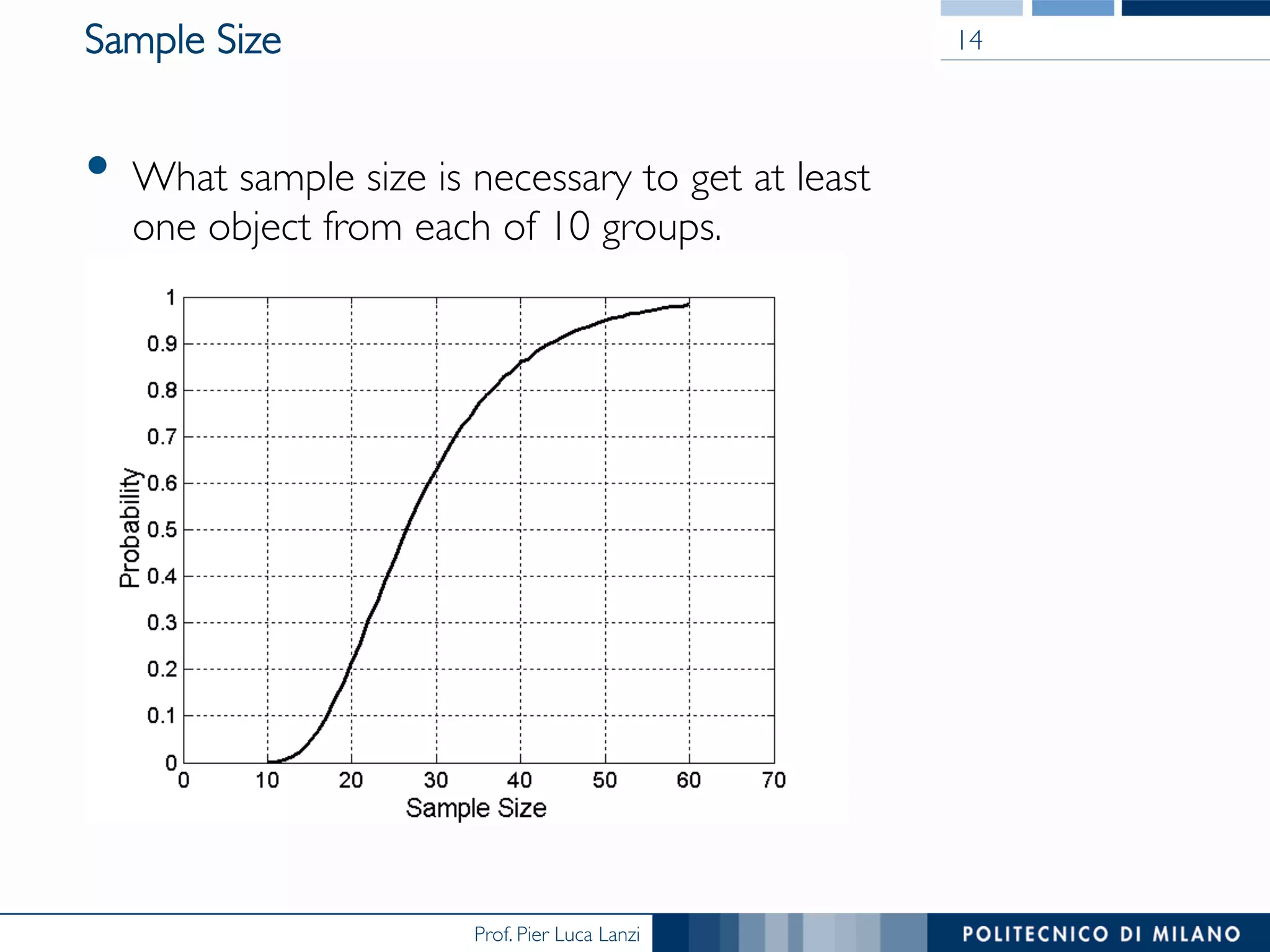
Downloaded 62 times

















![Prof. Pier Luca Lanzi
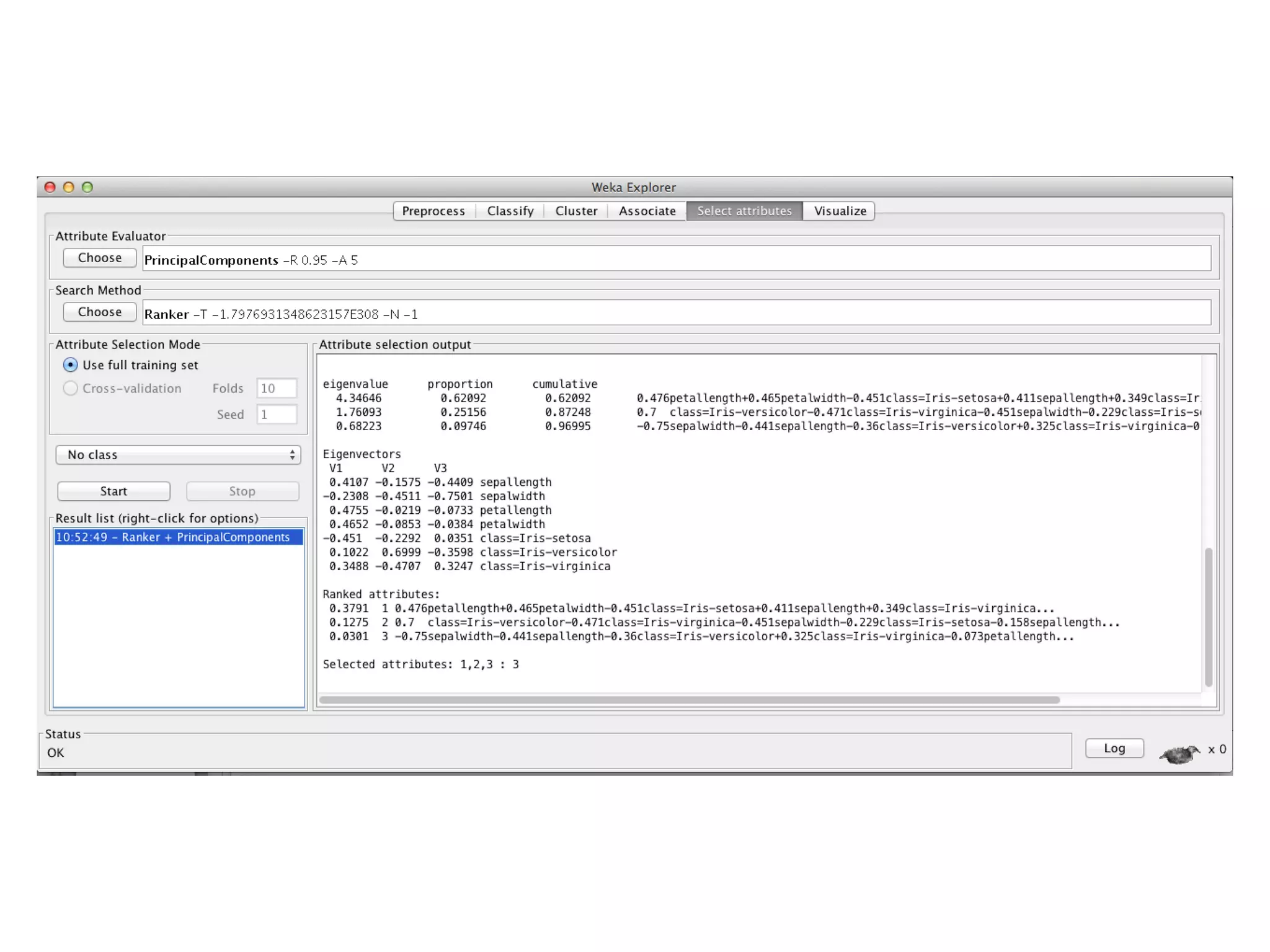
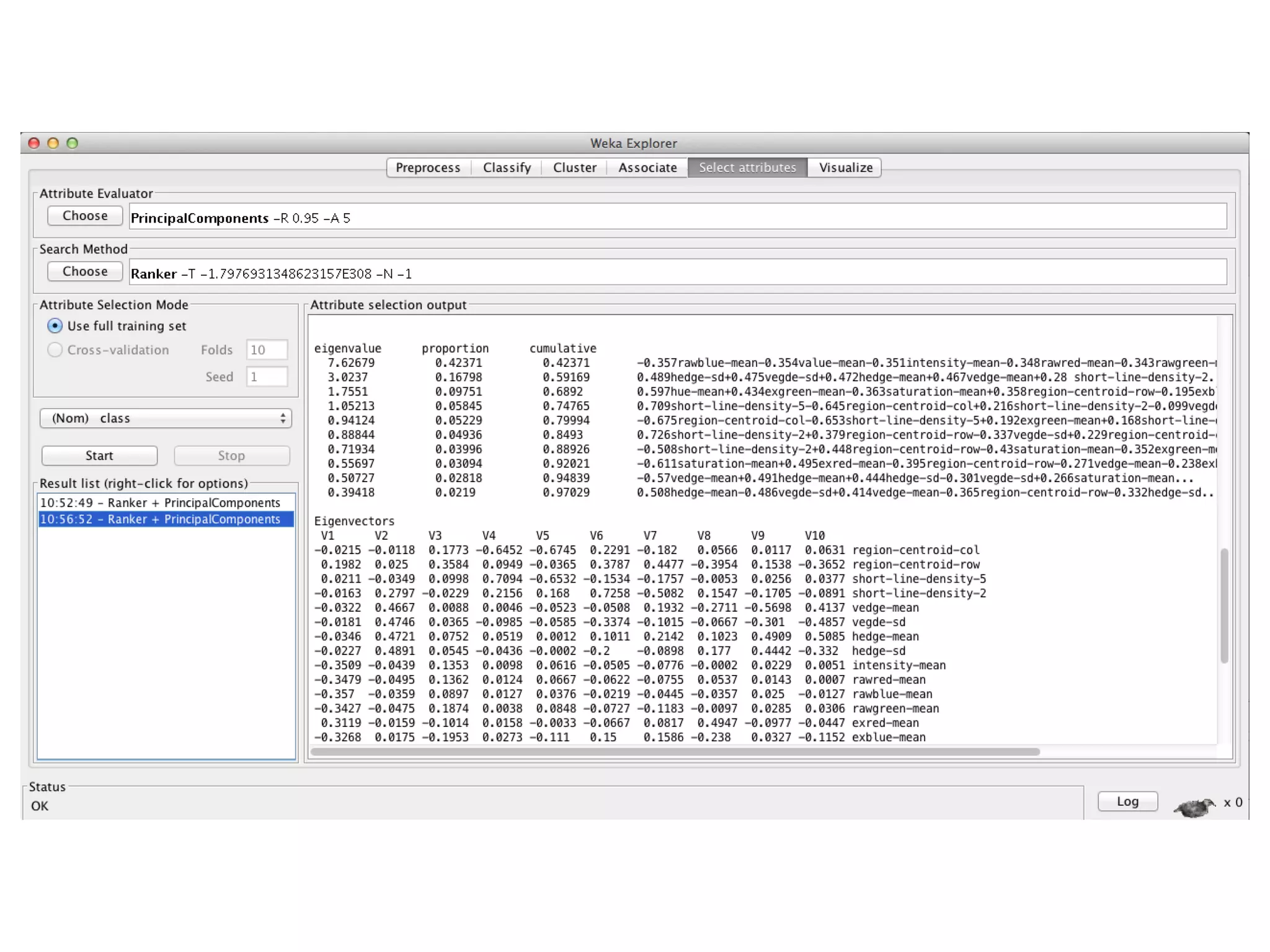
Singular Value Decomposition
• Data are viewed as a matrix A with n examples described by m
numerical attributes
A[n x m] = U[n x r] Λ [ r x r] (V[m x r])T
• A stores the original data
• U represents the n examples using r new concepts/attributes
• Λ represents the strength of each ‘concept’ (r is the rank of A)
• V contain m terms, r concepts
• Λi,i are called the singular values of A, if A is singular, some of the
wi will be 0; in general rank(A) = number of nonzero wi
• SVD is mostly unique (up to permutation of singular values, or if
some Li are equal)
22](https://image.slidesharecdn.com/dm2015-16-datapreparation-150707165306-lva1-app6891/75/DMTM-2015-16-Data-Preparation-22-2048.jpg)





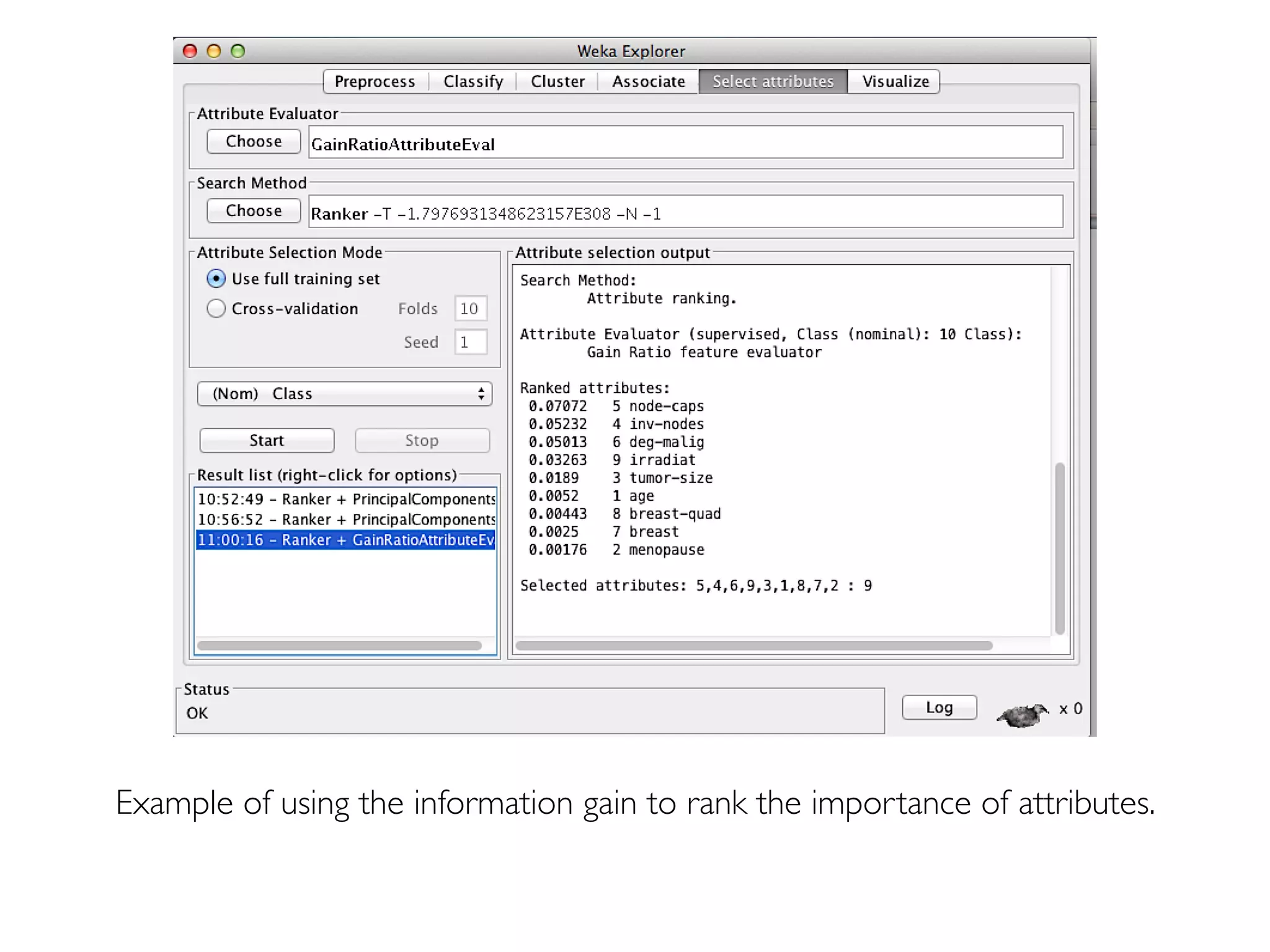
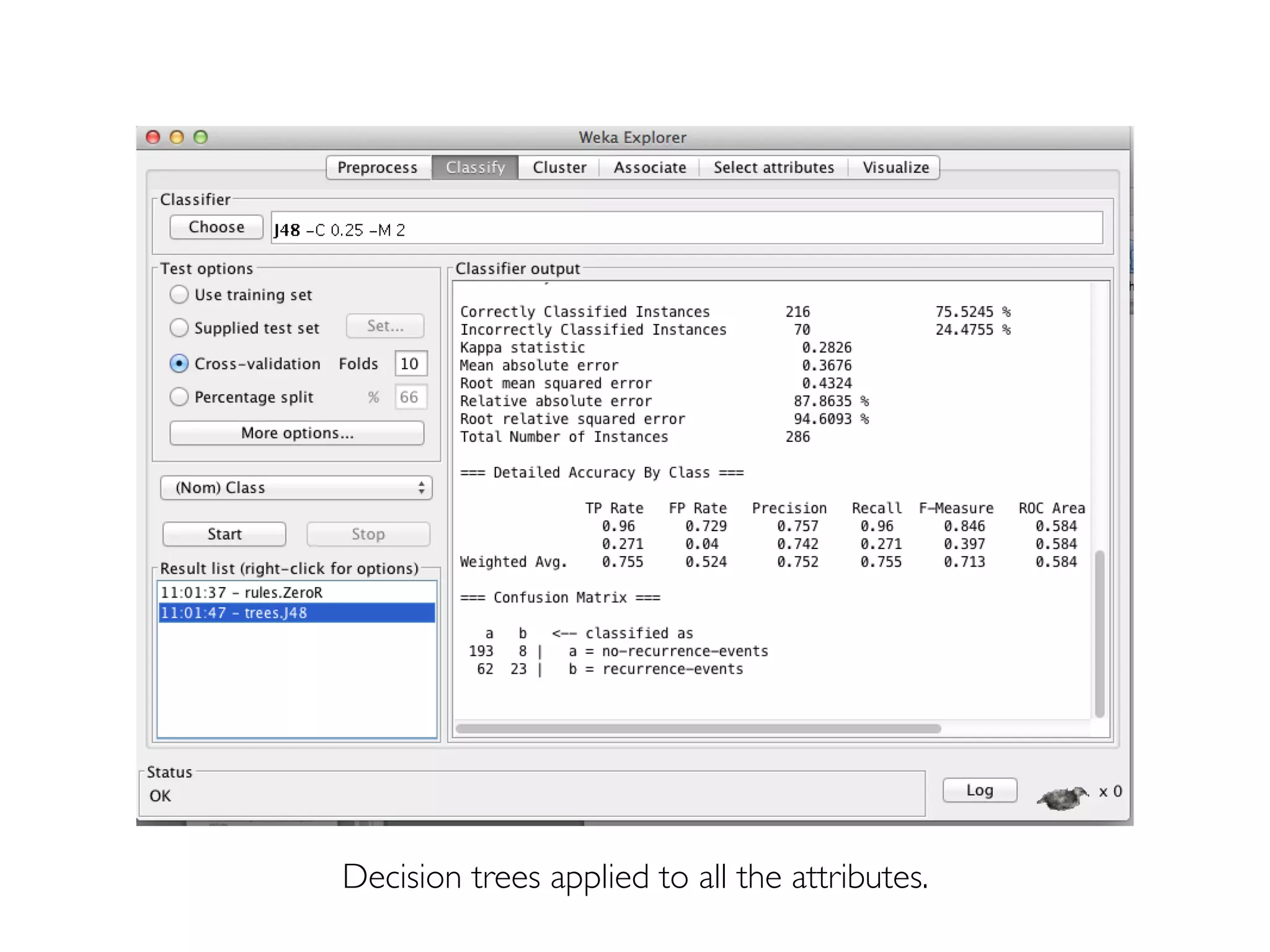
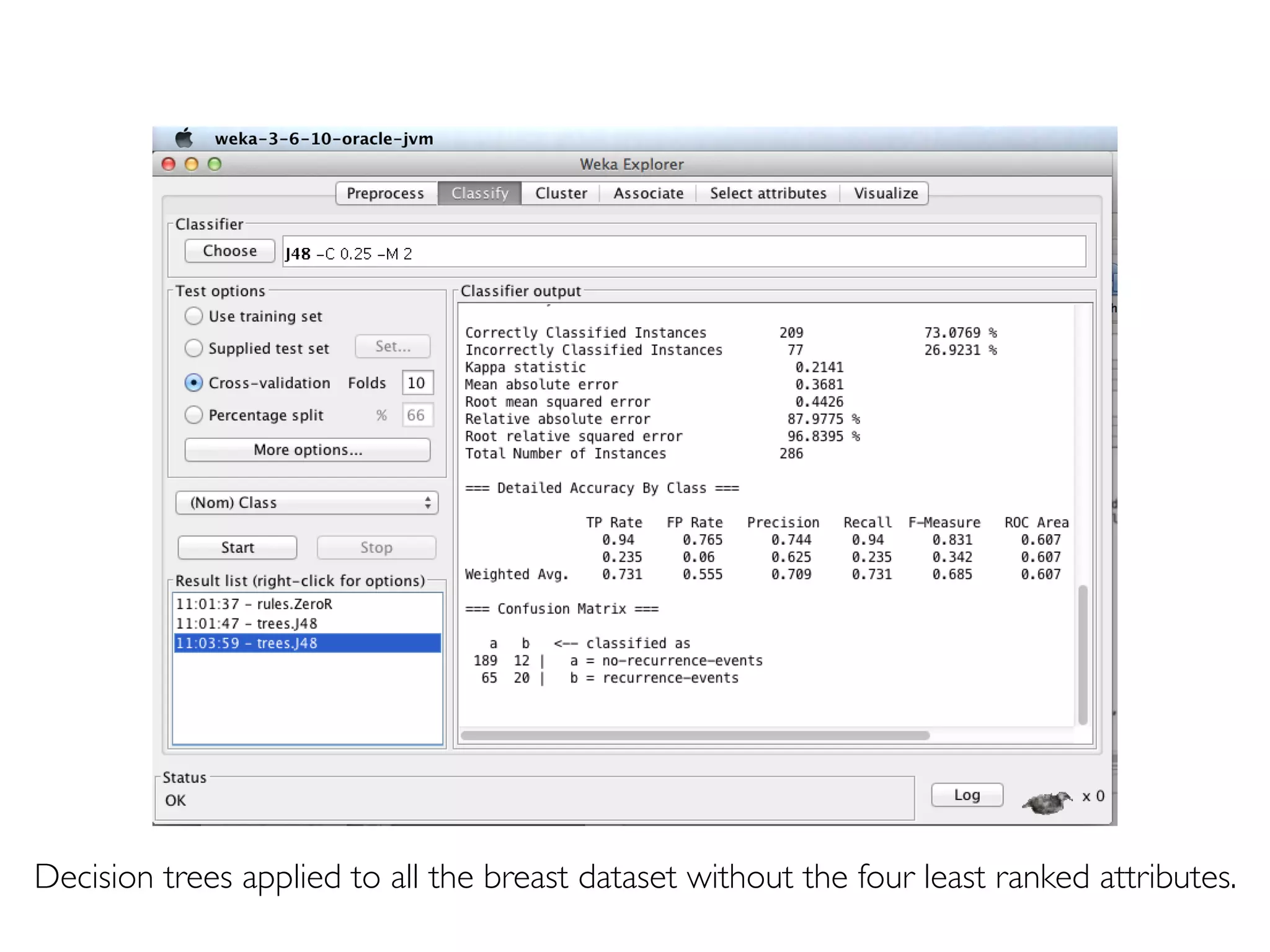
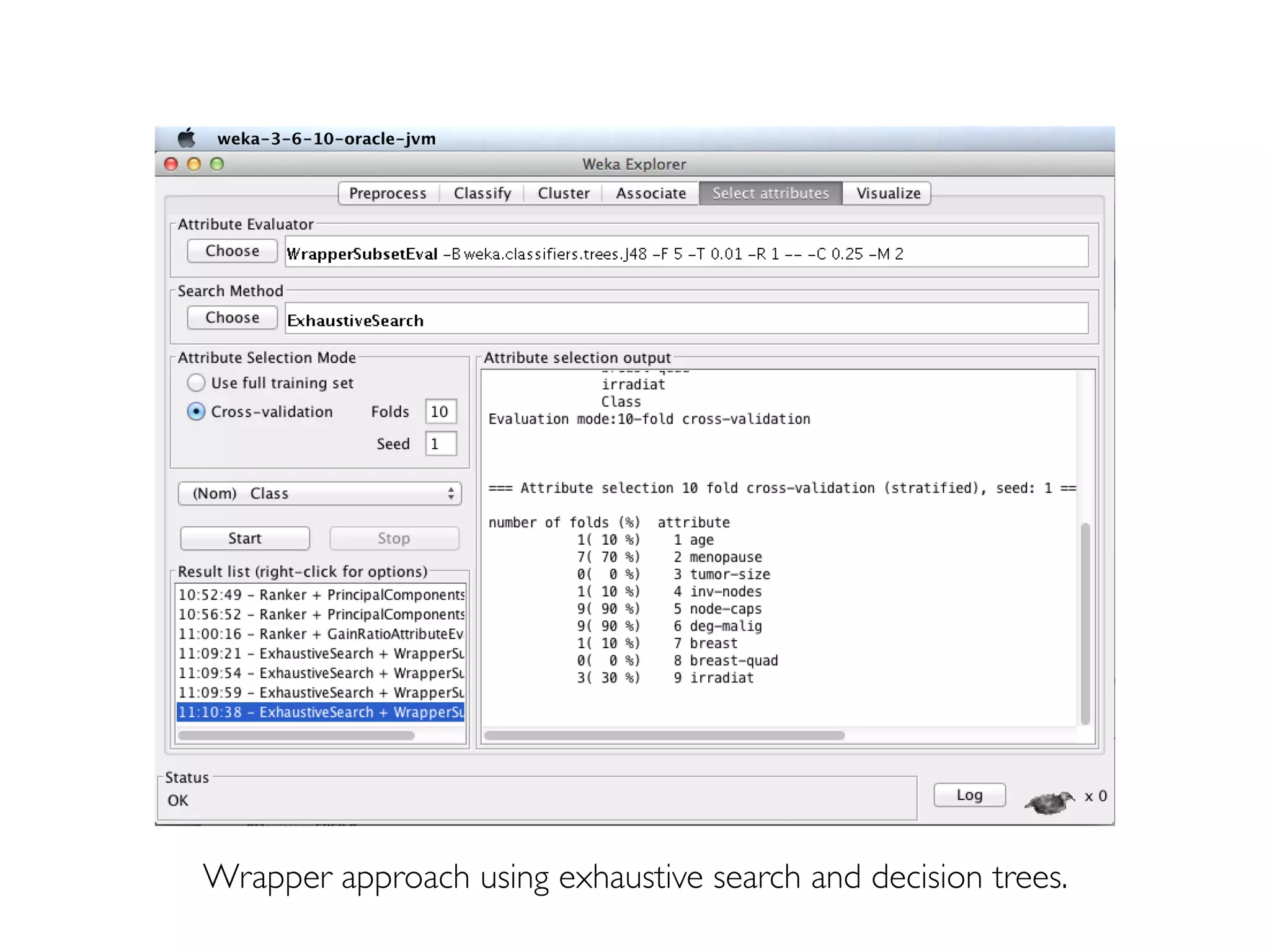






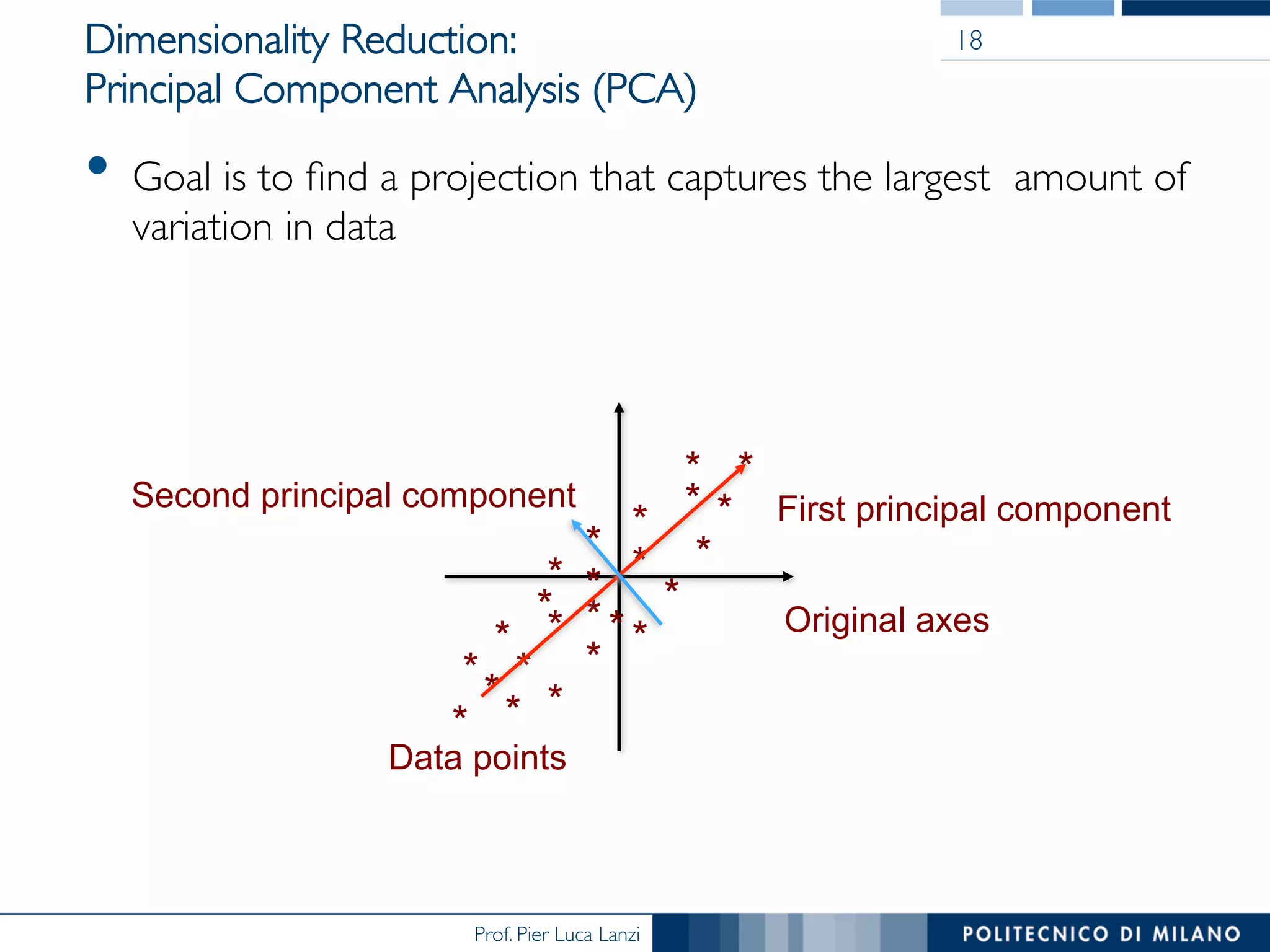
Prof. Pier Luca Lanzi discusses the significance of data preprocessing in data mining to handle real-world 'dirty' data, which can be incomplete, noisy, and inconsistent. Key tasks include data cleaning, integration, reduction, transformation, and handling missing or duplicate values, emphasizing that quality data is essential for accurate mining results. Various techniques such as dimensionality reduction through PCA and feature selection are also highlighted as critical to effective data analysis.




































































































