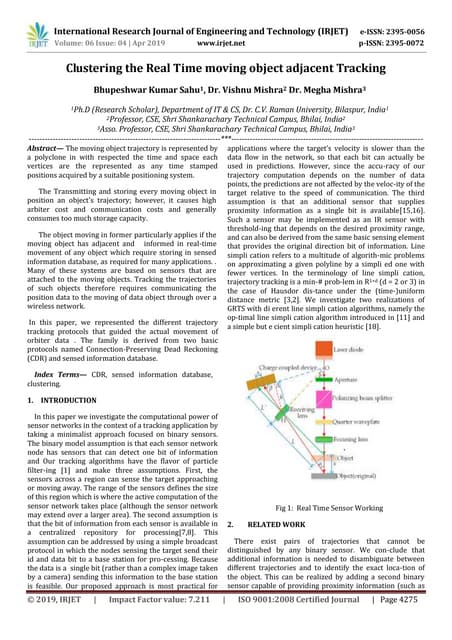






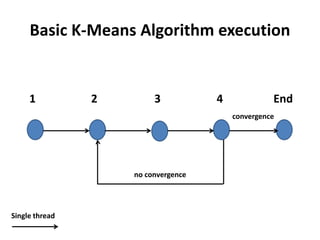



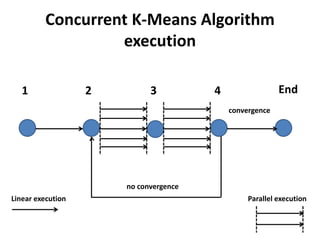








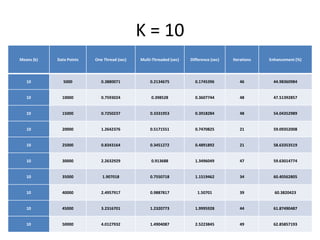
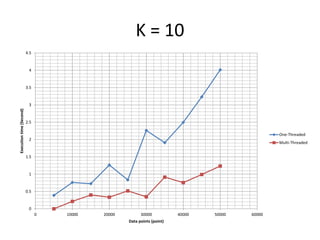
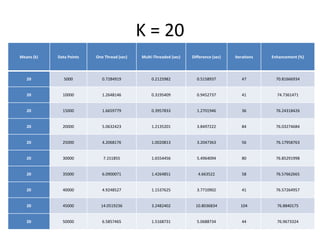
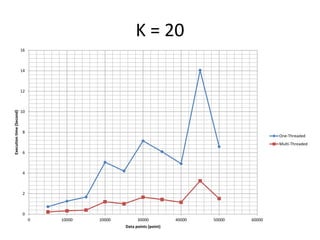
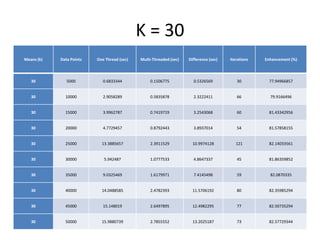
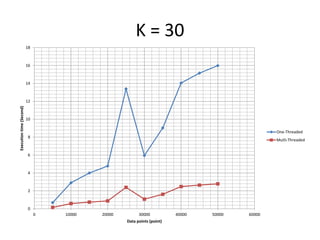
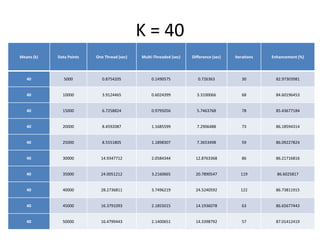
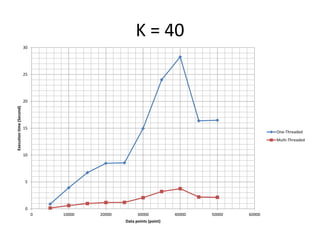









The document discusses enhancing the K-Means clustering algorithm performance by converting it to a concurrent version using multi-threading. It identifies that steps 2 and 3 of the basic K-Means algorithm contain independent sub-tasks that can be executed in parallel. The implementation in C# uses the Parallel class to parallelize the processing. Analysis shows the concurrent version runs 70-87% faster with increasing performance gains at higher numbers of clusters and data points. Future work could parallelize the full K-Means algorithm.