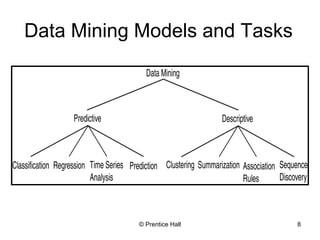
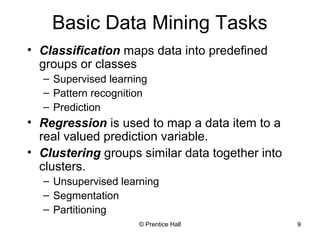
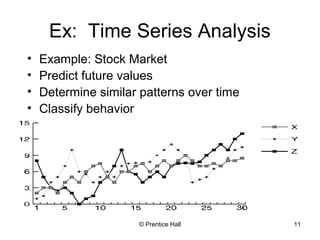
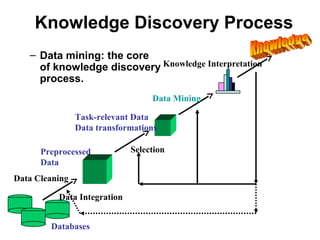
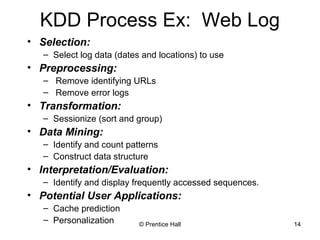
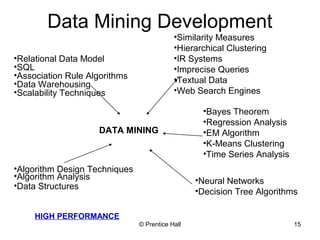
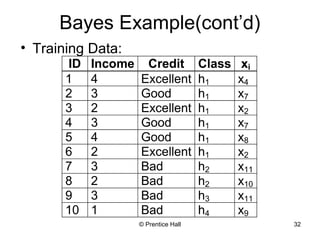
This document provides an overview and introduction to data mining. It defines data mining and distinguishes it from databases. The document outlines basic data mining tasks like classification, clustering, regression, and summarization. It also discusses the relationship between data mining and knowledge discovery in databases (KDD) and covers data mining models, development, issues, and metrics.