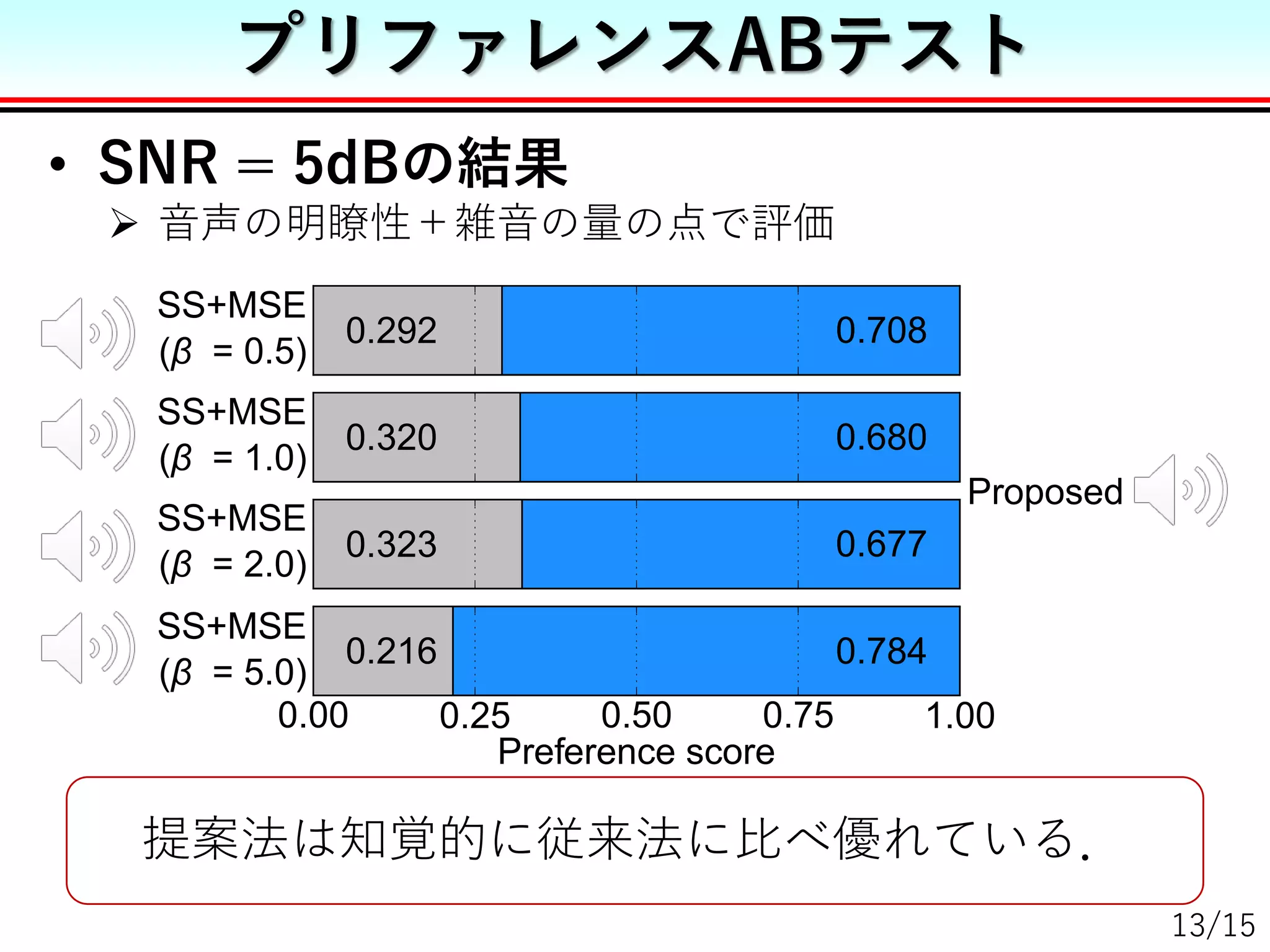
![• 比較手法
SS+MSE: SSで雑音抑圧後,音声生成モデルを学習
Proposed: 提案手法
実験条件
11/15
学習データ 日本語約3000文
テストデータ ATR音素バランス Jセット 53文
音声パラメータ 257次元のスペクトログラム
コンテキストラベル 439次元テキスト特徴量(F0を含む)
ニューラルネットワーク 全てFeed-Forward (原稿参照)
雑音生成モデルの入力 一様分布からランダム生成
観測雑音 白色ガウス雑音
SSにおける減算係数β 0.5, 1.0, 2.0, 5.0
入力SNR 0 [dB], 5 [dB], 10[dB]](https://image.slidesharecdn.com/une18asjsnoiseslide-180303165026/75/2018-DNN-11-2048.jpg)









































![[DL輪読会]Discriminative Learning for Monaural Speech Separation Using Deep Embe...](https://cdn.slidesharecdn.com/ss_thumbnails/201912227dldiscriminativeleraningformanaouraspeechseparationusingdeepembeddingfeaturessumissionver2-191227001259-thumbnail.jpg?width=640&height=640&fit=bounds)


































