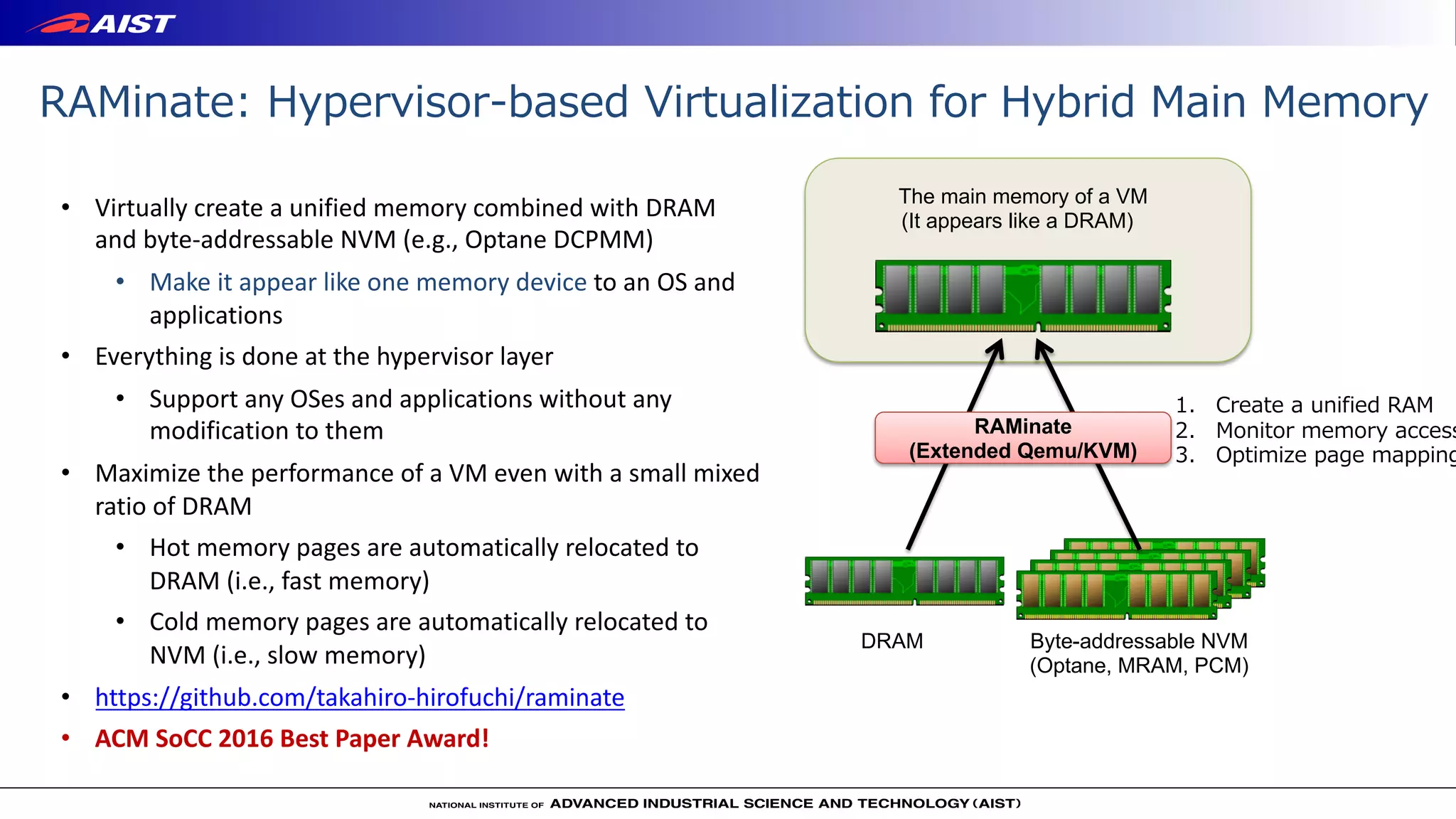
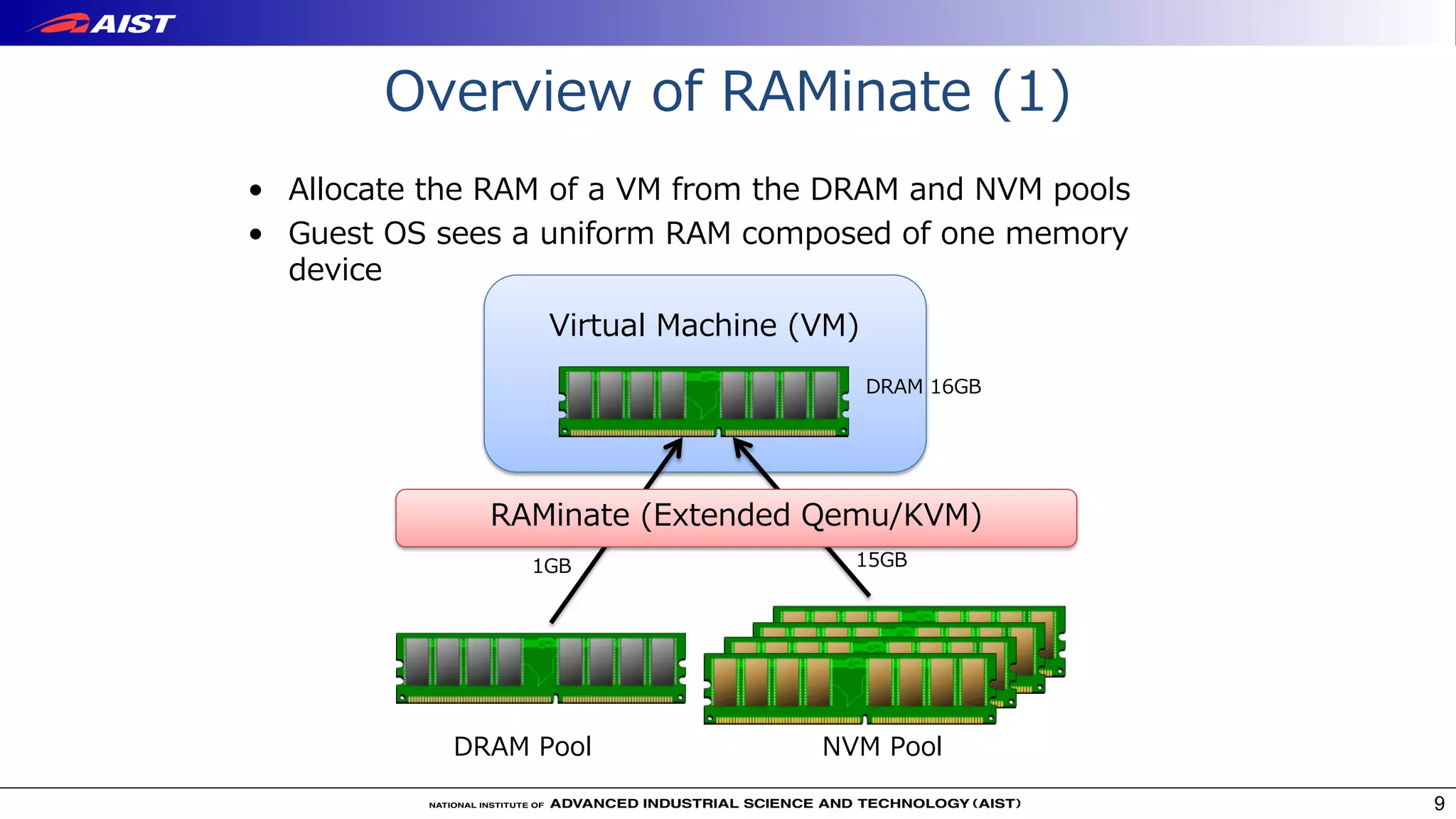
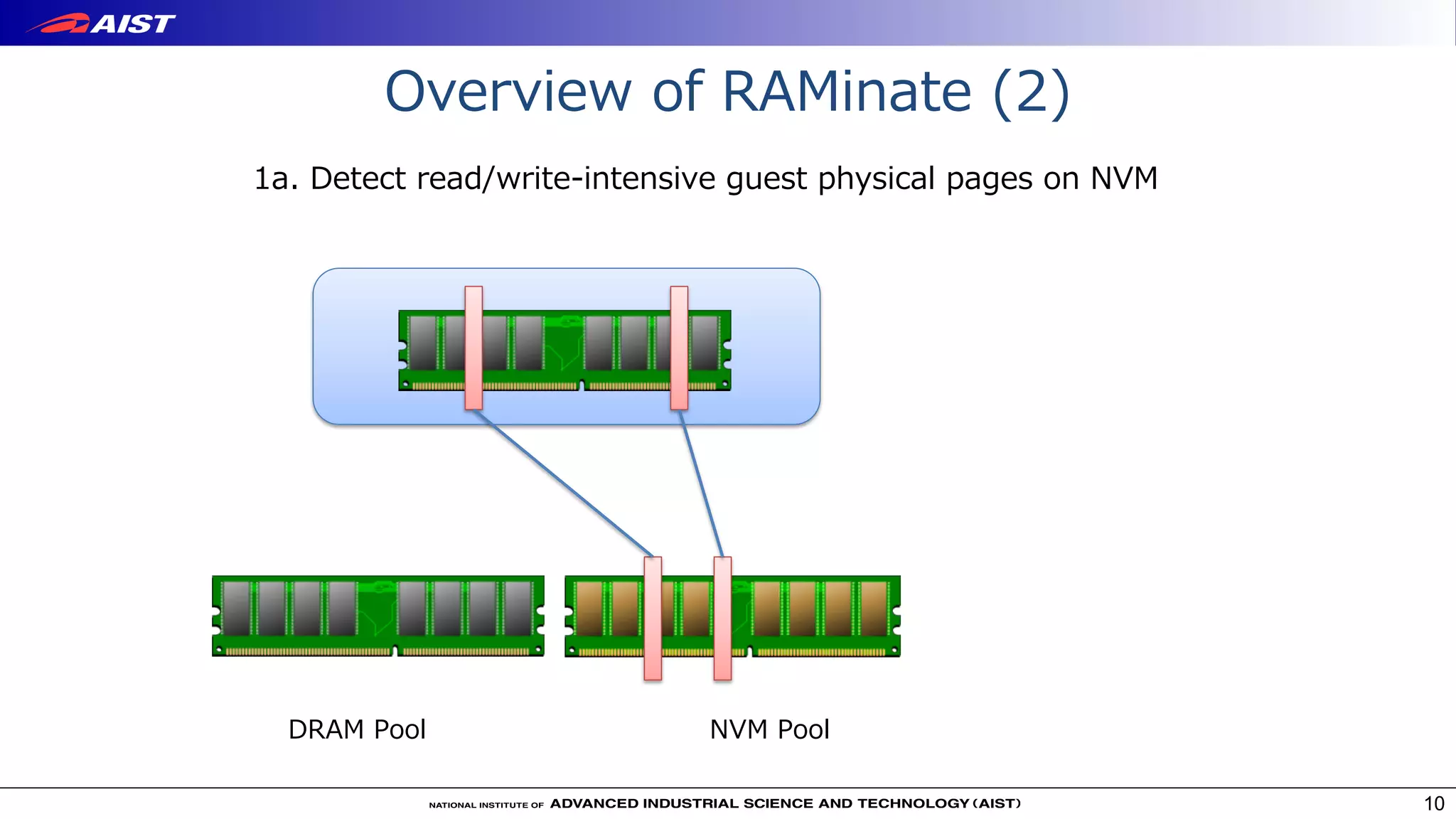
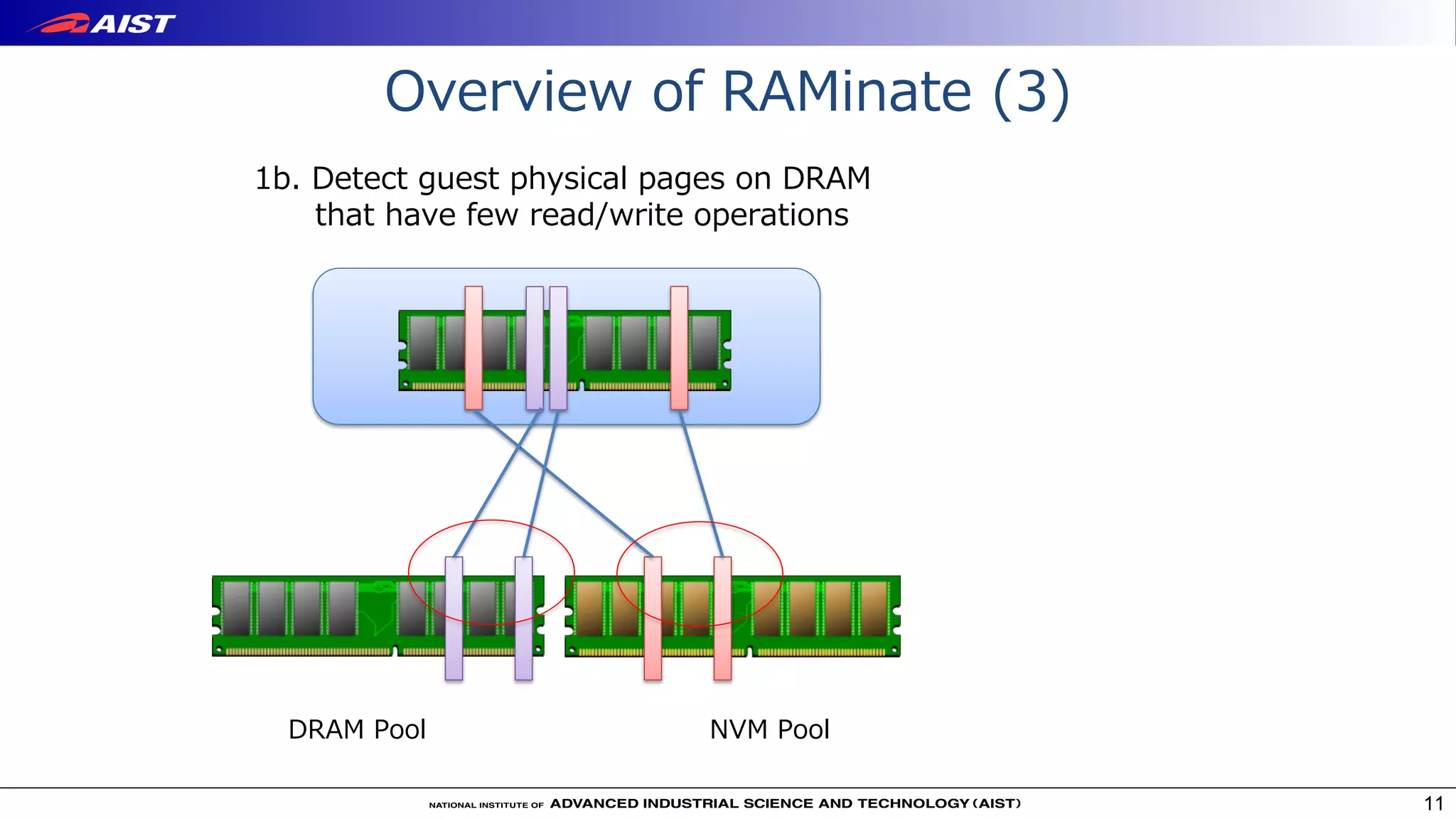
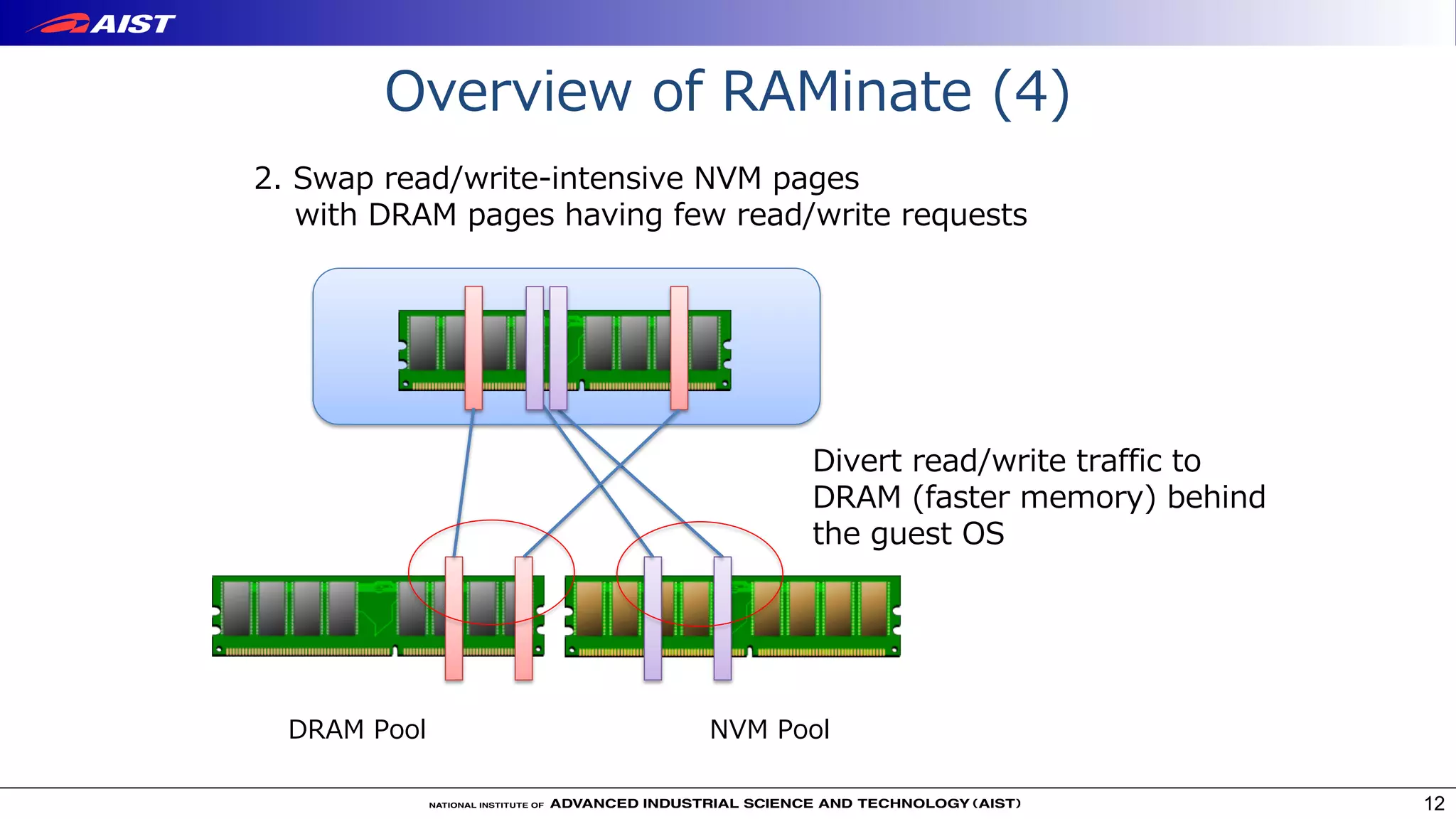
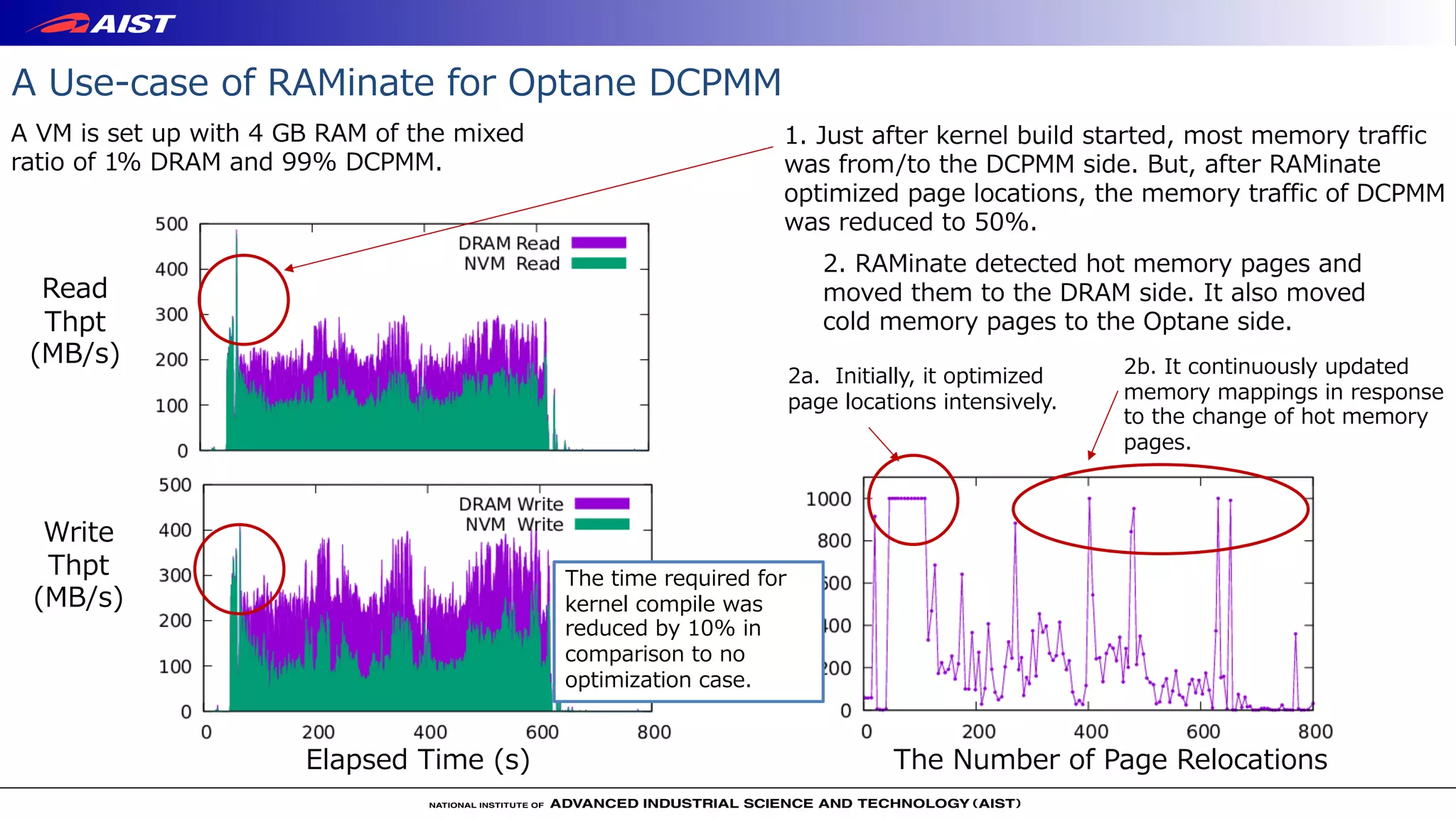
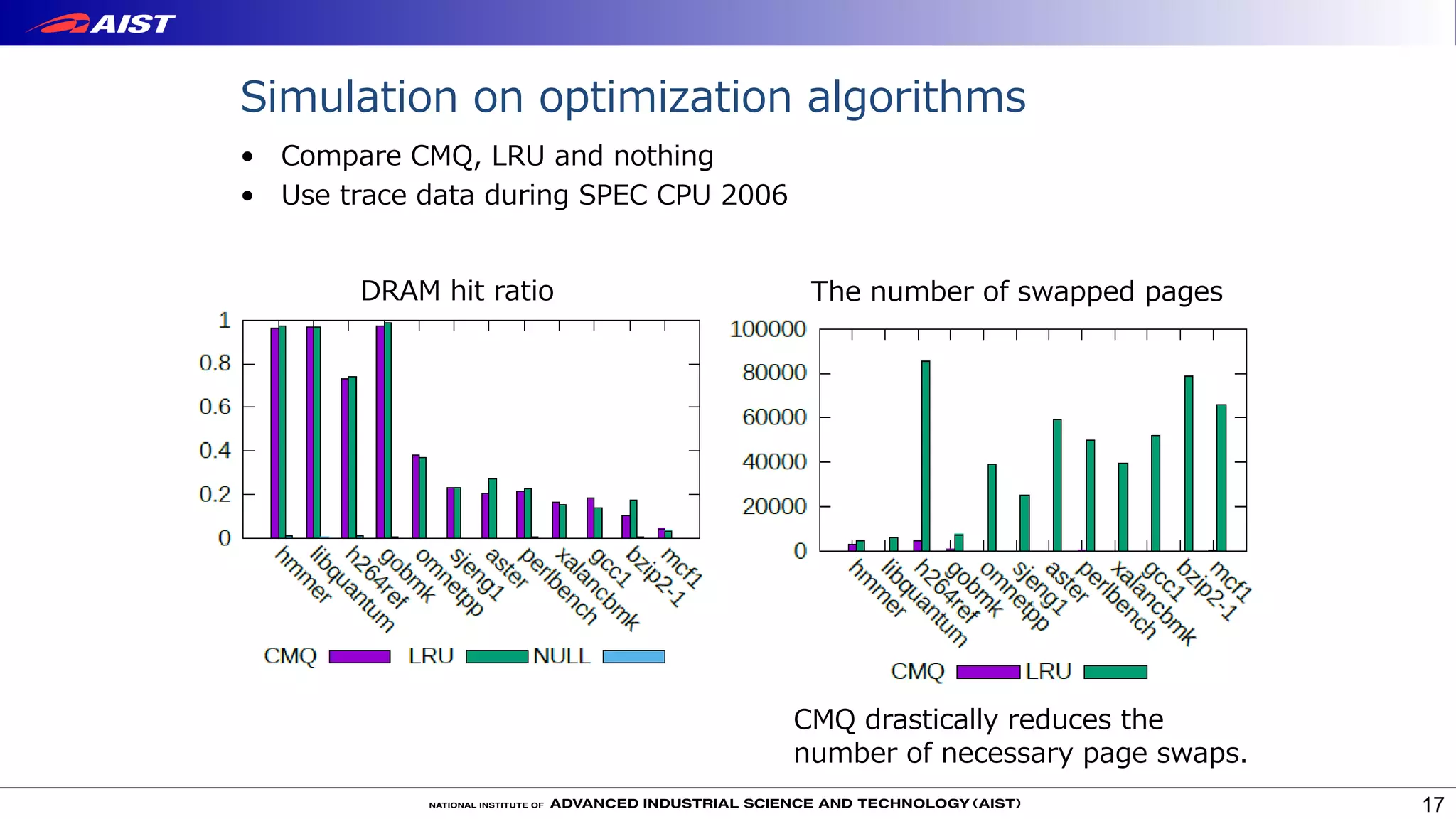
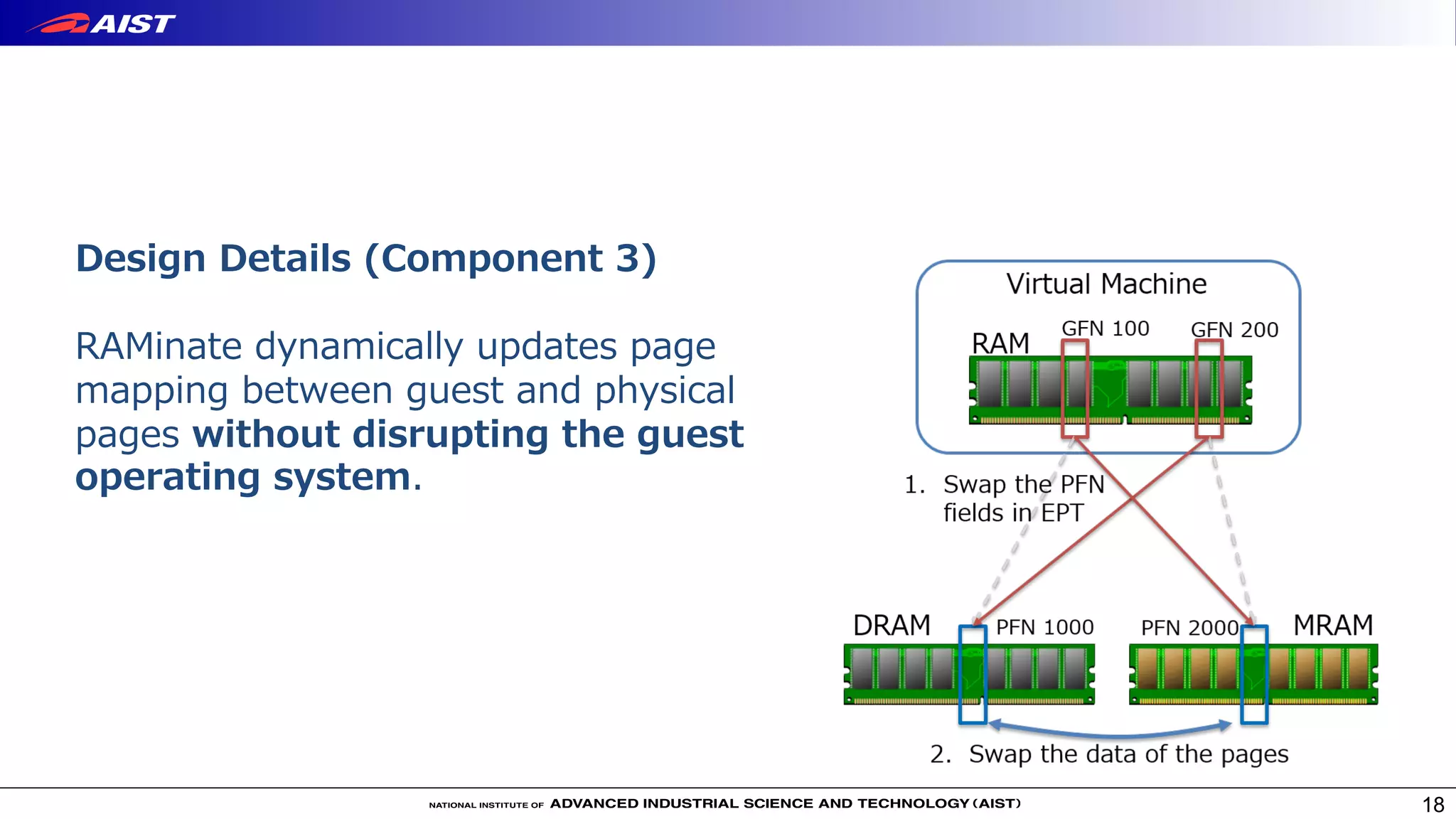
Virtualization techniques like RAMinate can unify emerging non-volatile memory devices with DRAM into a single memory space seen by the operating system. RAMinate uses a hypervisor to optimize page mapping and relocate data between faster DRAM and slower non-volatile memory. The presentation also describes software-based and FPGA-based emulation approaches for evaluating hybrid memory systems and new error permissive computing designs that aim to improve performance by controlling hardware error rates.



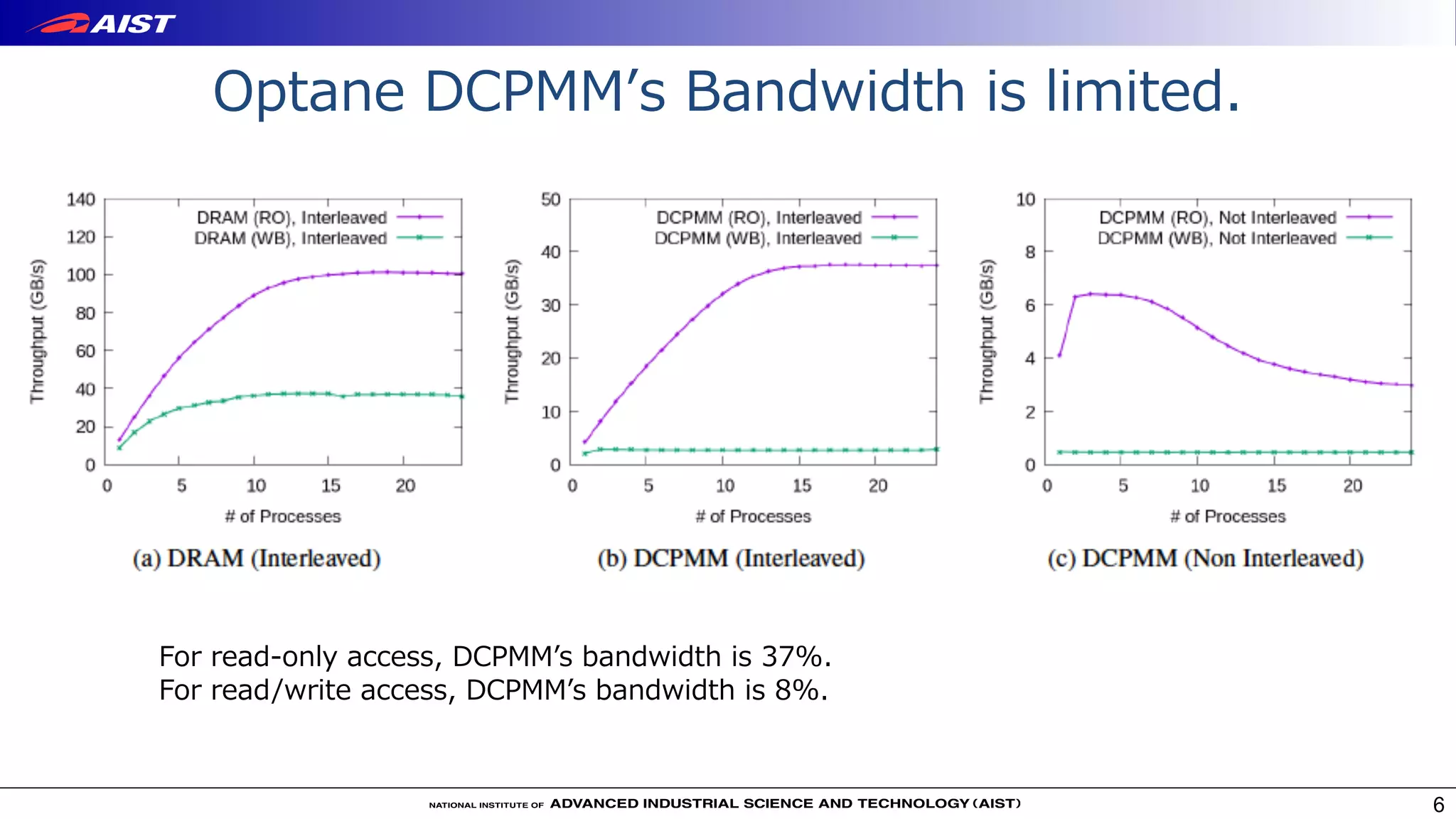
![Optane DCPMMʼs Latency is higher than DRAM.
5
For read-only access, DCPMMʼs latency is 4 times larger.
For read/write access, DCPMMʼs latency is 4.1 times larger.
[1] A Prompt Report on the Performance of Intel Optane DC Persistent Memory Module, Takahiro Hirofuchi, Ryousei
Takano, IEICE Transactions on Information and Systems, Vol.E103-D, No.5, IEICE, May 2020, Paper (arXiv)](https://image.slidesharecdn.com/coolchips2020-invited-talk-public-200513085916/75/Virtualization-for-Emerging-Memory-Devices-5-2048.jpg)














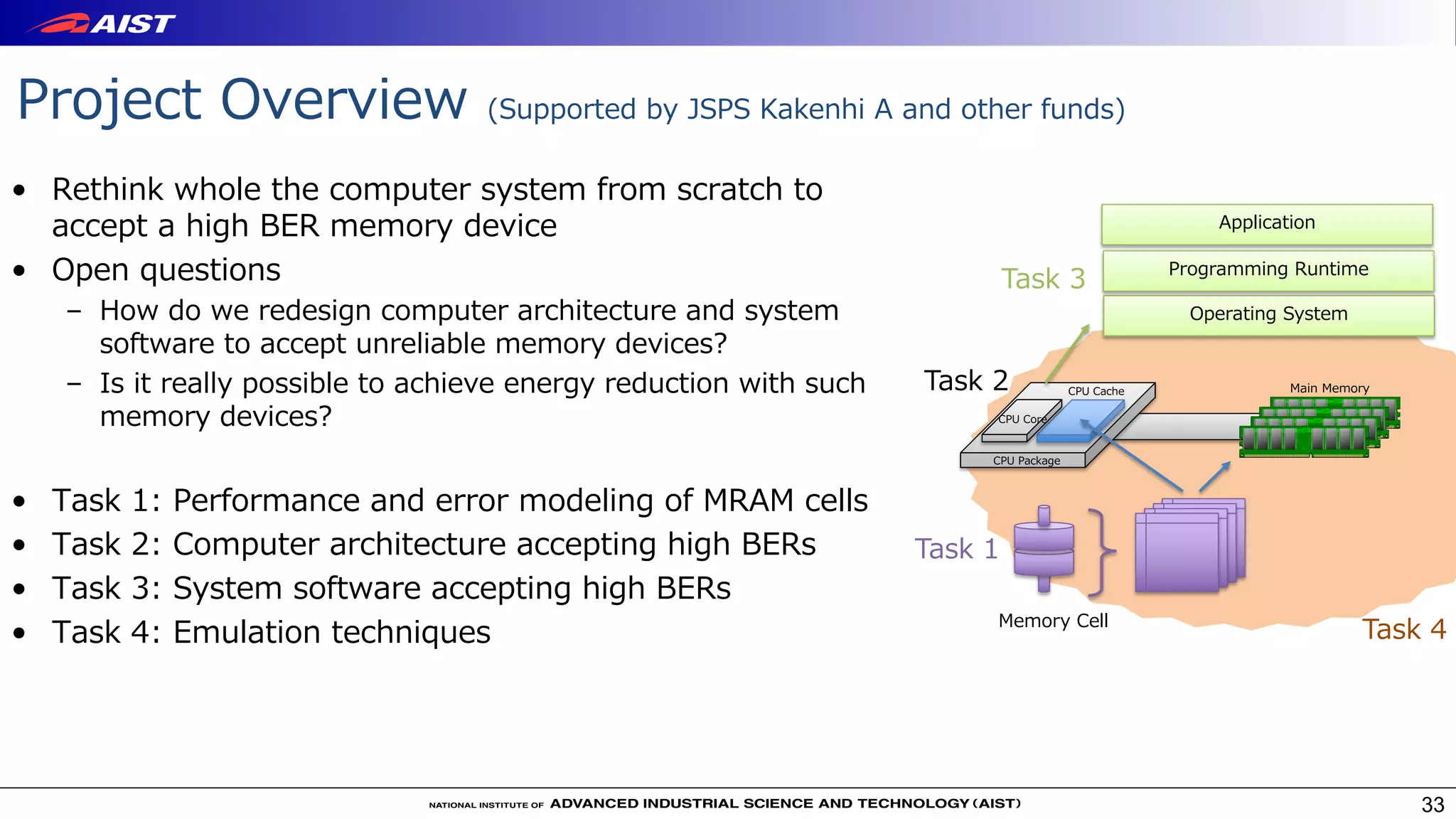

![Task 1. Performance and error modeling of MRAM cells
• Study bit-flip error
mechanisms and develop a
performance model
• Joint work with spintronics
researchers
35
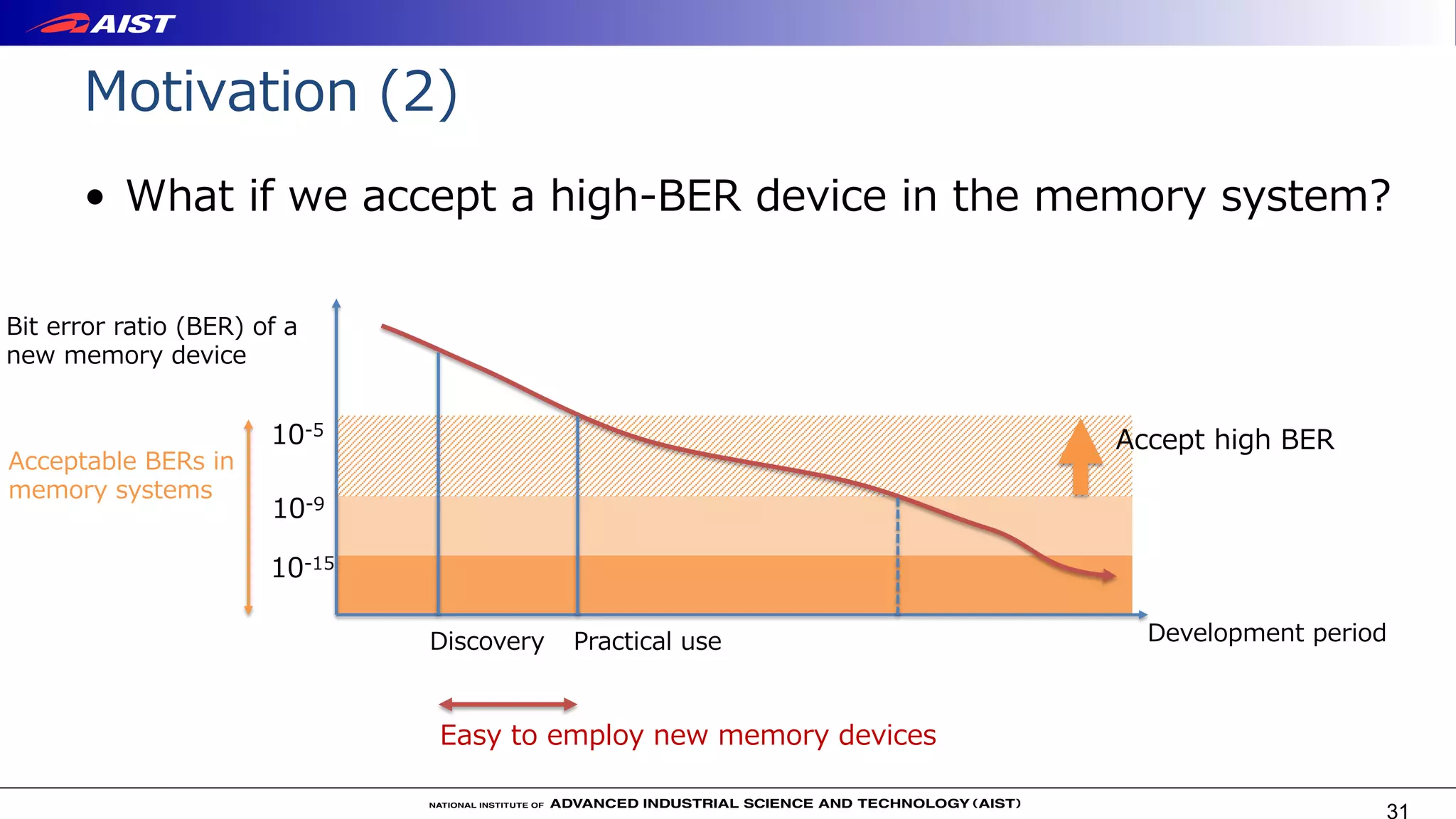
An example of tradeoff between error rate and power
consumption in STT-MRAM, which is based on
performance characteristics according to [1].
[1] Dynamics of spin torque switching in all-
perpendicular spin valve nanopillars , JMMM 2014](https://image.slidesharecdn.com/coolchips2020-invited-talk-public-200513085916/75/Virtualization-for-Emerging-Memory-Devices-35-2048.jpg)