Downloaded 17 times






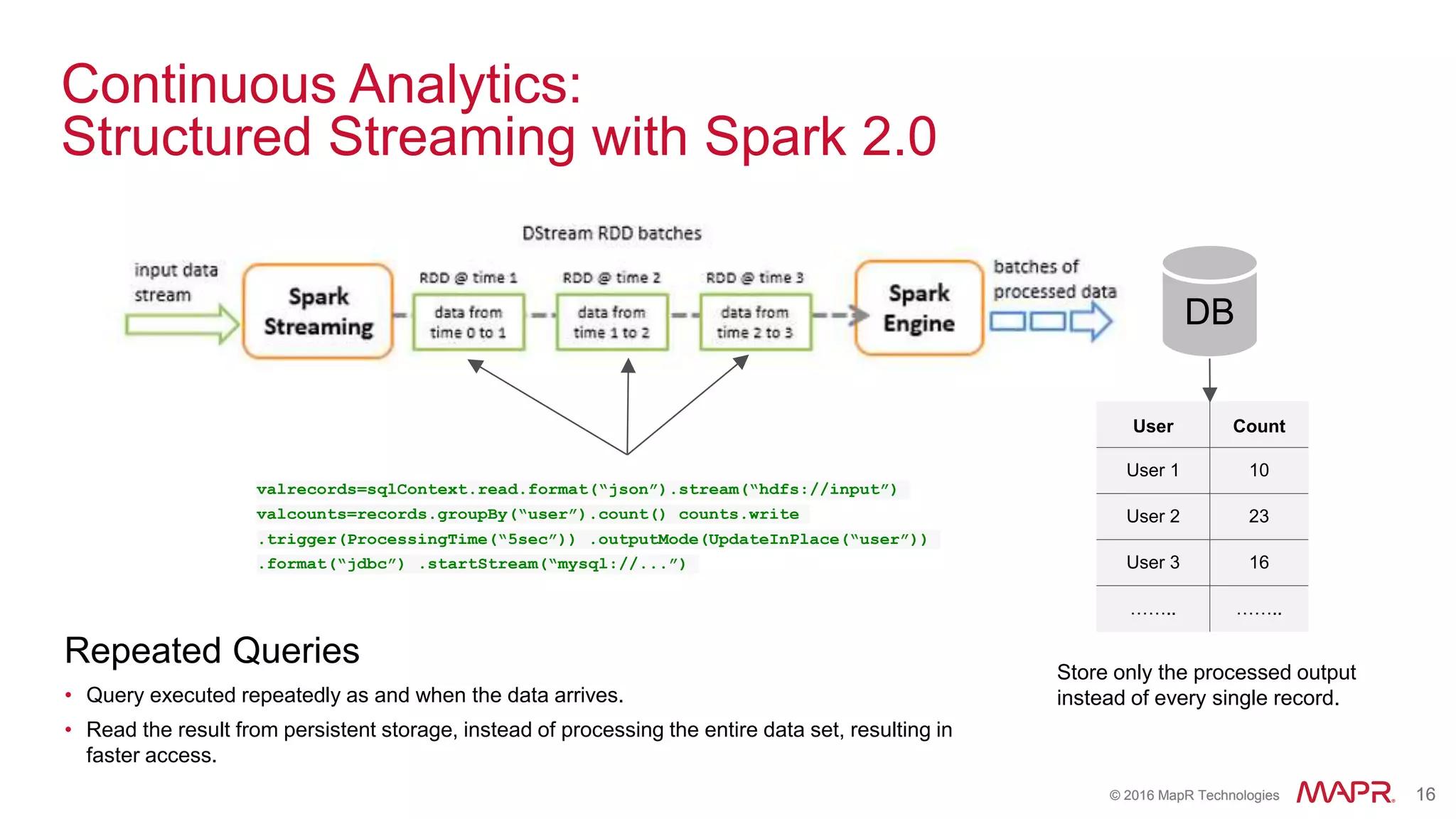










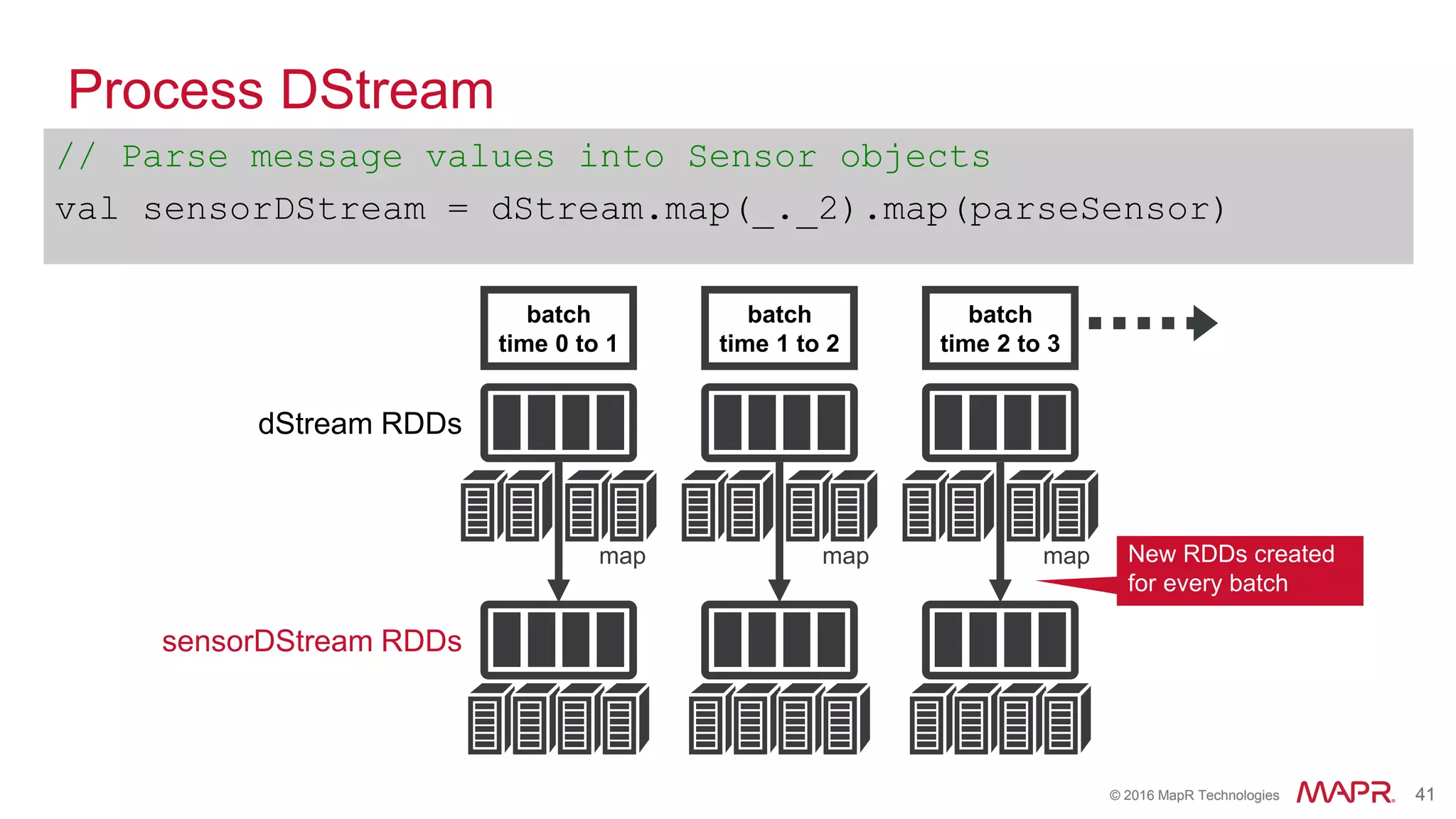
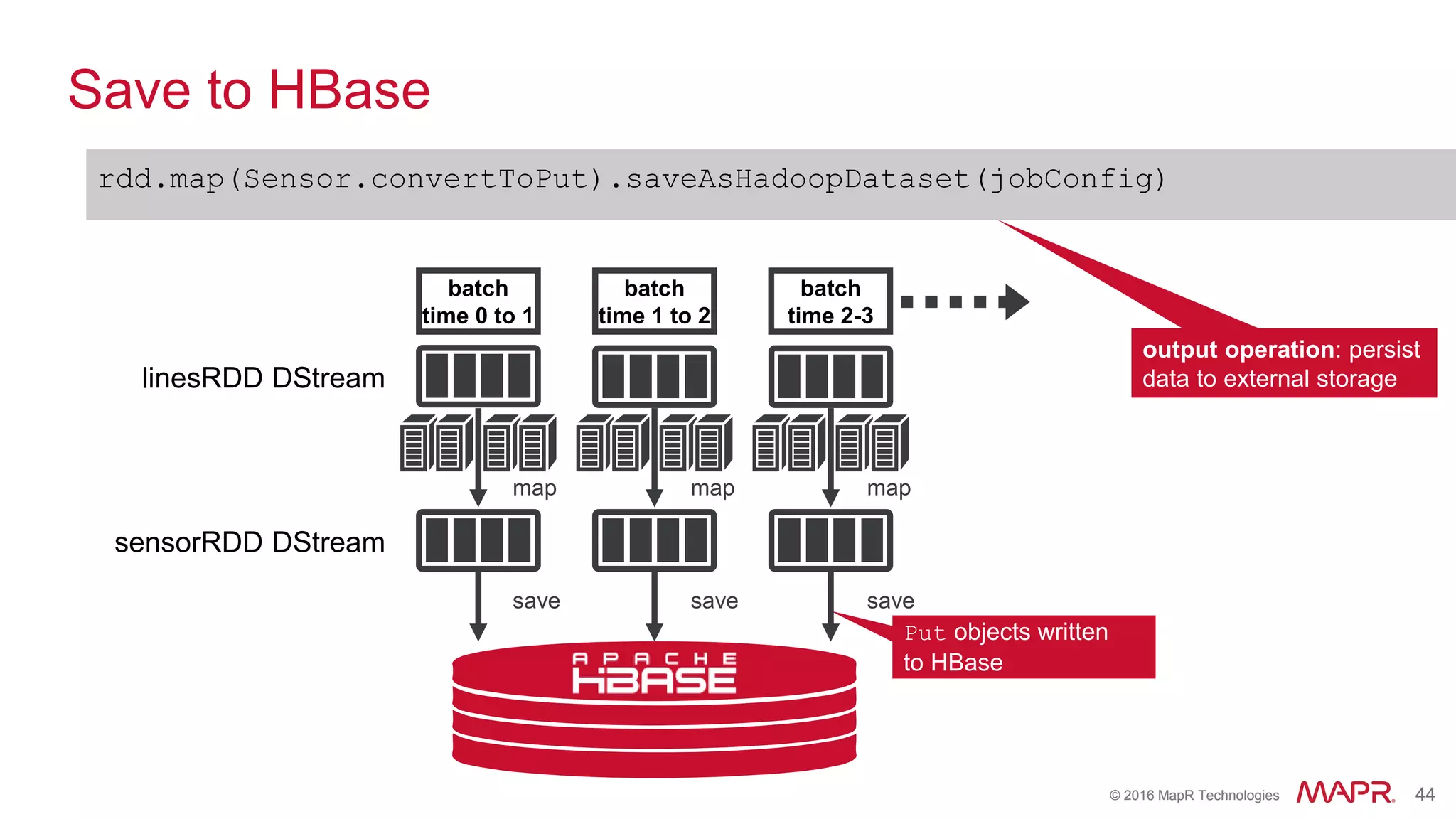
batch
time 0 to 1
batch
time 1 to 2
batch
time 2 to 3
dStream
Stored in memory
as an RDD](https://image.slidesharecdn.com/sparkwebinarsep30final1-161003213042/75/How-Spark-is-Enabling-the-New-Wave-of-Converged-Applications-38-2048.jpg)
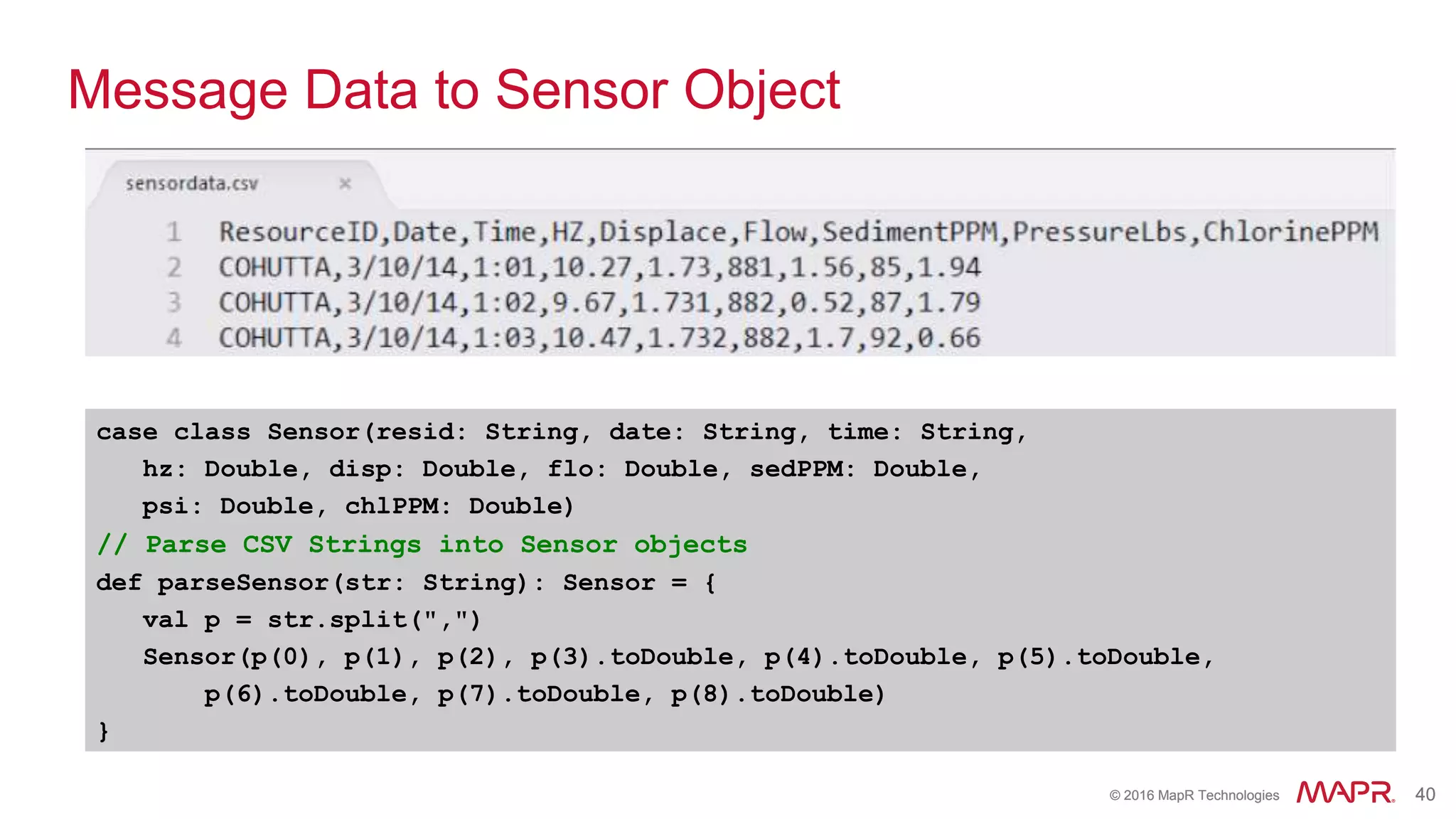



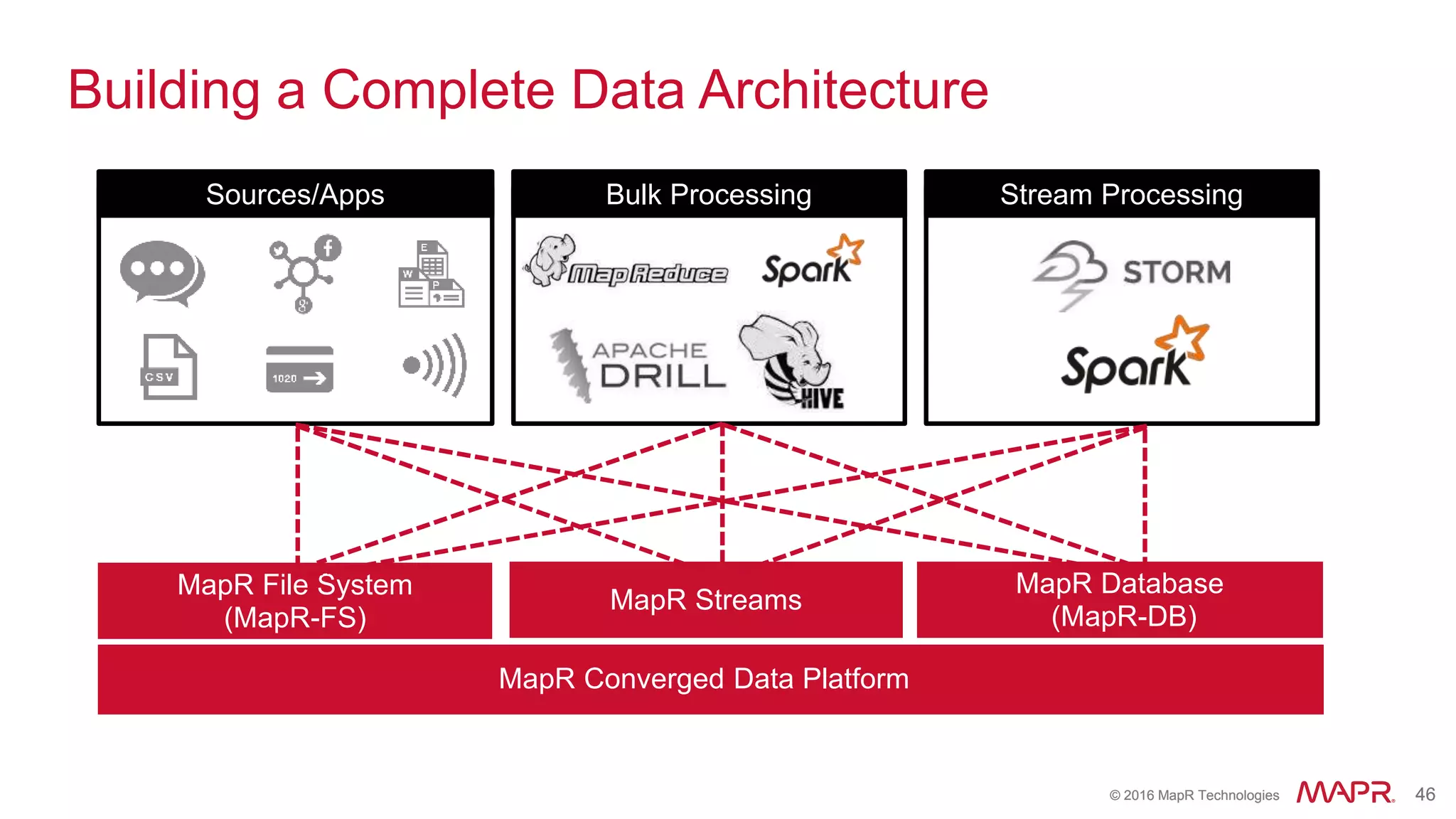


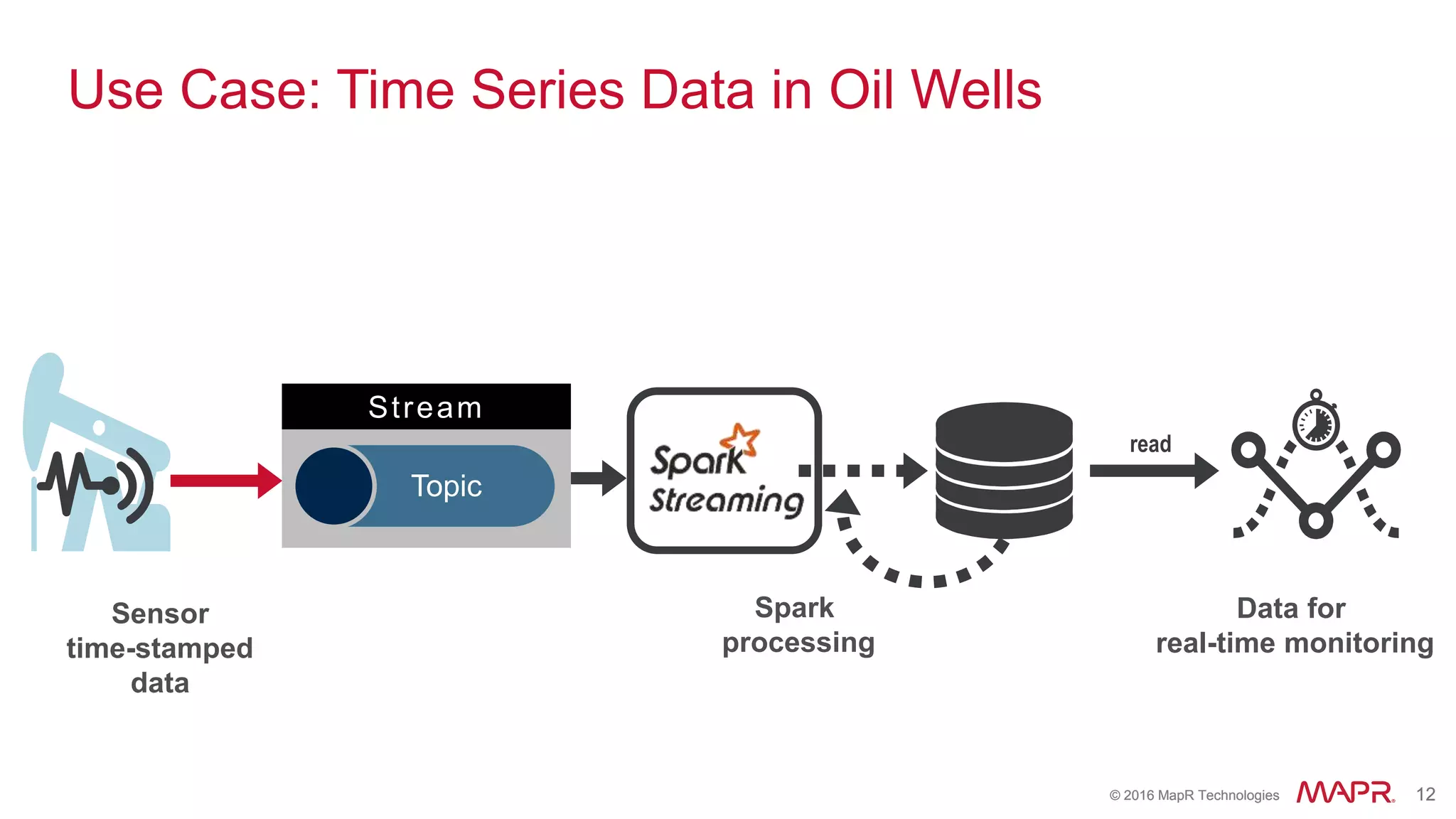
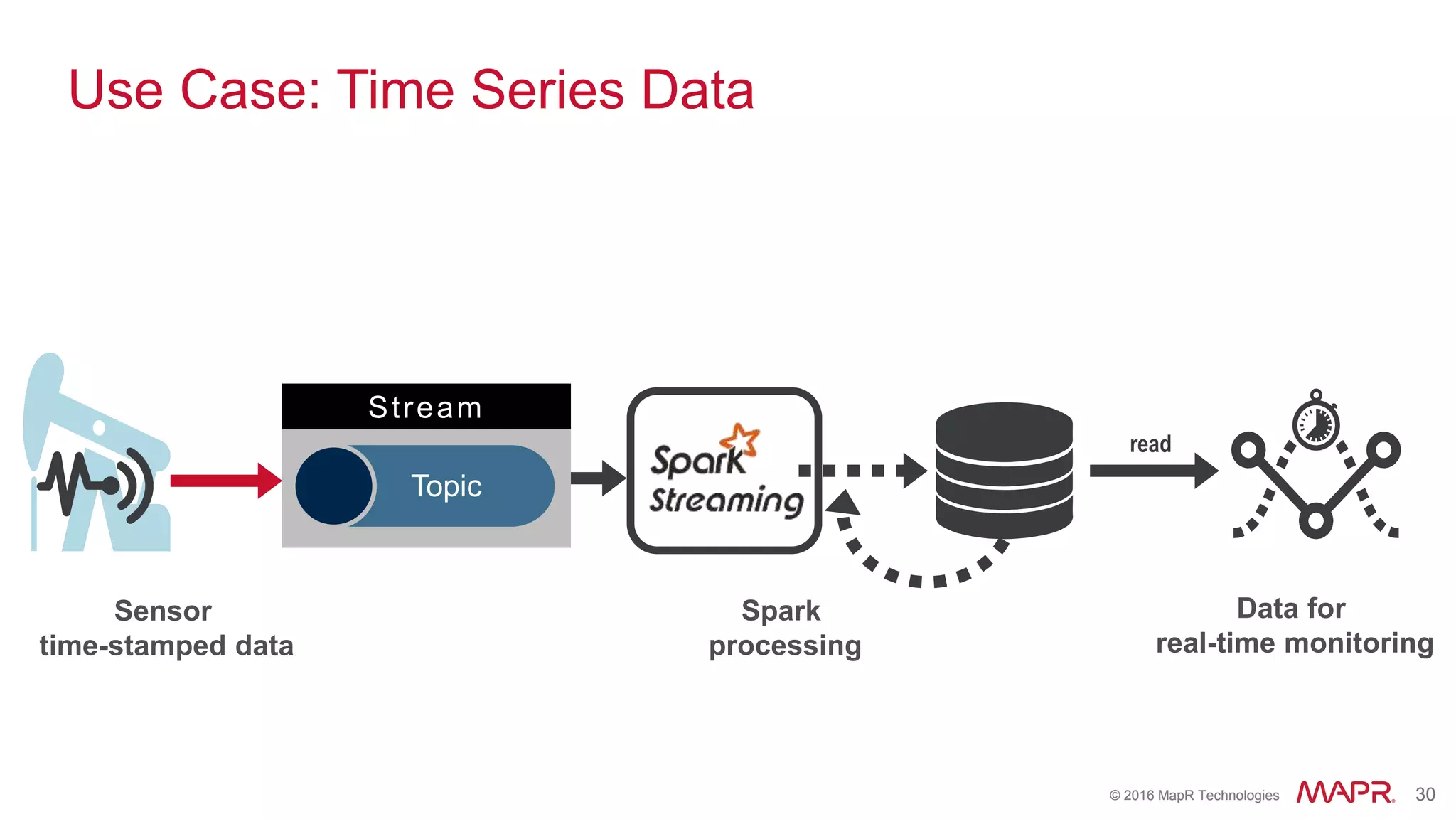
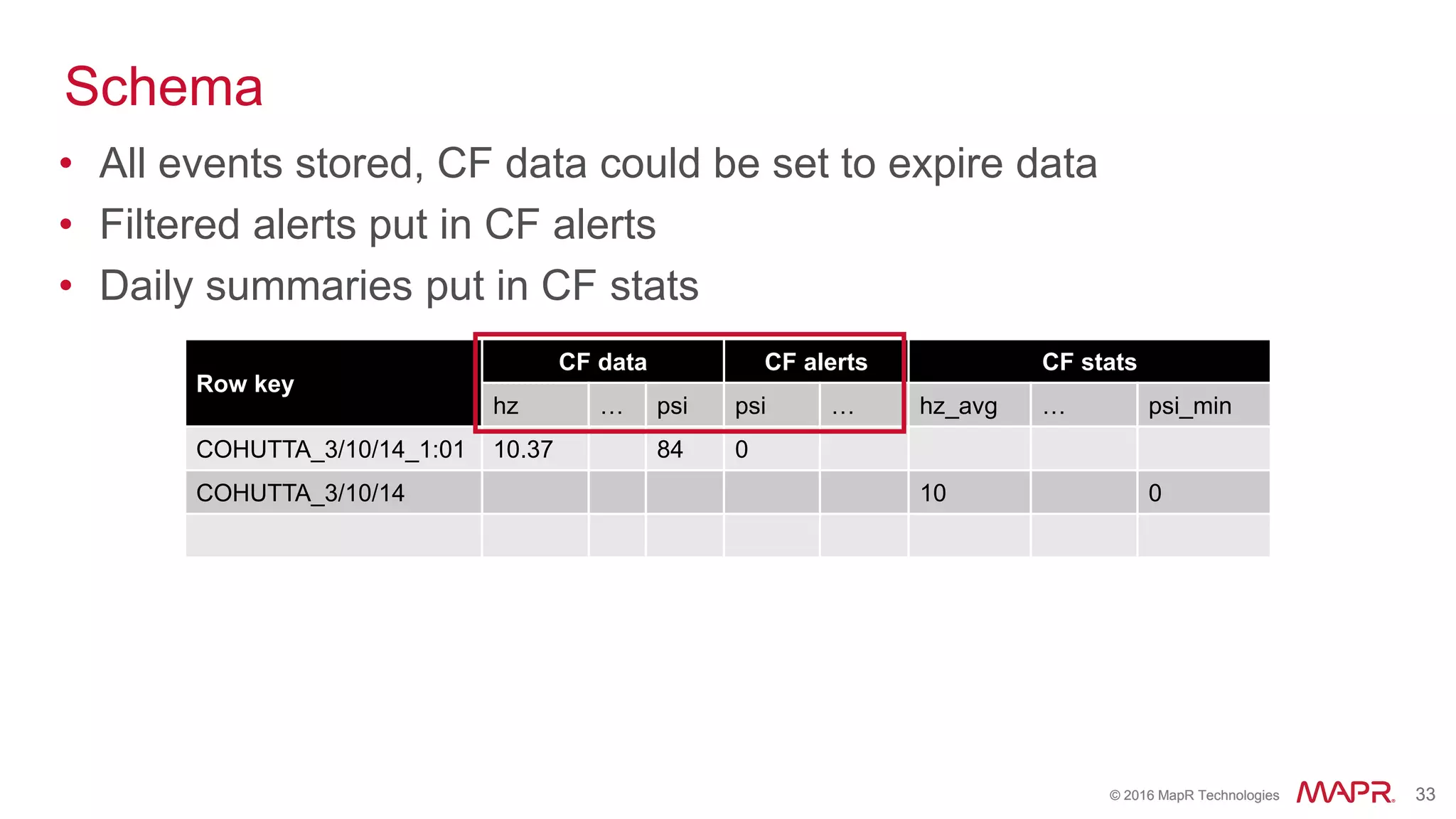
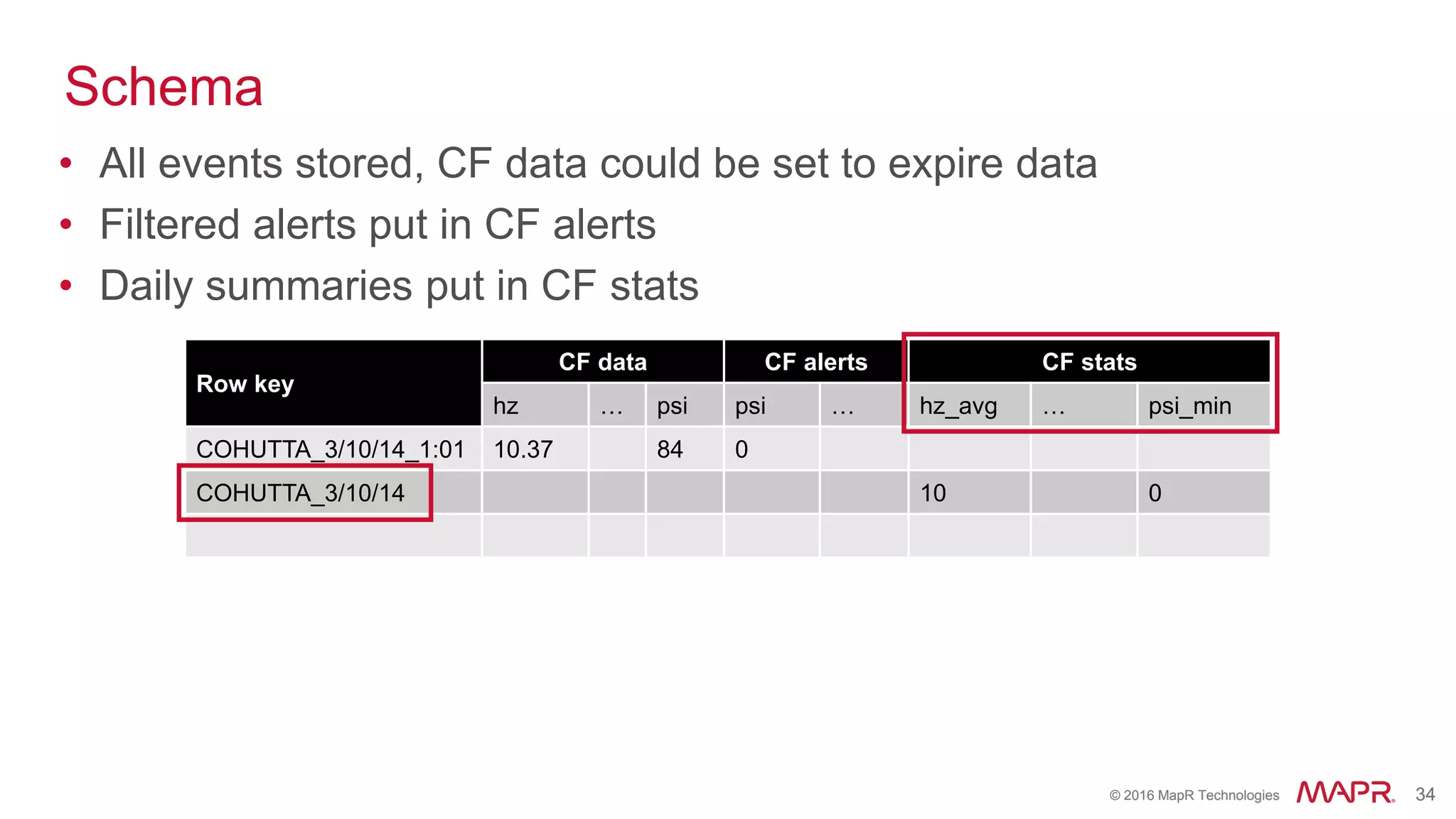
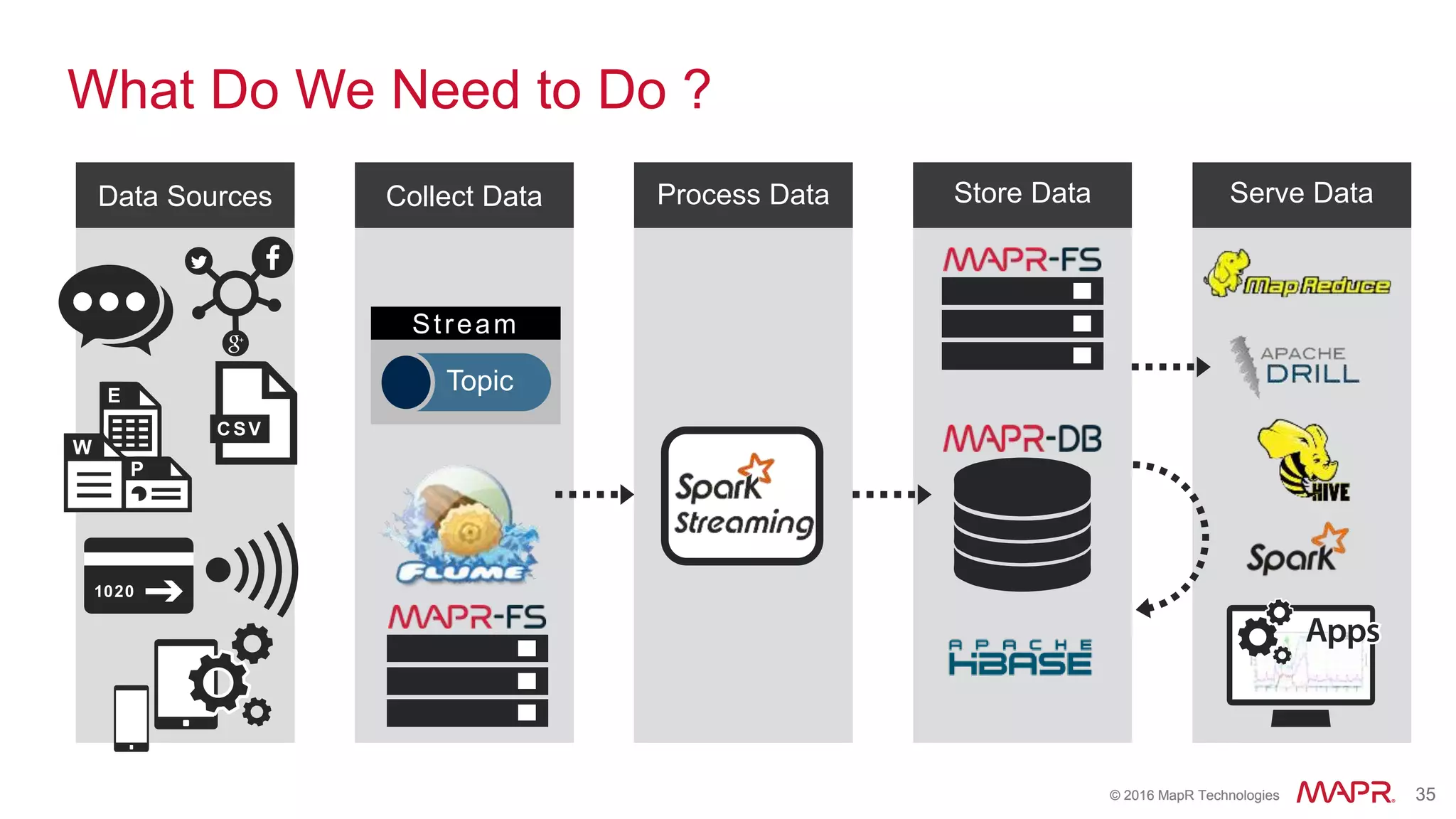
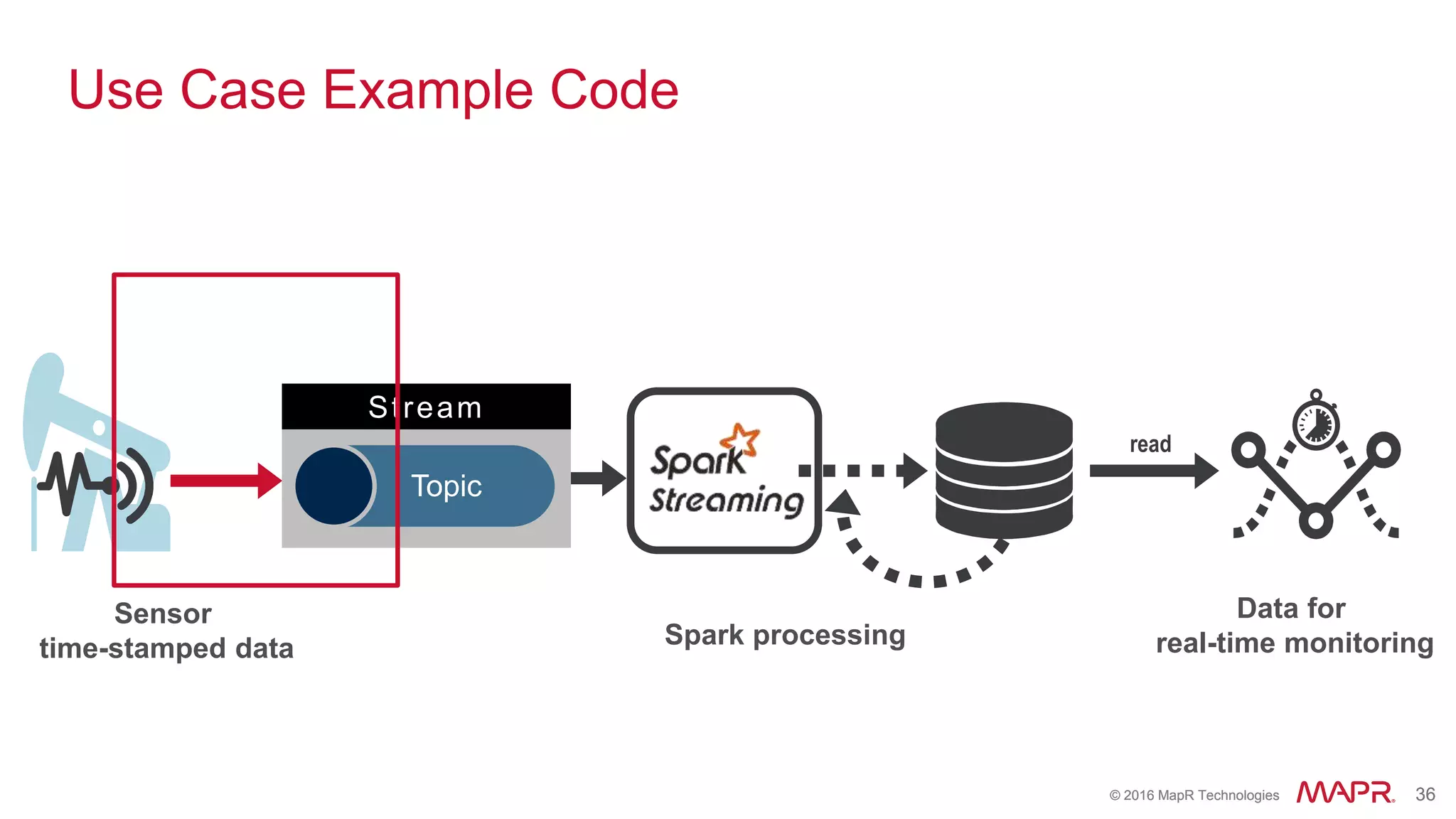
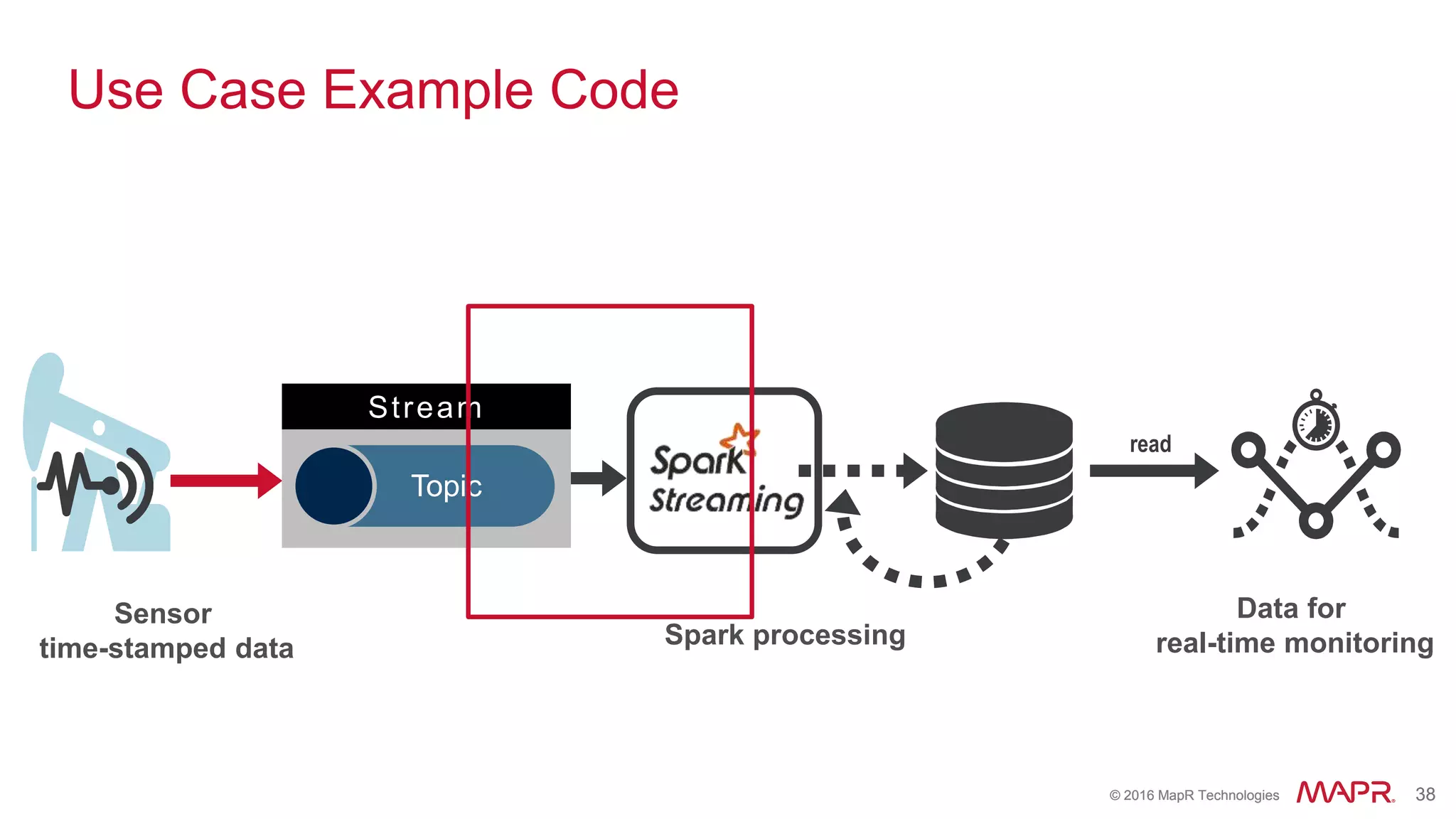
The document highlights the role of Spark in enabling converged applications, particularly focusing on real-time processing needs and use cases. It discusses market trends, essential components for these applications, and provides examples such as time-series data monitoring in oil wells and interactive analytics for customer behavior prediction. The presentation further illustrates how to leverage streaming data and integration with MapR technologies for effective analytics and decision-making.









































































































