Downloaded 151 times




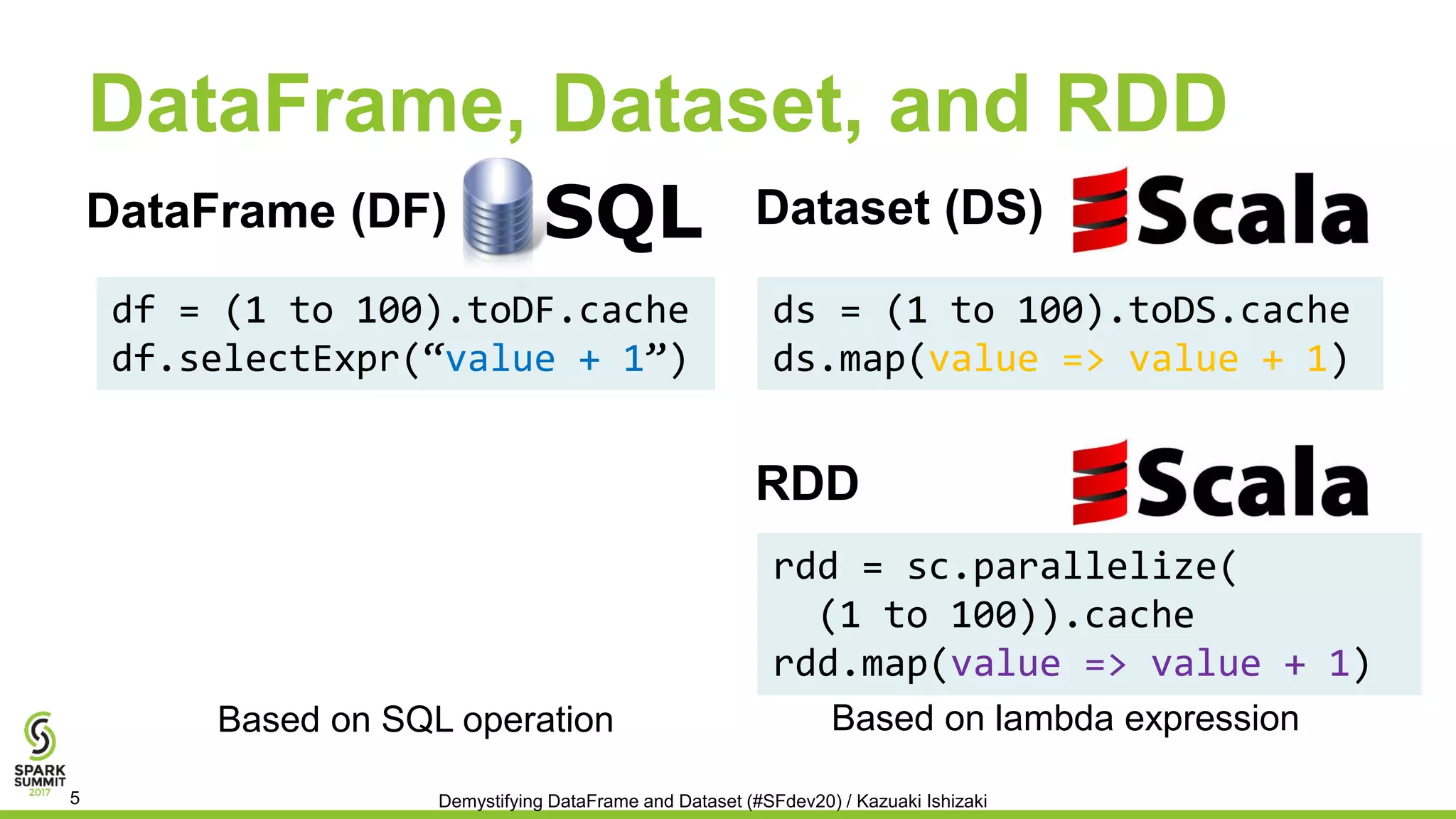
![Dataset for Int Value is Slow on
Spark 2.0
• 1.7x slow for addition to scalar int value
0 0.5 1 1.5 2
Relative execution time over DataFrame
DataFrame Dataset
df.selectExpr(“value + 1”)
ds.map(value => value + 1)
All experiments are done using
16-core Intel E2667-v3 3.2GHz, with 384GB mem, Ubuntu 16.04,
OpenJDK 1.8.0u212-b13 with 256GB heap, Spark master=local[1]
Spark branch-2.0 and branch-2.2, ds/df/rdd are cached
Demystifying DataFrame and Dataset (#SFdev20) / Kazuaki Ishizaki7
Shorter is better](https://image.slidesharecdn.com/065kazuakiishizaki-170614190427/75/Demystifying-DataFrame-and-Dataset-with-Kazuaki-Ishizaki-7-2048.jpg)
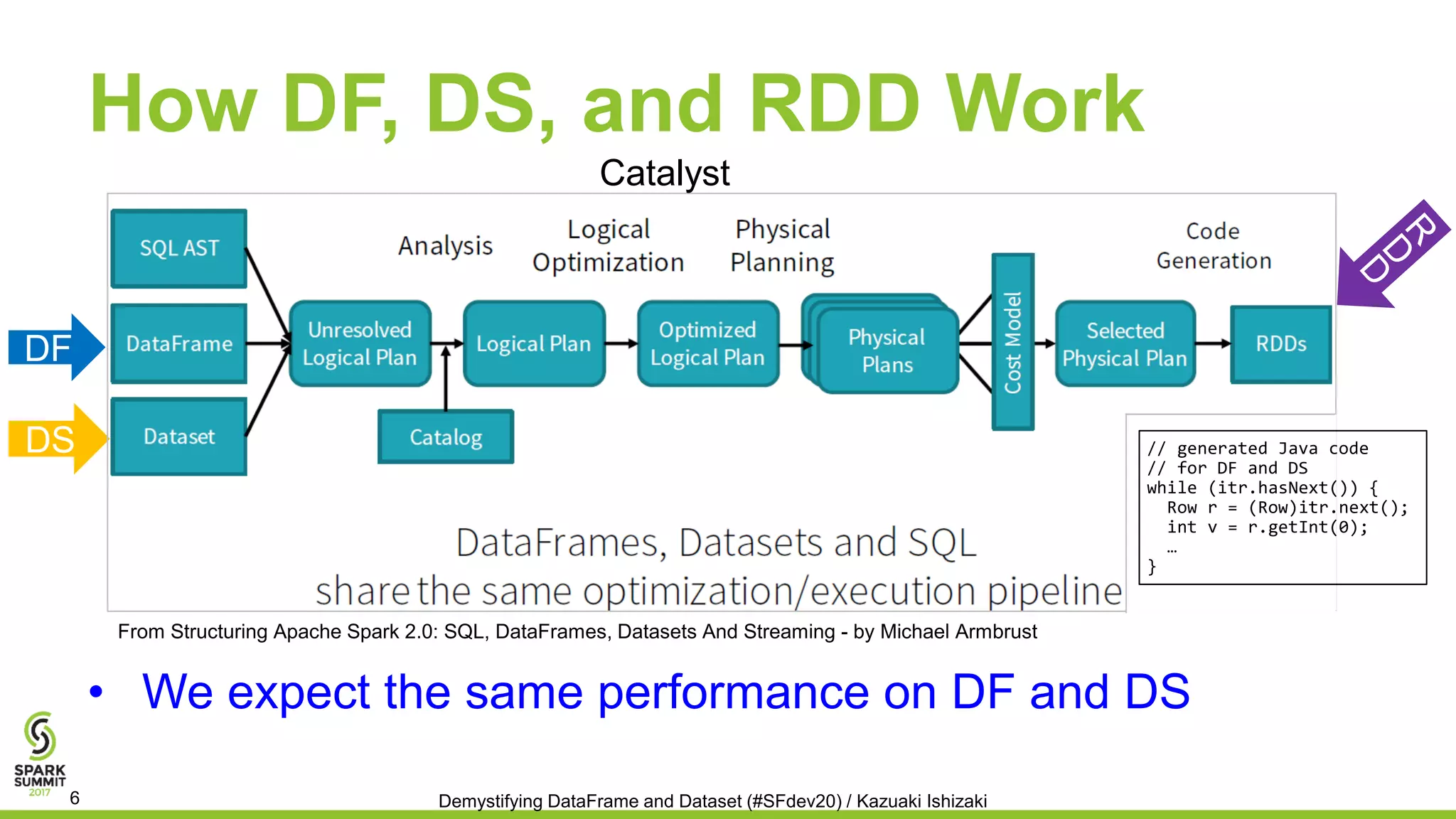
![Dataset for Int Array is Extremely
Slow on Spark 2.0
• 54x slow for creating a new array for primitive int array
0 10 20 30 40 50 60
Relative execution time over DataFrame
DataFrame Dataset
df = Seq(Array(…), Array(…), …)
.toDF(“a”).cache
df.selectExpr(“Array(a[0])”)
ds = Seq(Array(…), Array(…), …)
.toDS.cache
ds.map(a => Array(a(0)))
SPARK-16070 pointed out this performance problem
Demystifying DataFrame and Dataset (#SFdev20) / Kazuaki Ishizaki8
Shorter is better](https://image.slidesharecdn.com/065kazuakiishizaki-170614190427/75/Demystifying-DataFrame-and-Dataset-with-Kazuaki-Ishizaki-8-2048.jpg)


![Weird Generated Code with DS
• Generated code performs four data conversions
– Use standard API with generic type method apply(Object)
while (itr.hasNext()) {
int value = ((Row)itr.next()).getInt(0);
Object objValue = new Integer(value);
int mapValue = ((Integer)
mapFunc.apply(objVal)).toValue();
outRow.write(0, mapValue);
append(outRow);
}
Object apply(Object obj) {
int value = Integer(obj).toValue();
return new Integer(apply$II(value));
}
int apply$II(int value) { return value + 1; }
// ds: Dataset[Int] …
ds.map(value => value + 1)
Demystifying DataFrame and Dataset (#SFdev20) / Kazuaki Ishizaki11
Catalyst
generates
Java code
Scalac generates
these functions
from lambda expression
Catalyst](https://image.slidesharecdn.com/065kazuakiishizaki-170614190427/75/Demystifying-DataFrame-and-Dataset-with-Kazuaki-Ishizaki-11-2048.jpg)
![Simple Generated Code with DS
on Spark 2.2
• SPARK-19008 enables generated code to use int value
– Use non-standard API with type-specialized method
apply$II(int)
while (itr.hasNext()) {
int value = ((Row)itr.next()).getInt(0);
int mapValue = mapFunc.apply$II(value);
outRow.write(0, mapValue);
append(outRow);
}
int apply$II(int value) { return value + 1;}
// ds: Dataset[Int] …
ds.map(value => value + 1)
Demystifying DataFrame and Dataset (#SFdev20) / Kazuaki Ishizaki12
Catalyst
Scalac generates
this function
from lambda expression](https://image.slidesharecdn.com/065kazuakiishizaki-170614190427/75/Demystifying-DataFrame-and-Dataset-with-Kazuaki-Ishizaki-12-2048.jpg)

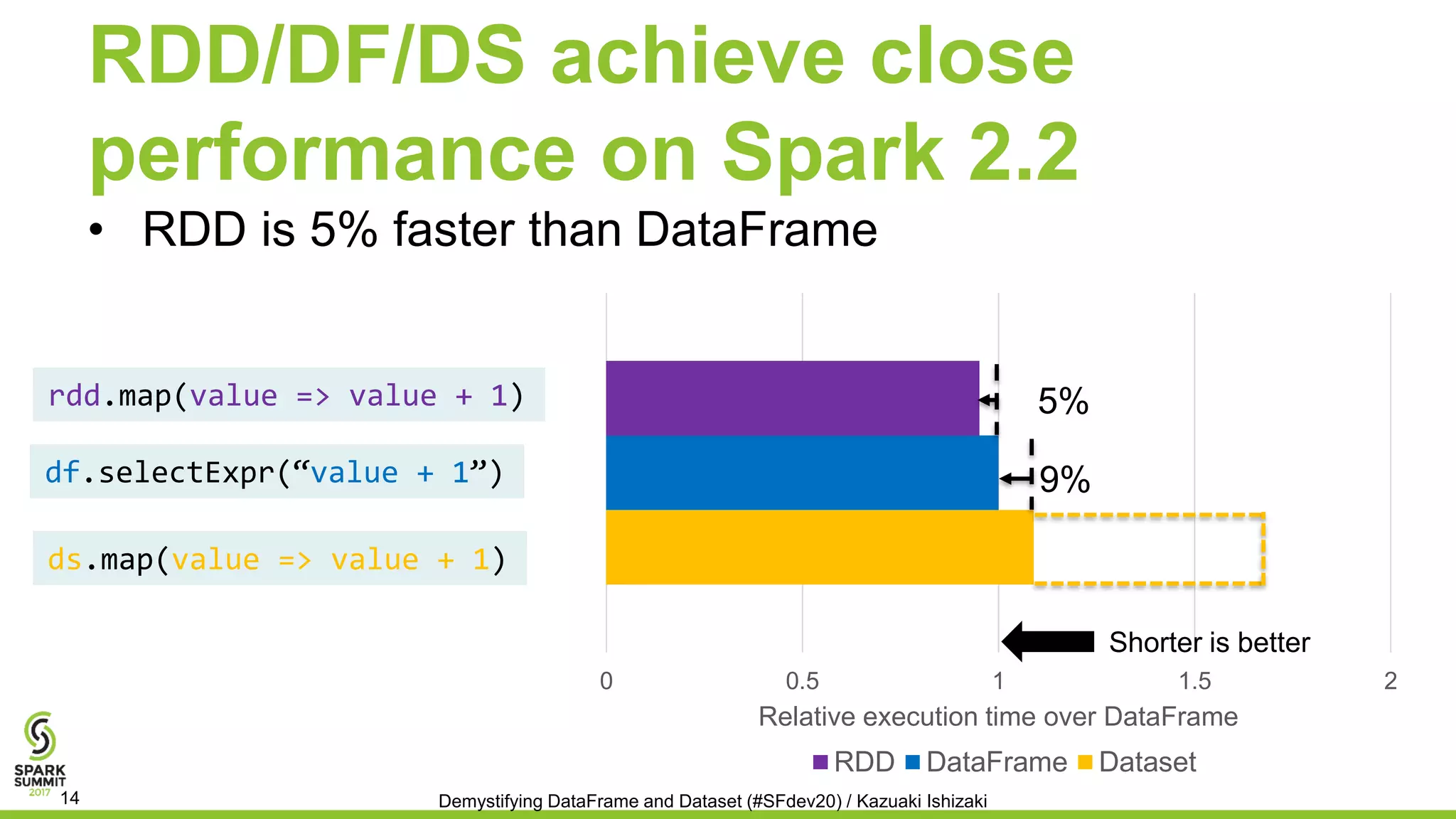
![Simple Generated Code for Array
with DF
• All operations access data in internal data format for array
ArrayData (devised in Project Tungsten)
// df: DataFrame for Array(Int) …
df.selectExpr(“Array(a[0])”)
ArrayData inArray, outArray;
while (itr.hasNext()) {
inArray = ((Row)itr.next()).getArray(0);
int value = inArray.getInt(0)); //a[0]
outArray = new UnsafeArrayData(); ...
outArray.setInt(0, value); //Array(a[0])
outArray.writeToMemory(outRow);
append(outRow);
}
Demystifying DataFrame and Dataset (#SFdev20) / Kazuaki Ishizaki15
Catalyst
generates
Java code
Internal data format (ArrayData)
inArray.getInt(0)
outArray.setInt(0, …)
Catalyst](https://image.slidesharecdn.com/065kazuakiishizaki-170614190427/75/Demystifying-DataFrame-and-Dataset-with-Kazuaki-Ishizaki-15-2048.jpg)
![Lambda Expression with DS
requires Java Object
• Need serialization/deserialzation (Ser/De) between internal
data format and Java object for lambda expression
// ds: DataSet[Array(Int)] …
ds.map(a => Array(a(0)))
ArrayData inArray, outArray;
while (itr.hasNext()) {
inArray = ((Row)itr.next()).getArray(0);
append(outRow);
}
Internal data formatJava object
Ser/De
Array(a(0))
Demystifying DataFrame and Dataset (#SFdev20) / Kazuaki Ishizaki16
int[] mapArray = Array(a(0));
Java bytecode for
lambda expression
Catalyst
Deserialization
Serialization
Ser/De](https://image.slidesharecdn.com/065kazuakiishizaki-170614190427/75/Demystifying-DataFrame-and-Dataset-with-Kazuaki-Ishizaki-16-2048.jpg)
![ArrayData inArray, outArray;
while (itr.hasNext()) {
inArray = ((Row)itr.next().getArray(0);
Object[] tmp = new Object[inArray.numElements()];
for (int i = 0; i < tmp.length; i ++) {
tmp[i] = (inArray.isNullAt(i)) ? Null : inArray.getInt(i);
}
ArrayData array = new GenericIntArrayData(tmpArray);
int[] javaArray = array.toIntArray();
int[] mapArray = (int[])map_func.apply(javaArray);
outArray = new GenericArrayData(mapArray);
for (int i = 0; i < outArray.numElements(); i++) {
if (outArray.isNullAt(i)) {
arrayWriter.setNullInt(i);
} else {
arrayWriter.write(i, outArray.getInt(i));
}
}
append(outRow);
}
ArrayData inArray, outArray;
while (itr.hasNext()) {
inArray = ((Row)itr.next().getArray(0);
append(outRow);
}
Extremely Weird Code for Array
with DS on Spark 2.0
• Data conversion is too slow
• Element-wise copy is slow
// ds: DataSet[Array(Int)] …
ds.map(a => Array(a(0)))
Data conversion
Element-wise data copy
Element-wise data copy
Demystifying DataFrame and Dataset (#SFdev20) / Kazuaki Ishizaki17
Data conversion Copy with Java object creation
Element-wise data copy Copy each element with null check
int[] mapArray = Array(a(0));
Catalyst
Data conversion
Element-wise data copy
Ser
De](https://image.slidesharecdn.com/065kazuakiishizaki-170614190427/75/Demystifying-DataFrame-and-Dataset-with-Kazuaki-Ishizaki-17-2048.jpg)
![Simple Generated Code for Array
on Spark 2.2
• SPARK-15985, SPARK-17490, and SPARK-15962
simplify Ser/De by using bulk data copy
– Data conversion and element-wise copy are not used
– Bulk copy is faster
// ds: DataSet[Array(Int)] …
ds.map(a => Array(a(0)))
while (itr.hasNext()) {
inArray =((Row)itr.next()).getArray(0);
int[] javaArray = inArray.toIntArray();
int[] mapArray = (int[])mapFunc.apply(javaArray);
outArray = UnsafeArrayData
.fromPrimitiveArray(mapArray);
outArray.writeToMemory(outRow);
append(outRow);
}
Demystifying DataFrame and Dataset (#SFdev20) / Kazuaki Ishizaki18
Bulk data copy Copy whole array using memcpy()
Catalyst
while (itr.hasNext()) {
inArray =((Row)itr.next()).getArray(0);
int[]mapArray=(int[])map.apply(javaArray);
append(outRow);
}
Bulk data copy
int[] mapArray = Array(a(0));
Bulk data copy
Bulk data copy](https://image.slidesharecdn.com/065kazuakiishizaki-170614190427/75/Demystifying-DataFrame-and-Dataset-with-Kazuaki-Ishizaki-18-2048.jpg)
![0 10 20 30 40 50 60
Relative execution time over DataFrame
DataFrame Dataset
Dataset for Array is Not
Extremely Slow over DataFrame
• Improve performance by 4.5 compared to Spark 2.0
– DataFrame is 12x faster than Dataset
ds = Seq(Array(…), Array(…), …)
.toDS.cache
ds.map(a => Array(a(0)))
Demystifying DataFrame and Dataset (#SFdev20) / Kazuaki Ishizaki19
4.5x
df = Seq(Array(…), Array(…), …)
.toDF(”a”).cache
df.selectExpr(“Array(a[0])”)
Would this overhead be negligible
if map() is much computation intensive?
12x
Shorter is better](https://image.slidesharecdn.com/065kazuakiishizaki-170614190427/75/Demystifying-DataFrame-and-Dataset-with-Kazuaki-Ishizaki-19-2048.jpg)
![RDD and DataFrame for Array
Achieve Close Performance
• DataFrame is 1.2x faster than RDD
0 5 10 15
Relative execution time over DataFrame
RDD DataFrame Dataset
ds = Seq(Array(…), Array(…), …)
.toDS.cache
ds.map(a => Array(a(0)))
Demystifying DataFrame and Dataset (#SFdev20) / Kazuaki Ishizaki20
df = Seq(Array(…), Array(…), …)
.toDF(”a”).cache
df.selectExpr(“Array(a[0])”)
rdd = sc.parallelize(Seq(
Array(…), Array(…), …)).cache
rdd.map(a => Array(a(0))) 1.2
12
Shorter is better](https://image.slidesharecdn.com/065kazuakiishizaki-170614190427/75/Demystifying-DataFrame-and-Dataset-with-Kazuaki-Ishizaki-20-2048.jpg)
![Enable Lambda Expression to
Use Internal Data Format
• Our prototype modifies Java bytecode of lambda
expression to access internal data format
– We improved performance by avoiding Ser/De
// ds: DataSet[Array(Int)] …
ds.map(a => Array(a(0)))
while (itr.hasNext()) {
inArray = ((Row)itr.next().getArray(0);
outArray = mapFunc.applyTungsten(inArray);
outArray.writeToMemory(outRow);
append(outRow);
}
Internal data format
“Accelerating Spark Datasets by inlining deserialization”, our academic paper at IPDPS2017
1
1
apply(Object)
1011
applyTungsten(ArrayData)
Demystifying DataFrame and Dataset (#SFdev20) / Kazuaki Ishizaki21
Catalyst
generates
Java code
Catalyst
Our
prototype](https://image.slidesharecdn.com/065kazuakiishizaki-170614190427/75/Demystifying-DataFrame-and-Dataset-with-Kazuaki-Ishizaki-21-2048.jpg)



![Two Method Calls for Adds
Remain with DS
• Spark 2.2 cannot understand lambda expressions stored
as Java bytecode
while (itr.hasNext()) {
int value = ((Row)itr.next()).getInt(0);
int mapValue = mapFunc1.apply$II(value);
mapValue += mapFunc2.apply$II(mapValue);
outRow.write(0, mapValue);
append(outRow);
}
// ds: Dataset[Int] …
ds.map(value => value + 1)
.map(value => value + 2)
class MapFunc1 {
int apply$II(int value) { return value + 1;}}
class MapFunc2 {
int apply$II(int value) { return value + 2;}}
Demystifying DataFrame and Dataset (#SFdev20) / Kazuaki Ishizaki25
Catalyst
Scalac generates
these functions
from lambda expression](https://image.slidesharecdn.com/065kazuakiishizaki-170614190427/75/Demystifying-DataFrame-and-Dataset-with-Kazuaki-Ishizaki-25-2048.jpg)
![class MapFunc1 {
int apply$II(int value) { return value + 1;}}
class MapFunc2 {
int apply$II(int value) { return value + 2;}}
Adds Will be Combined on Future
Spark 2.x
• SPARK-14083 will allow future Spark to understand Java
byte code lambda expressions and to combine them
while (itr.hasNext()) {
int value = ((Row)itr.next()).getInt(0);
int mapValue = value + 3;
outRow.write(0, mapValue);
append(outRow);
}
// ds: Dataset[Int] …
ds.map(value => value + 1)
.map(value => value + 2)
Dataset will become faster
Demystifying DataFrame and Dataset (#SFdev20) / Kazuaki Ishizaki26
Catalyst](https://image.slidesharecdn.com/065kazuakiishizaki-170614190427/75/Demystifying-DataFrame-and-Dataset-with-Kazuaki-Ishizaki-26-2048.jpg)

![How Dataset is Used in ML
Pipeline
• ML Pipeline is constructed by using DataFrame/Dataset
• Algorithm still operates on data in RDD
– Conversion overhead between Dataset and RDD
val trainingDS: Dataset = ...
val tokenizer = new Tokenizer()
val hashingTF = new HashingTF()
val lr = new LogisticRegression()
val pipeline = new Pipeline().setStages(
Array(tokenizer, hashingTF, lr))
val model = pipeline.fit(trainingDS)
def fit(ds: Dataset[_]) = {
...
train(ds)
}
def train(ds:Dataset[_]):LogisticRegressionModel = {
val instances: RDD[Instance] =
ds.select(...).rdd.map { // convert DS to RDD
case Row(...) => ...
}
instances.persist(...)
instances.treeAggregate(...)
}
ML pipeline Machine learning algorithm (LogisticRegression)
Derived from https://databricks.com/blog/2015/01/07/ml-pipelines-a-new-high-level-api-for-mllib.html
Demystifying DataFrame and Dataset (#SFdev20) / Kazuaki Ishizaki28](https://image.slidesharecdn.com/065kazuakiishizaki-170614190427/75/Demystifying-DataFrame-and-Dataset-with-Kazuaki-Ishizaki-28-2048.jpg)
![If We Use Dataset for Machine
Learning Algorithm
• ML Pipeline is constructed by using DataFrame/Dataset
• Algorithm also operates on data in DataFrame/Dataset
– No conversion between Dataset and RDD
– Optimizations applied by Catalyst
– Writing of control flows
val trainingDataset: Dataset = ...
val tokenizer = new Tokenizer()
val hashingTF = new HashingTF()
val lr = new LogisticRegression()
val pipeline = new Pipeline().setStages(
Array(tokenizer, hashingTF, lr))
val model = pipeline.fit(trainingDataset)
def train(ds:Dataset[_]):LogisticRegressionModel = {
val instances: Dataset[Instance] =
ds.select(...).rdd.map {
case Row(...) => ...
}
instances.persist(...)
instances.treeAggregate(...)
}
ML pipeline
Demystifying DataFrame and Dataset (#SFdev20) / Kazuaki Ishizaki29
Machine learning algorithm (LogisticRegression)](https://image.slidesharecdn.com/065kazuakiishizaki-170614190427/75/Demystifying-DataFrame-and-Dataset-with-Kazuaki-Ishizaki-29-2048.jpg)




Kazuaki Ishizaki from IBM Research presents enhancements in Apache Spark 2.2, highlighting the performance improvements of Datasets over DataFrames and RDDs. The document details benchmarking results, showing that Datasets have become significantly faster due to optimizations in the Catalyst optimizer and code generation. Key discussions include execution differences between Datasets and DataFrames, performance bottlenecks in earlier Spark versions, and the implications for application programmers and developers in machine learning pipelines.




































































![[DSC Europe 25] Hans Kleinsman - The Compliance Gearbox: How Tax Tech Mediate...](https://cdn.slidesharecdn.com/ss_thumbnails/dxdytie1toel0hr90bjs-2-251212103250-174fdbe7-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Kaja Kandare - LLM as a judge.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/arxyccaxsdsd1ba99wjw-7-251212104007-2b4e3f64-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Branko Dzakula - From Defense to Attack: How AI Redefines Cyb...](https://cdn.slidesharecdn.com/ss_thumbnails/80bdzdxpr3ky2g0qvyk9-8-251211083048-ce5fc1ee-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Marko Krstic - Understanding the AI Threat Landscape - Risks,...](https://cdn.slidesharecdn.com/ss_thumbnails/tiyim1ins5jvbrvzpzla-2-251209104645-c69d3553-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Behzad Hosseini - AI Agents in the Wild: Deploying Models tha...](https://cdn.slidesharecdn.com/ss_thumbnails/3qtejajvsjqrzwfept2c-10-251212103250-7f2b1068-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Miodrag Pesovic & Vladislav Radonjic - Federated Data Archite...](https://cdn.slidesharecdn.com/ss_thumbnails/gsbe3y5it5uhndi4e08e-1-251212103249-f1008e0c-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Vladimir Jelic - The AI-Driven Security Shift From Reactive D...](https://cdn.slidesharecdn.com/ss_thumbnails/6g5gj25mtjwayniqem1t-6-251209104645-7a5a5fc6-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Ivan Peric - Intelligence Swarm Logic and Techno-Functional M...](https://cdn.slidesharecdn.com/ss_thumbnails/7my7c97fsduiccadgavw-2-251212103249-5a03f7c6-thumbnail.jpg?width=640&height=640&fit=bounds)






![[DSC Europe 25] Branko Urosevic -Rethinking Financial Talent: Integrating Cod...](https://cdn.slidesharecdn.com/ss_thumbnails/8jjrus8ttko6qj64f58f-3-251212103250-642c6374-thumbnail.jpg?width=640&height=640&fit=bounds)

