Downloaded 29 times







![© 2017 Mesosphere, Inc. All Rights Reserved.
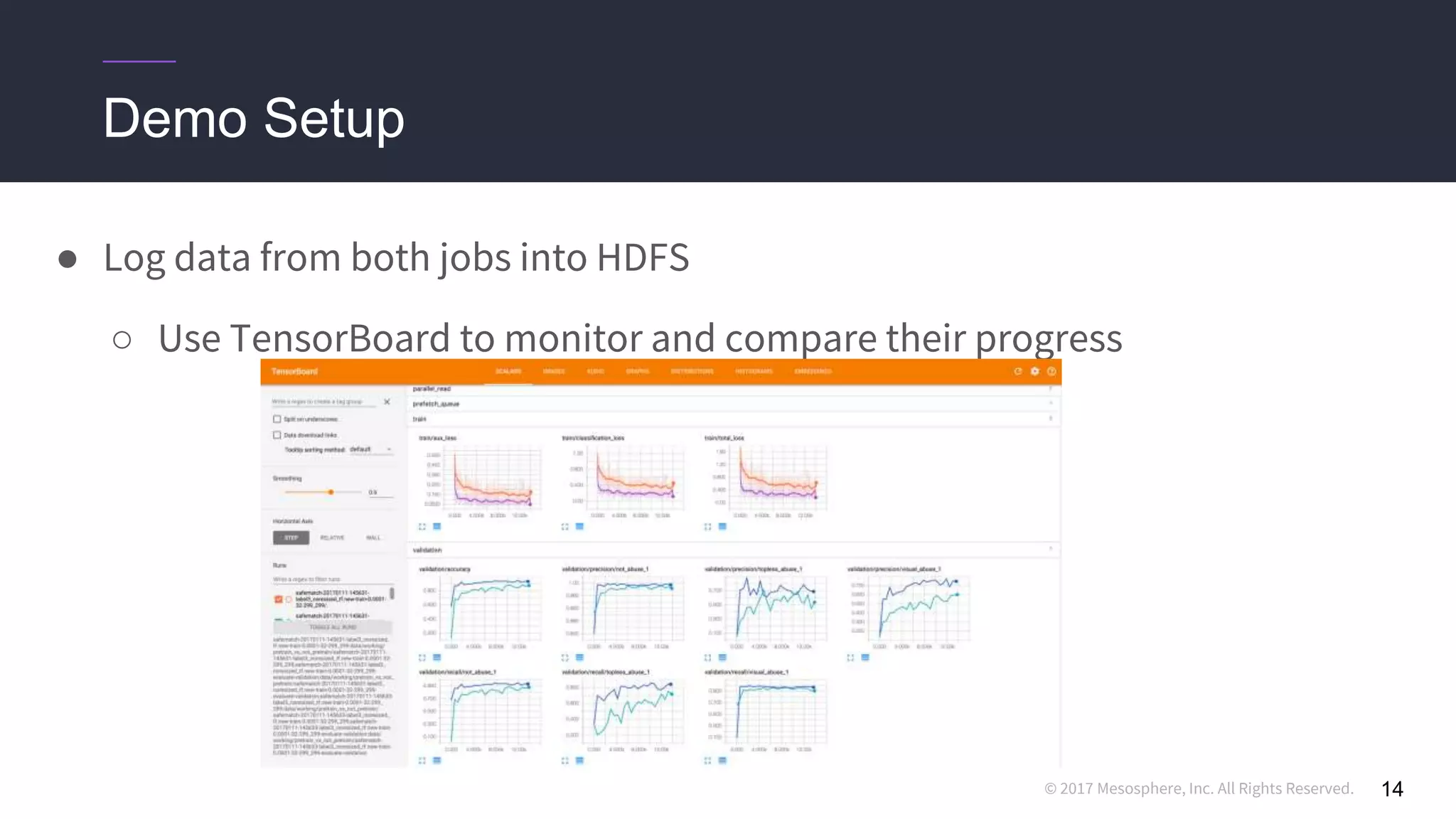
Challenges running distributed TensorFlow
20
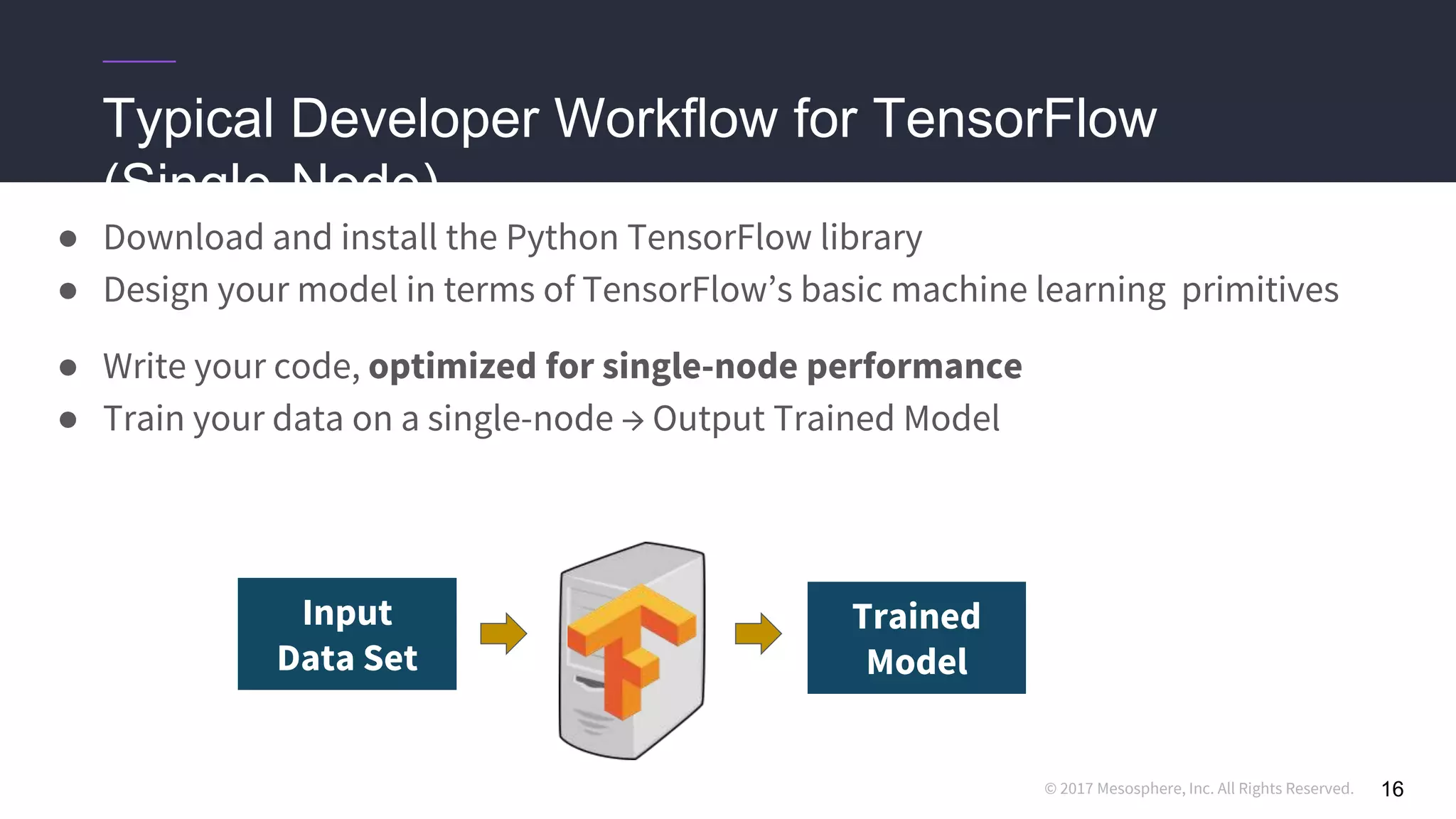
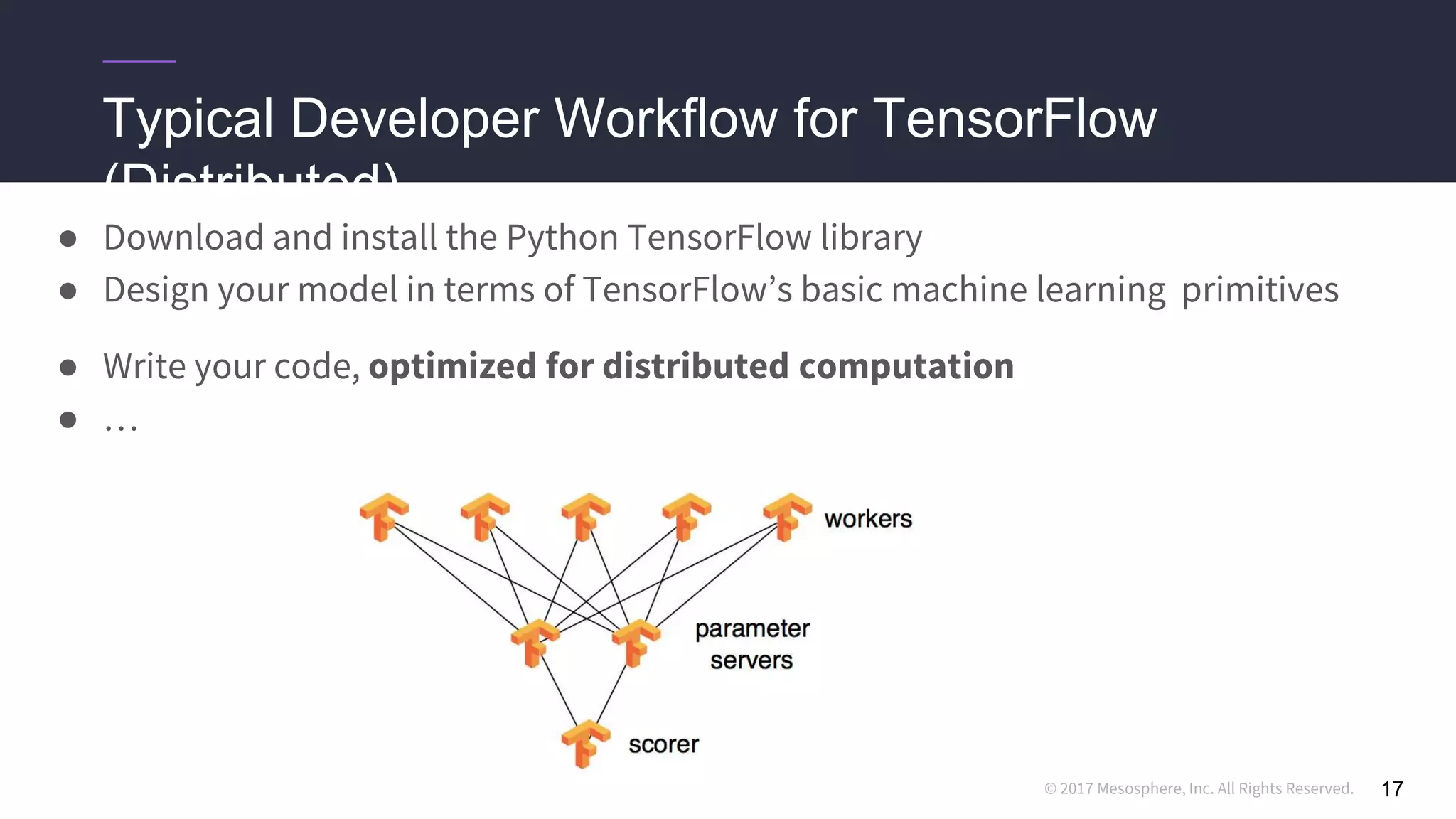
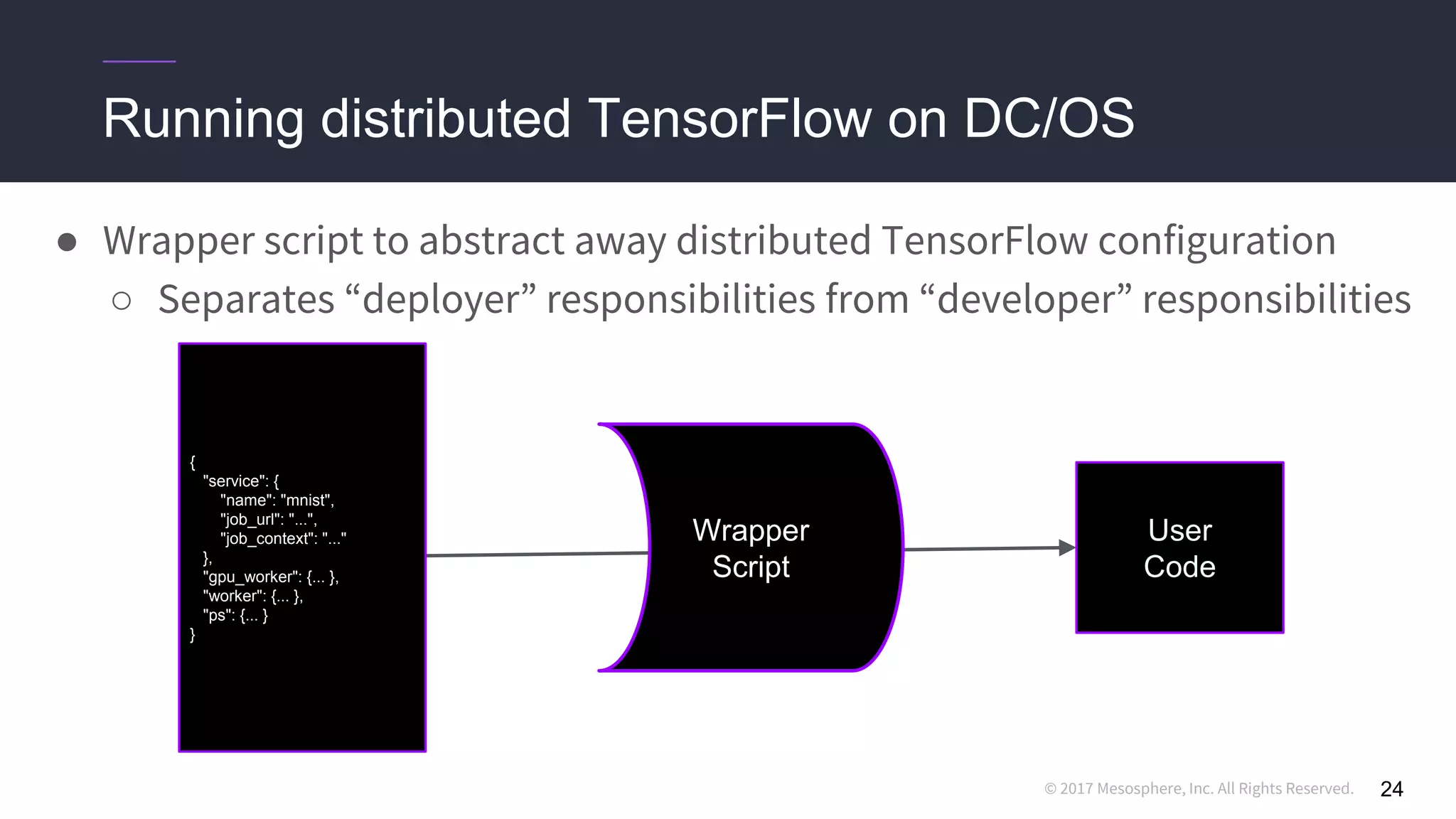
● Hard-coding a “ClusterSpec” is incredibly tedious
○ Users need to rewrite code for every job they want to run in a distributed setting
○ True even for code they “inherit” from standard models
tf.train.ClusterSpec({
"worker": [
"worker0.example.com:2222",
"worker1.example.com:2222",
"worker2.example.com:2222",
"worker3.example.com:2222",
"worker4.example.com:2222",
"worker5.example.com:2222",
...
],
"ps": [
"ps0.example.com:2222",
"ps1.example.com:2222",
"ps2.example.com:2222",
"ps3.example.com:2222",
...
]})
tf.train.ClusterSpec({
"worker": [
"worker0.example.com:2222",
"worker1.example.com:2222",
"worker2.example.com:2222",
"worker3.example.com:2222",
"worker4.example.com:2222",
"worker5.example.com:2222",
...
],
"ps": [
"ps0.example.com:2222",
"ps1.example.com:2222",
"ps2.example.com:2222",
"ps3.example.com:2222",
...
]})
tf.train.ClusterSpec({
"worker": [
"worker0.example.com:2222",
"worker1.example.com:2222",
"worker2.example.com:2222",
"worker3.example.com:2222",
"worker4.example.com:2222",
"worker5.example.com:2222",
...
],
"ps": [
"ps0.example.com:2222",
"ps1.example.com:2222",
"ps2.example.com:2222",
"ps3.example.com:2222](https://image.slidesharecdn.com/sparktensorflowmeetup-distributedtensorflowondc2fos-171215194741/75/Running-Distributed-TensorFlow-with-GPUs-on-Mesos-with-DC-OS-20-2048.jpg)


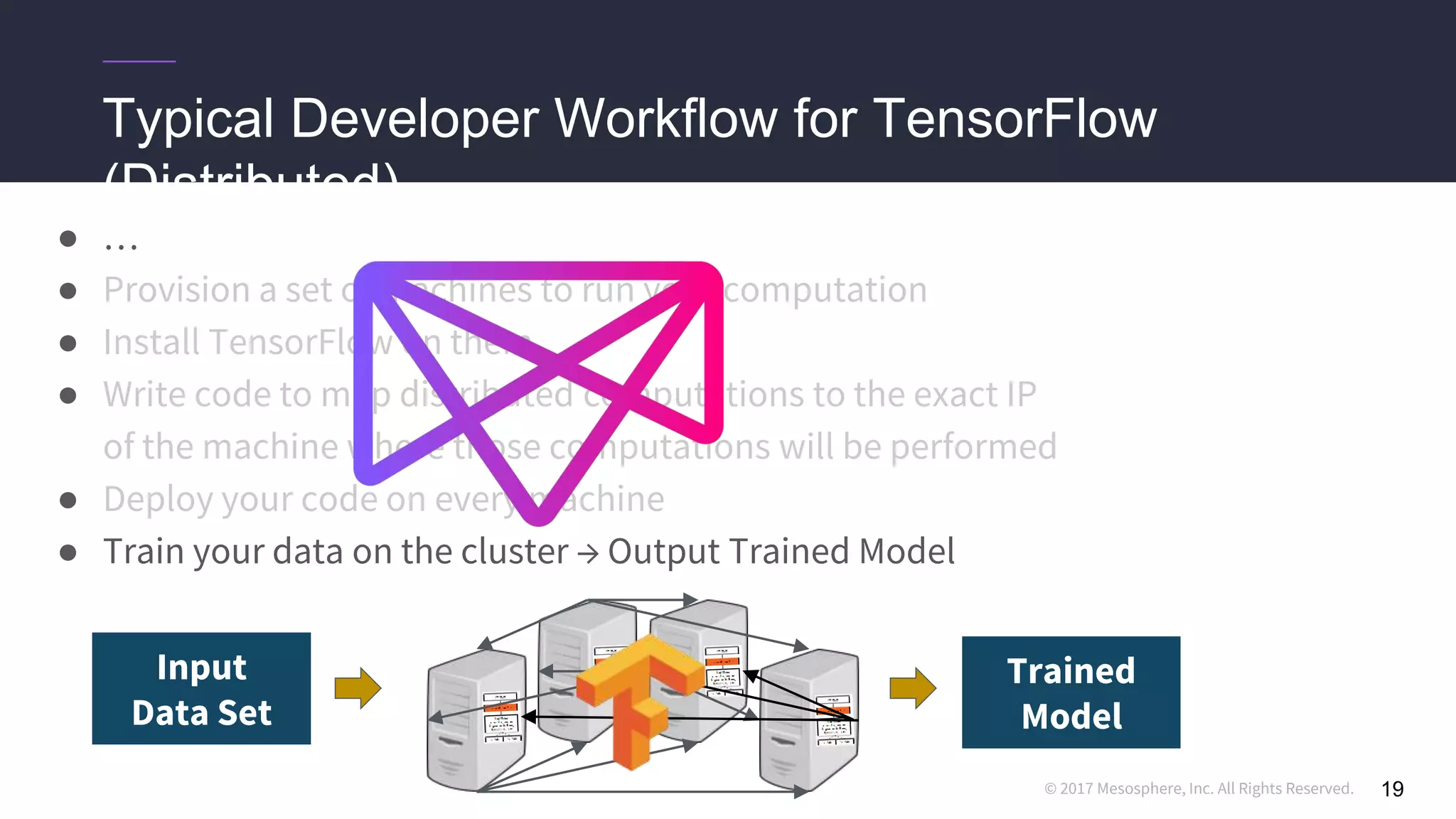
![© 2017 Mesosphere, Inc. All Rights Reserved.
Running distributed TensorFlow on DC/OS
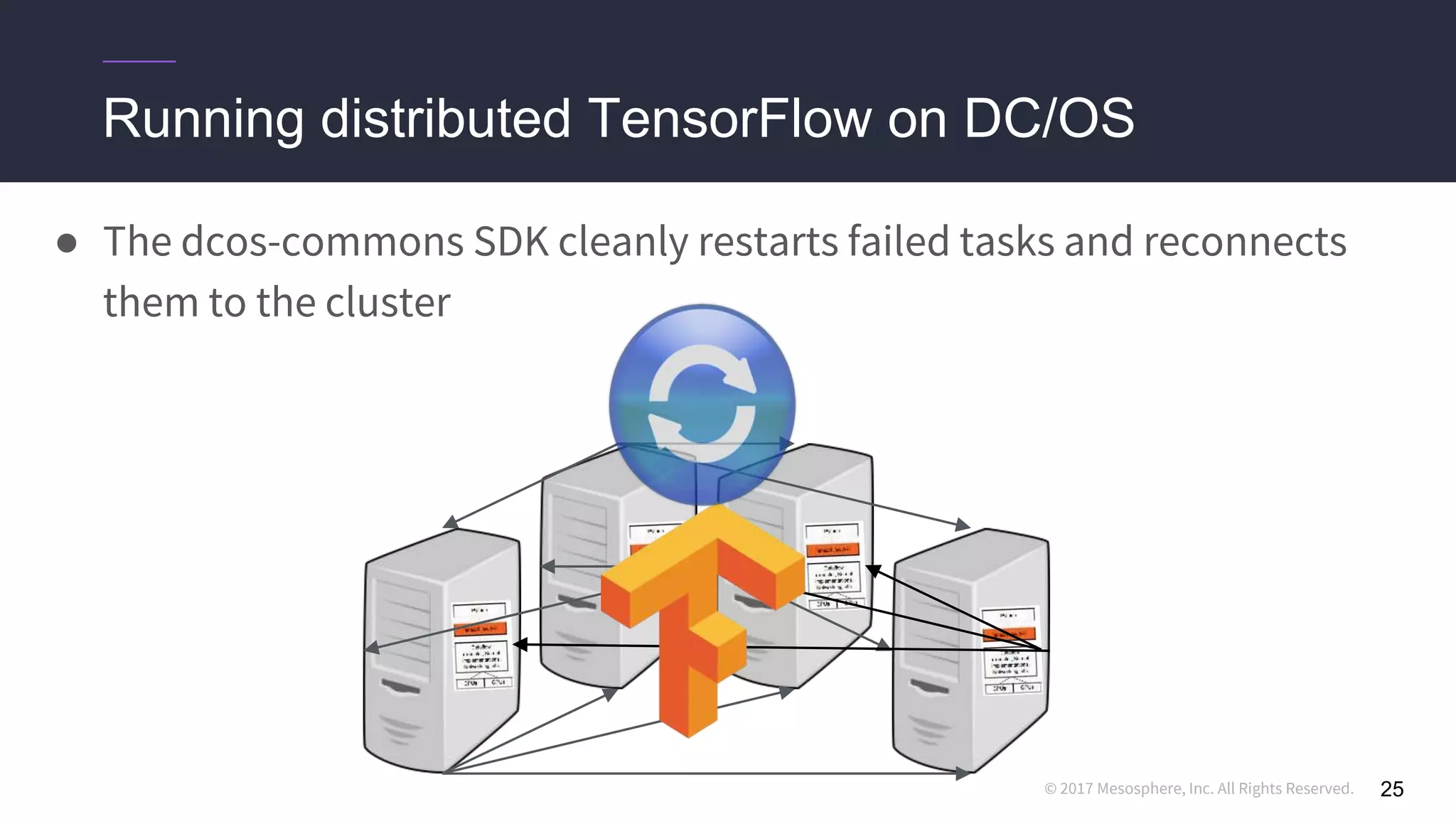
● We use the dcos-commons SDK to dynamically create the ClusterSpec
23
{
"service": {
"name": "mnist",
"job_url": "...",
"job_context": "..."
},
"gpu_worker": {... },
"worker": {... },
"ps": {... }
}
tf.train.ClusterSpec({
"worker": [
"worker0.example.com:2222",
"worker1.example.com:2222",
"worker2.example.com:2222",
"worker3.example.com:2222",
"worker4.example.com:2222",
"worker5.example.com:2222",
...
],
"ps": [
"ps0.example.com:2222",
"ps1.example.com:2222",
"ps2.example.com:2222",
"ps3.example.com:2222",
...
]})
tf.train.ClusterSpec({
"worker": [
"worker0.example.com:2222",
"worker1.example.com:2222",
"worker2.example.com:2222",
"worker3.example.com:2222",
"worker4.example.com:2222",
"worker5.example.com:2222",
...
],
"ps": [
"ps0.example.com:2222",
"ps1.example.com:2222",
"ps2.example.com:2222",
"ps3.example.com:2222",
...
]})
tf.train.ClusterSpec({
"worker": [
"worker0.example.com:2222",
"worker1.example.com:2222",
"worker2.example.com:2222",
"worker3.example.com:2222",
"worker4.example.com:2222",
"worker5.example.com:2222",
...
],
"ps": [
"ps0.example.com:2222",
"ps1.example.com:2222",
"ps2.example.com:2222",
"ps3.example.com:2222](https://image.slidesharecdn.com/sparktensorflowmeetup-distributedtensorflowondc2fos-171215194741/75/Running-Distributed-TensorFlow-with-GPUs-on-Mesos-with-DC-OS-23-2048.jpg)




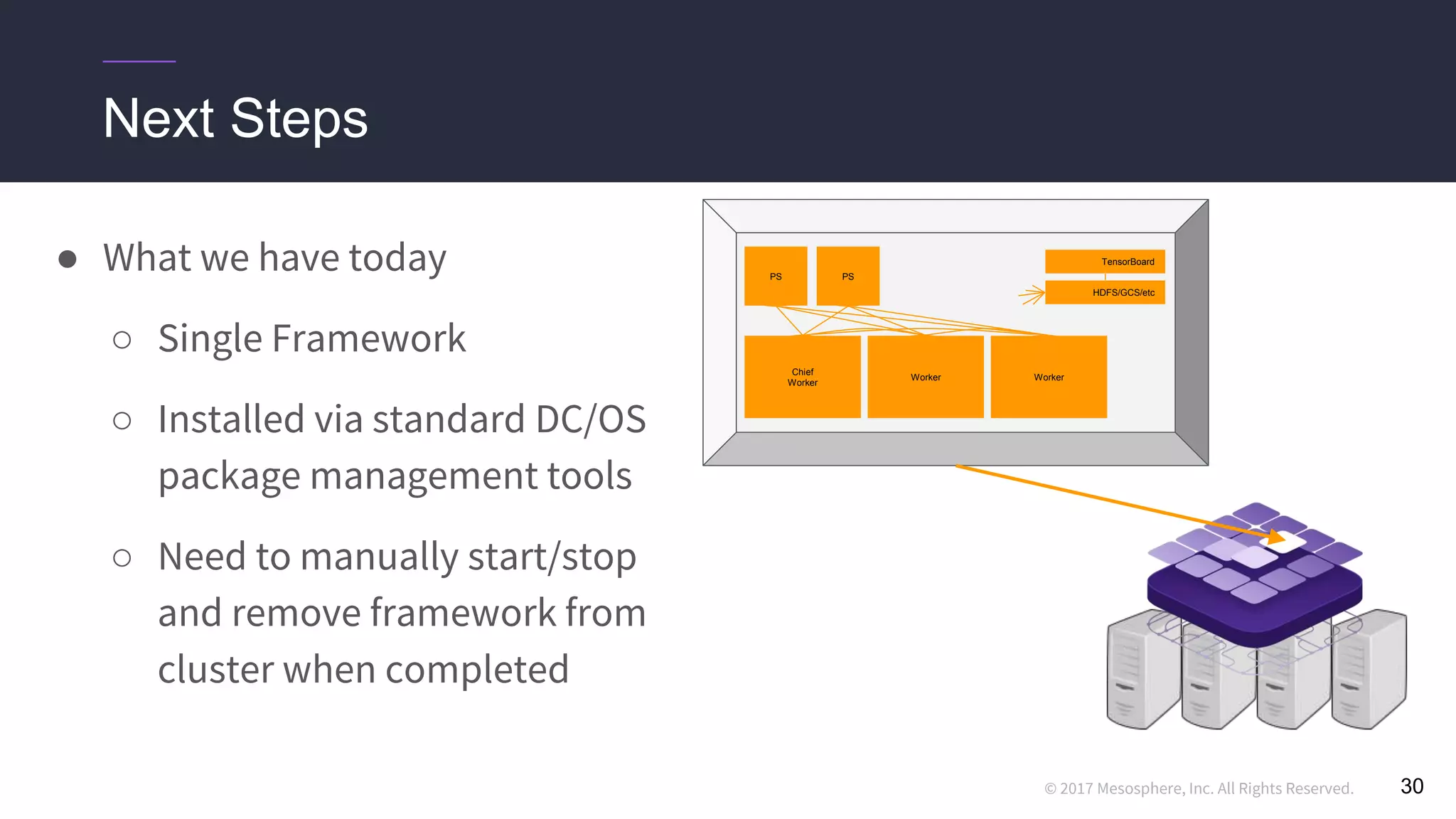
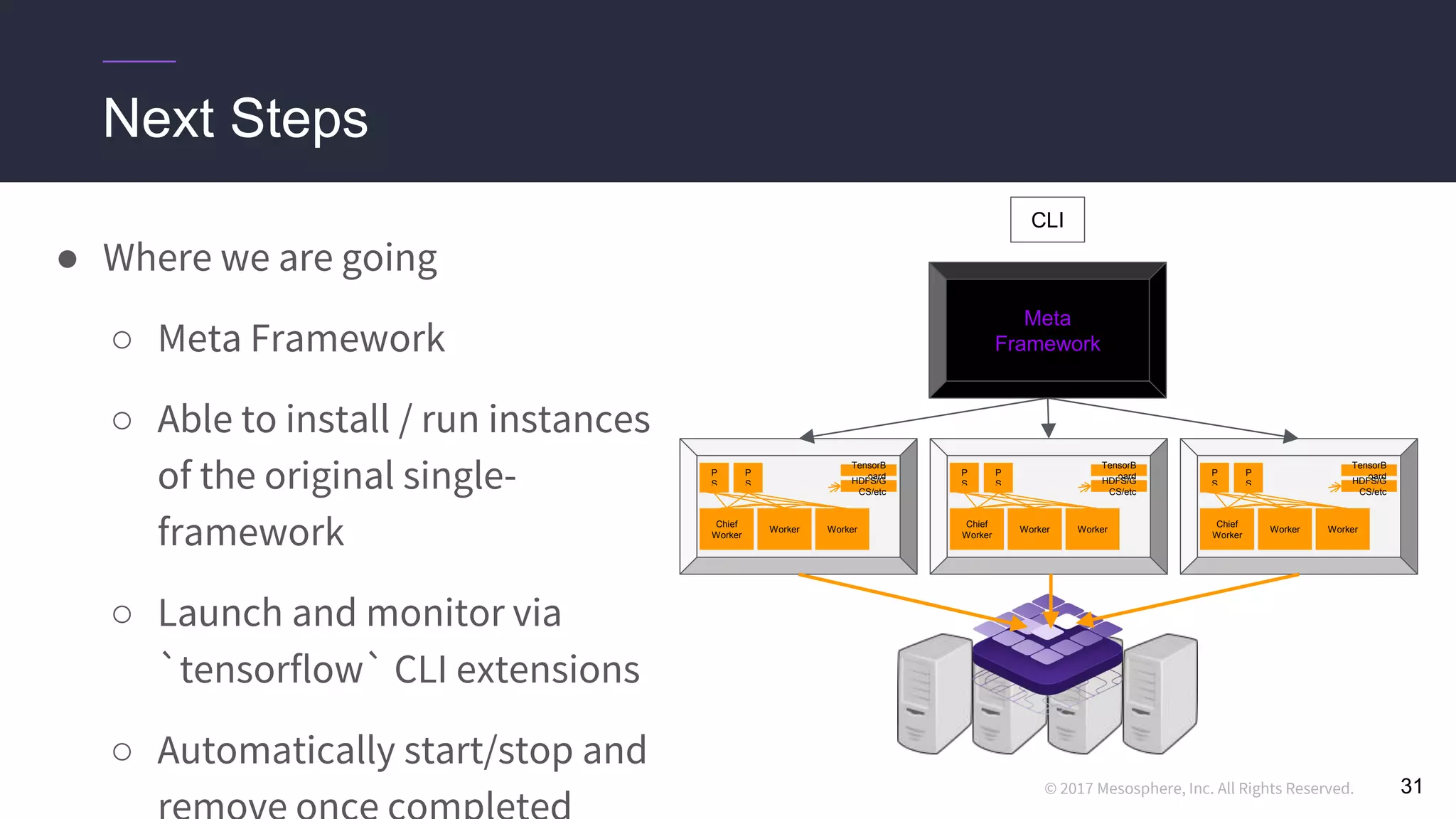




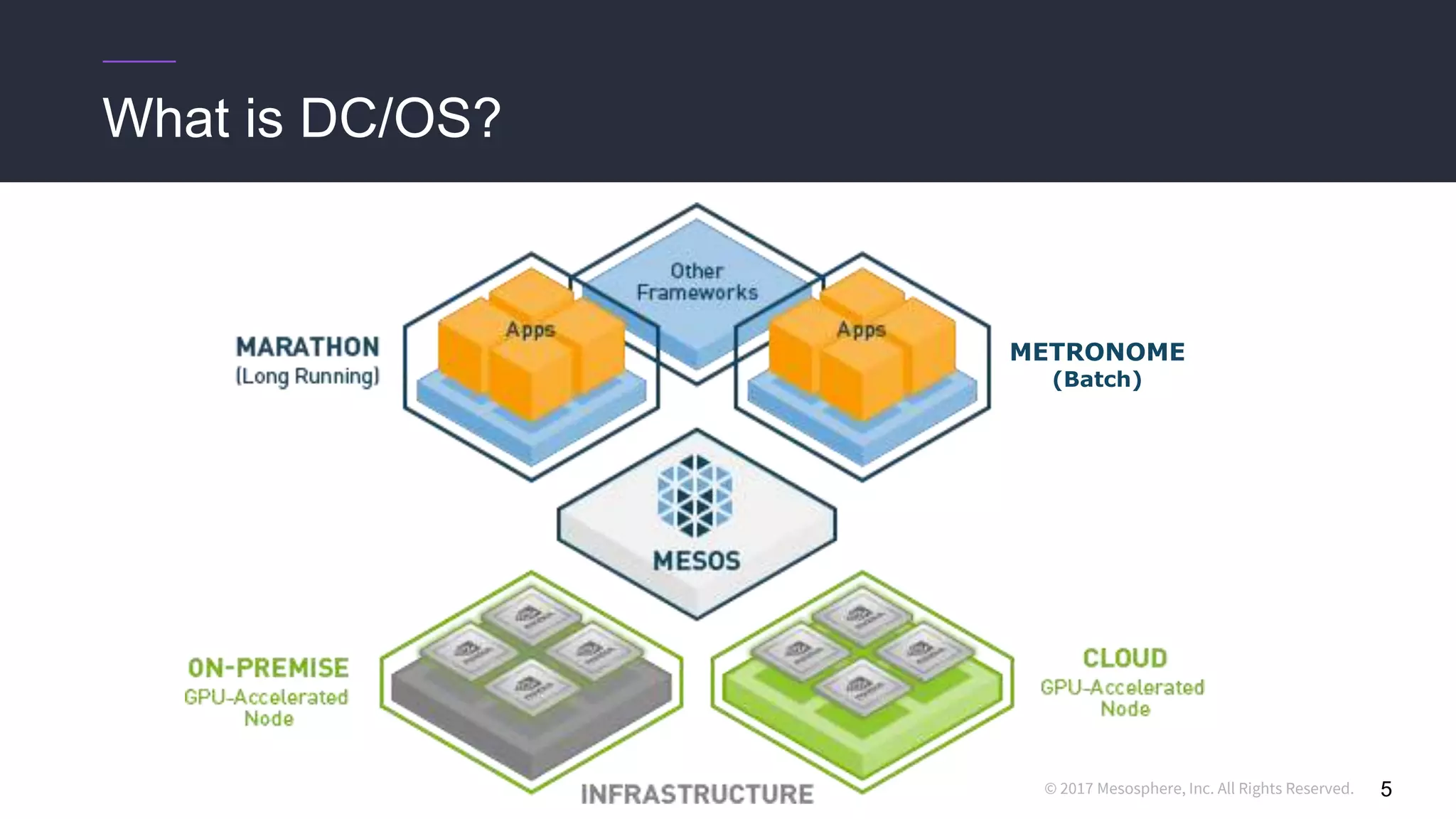
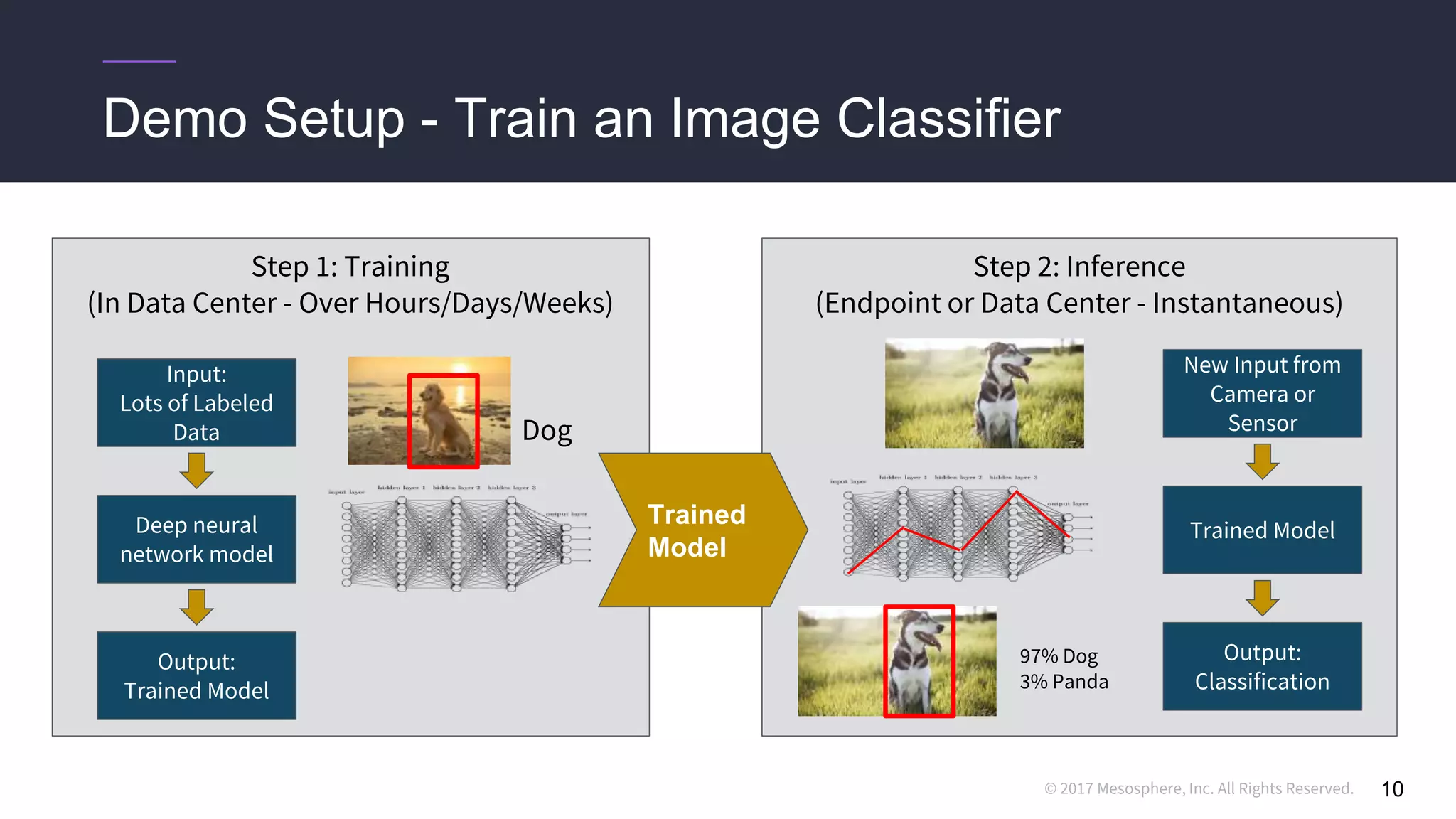
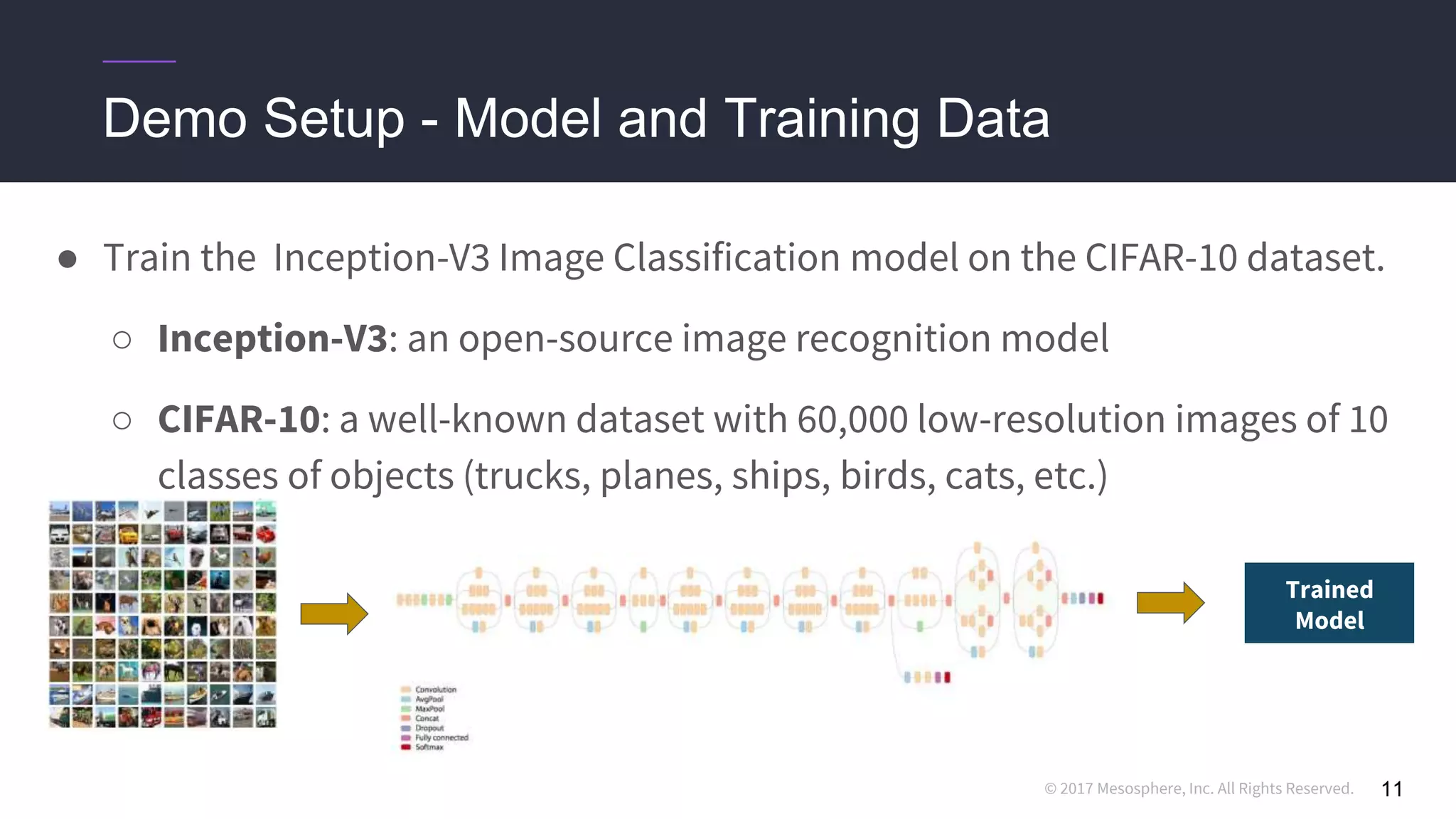
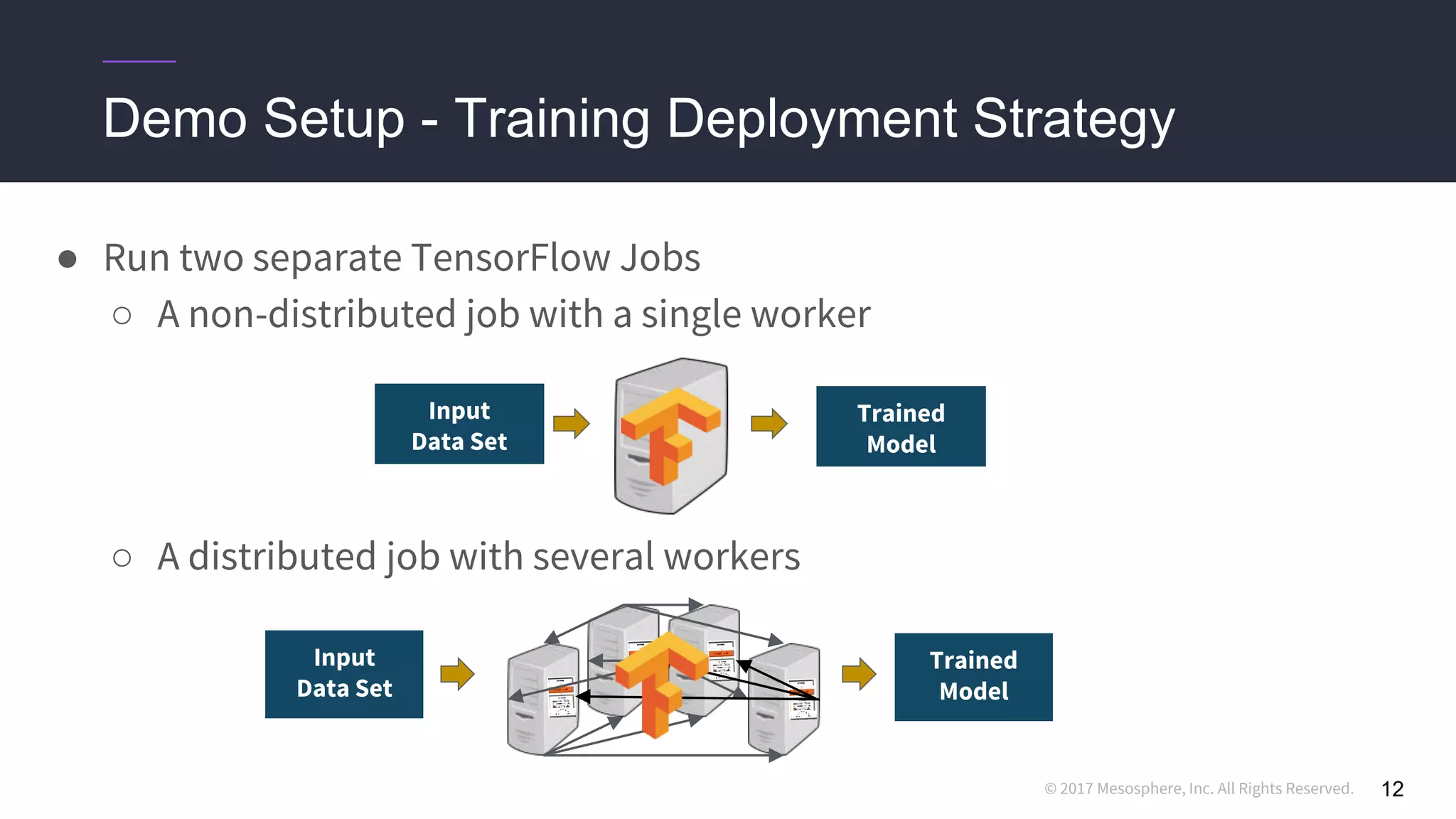
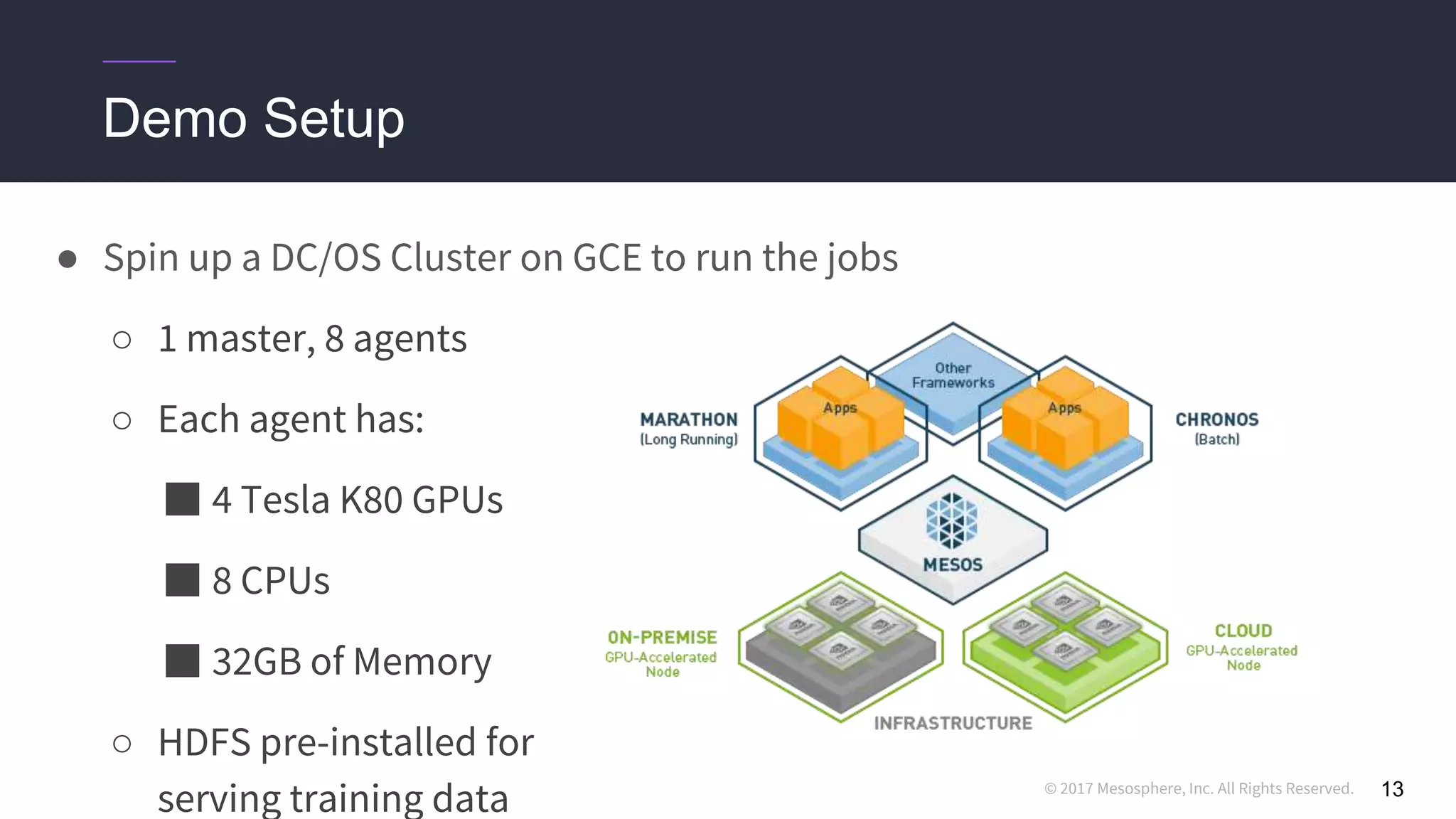
This document discusses running distributed TensorFlow jobs on the DC/OS platform. It begins with an overview of typical TensorFlow development workflows for single-node and distributed training. It then outlines some challenges of running distributed TensorFlow, such as needing to hard-code cluster configuration details. The document explains how DC/OS addresses these challenges by dynamically generating cluster configurations and handling failures gracefully. It demonstrates deploying non-distributed and distributed TensorFlow jobs on a DC/OS cluster to train an image classification model.














































































![Governance, Deployment & Methodologies for Agentic Automation [2/3]](https://cdn.slidesharecdn.com/ss_thumbnails/agenticcommunityseries-day2-251112135038-a386476d-thumbnail.jpg?width=640&height=640&fit=bounds)








