Download as PDF, PPTX





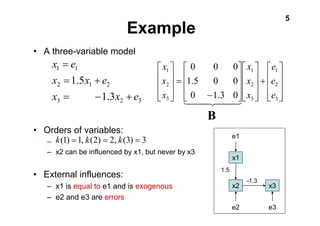



















DirectLiNGAM is a new non-Gaussian estimation method for the LiNGAM model that directly estimates the variable ordering without using ICA. It iteratively identifies exogenous variables using independence tests between each variable and its residuals from regression on other variables. This allows it to estimate the ordering in a fixed number of steps, with no algorithmic parameters, convergence issues, or scale dependence like previous ICA-based methods. It was shown to estimate the correct causal ordering on a real-world socioeconomic dataset, matching domain knowledge better than alternative methods like ICA-LiNGAM, PC algorithm, and GES.



































![Ica group 3[1]](https://cdn.slidesharecdn.com/ss_thumbnails/icagroup31-191026172214-thumbnail.jpg?width=640&height=640&fit=bounds)





































