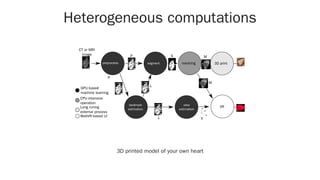
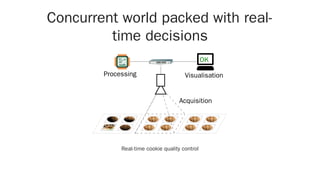
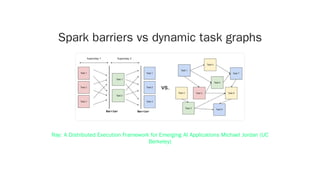
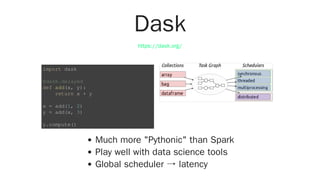
The document discusses distributed computing with Ray, a framework designed for parallel and distributed Python applications, particularly in AI and machine learning. It covers Ray's key features such as stateless tasks, actors, dynamic scheduling, and integration with popular data science tools, along with examples of using Ray for various computations. Additionally, it highlights the ecosystem of libraries built on top of Ray, emphasizing its usability and scalability from local machines to clusters.











![Celery
from celery import Celery
app = Celery('jobs', ...)
@app.task
def compute_stuff(x, y):
return x + y
@app.task
def another_compute_stuff(x, y):
return x + y
from jobs import compute_stuff, another_compute_stuff
compute_stuff.delay(1, 1).get()
compute_stuff.apply_async((2, 2), link=another_compute_stuff.s(16))
compute_stuff.starmap([(2, 2), (4, 4)])](https://image.slidesharecdn.com/distributedcomputingwithray-190503152105/85/Distributed-computing-with-Ray-Find-your-hyper-parameters-speed-up-your-Pandas-pipelines-and-much-more-13-320.jpg)
![PySpark
Mature, excellent for ETL, simple queries
Great for homogeneous processing of the points
"BigData" ecosystem in Java
R = matrix(rand(M, F)) * matrix(rand(U, F).T)
ms = matrix(rand(M, F))
us = matrix(rand(U, F))
Rb = sc.broadcast(R)
msb = sc.broadcast(ms)
usb = sc.broadcast(us)
for i in range(ITERATIONS):
ms = sc.parallelize(range(M), partitions)
.map(lambda x: update(x, usb.value, Rb.value))
.collect()
ms = matrix(np.array(ms)[:, :, 0])
…](https://image.slidesharecdn.com/distributedcomputingwithray-190503152105/85/Distributed-computing-with-Ray-Find-your-hyper-parameters-speed-up-your-Pandas-pipelines-and-much-more-14-320.jpg)








![Actors
Mutable state and unique resources
Instantiate the actor somewhere
@ray.remote
class ParameterServer(object):
def __init__(self, keys, values):
values = [value.copy() for value in values]
self.weights = dict(zip(keys, values))
def push(self, keys, values):
for key, value in zip(keys, values):
self.weights[key] += value
def pull(self, keys):
return [self.weights[key] for key in keys]
ps = ParameterServer.remote(keys, initial_values)](https://image.slidesharecdn.com/distributedcomputingwithray-190503152105/85/Distributed-computing-with-Ray-Find-your-hyper-parameters-speed-up-your-Pandas-pipelines-and-much-more-25-320.jpg)


![Mix and match tasks and actors
Grab and process an images from a camera
Or run a distributed SGD training
frame_id = camera.grab.remote()
segmented_id = segment.remote(frame_id)
segmented = ray.get(segmented_id)
@ray.remote
def worker(ps):
while True:
# Get the latest parameters
weights = ray.get(ps.pull.remote(keys))
# Compute an update of the params
# (e.g. the gradients for neural nets)
# Push the updates to the parameter server
ps.push.remote(keys, gradients)
worker_tasks = [worker.remote(ps) for _ in range(10)]](https://image.slidesharecdn.com/distributedcomputingwithray-190503152105/85/Distributed-computing-with-Ray-Find-your-hyper-parameters-speed-up-your-Pandas-pipelines-and-much-more-28-320.jpg)
![Dynamically define by run
import numpy as np
@ray.remote
def aggregate_data(x, y):
return x + y
data = [np.random.normal(size=1000) for i in range(4)]
while len(data) > 1:
intermediate_result = aggregate_data.remote(data[0], data[1])
data = data[2:] + [intermediate_result]
result = ray.get(data[0])](https://image.slidesharecdn.com/distributedcomputingwithray-190503152105/85/Distributed-computing-with-Ray-Find-your-hyper-parameters-speed-up-your-Pandas-pipelines-and-much-more-29-320.jpg)

![Plasma - Shared
memory object store
Share objects across local processes
In-memory key-value object store
data = ['Hallo PyDays', 4, (5, 5), np.ones((128, 128))]
key = ray.put(data)
deserialized = ray.get(key)](https://image.slidesharecdn.com/distributedcomputingwithray-190503152105/85/Distributed-computing-with-Ray-Find-your-hyper-parameters-speed-up-your-Pandas-pipelines-and-much-more-32-320.jpg)




![On-prem set-up
Start Ray head on one of the nodes
Start Ray workers on the nodes
Connect and run commands
Teardown Ray
$ ray start --head --redis-port=6379 # head IP: 192.168.1.5
$ ray start --redis-address=192.168.1.5:6379
ray.init(redis_address="192.168.1.5:6379")
@ray.remote
def imread(filename):
return cv2.imread(filename)
ims = ray.get([imread.remote(f) for f in glob('*.png')])
$ ray stop](https://image.slidesharecdn.com/distributedcomputingwithray-190503152105/85/Distributed-computing-with-Ray-Find-your-hyper-parameters-speed-up-your-Pandas-pipelines-and-much-more-39-320.jpg)



![5. Enter the head pod and run ipython
6. Profit from a distributed Python
$ kubectl --kubeconfig="kubeconfig.yaml" exec -it
ray-head-56fdb7fdd-qtgbt -- bash
$ ipython
from collections import Counter
import time
import ray
ray.init(redis_address="localhost:6379")
@ray.remote
def get_node_ip():
time.sleep(0.01)
return ray.services.get_node_ip_address()
%time Counter(ray.get([f.remote() for _ in range(100)]](https://image.slidesharecdn.com/distributedcomputingwithray-190503152105/85/Distributed-computing-with-Ray-Find-your-hyper-parameters-speed-up-your-Pandas-pipelines-and-much-more-43-320.jpg)


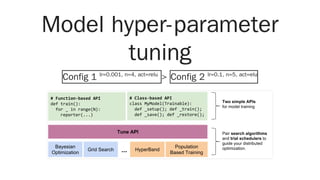


![Define the parameter space
Register the trainable function
Launch hyper-parameter search
Consider extracting your argparse arguments
spec = {
"stop": {
"mean_accuracy": 0.995,
"time_total_s": 600,
},
"config": {
"activation": grid_search(["relu", "elu", "tanh"]),
"learning_rate": tune.grid_search([0.001, 0.01, 0.1]),
},
}
tune.register_trainable("train_imagenet", my_tunable_function)
tune.run("train_imagenet", name="tune_imagenet_test", **spec)](https://image.slidesharecdn.com/distributedcomputingwithray-190503152105/85/Distributed-computing-with-Ray-Find-your-hyper-parameters-speed-up-your-Pandas-pipelines-and-much-more-50-320.jpg)

![Wrapping OpenAI gym environments
in actors
import gym
@ray.remote
class Simulator:
def __init__(self):
self.env = gym.make("SpaceInvaders-v0")
self.env.reset()
def step(self, action):
return self.env.step(action)
simulator = Simulator.remote()
# Take actions in the simulator
observations = []
observations.append(simulator.step.remote(0))
observations.append(simulator.step.remote(1))](https://image.slidesharecdn.com/distributedcomputingwithray-190503152105/85/Distributed-computing-with-Ray-Find-your-hyper-parameters-speed-up-your-Pandas-pipelines-and-much-more-53-320.jpg)



![Serial Parallel and distributedf
Remember
def heavy_computation(x):
# do something nice here
return x
results = [
heavy_computation(i)
for i in range(100)
]
@ray.remote
def heavy_computation(x):
# do something nice here
return x
ray.init()
results = ray.get([
heavy_computation.remote(i)
for i in range(100)
])](https://image.slidesharecdn.com/distributedcomputingwithray-190503152105/85/Distributed-computing-with-Ray-Find-your-hyper-parameters-speed-up-your-Pandas-pipelines-and-much-more-57-320.jpg)







































































