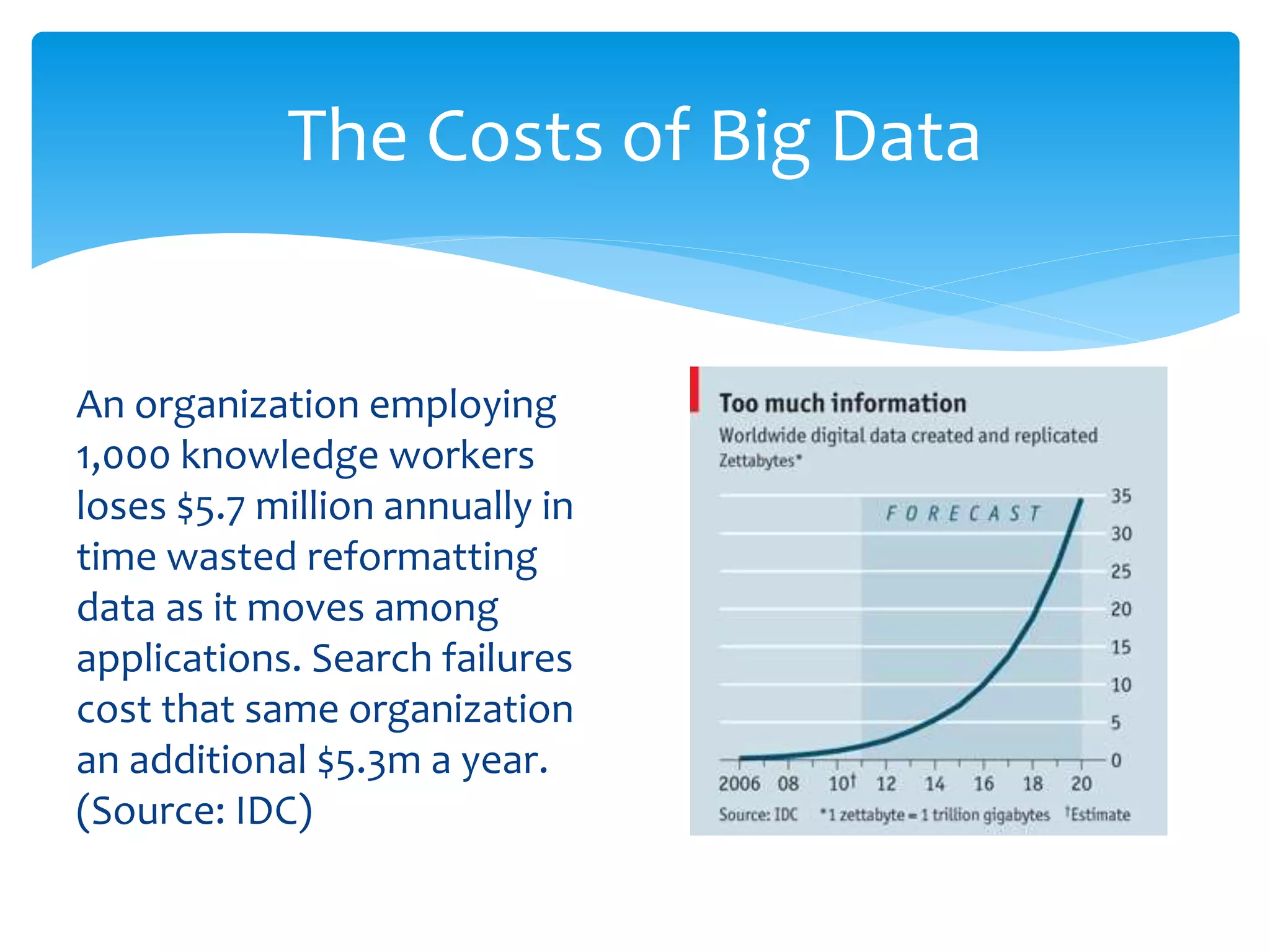
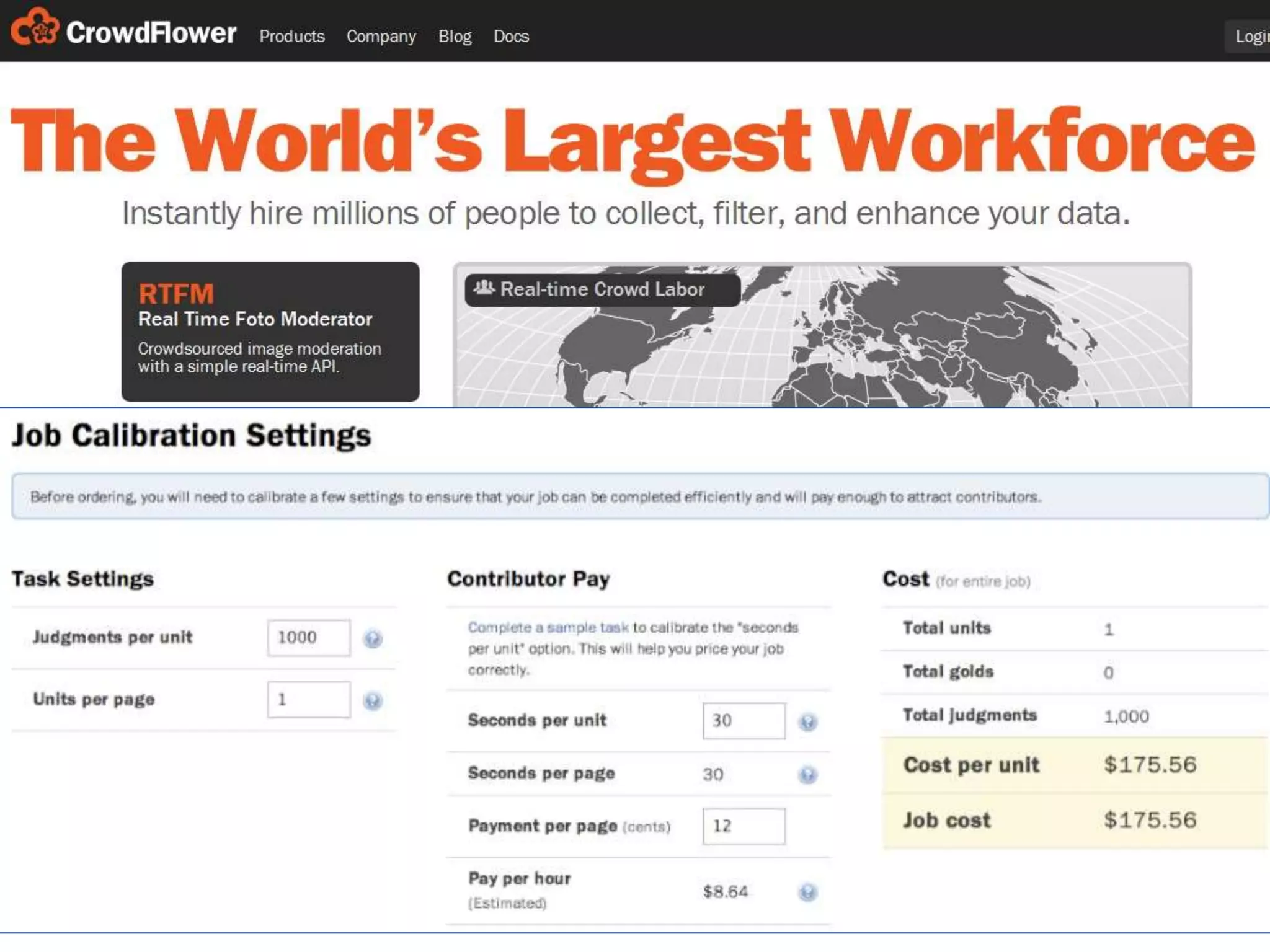
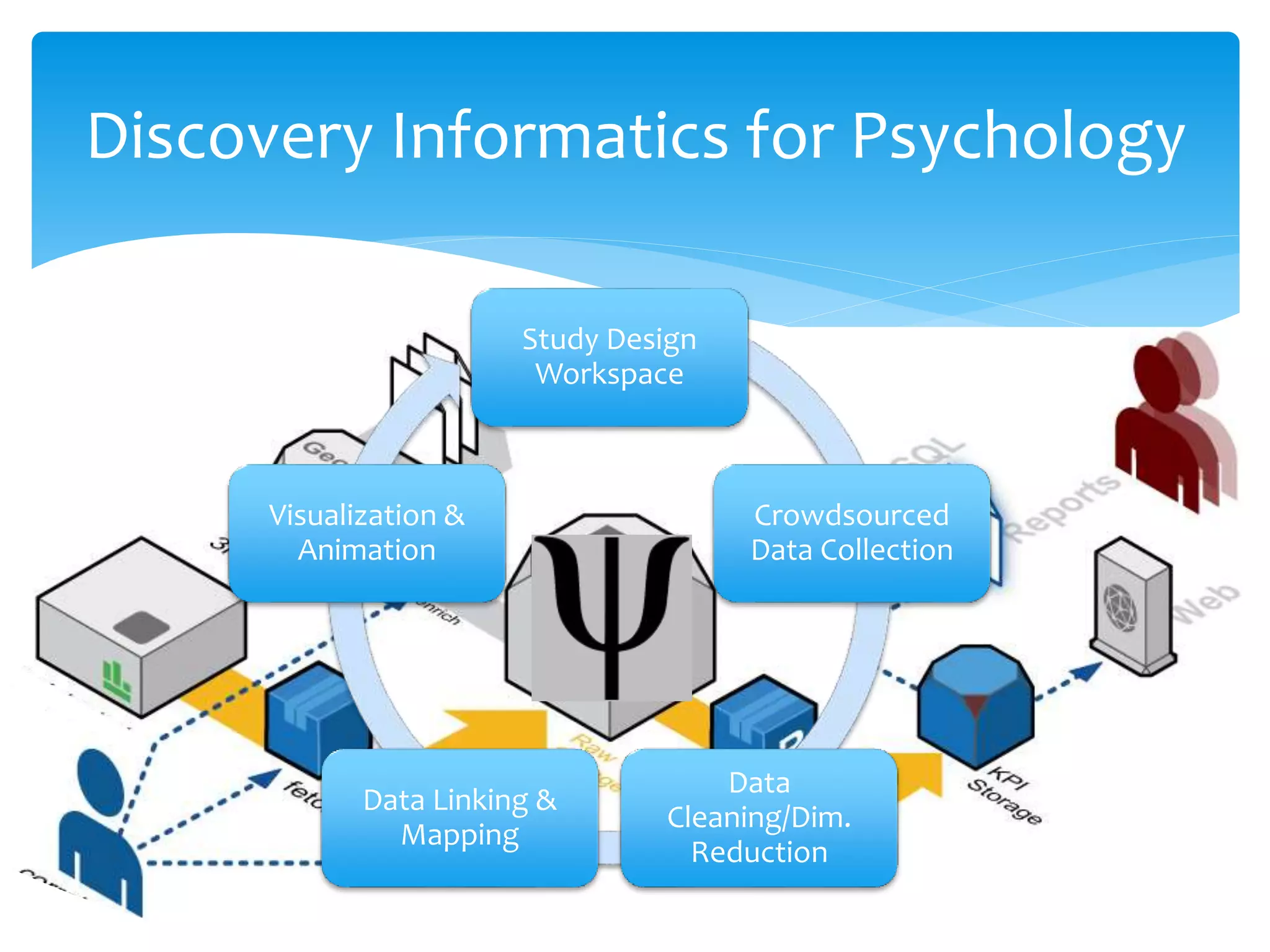
Jeff Stanton discusses discovery informatics for analyzing large datasets. He notes that the amount of data is growing rapidly but IT spending is not keeping pace. Traditional data exploration methods are insufficient for "big data." Emerging alternatives are needed for creating and analyzing large datasets. Stanton provides examples of big data in retail and jobs in the field. He also discusses costs of data reformatting and search failures. The document explores using crowdsourcing, natural language processing, and visualization tools to translate and validate psychological assessment items across languages and cultures.




















































![Big Data [sorry] & Data Science: What Does a Data Scientist Do?](https://cdn.slidesharecdn.com/ss_thumbnails/dslatcloudmsevent20130125-130126065651-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)















































