More Related Content

PDF
SLP201805: 日本語韻律構造を考慮した prosody-aware subword embedding とDNN多方言音声合成への適用 
PDF
日本音響学会2017秋 ”Moment-matching networkに基づく一期一会音声合成における発話間変動の評価” 
PDF
Moment matching networkを用いた音声パラメータのランダム生成の検討 
PDF
DNN音声合成のための Anti-spoofing を考慮した学習アルゴリズム 
PDF

PDF

PDF
DNNテキスト音声合成のためのAnti-spoofingに敵対する学習アルゴリズム 
PDF
What's hot

PDF

PDF
日本語音声合成のためのsubword内モーラを考慮したProsody-aware subword embedding 
PDF
Phonetic Posteriorgrams for Many-to-One Voice Conversion without Parallel Dat... 
PDF
Saito21asj Autumn Meeting 
PDF

PDF
時間領域低ランクスペクトログラム近似法に基づくマスキング音声の欠損成分復元 
PDF
日本音響学会2017秋 ”クラウドソーシングを利用した対訳方言音声コーパスの構築” 
PDF

PDF

PDF
雑音環境下音声を用いた音声合成のための雑音生成モデルの敵対的学習 
PDF
短時間発話を用いた話者照合のための音声加工の効果に関する検討 
PDF
日本音響学会2018春 ”雑音環境下音声を用いたDNN音声合成のための雑音生成モデルの敵対的学習” (宇根) 
PPTX
ICASSP2019音声&音響論文読み会 論文紹介(認識系) 
PPTX
ICASSP2019 音声&音響論文読み会 著者紹介2 (信号処理系2) 
PPTX
論文紹介: Direct-Path Signal Cross-Correlation Estimation for Sound Source Locali... 
ODP

PDF

PDF

PDF

PDF
Viewers also liked

PDF

PDF
Informed Refusal: you are doing it wrong 
PDF

PPTX
Informe sobre el diagnostico de seguridad industrial , 
PDF
GMMに基づく固有声変換のための変調スペクトル制約付きトラジェクトリ学習・適応 
PPTX

PPT

PPTX

PDF

PDF

PDF

PPTX
Metriplica America: “Cómo a partir de la medición, mejoramos nuestro negocio ... 
PDF
Interreg Europe ZEROCO2 regional policies report promoting energy efficiency ... 
PPTX
Herramientas de la web 2.0 
PPTX

PPTX
Tema 4. ciencias sociales. 
DOCX

PPTX

PPTX
Similar to saito2017asj_tts

PDF
分布あるいはモーメント間距離最小化に基づく統計的音声合成 
PDF

PDF
音学シンポジウム2025「ニューラルボコーダ概説:生成モデルと実用性の観点から」 
PDF
Neural text-to-speech and voice conversion 
PDF
差分スペクトル法に基づくDNN声質変換のためのリフタ学習およびサブバンド処理 
PDF
音学シンポジウム2025「音声研究の知見がニューラルボコーダの発展にもたらす効果」 
PDF

PDF

PDF
Interspeech 2020 読み会 "Incremental Text to Speech for Neural Sequence-to-Sequ... 
PDF
ヤフー音声認識サービスでのディープラーニングとGPU利用事例 ![[DL輪読会]Discriminative Learning for Monaural Speech Separation Using Deep Embe...](https://cdn.slidesharecdn.com/ss_thumbnails/201912227dldiscriminativeleraningformanaouraspeechseparationusingdeepembeddingfeaturessumissionver2-191227001259-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
[DL輪読会]Discriminative Learning for Monaural Speech Separation Using Deep Embe... 
PDF
微分可能な信号処理に基づく音声合成器を用いた DNN 音声パラメータ推定の検討 
PPTX
Deep-Learning-Based Environmental Sound Segmentation - Integration of Sound ... 
PDF
フィラーを含む自発音声合成モデルの品質低下原因の調査と一貫性保証による改善 
PPTX
End-to-end 韻律推定に向けた subword lattice 構造を考慮した DNN 音響モデル学習 
PPTX
深層ガウス過程音声合成におけるsequence-to-sequence学習の初期検討 ![[DL輪読会]Monaural Audio Source Separationusing Variational Autoencoders](https://cdn.slidesharecdn.com/ss_thumbnails/20190717dlmonauralaudiosourceseparationusingvariationalautoencodersver2-190719035345-thumbnail.jpg?width=640&height=640&fit=bounds)
PPTX
[DL輪読会]Monaural Audio Source Separationusing Variational Autoencoders 
PDF
Icassp2018 発表参加報告 FFTNet, Tactron2紹介 ![[DL輪読会]GANSynth: Adversarial Neural Audio Synthesis](https://cdn.slidesharecdn.com/ss_thumbnails/20180315gansynthmizuta-190315003922-thumbnail.jpg?width=640&height=640&fit=bounds)
PPTX
[DL輪読会]GANSynth: Adversarial Neural Audio Synthesis 
PDF
Deep learning for acoustic modeling in parametric speech generation More from Yuki Saito

PDF

PDF

PDF

PDF
Nishimura22slp03 presentation 
PDF
Saito20asj s slide_published 
PDF
GAN-based statistical speech synthesis (in Japanese) 
PDF
nakai22apsipa_presentation.pdf 
PDF

PDF

PDF
saito22research_talk_at_NUS 
PDF

PPTX
saito2017asj_tts
- 1.
- 2.
/16
問題点: 統計的パラメトリック音声合成の音質劣化
–生成される音声特徴量系列の過剰な平滑化が一因
従来法: 敵対的DNN音声合成 [Saito et al., 2017.]
– 声のなりすましを防ぐ anti-spoofing を詐称するように学習
– 自然 / 合成音声特徴量の分布の違いを補償
– スペクトル特徴量のみに関して有効性を確認
本発表: 敵対的DNN音声合成による 𝐹0・継続長の生成
– スペクトル特徴量と 𝐹0 の同時分布を補償
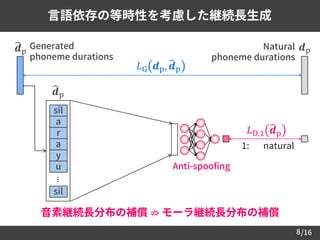
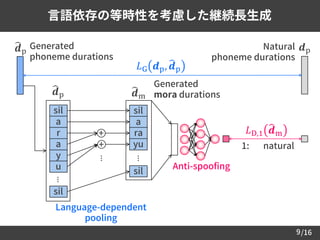
– 言語依存の等時性を考慮した継続長の生成法を提案
結果: 𝐹0の生成に関して提案法による音質改善を確認
1
本発表の概要
- 3.
/16
Minimum Generation Error(MGE) 学習
2
Generation
error
𝐿G 𝒚, ෝ𝒚
Linguistic
feats.
[Wu et al., 2016.]
Natural
speech
params.
𝐿G 𝒚, ෝ𝒚 =
1
𝑇
ෝ𝒚 − 𝒚 ⊤ ෝ𝒚 − 𝒚 → Minimize
𝒚
ML-based
parameter
generation
Generated
speech
params.ෝ𝒚
Acoustic models
⋯
⋯
⋯
Frame
𝑡 = 1
Static-dynamic
mean vectors
Frame
𝑡 = 𝑇
音素継続長も同様の枠組みで生成可能 [Zen et al., 2013.]
- 4.
/16
Anti-Spoofing: 声のなりすましを防ぐ識別器
3
[Wu etal., 2016.] [Chen et al., 2015.]
𝐿D 𝒚, ෝ𝒚 = → Minimize−
1
𝑇
𝑡=1
𝑇
log 𝐷 𝒚 𝑡 −
1
𝑇
𝑡=1
𝑇
log 1 − 𝐷 ෝ𝒚 𝑡
ෝ𝒚
Cross entropy
𝐿D 𝒚, ෝ𝒚
1: natural
0: generated
Generated
speech params.
𝒚Natural
speech params.
Feature
function
𝝓 ⋅
本発表では
𝝓 𝒚 𝑡 = 𝒚 𝑡
Anti-spoofing
𝐷 ⋅
or
𝐿D,1 𝒚 𝐿D,0 ෝ𝒚
合成音声を
合成音声と識別させる
自然音声を
自然音声と識別させる
- 5.
/144
𝜔D: 重み, 𝐸𝐿G
, 𝐸 𝐿D
: 𝐿G 𝒚, ෝ𝒚 , 𝐿D,1 ෝ𝒚 の期待値
𝐿 𝒚, ෝ𝒚 = 𝐿G 𝒚, ෝ𝒚 + 𝜔D
𝐸 𝐿G
𝐸 𝐿D
𝐿D,1 ෝ𝒚 → Minimize
敵対的DNN音声合成 [Saito et al., 2017.]
𝐿G 𝒚, ෝ𝒚
Linguistic
feats.
Natural
𝒚
ML-based
parameter
generation
Generated
ෝ𝒚
Acoustic models
⋯
⋯
⋯
𝐿D,1 ෝ𝒚
1: natural
Feature
function
𝝓 ⋅
Anti-spoofing
合成音声を
自然音声と識別させる
- 6.
/145
敵対的学習 [Goodfellow etal., 2014.] による
分布補償効果
21st mel-cepstral coefficient
23rdmel-cepstral
coefficient
Natural MGE Proposed
分布の違いを補償し, 過剰な平滑化を緩和!
- 7.
- 8.
/167
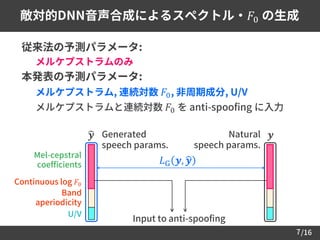
敵対的DNN音声合成によるスペクトル・𝐹0 の生成
従来法の予測パラメータ:
–メルケプストラムのみ
本発表の予測パラメータ:
– メルケプストラム, 連続対数 𝐹0, 非周期成分, U/V
– メルケプストラムと連続対数 𝐹0 を anti-spoofing に入力
Generated
speech params.
Mel-cepstral
coefficients
Continuous log 𝐹0
U/V
Band
aperiodicity
Natural
speech params.
𝒚ෝ𝒚
𝐿G 𝒚, ෝ𝒚
Input to anti-spoofing
- 9.
- 10.
- 11.
/1610
考察
𝐹0 の生成:
–スペクトルと 𝐹0 の同時分布を補償可能
• 異なる特徴量の相関を考慮した学習 [Tanaka et al., 2014.]
• 特徴量の次元数を考慮した学習 [Kang et al., 2014.] も可能
継続長の生成:
– 多重解像度に基づく敵対的学習 [Zhang et al., 2016.] に類似
• 高い時間解像度における生成誤差最小化
• 低い時間解像度における敵対的学習
– スペクトル・ 𝐹0・継続長の同時分布も補償可能
• Un-pooling により音素継続長をフレームレベルに展開可能
- 12.
- 13.
/16
実験条件
データセット ATR 音素バランス503文(16 kHz サンプリング)
学習 / 評価データ A-I セット 450文 / Jセット 53文
音声パラメータ
25次元のメルケプストラム, 連続対数 𝐹0,
5帯域の非周期成分, U/V
コンテキストラベル 442次元 (音素, モーラ位置, アクセント型など)
最適化アルゴリズム AdaGrad [Duchi et al., 2011.] (学習率 0.01)
DNNアーキテクチャ
Feed-Forward, ReLU nonlinearity
(詳細は原稿参照)
12
𝐹0 生成, 継続長生成それぞれに関して提案法の有効性を検証
- 14.
/1613
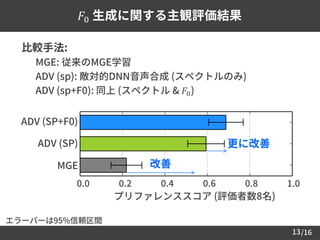
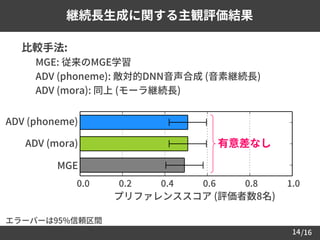
𝐹0 生成に関する主観評価結果
比較手法:
–MGE: 従来のMGE学習
– ADV (sp): 敵対的DNN音声合成 (スペクトルのみ)
– ADV (sp+F0): 同上 (スペクトル & 𝐹0)
ADV (SP+F0)
ADV (SP)
エラーバーは95%信頼区間
MGE
0.0 0.2 0.4
改善
プリファレンススコア (評価者数8名)
更に改善
0.6 0.8 1.0
- 15.
- 16.
/16
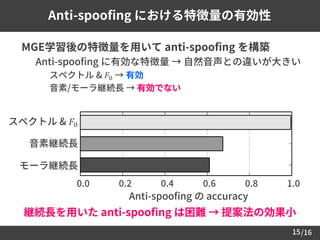
MGE学習後の特徴量を用いて anti-spoofingを構築
– Anti-spoofing に有効な特徴量 → 自然音声との違いが大きい
• スペクトル & 𝐹0 → 有効
• 音素/モーラ継続長 → 有効でない
15
Anti-spoofing における特徴量の有効性
継続長を用いた anti-spoofing は困難 → 提案法の効果小
スペクトル & 𝐹0
音素継続長
モーラ継続長
0.0
Anti-spoofing の accuracy
0.2 0.4 0.6 0.8 1.0
- 17.
/1616
まとめ
目的: 統計的パラメトリック音声合成の音質改善
提案手法:
– (1) 敵対的DNN音声合成によるスペクトル・ 𝐹0 の生成
• 主観評価により音質改善を確認
– (2) モーラ等時性を考慮した継続長生成 + 敵対的DNN音声合成
• 主観評価において有意差は確認できず
• 継続長を用いた anti-spoofing の難しさに起因
今後の予定:
• 他言語・オーディオブックのタスクへの適用

![/16
問題点: 統計的パラメトリック音声合成の音質劣化
– 生成される音声特徴量系列の過剰な平滑化が一因
従来法: 敵対的DNN音声合成 [Saito et al., 2017.]
– 声のなりすましを防ぐ anti-spoofing を詐称するように学習
– 自然 / 合成音声特徴量の分布の違いを補償
– スペクトル特徴量のみに関して有効性を確認
本発表: 敵対的DNN音声合成による 𝐹0・継続長の生成
– スペクトル特徴量と 𝐹0 の同時分布を補償
– 言語依存の等時性を考慮した継続長の生成法を提案
結果: 𝐹0の生成に関して提案法による音質改善を確認
1
本発表の概要](https://image.slidesharecdn.com/asj2017stts-170316221704/85/saito2017asj_tts-2-320.jpg)
![/16
Minimum Generation Error (MGE) 学習
2
Generation
error
𝐿G 𝒚, ෝ𝒚
Linguistic
feats.
[Wu et al., 2016.]
Natural
speech
params.
𝐿G 𝒚, ෝ𝒚 =
1
𝑇
ෝ𝒚 − 𝒚 ⊤ ෝ𝒚 − 𝒚 → Minimize
𝒚
ML-based
parameter
generation
Generated
speech
params.ෝ𝒚
Acoustic models
⋯
⋯
⋯
Frame
𝑡 = 1
Static-dynamic
mean vectors
Frame
𝑡 = 𝑇
音素継続長も同様の枠組みで生成可能 [Zen et al., 2013.]](https://image.slidesharecdn.com/asj2017stts-170316221704/85/saito2017asj_tts-3-320.jpg)
![/16
Anti-Spoofing: 声のなりすましを防ぐ識別器
3
[Wu et al., 2016.] [Chen et al., 2015.]
𝐿D 𝒚, ෝ𝒚 = → Minimize−
1
𝑇
𝑡=1
𝑇
log 𝐷 𝒚 𝑡 −
1
𝑇
𝑡=1
𝑇
log 1 − 𝐷 ෝ𝒚 𝑡
ෝ𝒚
Cross entropy
𝐿D 𝒚, ෝ𝒚
1: natural
0: generated
Generated
speech params.
𝒚Natural
speech params.
Feature
function
𝝓 ⋅
本発表では
𝝓 𝒚 𝑡 = 𝒚 𝑡
Anti-spoofing
𝐷 ⋅
or
𝐿D,1 𝒚 𝐿D,0 ෝ𝒚
合成音声を
合成音声と識別させる
自然音声を
自然音声と識別させる](https://image.slidesharecdn.com/asj2017stts-170316221704/85/saito2017asj_tts-4-320.jpg)
![/144
𝜔D: 重み, 𝐸 𝐿G
, 𝐸 𝐿D
: 𝐿G 𝒚, ෝ𝒚 , 𝐿D,1 ෝ𝒚 の期待値
𝐿 𝒚, ෝ𝒚 = 𝐿G 𝒚, ෝ𝒚 + 𝜔D
𝐸 𝐿G
𝐸 𝐿D
𝐿D,1 ෝ𝒚 → Minimize
敵対的DNN音声合成 [Saito et al., 2017.]
𝐿G 𝒚, ෝ𝒚
Linguistic
feats.
Natural
𝒚
ML-based
parameter
generation
Generated
ෝ𝒚
Acoustic models
⋯
⋯
⋯
𝐿D,1 ෝ𝒚
1: natural
Feature
function
𝝓 ⋅
Anti-spoofing
合成音声を
自然音声と識別させる](https://image.slidesharecdn.com/asj2017stts-170316221704/85/saito2017asj_tts-5-320.jpg)
![/145
敵対的学習 [Goodfellow et al., 2014.] による
分布補償効果
21st mel-cepstral coefficient
23rdmel-cepstral
coefficient
Natural MGE Proposed
分布の違いを補償し, 過剰な平滑化を緩和!](https://image.slidesharecdn.com/asj2017stts-170316221704/85/saito2017asj_tts-6-320.jpg)

![/1610
考察
𝐹0 の生成:
– スペクトルと 𝐹0 の同時分布を補償可能
• 異なる特徴量の相関を考慮した学習 [Tanaka et al., 2014.]
• 特徴量の次元数を考慮した学習 [Kang et al., 2014.] も可能
継続長の生成:
– 多重解像度に基づく敵対的学習 [Zhang et al., 2016.] に類似
• 高い時間解像度における生成誤差最小化
• 低い時間解像度における敵対的学習
– スペクトル・ 𝐹0・継続長の同時分布も補償可能
• Un-pooling により音素継続長をフレームレベルに展開可能](https://image.slidesharecdn.com/asj2017stts-170316221704/85/saito2017asj_tts-11-320.jpg)

![/16
実験条件
データセット ATR 音素バランス503文 (16 kHz サンプリング)
学習 / 評価データ A-I セット 450文 / Jセット 53文
音声パラメータ
25次元のメルケプストラム, 連続対数 𝐹0,
5帯域の非周期成分, U/V
コンテキストラベル 442次元 (音素, モーラ位置, アクセント型など)
最適化アルゴリズム AdaGrad [Duchi et al., 2011.] (学習率 0.01)
DNNアーキテクチャ
Feed-Forward, ReLU nonlinearity
(詳細は原稿参照)
12
𝐹0 生成, 継続長生成それぞれに関して提案法の有効性を検証](https://image.slidesharecdn.com/asj2017stts-170316221704/85/saito2017asj_tts-13-320.jpg)