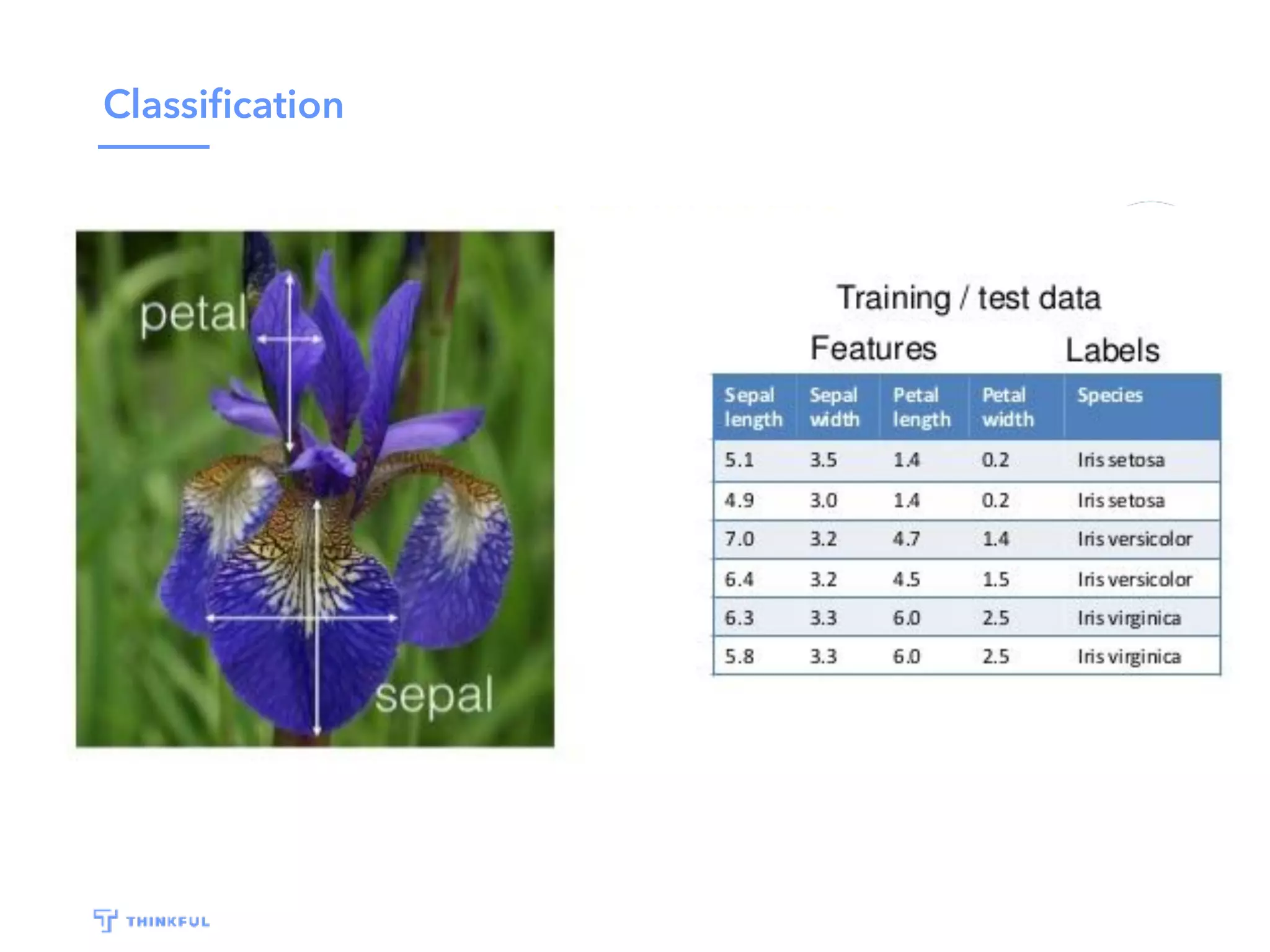
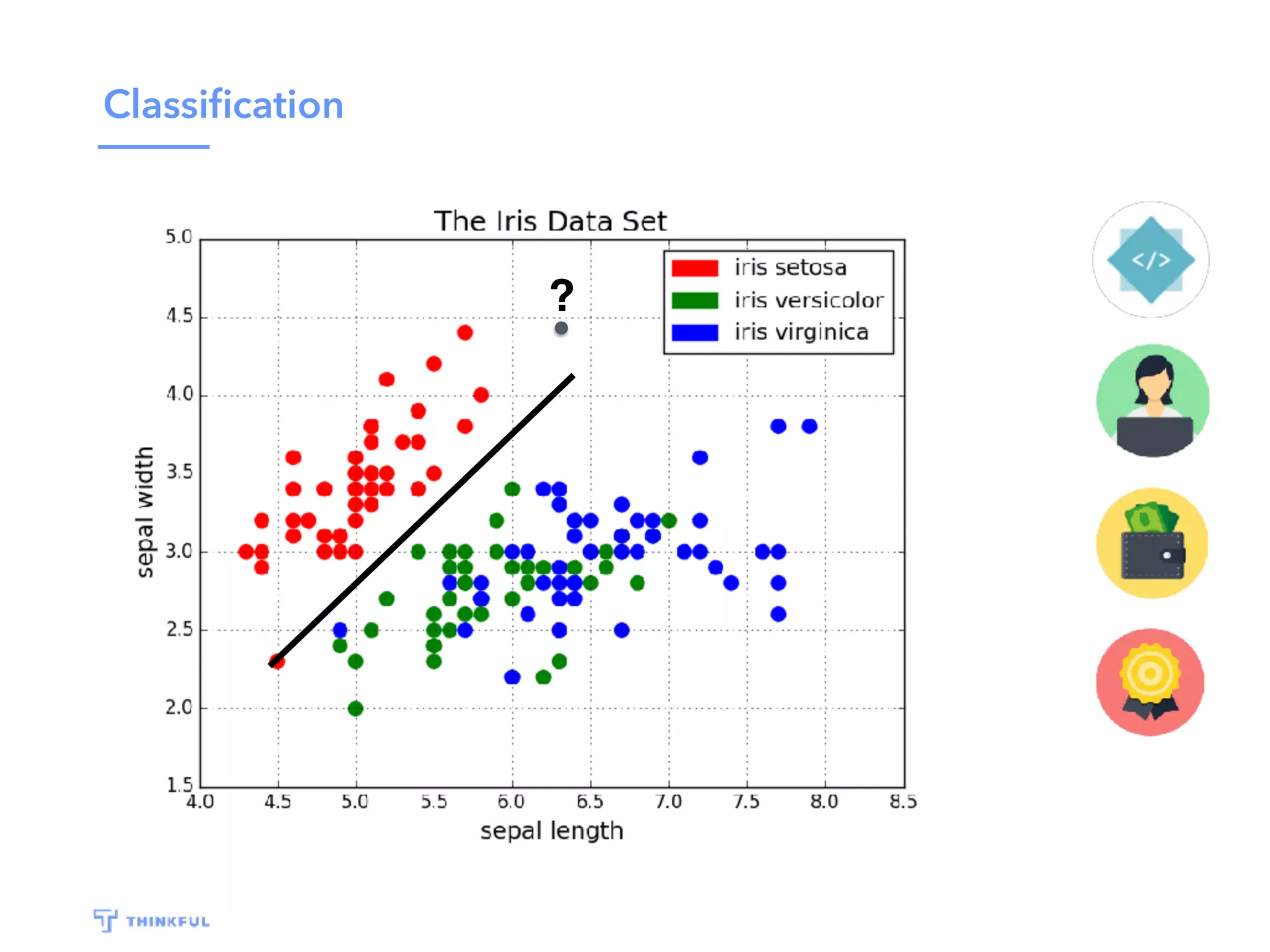
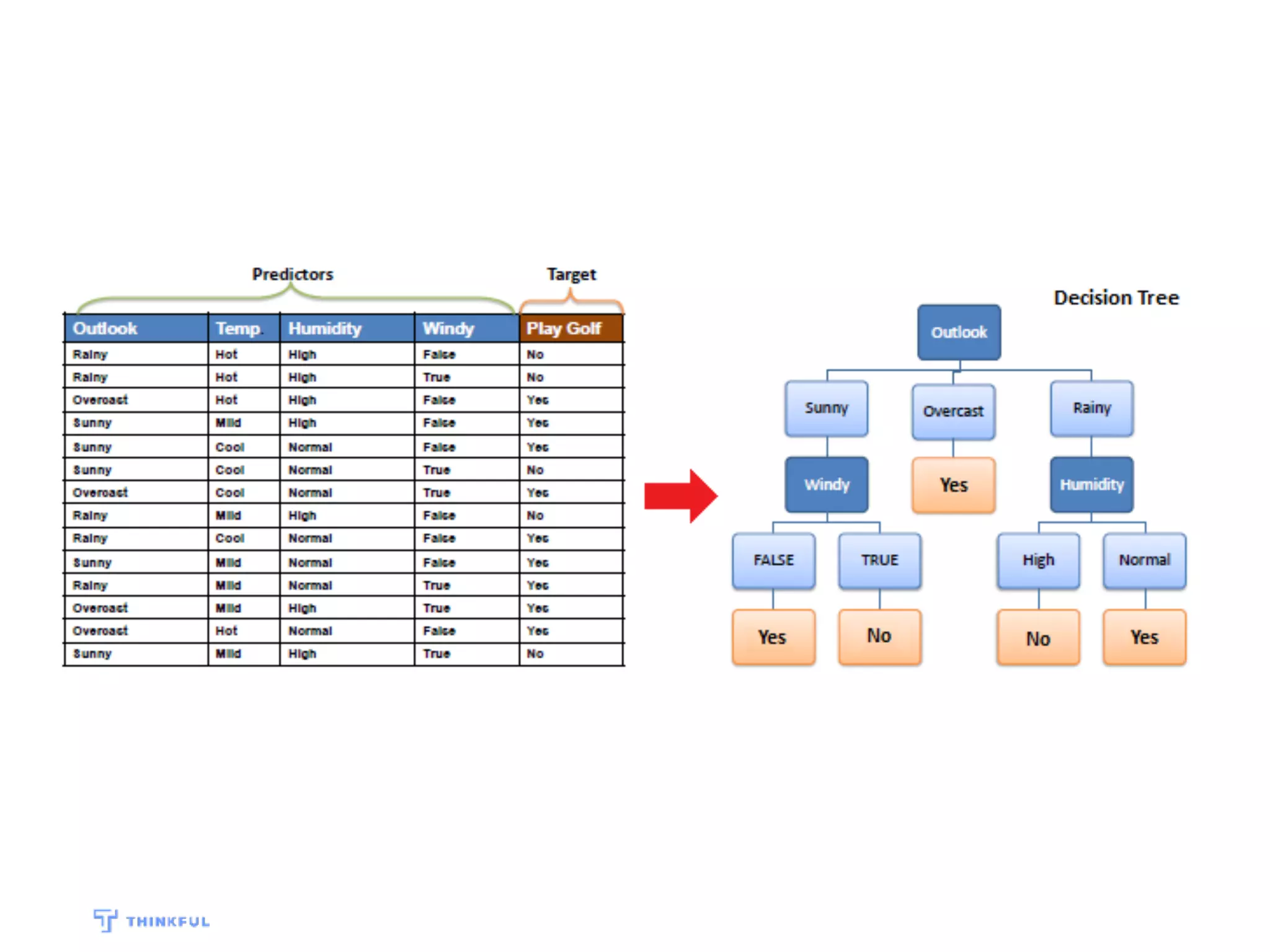
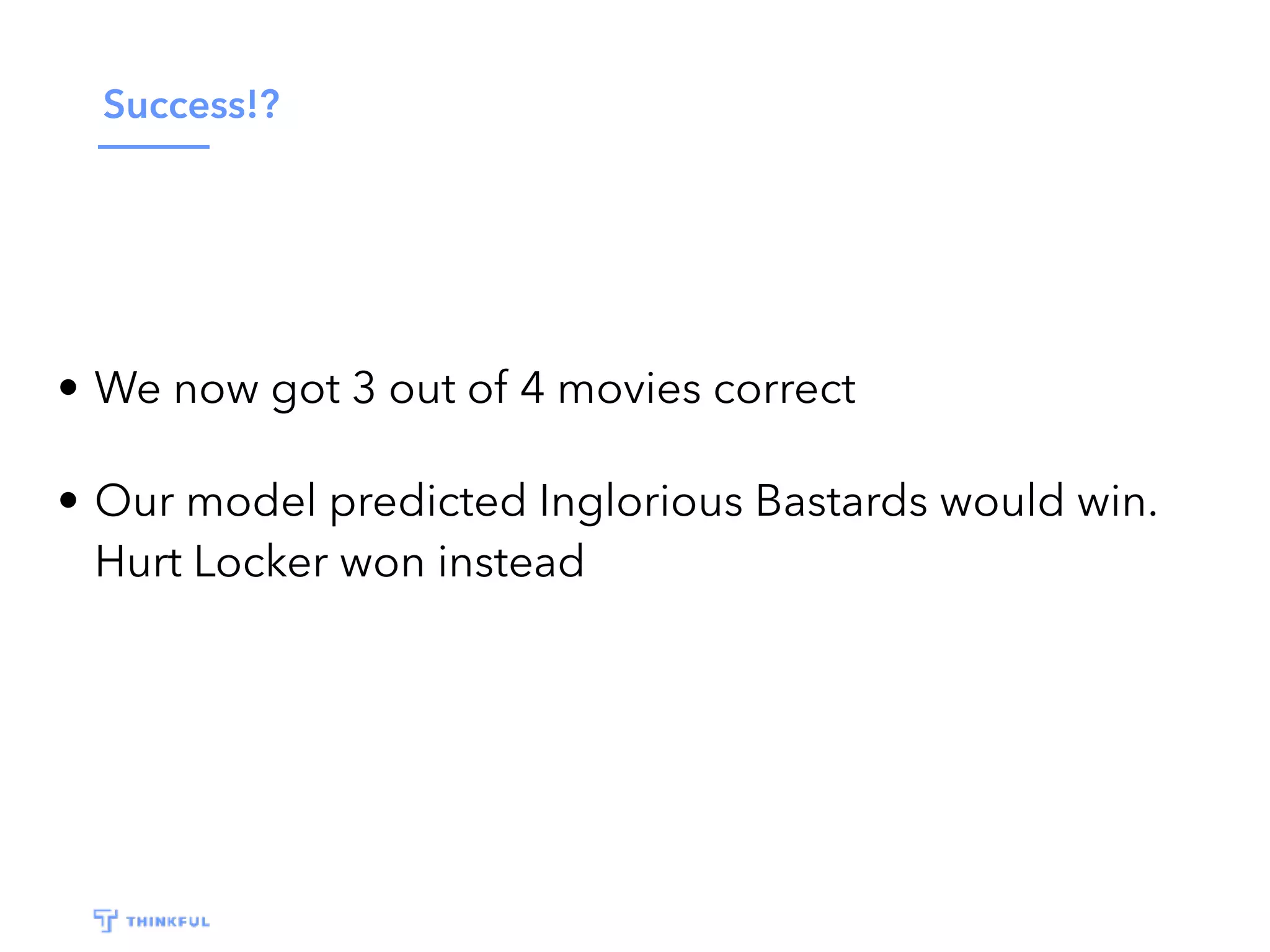
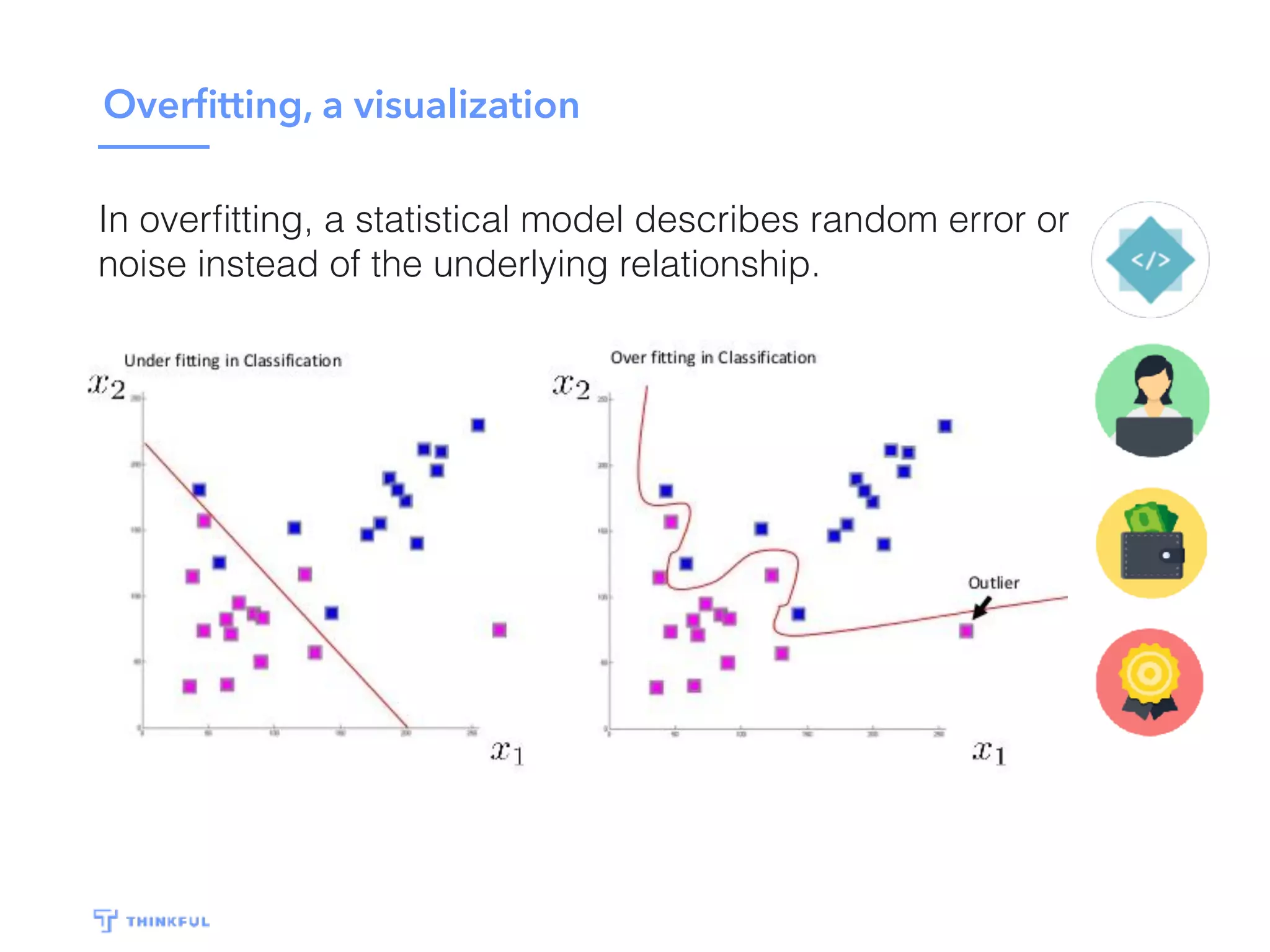
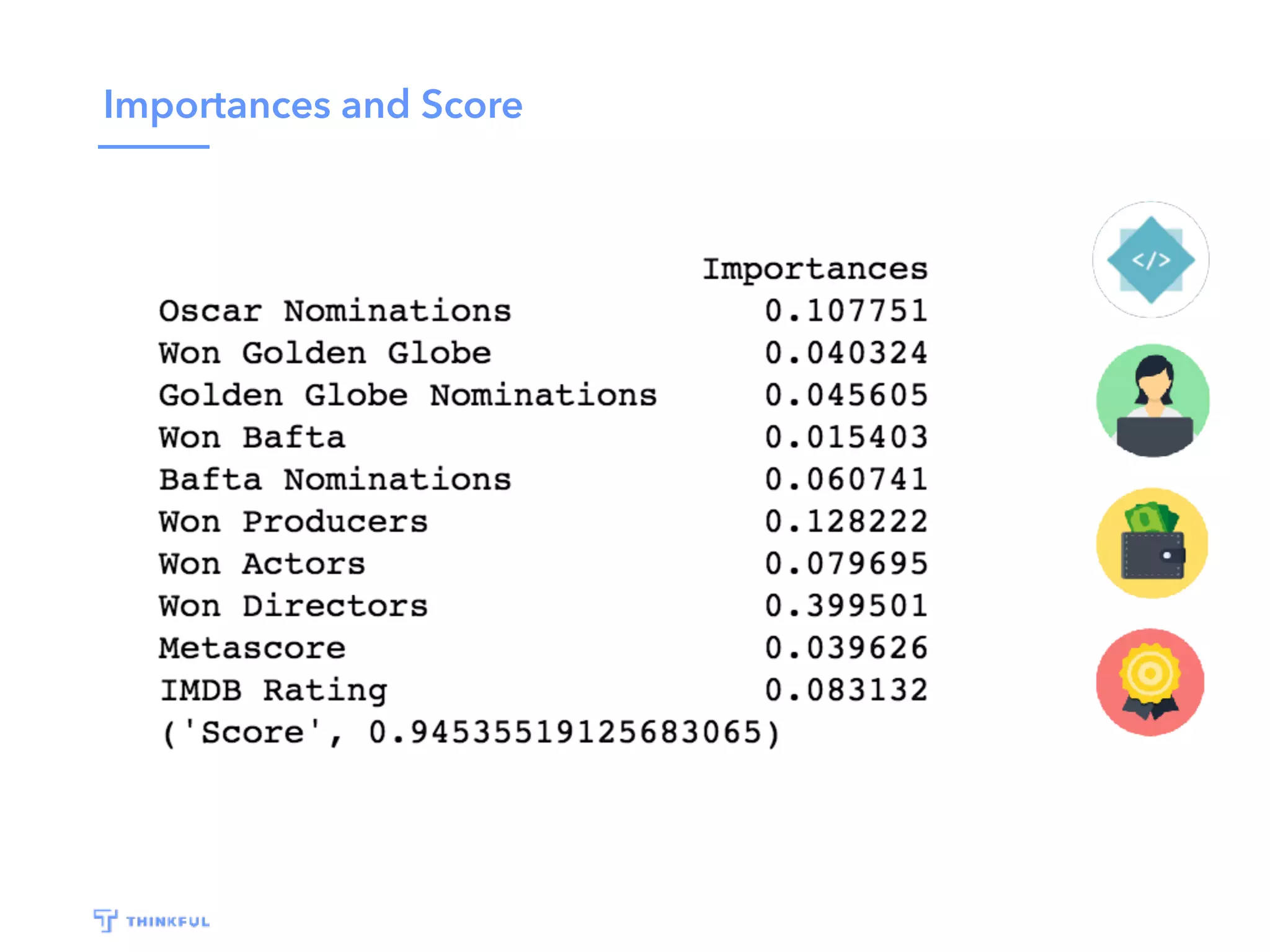
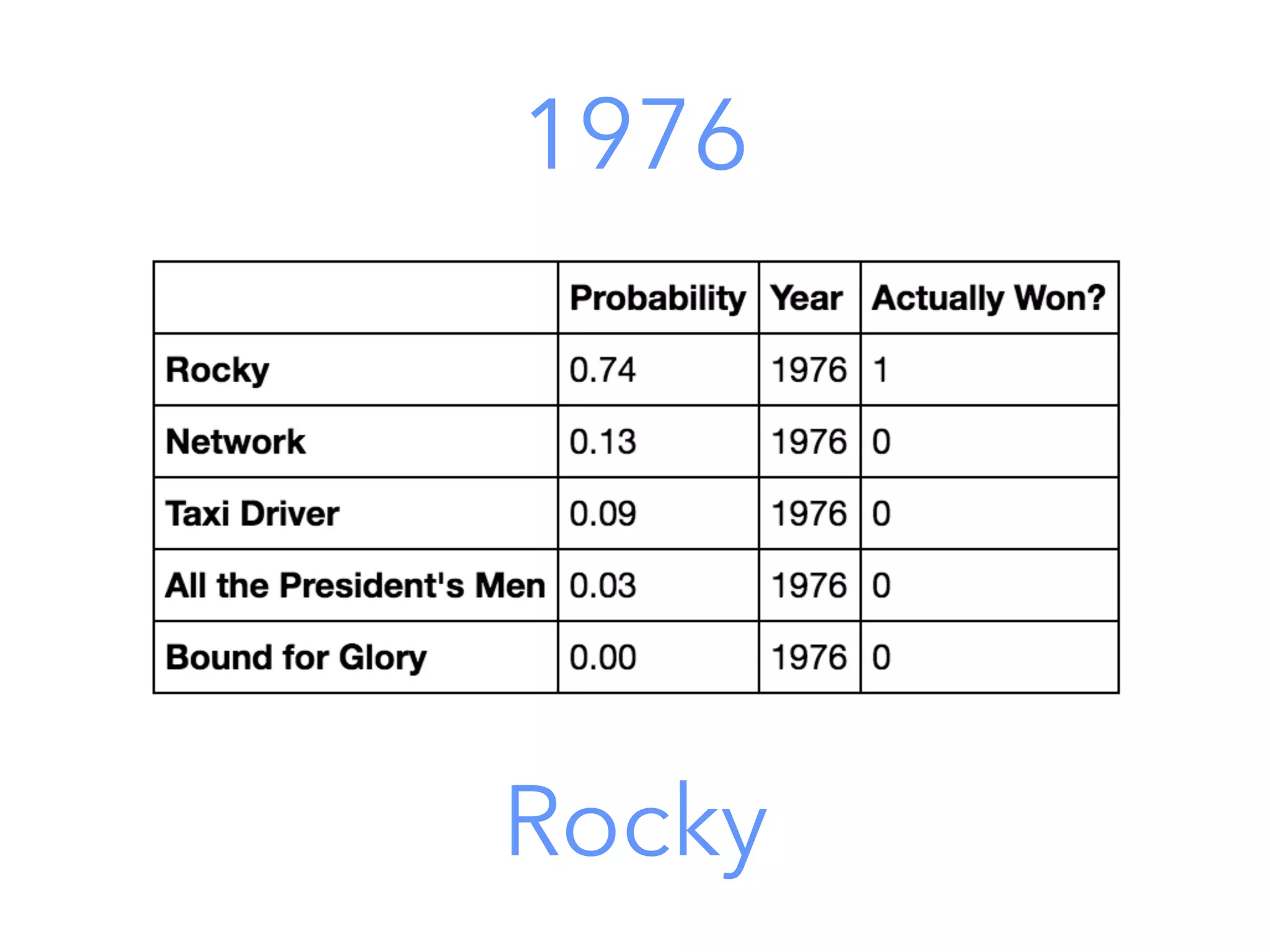
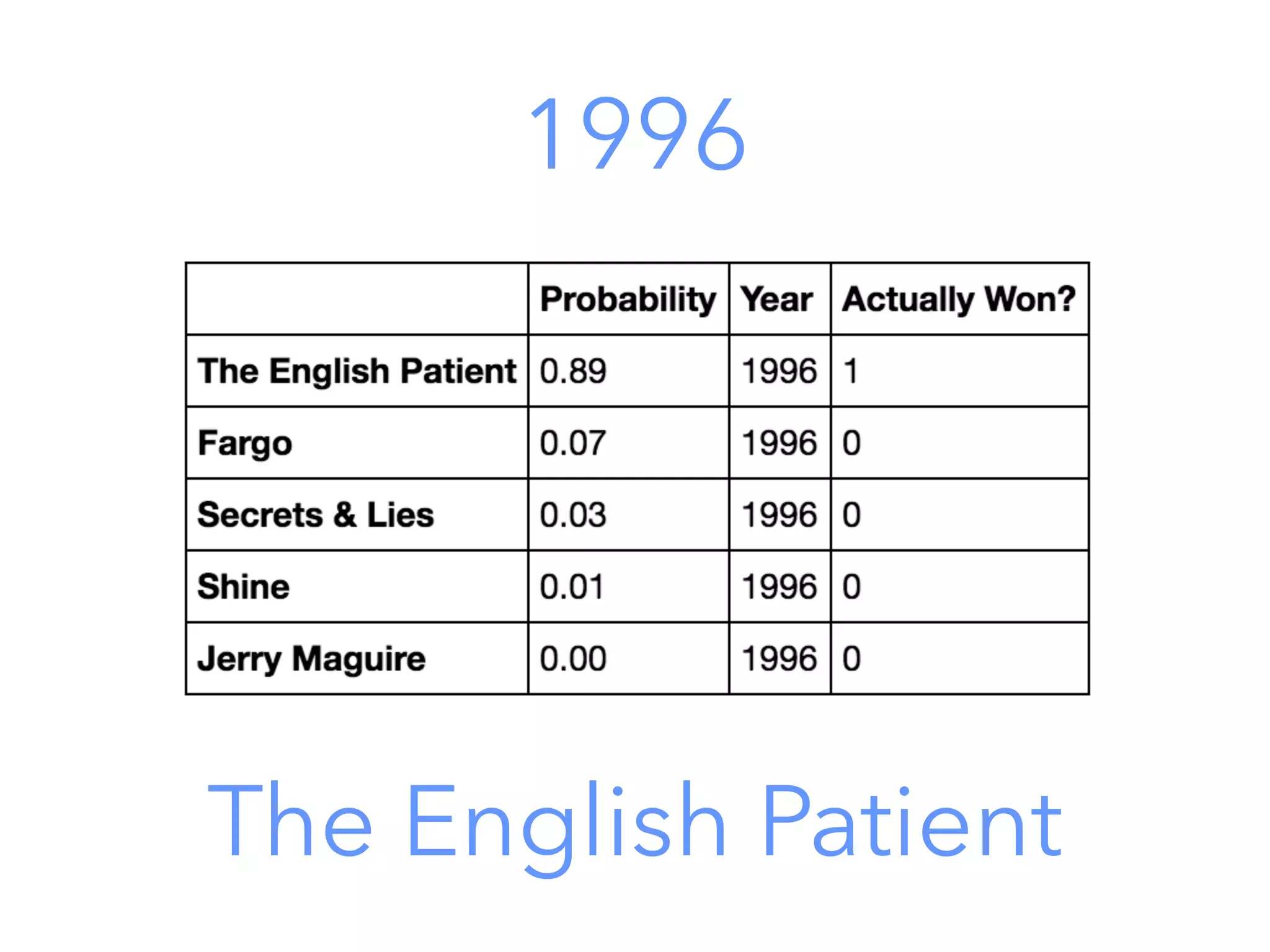
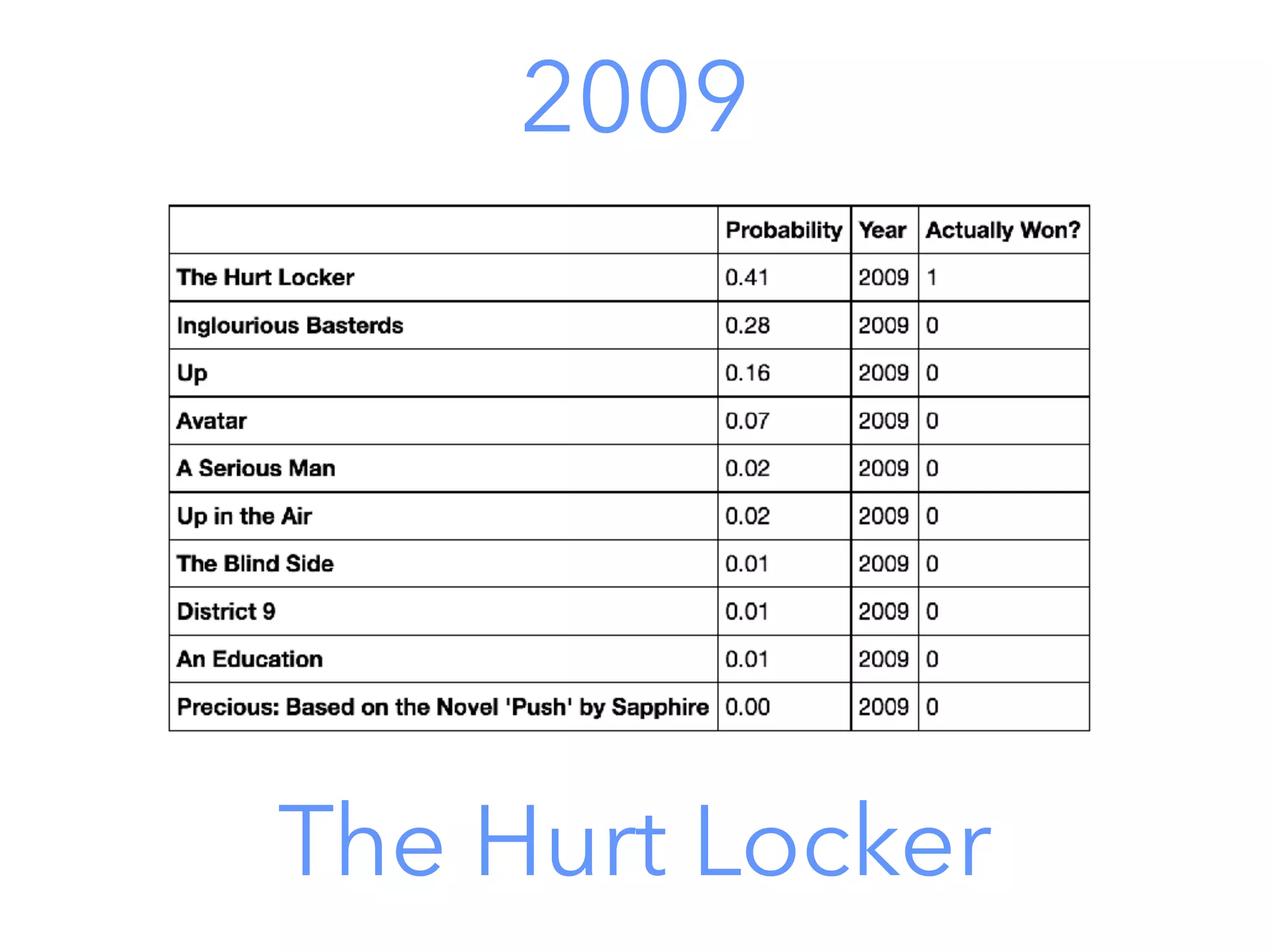
This document outlines a data science project to predict Oscar winners using machine learning techniques. It discusses collecting financial and review data on films, cleaning and formatting the data, exploring it for patterns, building a decision tree model, improving the model with a random forest classifier, and using the model to predict 2016 winners. The goal is to walk through the full data science process and how these techniques can be applied to a real-world prediction problem.