The document discusses the challenges data scientists face when deploying models to production, emphasizing the role of platform engineers in optimizing data processing and query performance. It outlines various data types, the importance of handling failures gracefully, and proposes data projects to help the platform team improve observability and resource allocation. It also highlights the need for data engineers to adapt to distributed systems and manage inconsistencies in data effectively.





![Why is entity resolution so hard?
def compare(self, batch):
# create pairs from batch and perform pairwise comparison
for first, second in combinations(batch.values(), 2):
if compare_pair(first, second):
# Check if the reference has a canonical and *UNIQUE* id
first_canonical = self.canonical_ids.get(first["guid"])
second_canonical = self.canonical_ids.get(second["guid"])
smallest_id = int(min(first_canonical, second_canonical))
# Update the guids for both references
self.canonical_ids[first["guid"]] = smallest_id
self.canonical_ids[second["guid"]] = smallest_id
# Update other references that resolve to the same guid
for reference, guid in self.canonical_ids.items():
if guid in [first["guid"], second["guid"]]:
self.canonical_ids[reference] = smallest_id
Turned out it was
actually a data
warehouse not a
database.
No UUIDs!](https://image.slidesharecdn.com/datasecretsfromaplatformengineer-241111193849-c3485589/85/Data-Secrets-From-a-Platform-Engineer-Bilbro-6-320.jpg)



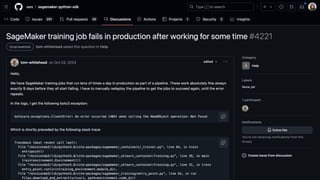










![Failure is the norm
import numpy as np
import tensorflow as tf
# Generate some sample data
x_train = np.random.random(( 100, 10))
y_train = np.random.random(( 100,))
# Create a simple model
model = tf.keras.Sequential([
tf.keras.layers.Dense( 64, activation= 'relu', input_shape=( 10,)),
tf.keras.layers.Dense( 1)
])
# Compile the model
model.compile(optimizer= 'adam', loss='mse')
# Create a checkpoint callback
checkpointer = tf.keras.callbacks.ModelCheckpoint(
filepath=CHECKPOINT_STORE,
save_weights_only= True,
verbose= 1
)
# Train the model with checkpointing
model.fit(x_train, y_train, epochs= 10, callbacks=[ checkpointer ])
# Retrieve that checkpoint
model.load_weights( "checkpoints/110720240005.ckpt" )
Handle exceptions and failures
gracefully.
Periodically save computation
state so we can recover.
Replicate data and services
across multiple nodes.](https://image.slidesharecdn.com/datasecretsfromaplatformengineer-241111193849-c3485589/85/Data-Secrets-From-a-Platform-Engineer-Bilbro-21-320.jpg)












































































